阿里云ACP-检索分析服务
当数据量爆炸增长,并且需要提供全文检索功能,需要有效的数据检索能力
- 用什么数据库
- 怎么保证安全性
- 如何解决统计分析问题
- 如何解决单点故障
- 如何解决检索难题
应对方案:
- 关系型数据库:主从备份解决数据安全性问题,数据库代理中间件进行心跳监测解决单点故障,代理中间件通过查询语句分发到从节点进行最后汇总结果。
- 非关系数据库:MongoDB备份解决数据安全性问题,节点竞选机制解决单点故障问题,从配置库检索分片信息,将请求分发到各个节点,最后路由节点合并汇总结果
- 内存数据库:数据达到PB级别,成本巨大
ElasticSearch(ES)
业内最主流的信息检索、分析引擎,永远开源且免费,应用场景:
- 信息查询(查工商信息/物流信息)
- 日志检索和安全分析(IT运维领域)
- 商品搜索(条件筛选/排序)
- 数据分析和可视化(业务数据/交易数据)
- 订单查询(被集成到ERP/CRM等系统)
- 地理位置查询(LBS/地图/O2O)
优点:
- 查询速度快
- 对开发工程师,使用简单,容易入门
- 应用场景广泛
- Elastic Stack生态强大
- 软件开源免费
- 支持云原生
ES基本概念
| 名词 | 解释 |
|---|---|
| Cluster | ES集群 |
| Node | 节点 |
| Shards | 索引分片 |
| Replicas | 索引分片副本 |
| Master | 元数据管理 |
| Corrdinating | 处理路由请求 |
| Data | 保存数据分片,负责数据相关操作 |
ES和Mysql的概念对比
| ES | Mysql |
|---|---|
| index索引 | database数据库 |
| type文档类型 | Table表 |
| document文档 | row行,一条记录 |
| field字段,组成文档的最小单位 | column列 |
| mapping映射 | schema模式 |
| Get获取数据 | select … from table |
| Put插入数据 | insert into table |
阿里云ES简介
基于开源ES构建的全托管云服务
- 100% 兼容开源
- 开箱即用,
按需付费 - 支持ES stack生态组件
- 与Elastic官方合作提供免费X-pack商业插件
- 一键部署、弹性伸缩、智能运维
- 各类内核引擎优化
- 迁移、容灾、备份和监控等全套解决方案
成本对比

能力对比

实例创建

开启ES后可以修改配置


ES产品功能
- 完美适配公共和混合云

Beats采集
Logstash收集
ES检索
Ki可视化

计算存储分离
云原生-弹性-计算存储分离
开源ES问题:
- 负载不均:迁移热点分片带来大量数据拷贝
- 数据副本多副本带来重复计算和存储
- 数据搬迁节点扩缩容带来的数据搬迁
使用28定律,分为用的多的数据和不活跃的数据
写入增量数据之后,后台任务会定期复制增量数据到临时目录,秩序临时目录+commit segment即可,只保存了一份,成本降低

Indexing service
提供写入托管服务,针对写入方面的性能优化,适用于TPS高、写入流量波动较大、搜索QPS较低的场景(低成本、弹性扩展、免运维)
架构:计算和存储相分离的架构

Open Store自研引擎:针对日志场景自研的日志存储解决方案,能耨在日志场景中提供海量存储服务。使用与业务上对于数据有实时更新的需求,数据没有严格的冷热区分,业务有强烈且明确的数据冷热区分。
优势:
- 接近OSS的费用
- 海量存储(PB级别数据存储)、按量付费,资源使用率100%
- 零副本(默认数据容灾,无需配置副本)
- 查询性能提升(接近云盘性能)
- 易用
- 海量高效存储
其他高级特性
-
APM企业应用性能检测,对软件和应用程序运行状态进行检测、诊断和分析(APM Agent采集数据(数百个)-传到APMServer-转到ES-KIbana可视化,快速部署、灵活扩缩管理、低成本高性能)
-
Xpack商业特性:安全(索引和字段分权)、机器学习(数据实时监控,自预警)、监控、SQL能力(ES全文本检索和数据统计分析,支持客户端和RestAPI)
-
阿里分词:ES自带插件,可以完成文档分析检索,支持CRF、结合词典CRF、MMSEG等,有多种分词器(standard标准、cjk中日韩文、ik_max_wordIK中文、ik_smartIK中文、aliws阿里中文分词器)

ES迁移

啥数据都能迁移数据到ES,都可以到阿里云ES
可以结束Logstash全量和增连迁移ES数据,logstash自动创建索引,但是索引可能会跟之前不一致,推荐用python脚本手动创建索引

还可以通过Dataworks将Mysql数据实时同步至ES
阿里云ES DSL
发送restful请求,Kibana控制台进入ES
ES创建索引:PUT命令
右边代表创建twitter索引成功

