深度学习入门知识
1. 均方误差
Mean Squared Error, 简称 MSE
均方误差损失是在监督学习中,特别是在回归问题中经常使用的一种损失函数。它计算了预测值与真实值之间差异的平方的平均值,用于衡量模型预测的准确性。
MSE 损失的数学表示表达式定义如下:
M S E = 1 n ∑ k n ( y k − t k ) 2 (1) MSE = \frac{1}{n} \sum_k^n (y_k-t_k)^2 \tag{1} MSE=n1k∑n(yk−tk)2(1)
y k y_k yk 是表示神经网络的输出, t k t_k tk 是表示监督数据, k k k 表示数据的维数。
由于误差被平方,因此较大的误差会受到更重的惩罚。这有助于模型在训练过程中减少较大的预测误差。MSE 损失函数在整个定义域上连续可微,这一特性使得使用基于梯度的优化算法(如梯度下降法)求解时更加高效。
2. Huber
Huber Loss,,又称为Smooth L1 Loss, 是一种在回归任务中常用的损失函数,它是平方误差损失(squared loss)和绝对误差损失(absolute loss)的结合。这种损失函数主要用于减少异常值(outliers)在训练模型时的影响,从而提高模型的鲁棒性。
Huber Loss函数通过一个参数 δ \delta δ 来定义,该参数决定了损失函数从平方误差向绝对误差转变的点。具体的数学表达式为:
L δ ( y , f ( x ) ) = { 1 2 ( y − f ( x ) ) 2 i f ∣ y − f ( x ) ∣ ≤ δ δ ∣ y − f ( x ) ∣ − 1 2 δ 2 o t h e r w i s e (2) L_{\delta}(y,f(x))= \begin{cases} \frac{1}{2}(y-f(x))^2 & \mathrm{if}|y-f(x)|\leq\delta\\ \delta|y-f(x)|-\frac{1}{2}\delta^2 & \mathrm{otherwise} & \end{cases} \tag{2} Lδ(y,f(x))={21(y−f(x))2δ∣y−f(x)∣−21δ2if∣y−f(x)∣≤δotherwise(2)
Huber Loss 通常用于回归问题,尤其是当数据中可能包含异常值时。
3. 交叉熵误差
Cross-Entropy Loss
在机器学习领域,尤其是分类问题中,扮演了重要的角色。它主要用于衡量两个概率分布之间的差异,通常用于评估模型预测的概率分布与实际标签的概率分布之间的距离。
对于多分类任务:

真实标签通常使用 One-Hot 编码,可简化为
L = − 1 N ∑ i = 1 N l o g ( y ^ i , c i ) (3) L=-\frac{1}{N} \sum_{i=1}^N log(\hat{y}_{i,c_i}) \tag{3} L=−N1i=1∑Nlog(y^i,ci)(3)
