AMD Pensando Pollara 400Gbps网卡深度解析:超级以太网重塑AI集群网络架构
在生成式AI爆发初期,标准以太网曾因性能瓶颈在数据中心市场被英伟达InfiniBand大幅抢占份额。然而,凭借成本优势、InfiniBand固有缺陷(如架构复杂性与生态封闭性),以及以太网在功能扩展与定制化上的灵活性,以太网正逐步夺回失地。亚马逊、谷歌等企业通过内部优化以太网实现,大幅缩小了与InfiniBand的性能差距,甲骨文与Meta等公司也在以太网基础上投入大量研发,技术水平已与英伟达接近。甚至英伟达自身也意识到以太网的主导地位,其Blackwell一代产品中,Spectrum-X以太网的出货量已远超Quantum InfiniBand。
在此背景下,超级以太网联盟(Ultra Ethernet Consortium, UEC)发布1.0规范成为行业转折点。Ultra Ethernet Consortium(超以太网联盟)于2025年6月发布1.0版本技术规范,其核心目标是为超大规模AI和HPC数据中心提供低延迟、高带宽、可扩展的互联架构。与传统以太网相比,Ultra Ethernet 1.0引入了三项关键技术:
1. 多路径传输与动态路由
-
-
通过多路径负载均衡(Multi-Path Load Balancing),数据流可智能拆分并动态分配至最优路径,避免网络瓶颈。
-
选择性重传机制(Selective Retransmission)仅重传丢失的数据包,而非整个数据流,显著降低冗余流量。
-
2. 路径感知拥塞控制(Path-Aware Congestion Control)
-
-
实时监控网络路径状态,动态调整传输速率,避免拥塞。相比传统RoCEv2协议,Ultra Ethernet 1.0的拥塞控制算法可提升25%的RDMA性能。
-
3. RDMA优化与低延迟设计
-
-
远程直接内存访问(RDMA)技术被进一步优化,AMD Pensando Pollara网卡的RDMA性能较NVIDIA CX7高10%,较Broadcom Thor2高20%。
-

与传统以太网的对比:从“被动传输”到“主动智能”。传统以太网(如RoCEv2)在超大规模AI集群中面临三大痛点:
-
尾部延迟(Tail Latency):单点故障或拥塞可能导致局部延迟激增。
-
协议僵化:缺乏对动态负载的适应性,难以满足AI训练的突发性数据需求。
-
扩展性瓶颈:百万级GPU互联场景下,传统协议无法有效管理复杂拓扑。
而Ultra Ethernet 1.0通过可编程协议栈(P4架构)和硬件级智能调度,解决了上述问题。例如,Pensando Pollara网卡内置的自研专用处理器(ASIC)可实时解析数据流特征,动态调整传输策略,从而将AI工作负载效率提升最高6倍。
该规范旨在为大规模AI与高性能计算(HPC)数据中心制定标准化网络传输与流控协议,通过硬件加速、智能拥塞控制等技术,解决传统以太网在超大规模集群中的性能短板。AMD推出的Pensando Pollara 400Gbps网卡作为业界首款符合UEC标准的网络接口卡,标志着以太网在AI网络领域的技术突破。
一、UEC技术框架:从理论到实践的标准化革新
1.1 UEC的核心设计目标与架构基础