ES写入文档:Put请求指定索引名称、类型、主键

ES主键查询:GET,可以通过ID查询

查询语法:GET

聚合查询语法:通过aggs进行聚合

修改ES文档:PUT写入到doc,POST发起更新

删除:DELETE

批量操作语句:/_bulk{}{}{},每个都是一对json串{操作:{}}{key:value}
有空行会报错

ES SQL查询
使用_xpack/sql
?format指定返回数据格式 csv/txt

添加索引别名:_alias

配置压缩的算法
默认EZ4,设置index.codec就行
default:EZ4
best_compression:更高压缩比
open:打开索引
close:关闭索引

#查询
GET _search{}
#看索引
GET _cat/indices?v
#创建索引
PUT /twitter?include_type_name=true
#写入数据:向twitter索引里面写入id为1的数据
PUT /twitter/_doc/1
#查询id 为1 的数据
GET /twitter/_doc/1
#Lucene查询语法:查询user为kmichy的记录
GET /twitter/_search?q=user.kmichy
#DSL查询语法,match匹配
GET /twitter/_seach
#DSL查询所有数据
GET /twitter/_search
#精准查询query--range--post_date --{from,to}
GET /twitter/_search
{"query":{"range":{"post_date":{}}}
}
#关键字查询;query---query_string--{query,default_opeartor,fields}
GET /twitter/_search
#查看索引映射字段信息
GET /twitter
#聚合统计
POST /twitter/_search?pretty
#修改数据{PUT覆盖全部信息/POST更新操作}
PUT /twitter/_doc/3{"key":"value"}
POST /twitter/_doc/3/_update{"key":"value"}
#批量请求操作
#创建test索引
PUT /test
#查看所有索引
GET _cat/indices?v
#批量创建,不能有空格,分别为:创建id为1,删除id为2,创建id为3,更新id为1
PUT /_bulk
{"index":{"_index":"test","_type":"doc","_id":"1"}}
{"field1":"value1"}
{"delete":{"_index":"test","_type":"_doc","_id":"2"}}
{"create":{"_index":"test","_type":"_doc","_id":"3"}}
{"field1":"value3"}
{"update":{{"_index":"test","_type":"_doc","_id":"1"}}}
{"doc":{"field1":"value1"}}#查询test索引
GET /test/_search# SQL查询,直接query里面执行sql
POST /_xpack/sql?format-txt
{"query":"select * from twitter"
}POST /_xpack/sql?format-txt
{"query":"show tables"
}POST /_xpack/sql?format-txt
{"query":"describe twitter"
}POST /_xpack/sql?format-txt
{"query":"select score() as score,user as name from twitter as mytable where user ='kimchy' or user='xx' limit 5"
}#创建索引,配置别名为my_index
PUT /my_index_v1
PUT /my_index_v1/_alias/my_index#查看所有别名为my_index的索引
GET /*/_alias/my_index#查看这个索引有哪些别名
GET /my_index_v1/_alias/*
阿里云ES SDK开发
ES支持通过REST API,通过JAVA,Python,Curl,C#,GO,JS,Perl,PHP,Ruby,SQL等多种开发语言客户端,支持sql查询数据
JAVA:发起查询请求
SQL:在Kiba统计
创建Maven-引入elasticsearch-rest-high-level-client(比ES版本高或相等)相关依赖包,执行查询操作。高并发场景推荐增加客户端连接数



需要添加白名单远程访问ES

集群监控管理
- 通过DSL发送指令
- GUI页面

高级监控报警
主分片不能用:red
部分分片不可用:yellow

基础监控
可查看CPU、内存等资源使用情况

Kibana查看堆栈检测
语句:GET /_cat/health?v,v代表列名标示出来
GUI:

GET /_cat/nodes?v或者GUI:

GET /_cat/indices?v

分析当前线程池
GET /_cat/thread_pool?v:所有线程池信息
GET /_cat/thread_pool/write?v:写入线程池信息
GET /_cat/thread_pool/search?v:查询线程池信息

分析热点线程(消耗资源多的线程)
GET /_nodes/hot_threads

分析当前执行任务
GET _cat/tasks?v

写入优化
ES写入流程:
客户端选择Node发送请求:为协调节点,写入到对应Node(Primary),写数据之后,replica副本分片同步数据
主和副本写入完成后返回成功
Lucene引擎用于写入数据,记录translog日志并写入内存,定期刷新以segment文件格式保存