One-Hot 编码的特性: 在 y i y_i yi中只有一个元素是1(对应真实类别),其余都是0
L = − 1 N ∑ i = 1 N ∑ j = 1 C y i , j l o g ( y ^ i , j ) = − 1 N ∑ i = 1 N l o g ( y ^ i , c i ) L=-\frac{1}{N}\sum_{i=1}^N \sum_{j=1}^C y_{i,j} log(\hat{y}_{i,j})=-\frac{1}{N} \sum_{i=1}^N log(\hat{y}_{i,c_i}) L=−N1i=1∑Nj=1∑Cyi,jlog(y^i,j)=−N1i=1∑Nlog(y^i,ci)
y ^ i , c i \hat{y}_{i,c_i} y^i,ci 表示模型对样本 i 在其真实类别 c i c_i ci 上预测的概率。
交叉熵损失实际上就是对每个样本在其真实类别上预测概率的对数求平均,然后取负。
鱼书中的写法如下:
E = − ∑ k t k l o g y k (4) E = - \sum_k t_k\ log\ y_k \tag{4} E=−k∑tk log yk(4)
这里, l o g log log 表示以 e 为底数的自然对数( l o g e log_e loge)。 y k y_k yk 是神经网络的输出, t k t_k tk 是正确解标签。 并且, t k t_k tk 中只有正确解标签的索引为1, 其他均为0 (one-hot 表示)。
对于二分类任务:

当真实标签y=1时,损失为 L = − l o g ( y ^ ) L=-log(\hat{y}) L=−log(y^) 模型预测 y ^ \hat{y} y^ 越接近1,损失越小; y ^ \hat{y} y^ 越接近0,损失越大。
当真实标签y=0时,损失为 L = − l o g ( 1 − y ^ ) L = -log(1- \hat{y}) L=−log(1−y^) 模型预测 y ^ \hat{y} y^ 越接近0,损失越小; y ^ \hat{y} y^越接近1,损失越大。
4. 数值微分计算梯度
先从导数出发理解什么是梯度。某一点的导数直观理解就是在该点的切线的斜率。在数学中导数表示某个瞬时的变化量,如下公式表示:
d f ( x ) d x = lim h → 0 f ( x + h ) − f ( x ) h (5) \frac{\mathrm{d}f(x)}{\mathrm{d}x}=\lim_{h\to0}\frac{f(x+h)-f(x)}{h} \tag{5} dxdf(x)=h→0limhf(x+h)−f(x)(5)
上述利用微小的差分求导数的过程称为数值微分(numerical differentiation)上式表示的是前向差分( f ( x + h ) − f ( x ) f(x+h)-f(x) f(x+h)−f(x)),因为h无法无线趋近于0,所以存在误差(如下图所示)。为了减小这种数值微分误差,可以用中心差分( f ( x + h ) − f ( x − h ) f(x+h)-f(x-h) f(x+h)−f(x−h))减小误差。
