ACL 2025 Findings | 无监督概念发掘,提高文本解释的可理解性
5月29日,第63届国际计算语言学学会年会(Annual Meeting of the Association for Computational Linguistics,ACL 2025)公布录用论文清单。会议将于7月27日至8月1日在奥地利维也纳举行。 本文将介绍一篇关于模型可解释的ACL 2025 Findings录用论文。

★题目:Enhancing the Comprehensibility of Text Explanations via Unsupervised Concept Discovery
作者:Yifan Sun, Danding Wang, Qiang Sheng, Juan Cao, Jintao Li
ArXiv: https://arxiv.org/abs/2505.20293
(点击“阅读原文”可直接跳转)
研究背景
深度神经语言模型具有高度的复杂性和不透明性,其决策机制难以被人类理解。传统的大多数可解释性方法采用特征归因的方式,虽然能够确定重要特征的位置,却未能揭示这些特征的确切含义。因此,可解释性方法的研究焦点逐渐转向更深层次的需求——不仅要指出重要特征的位置,更要揭示这些特征背后的含义与逻辑,以接近人类认知的方式解释模型。
在此背景下,研究者们提出了基于概念的可解释方法。该方法将输入特征映射到一系列人类可理解的概念上,并量化每个概念对模型预测结果的具体影响。现有方法主要分为两类:①一类需要人工预定义概念集作为监督,这类方法无法自动发现新概念,应用场景受限;②另一类无需概念标注监督,但由于在训练过程中缺乏可量化的指标优化概念的可理解性,导致发现的概念含义模糊、难以理解。如何自动发现可理解的概念解释,仍然是一个尚未解决的问题。
针对上述问题,本文提出了一个流程自解释的方法 ECO-Concept,该 方法 具有以下创新:(1)无需人工概念标注,通过竞争注意力机制自动发现语义概念;(2)借鉴人类认知过程,采用自然语言总结与重现能力作为可理解性评估标准;(3)在模型训练过程中实现实时评估与反馈优化,以增强提取概念的可理解性。

图1 与现有基于概念方法的对比
研究方法
本文提出的方法包含两个核心模块:概念提取器和概念评估器。概念提取器接收编码后的文本输入,生成概念注意力矩阵。而后将各概念的注意力分数在词元维度聚合,输入分类器进行预测。概念评估器则使用大型语言模型(LLM)对提取出的概念进行可理解性评估,并通过计算可理解性损失来进一步指导概念的优化。

图2 方法流程框架
概念提取
-
本文使用基于槽注意力的机制自动提取语义概念。其核心思想是利用多个槽来竞争性地解释输入特征的不同部分。通过多轮注意力竞争,这些槽逐渐调整以代表不同的与任务相关的概念。
-
为了提高概念的可解释性,引入了两个正则化项:一致性(Consistency)和独特性(Distinctiveness)。一致性确保同一概念在不同样本中的激活特征具有一致的语义,独特性确保不同概念覆盖不同的语义元素。

图3 基于槽注意力的概念提取
概念可理解性增强
为了进一步评估和提升所提取概念的可理解性,本文提出利用 LLM 作为人类代理来计算概念的可理解性损失。具体步骤如下:
1. 选择每个概念下激活值最高的样本,形成两个集合,分别用于概念总结和概念相关片段的高亮;
2. 使用 LLM 对一个集合中的样本进行概念总结,生成自然语言描述;
3. 如果某个概念具有语义,则使用另一个 LLM 在另一组新样本中高亮与概念相关的文本段落;
4. 通过比较 LLM 高亮的片段与模型槽注意力矩阵之间的差异,并结合概念对分类器的重要性,计算概念的可理解性损失。

图4 概念可理解性增强
实验结果
分类性能评估
通过在虚假新闻检测、意图识别、情感分析等多个任务的实验验证,ECO-Concept 在分类性能上能达到与黑盒模型相媲美甚至更优的结果,说明模型在注重可理解性提升的同时,并未影响任务的性能。
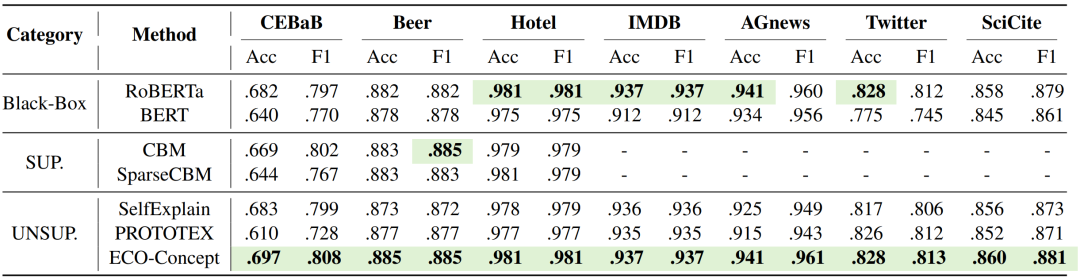
表1 分类性能对比结果
概念解释评估
为了评估 ECO-Concept 抽取概念的可理解性,进行了量化指标评估和人类评估实验,与多个基于概念的可解释性方法进行了对比。
量化指标评估:
-
语义性:抽取的概念中具有明确语义的概念所占比例
-
多样性:抽取的概念中具有独特含义的概念所占比例
-
一致性:采用主题一致性分数评估每个概念内部激活内容的一致性

表2 可解释量化指标结果
人类评估:
入侵者检测实验:参与者需要从四个样例中识别出与其它概念不同的样例。

表3 入侵者检测实验结果
主观评分实验:参与者从一致性、清晰度、任务相关性和可理解性等多个角度对提取的概念进行评分。

图5 人类主观评分结果
前向可模拟性实验:参与者根据提供的解释推断模型的输出,并对其信心进行评分,以验证提取的概念是否有助于人类理解模型的行为。

表4 前向可模拟性实验结果
总结
针对当前可解释性方法难以在无监督情况下自动发现可理解概念的问题 ,本文提出了一种 流程自解释方法 。该方法通过 竞争注意力机制 自动挖掘语义概念,并利用 LLM 作为人类代理 ,在训练过程中实时评估和反馈优化概念的可理解性。实验表明,在多个数据集上,本方法 既能保持模型分类性能,又能生成更符合人类认知的解释 。