写入优化
不同索引分片数的写入耗时

设置合理的分片数和副本数

具体代码:
settings–index–number_of_shards/replicas
settings–refresh_interval/…

写入优化示例
索引刷新间隔:默认1s,会有很多segment
bulk总体字节数不能太大,不然会有内存压力

查询优化

- query:广播到所有分片,在本地搜索并匹配文档的优先队列,每个分片返回各自优先队列里面文档id和排序值给给协调节点,协调节点会把这些值合并到自己的有限队列,产生全局排序后结果列表。
- then
- fetch:协调节点会辨别出哪些文档需要被取回,并且向相关分片提交多个get请求,并返回文档给协调节点,一旦所有节点都被取回,那么协调节点就会返回结果给客户端,关键词的查询请求会同时从内存和磁盘的索引里面查找,主键磁盘优先从事务日志里面获取文档信息,事务日志没有命中再从磁盘去读取文档信息,这样就可以保证数据写入后实时读取到文档信息。(因为写入后首先写的就是日志)
内存查询性能优化 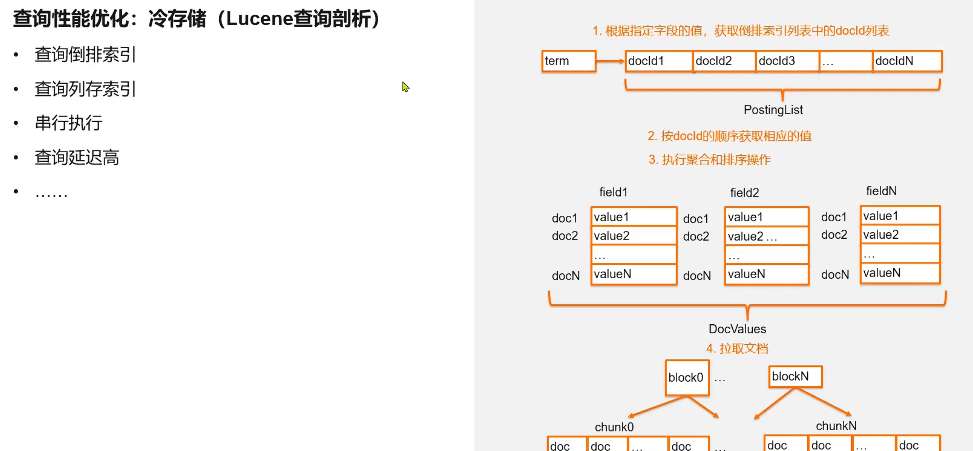


集群节点数对延迟的影响

提高查询效率:
硬件;在一定前提下升级扩容集群。
查询本身:filter过滤、路由强制合并只读索引,配置协调节点,配置合适的分词器,设置查询读数设置的条数和字段,配置terminate after查询快速返回,同时避免前缀模糊匹配、避免深度翻页,避免索引稀疏
-使用过滤器GET /twitter/_search{query--bool--filter}

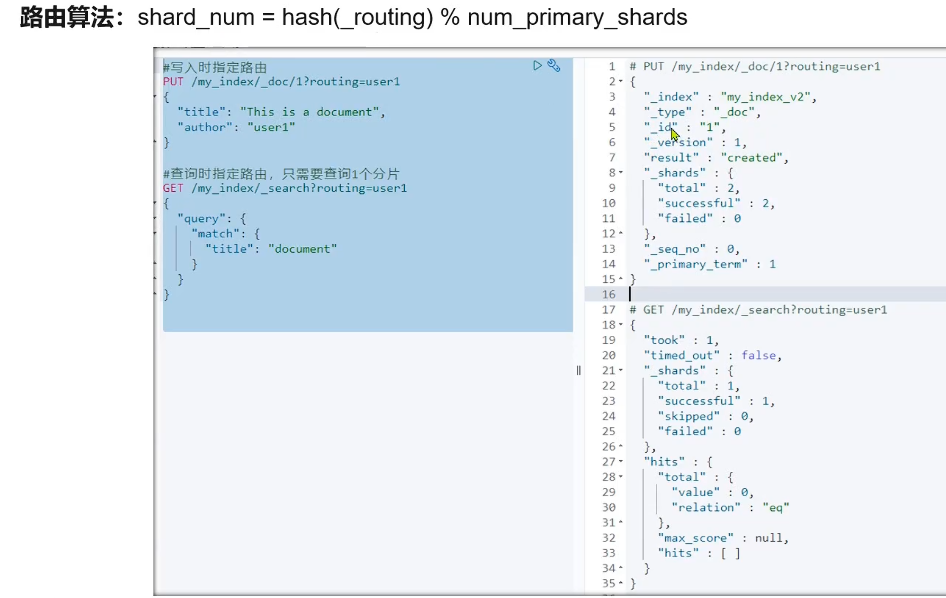
-使用路由:GET /my_index/_search?routing=user1 路由算法:shard_num=hash(_routing)%num_primary_shards
PUT /my_index/_doc/1?routing=user1设置路由字段
- 强制合并优化索引
POST /twitter/_forcemerge?max_num_segments=1,设为1后就不需要跨网络跨分片,小于30GB可合为一个分片

terminate_after提前结束搜索快速返回,到达1000(terminate_after)之后就会结束查询