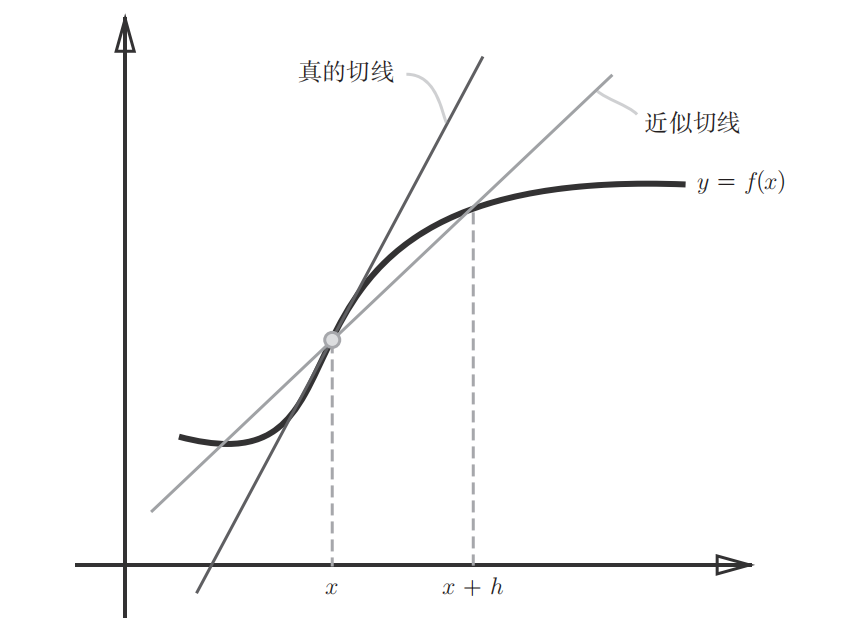
偏导数和梯度
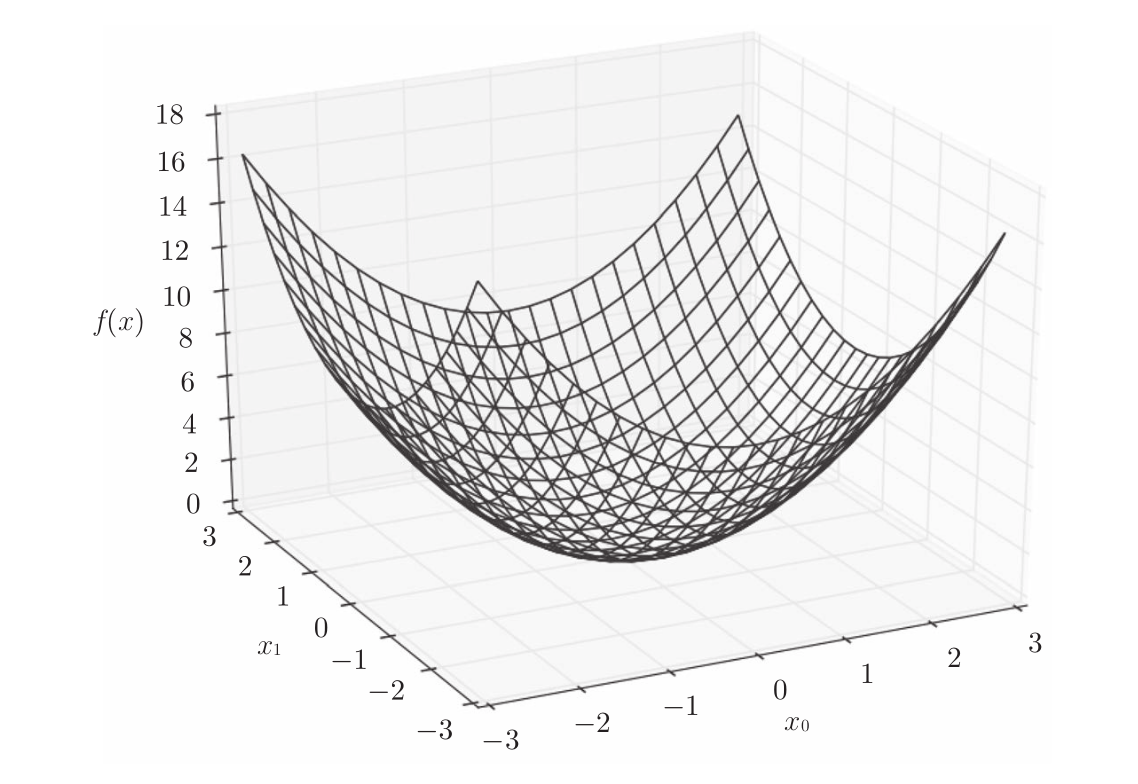
下式表示的是包含两个变量的函数,可以看为计算平面内点的坐标的平方和函数:
f ( x 1 , x 2 ) = x 1 2 + x 2 2 (6) f(x_1,x_2) = x_1^2+x_2^2 \tag{6} f(x1,x2)=x12+x22(6)
上式(6)中有两个变量,所以有必要区分对哪个变量求导数,即对 x 0 和 x 1 x_0和x_1 x0和x1两个变量中的哪一个求导数。另外,把这里讨论的有多个变量的函数的导数称为偏导数。用数学式表示的话,可以写成 ∂ f ∂ x 0 、 ∂ f ∂ x 1 \frac{\partial f}{\partial x_0}\mathrm{、}\frac{\partial f}{\partial x_1} ∂x0∂f、∂x1∂f。
求偏导数和求单变量的导数一样,都是求某个地方的斜率。不过,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。
5.梯度
那么如果需要一起计算 x 0 和 x 1 x_0和x_1 x0和x1的偏导数,应该如何求呢?比如,我们来考虑求 x 0 = 3 , x 1 = 4 x_0=3,x_1=4 x0=3,x1=4时( x 0 , x 1 x_0,x_1 x0,x1)的偏导数( ∂ f ∂ x 0 , ∂ f ∂ x 1 \frac{\partial f}{\partial x_0}\mathrm{,}\frac{\partial f}{\partial x_1} ∂x0∂f,∂x1∂f)。另外,像( ∂ f ∂ x 0 , ∂ f ∂ x 1 \frac{\partial f}{\partial x_0}\mathrm{,}\frac{\partial f}{\partial x_1} ∂x0∂f,∂x1∂f)这样的由全部向量的偏导数汇总而成的向量称为梯度 (gradient)。
如下图所示,式(6)的梯度呈现为有向向量(箭头)。观察下图,可以发现梯度指向函数 f ( x 1 , x 2 ) = x 1 2 + x 2 2 f(x_1,x_2) = x_1^2+x_2^2 f(x1,x2)=x12+x22 的“最低处”(最小值),就像指南针一样,所有的箭头都指向同一点。其次,可以发现离“最低处”越远,箭头越大。
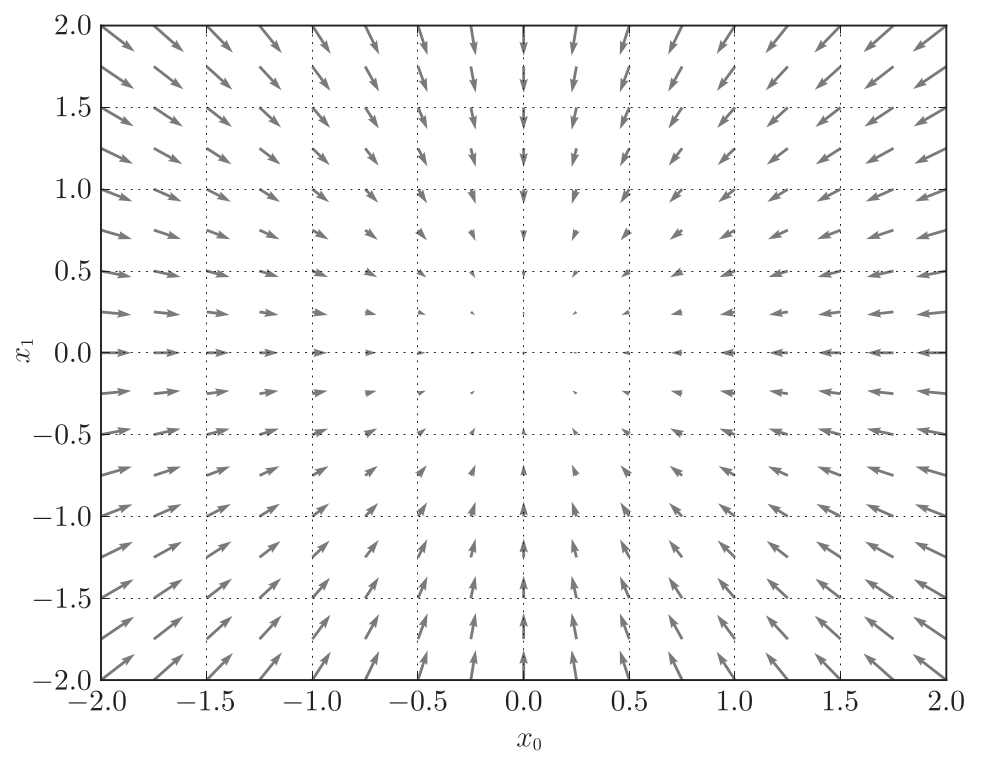
虽然上图中的梯度指向了最低处,但并非任何时候都这样。实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。这是一个非常重要的性质!