UEC架构基于Linux联合开发基金会(JDF),作为标准开发组织(SDO),其核心目标是为以太网NIC与交换机提供传输层和流控层优化,以适配数万节点规模的AI/HPC集群。其技术框架具有以下特点:
-
传输层优化:确保数据从源到目的地的可靠传输,支持现代AI工作负载所需的RDMA、原子操作等高级指令
-
流控层创新:通过高效负载均衡、选择性重传和路径感知拥塞控制(UEC-CC),实现微秒级延迟控制
-
硬件加速:基于Open Fabric Interfaces(LibFabric)开源API,将软件协议栈卸载至NIC硬件执行
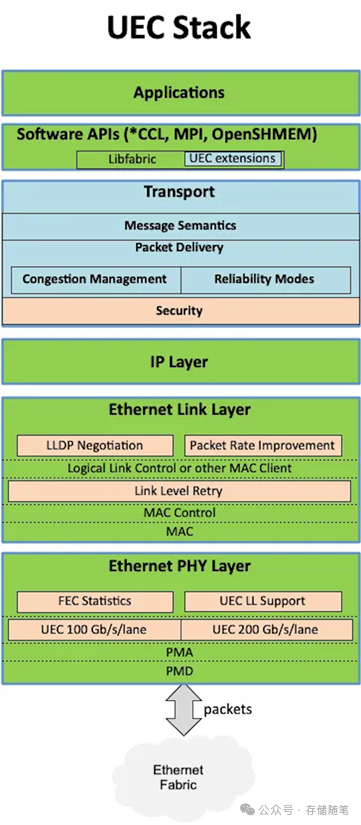
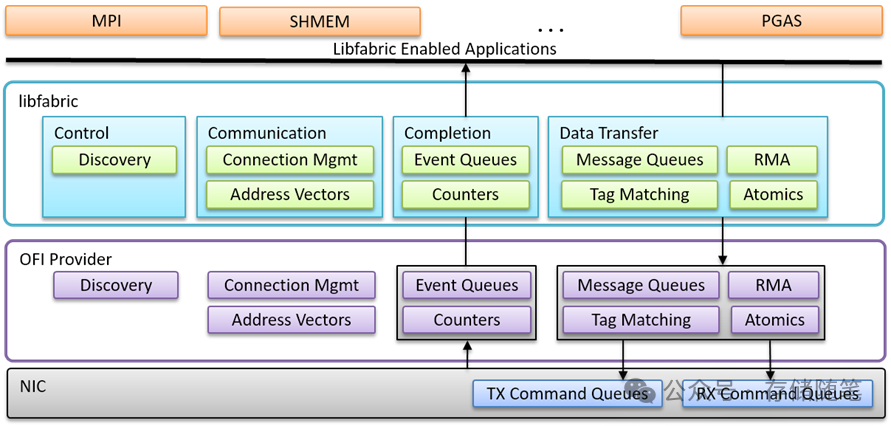
LibFabric作为UEC的关键技术基石,标准化了NIC的使用方式,通过命令队列机制(发送、接收、RDMA等)实现与CPU/GPU的高效交互。UEC将LibFabric从软件层下沉至NIC硬件加速,使数据处理延迟降低50%以上。
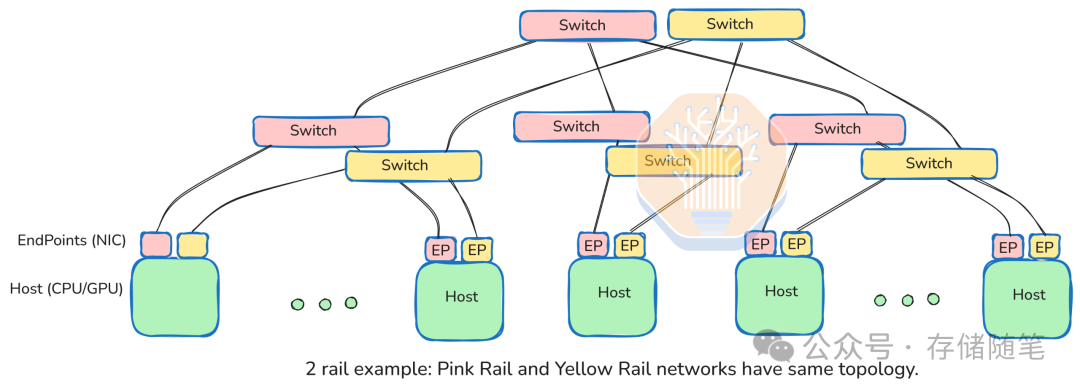
1.2 Packet Layer设计:智能路由与流量分发机制
UEC规范的包层设计借鉴了模块化交换机的实践经验,核心包括:
-
多路径流量喷涂(Traffic Spraying):通过"熵值(Entropy)"哈希算法,将数据流分散到多个物理路径(如8条100Gbps通道),实现400Gbps全带宽利用。以双轨(Dual Rail)架构为例,单个NIC可通过8个100Gbps接口连接8台512端口交换机,形成512×8的并行传输网络
-
动态路径调整:实时监测各路径负载,自动将流量从拥塞路径重路由至空闲路径,避免网络瓶颈
-
轻量级Packet header设计:标准Packet header为44字节,优化后短包仅20字节,在100Gbps速率下传输延迟仅1.6ns
这种设计使UEC在保持以太网兼容性的同时,实现了接近InfiniBand的低延迟性能,且无需修改上层应用代码,仅通过NIC硬件自动处理多路径分发。
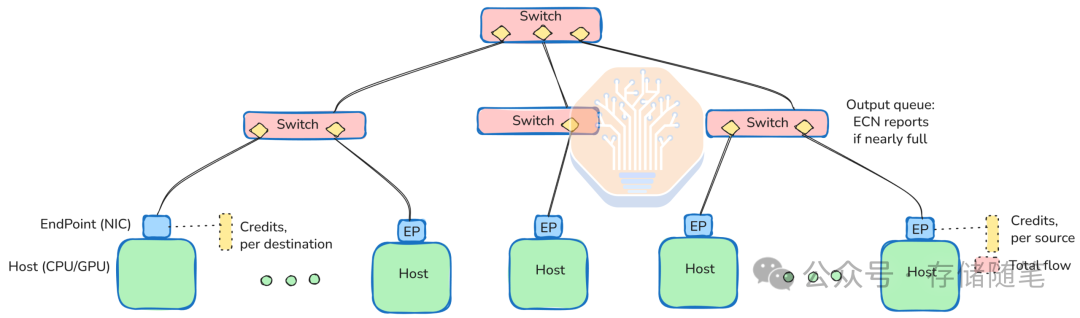
1.3 拥塞控制UEC-CC:超越传统RoCE的革命性机制
UEC-CC作为UEC的核心创新,采用时间基准的双向拥塞监测,具有以下技术突破:
-
亚500ns精度时延测量:发送端与接收端独立测量往返时延,准确定位拥塞节点
-
显式拥塞通知(ECN)增强:要求交换机按流量类别标记ECN,接收端通过Credit CP命令动态调整发送端速率,响应时间控制在微秒级
-
智能流控策略:弃用传统RoCE/DCQCN/PFC等低效机制,采用基于信用的流控(Credit-Based Flow Control),避免链路阻塞
-
丢包快速恢复:通过序列号检测丢包,发送特定请求包触发重传,适用于数据中心极低丢包率场景(<10^-12)
测试数据显示,UEC-CC相比传统RoCEv2可提升25%的RDMA性能,在10万节点规模集群中,时延抖动控制在5%以内。
1.4 安全子层与可扩展架构
UEC的传输安全子层集成后量子加密算法,支持按域(Domain)加密通信,单个Job可包含数万个端点,