梯度法
机器学习的主要任务是在学习时寻找最优参数。同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。但是,一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
梯度表示的是各点处的函数值减小最多的方向。因此,无法保证梯度所指的方向就是函数的最小值或真正应该前进的方向。实际上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处。
函数的极小值、最小值以及被称为靶点(saddle point)的地方,梯度为 0.极小值是局部最小值,也就是限定在某个范围内的最小值。靶点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。虽然梯度法是要寻找梯度为0的地方,但是那个地方不一定就是最小值(也有可能是极小值或者靶点)。此外,当函数很复杂且呈扁平状时,学习可能会进入一个(几乎)平坦的地区,陷入被称为“学习高原”的无法前进的停滞期。
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法 (gradient method)。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络的学习中经常被使用。寻找最小值的梯度法称为梯度下降法,寻找最大值的梯度法称为梯度上升法。一般情况下,在神经网络中主要指的是梯度下降法,要最小化损失函数,最终得到最小值处对应的神经网络的权重和偏置,此时神经网络就被训练好了。
用数学式来表示梯度法,如下式所示:
x 0 = x 0 − η ∂ f ∂ x 0 x 1 = x 1 − η ∂ f ∂ x 1 (7) \begin{aligned} x_0 & =x_0-\eta\frac{\partial f}{\partial x_0} \\ x_1 & =x_1-\eta\frac{\partial f}{\partial x_1} \end{aligned} \tag{7} x0x1=x0−η∂x0∂f=x1−η∂x1∂f(7)
η \eta η 表示更新量,在神经网络的学习中,称为学习率(learning rate)。 学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
学习率需要事先确定为某个值,比如0.01或0.001。一般而言,这个值过大或过小对于损失函数的收敛都不利,因此选取合适的学习率也是神经网络超参数的一个重要部分。与神经网络的权重与偏置不同,学习率需要人为设定。
在神经网络中所说的梯度是指损失函数关于权重参数的梯度。比如,有一个只有形状为2x3的权重W的神经网络,损失函数用L表示。此时,梯度可以用 ∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L 表示。用数学式表示的话,如下式所示:
W = ( w 11 w 12 w 13 w 21 w 22 w 23 ) ∂ L ∂ W = ( ∂ L ∂ w 11 ∂ L ∂ w 12 ∂ L ∂ w 13 ∂ L ∂ w 21 ∂ L ∂ w 22 ∂ L ∂ w 23 ) (8) \begin{gathered} \boldsymbol{W}= \begin{pmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \end{pmatrix} \\ \begin{aligned} \frac{\partial L}{\partial\boldsymbol{W}} \end{aligned}= \begin{pmatrix} \frac{\partial L}{\partial w_{11}} & \frac{\partial L}{\partial w_{12}} & \frac{\partial L}{\partial w_{13}} \\ \frac{\partial L}{\partial w_{21}} & \frac{\partial L}{\partial w_{22}} & \frac{\partial L}{\partial w_{23}} \end{pmatrix} \end{gathered} \tag{8} W=(w11w21w12w22w13w23)∂W∂L=(∂w11∂L∂w21∂L∂w12∂L∂w22∂L∂w13∂L∂w23∂L)(8)
∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L 的元素由各个元素关于 W 的偏导数构成。
神经网络学习的步骤如下所示:
前提:神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”。神经网络的学习分成下面4个步骤。
step 1:mini-batch
从训练数据中随机选出一部分数据,这部分数据称为 mini-batch。我们的目标是减小mini-batch的损失函数的值。
step 2:计算梯度
为了减小 mini-bacth 的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
step 3:更新参数
将权重参数沿着梯度方向进行微小更新。
step 4:重复
重复step1、step2、step3.
神经网络的学习按照上面 4 个步骤进行。这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的 mini batch 数据,所以又称为随机梯度下降法 (stochastic gradient descent)。“随机”指的是“随机选择的”的意思,因此,随机梯度下降法是“对随机选择的数据进行的梯度下降法”。深度学习的很多框架中,随机梯度下降法一般由一个名为 SGD 的函数来实现。SGD 来源于随机梯度下降法的英文名称的首字母。
为了保证所有的训练数据都被使用,一般做法是事先将所有训练数据随机打乱,然后按指定的频次大小按序生成mini-batch。这样每个mini-batch均有一个索引号,然后索引号可以遍历所有的mini-batch。遍历一次所有数据,就称为一个epoch。
6. 误差反向传播法
数值微分虽然简单,也容易实现,但缺点是计算上比较费时间。而误差反向传播法是一个能够高效计算权重参数的梯度的方法。
**误差反向传播法(Back-propagation, BP)**算法的出现是神经网络发展的重大突破,也是现在众多深度学习训练方法的基础。该方法会计算神经网络中损失函数对各参数的梯度,配合优化方法更新参数,降低损失函数。
BP 本来只指损失函数对参数的梯度通过网络反向流动的过程,但现在也常被理解成神经网络整个的训练方法,由误差传播、参数更新两个环节循环迭代组成。
这里从鱼书中的角度学习误差方向传播法,基于计算图来理解误差反向传播法。
计算图:将计算过程用图形表示出来。
以鱼书中的例子来看。

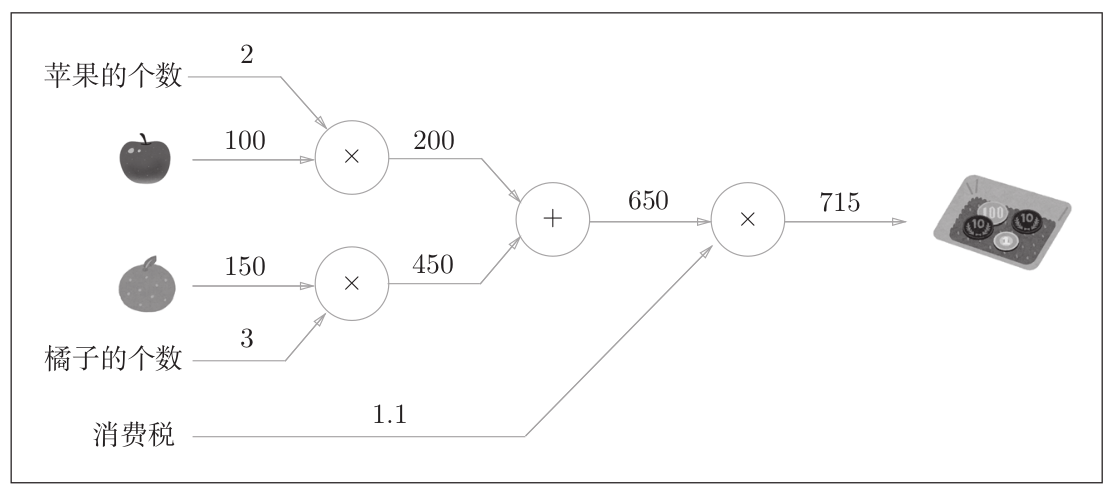
构建了计算图后,从左向右进行计算。就像电路中的电流流动一样,计算结果从左向右传递。到达最右边的计算结果后,计算过程就结束了。
1.构建计算图。
2.在计算图上,从左向右进行计算。
第2步中的“从左向右进行计算”是一种正方向上的传播,简称为正向传播(forward propagation)。正向传播是从计算图出发点到结束点的传播。反向(从图上看的话,就是从右向左)的传播,称为反向传播(backward propagation)。
计算图的特征是可以通过传递“局部计算”来获得最终结果。“局部”这个词的意思是“与自己相关的某个小范围”。局部计算是指,无论全局发生了什么,都能只根据与自己相关的信息输出接下来的结果。
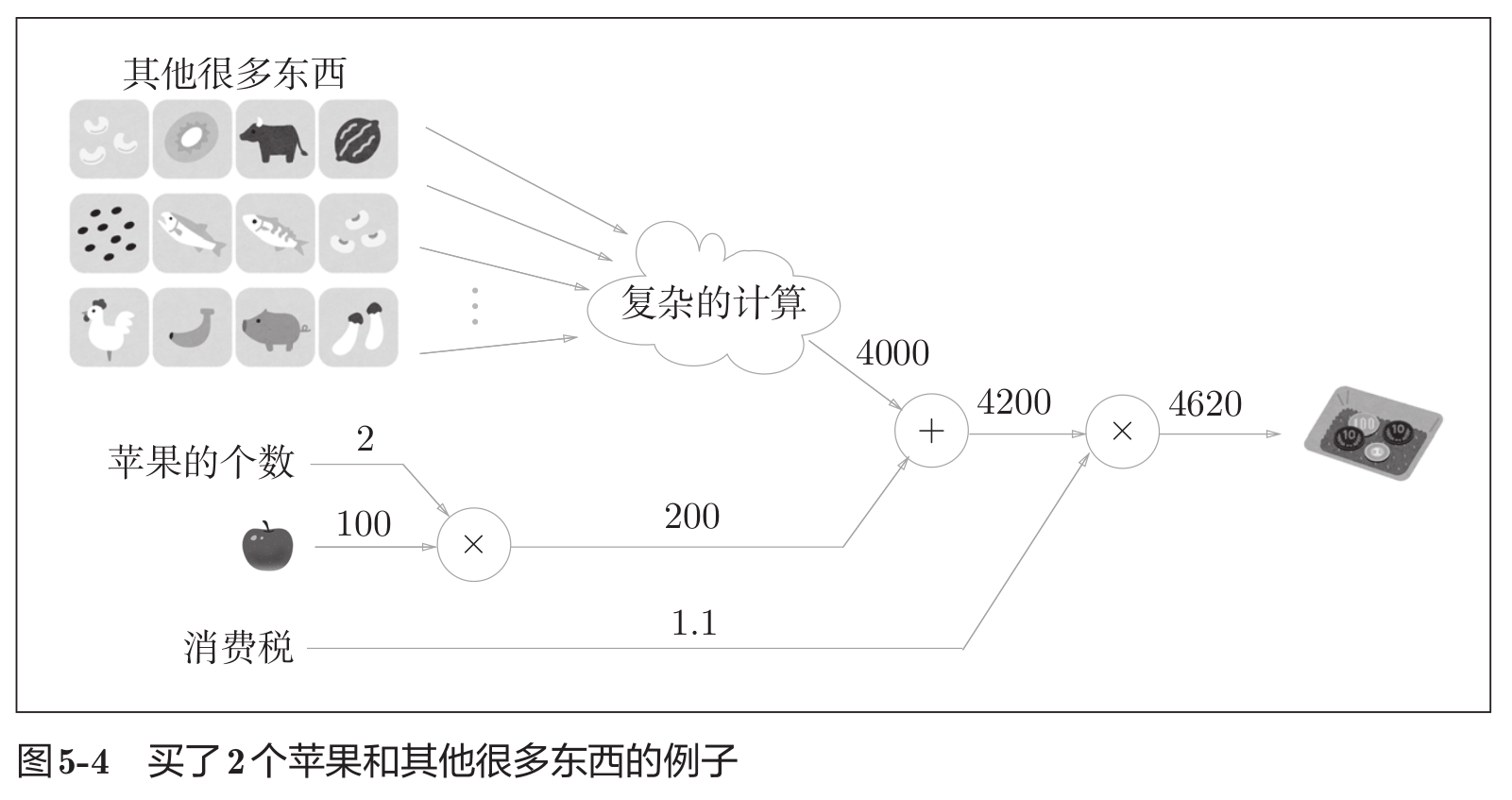
这里的重点是,各个节点处的计算都是局部计算。这意味着,例如苹果和其他很多东西的求和运算并不关心其他很多东西这一复杂的计算结果(如上图中的4000)是如何得到的,各个节点只需进行与自己有关的计算,不需要考虑全局。
计算图可以集中精力与局部计算。无论全局的计算有多么复杂,各个步骤所要做的就是对象节点的局部计算。虽然局部计算非常简单,但是通过传递它的计算结果,可以获得全局的复杂计算的结果。
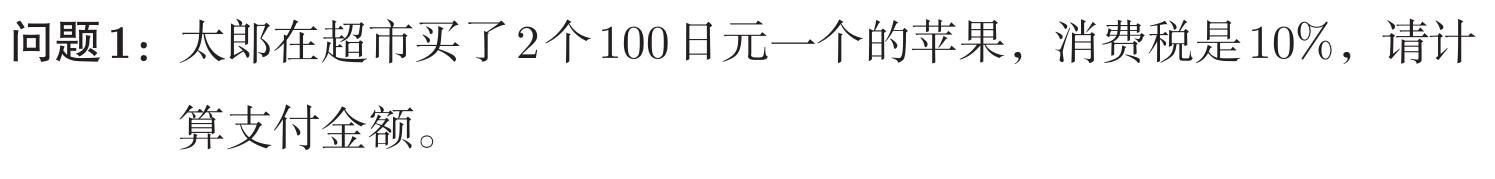
如果我们想要知道苹果价格的上涨会在多大程度上影响最终的支付金额,即求“支付金额关于苹果的价格的导数”。而这一导数的值可以通过计算图的反向传播求出来。
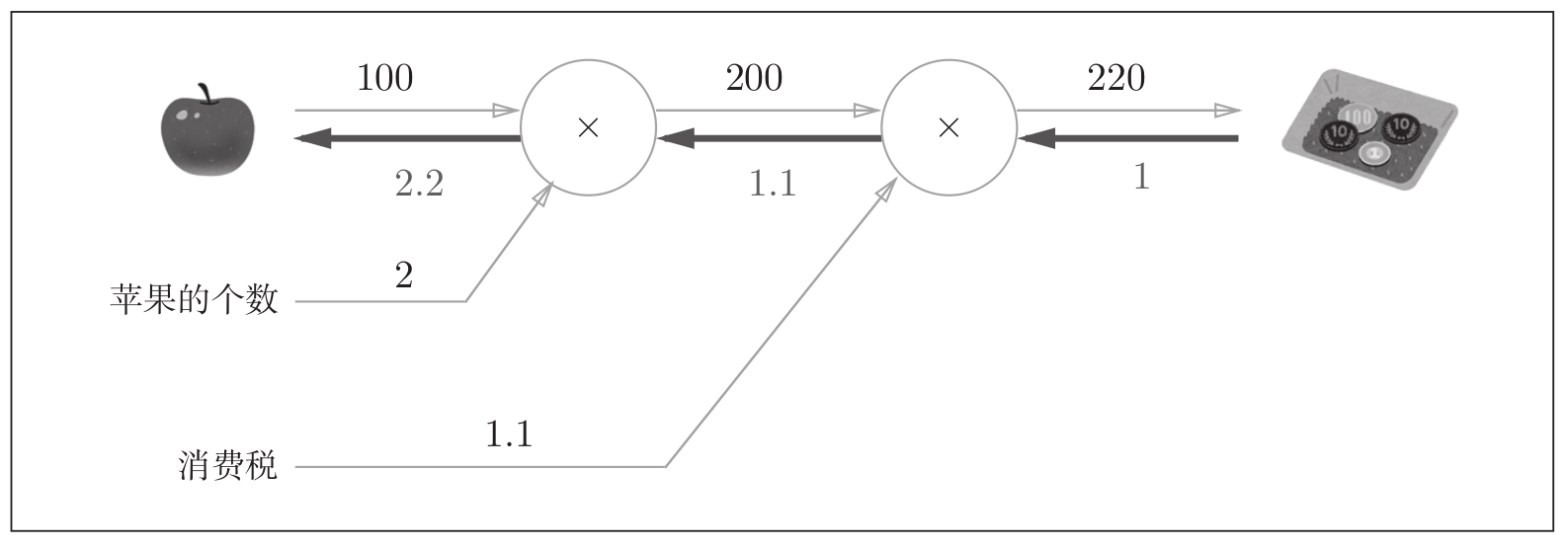
反向传播使用与正方向相反的箭头(粗线)表示。反向传播传递“局部导数”,将导数的值写在了箭头的下方。
计算图的优点就是可以通过正向传播和反向传播高效地计算各个变量的导数值。
链式法则
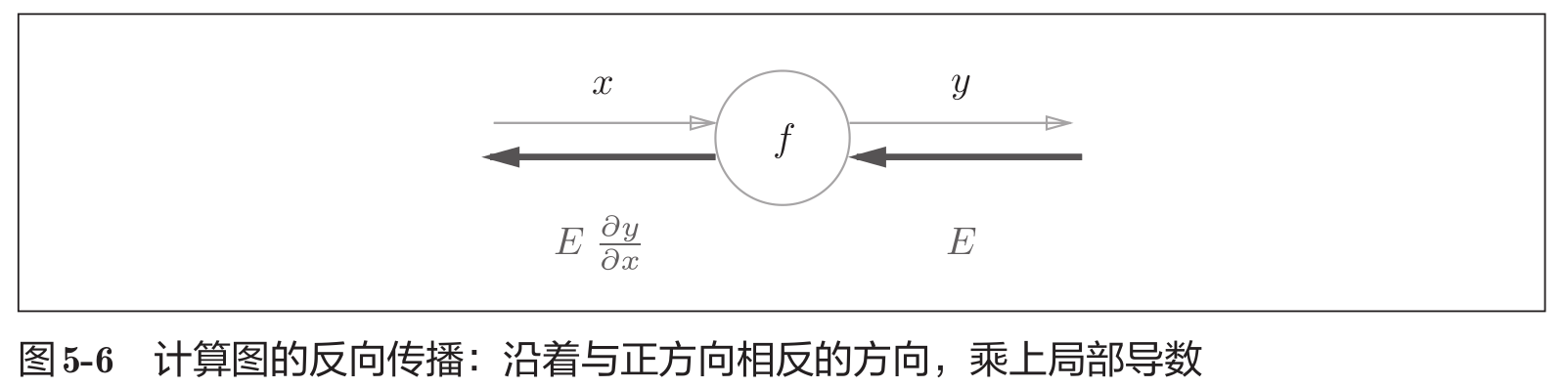
如图所示,反向传播的计算顺序是,将信号E乘以节点的局部导数( ∂ y ∂ x \frac{\partial y} {\partial x} ∂x∂y) ,然后将结果传递给下一个节点。这里所说的局部导数是指正向传播中 y = f ( x ) y=f(x) y=f(x)的导数,也就是y关于x的导数( ∂ y ∂ x \frac{\partial y}{\partial x} ∂x∂y)。
什么是链式法则呢?
复合函数是由多个函数构成的函数,而链式法则是关于复合函数的导数的性质,定义如下:
如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。
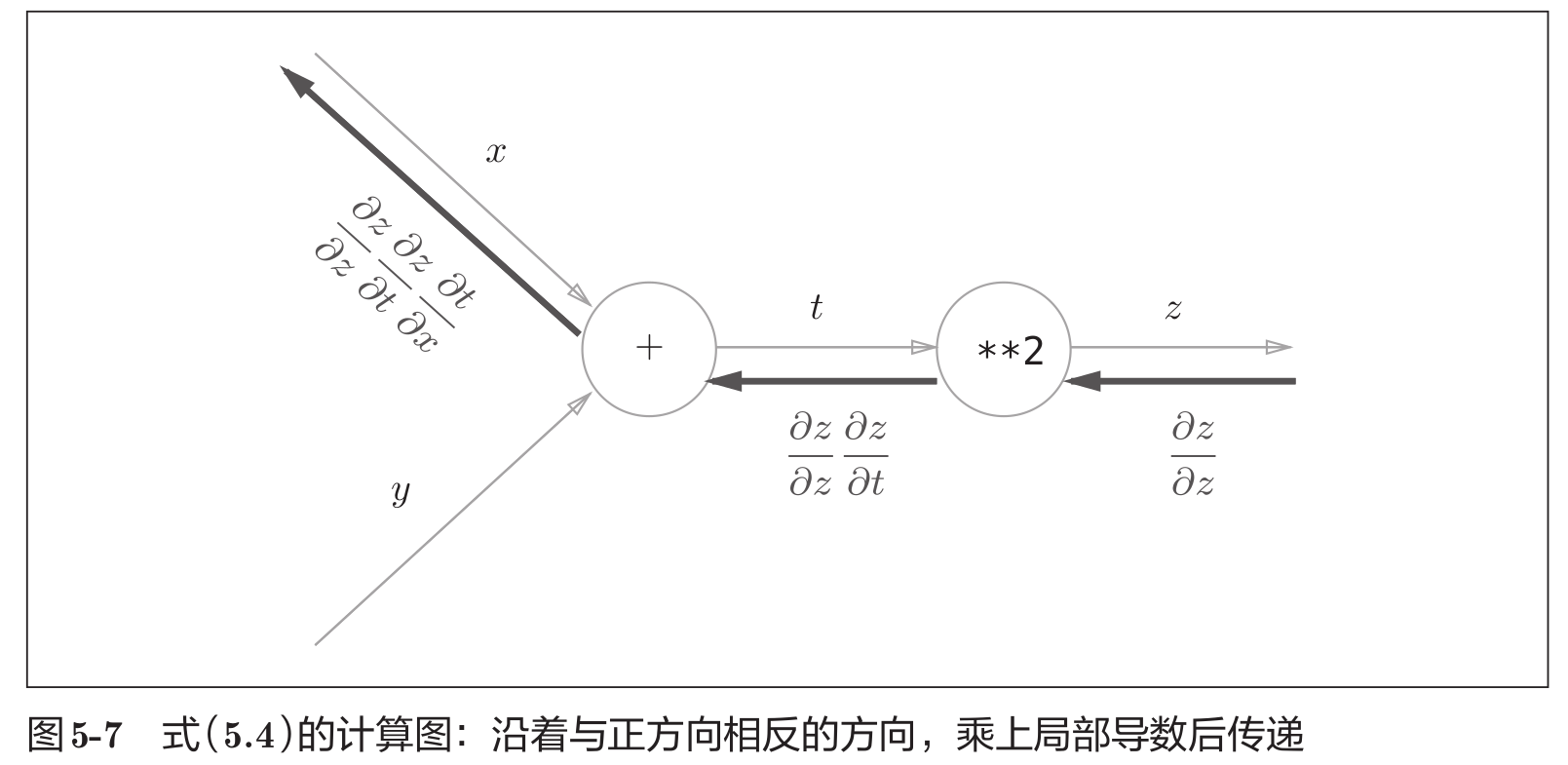
计算图的反向传播从右到左传播信号。反向传播的计算顺序是,先将节点的输入信号乘以节点的局部导数(偏导数),然后再传递给下一个节点。
计算图的反向传播是基于链式法则成立的。
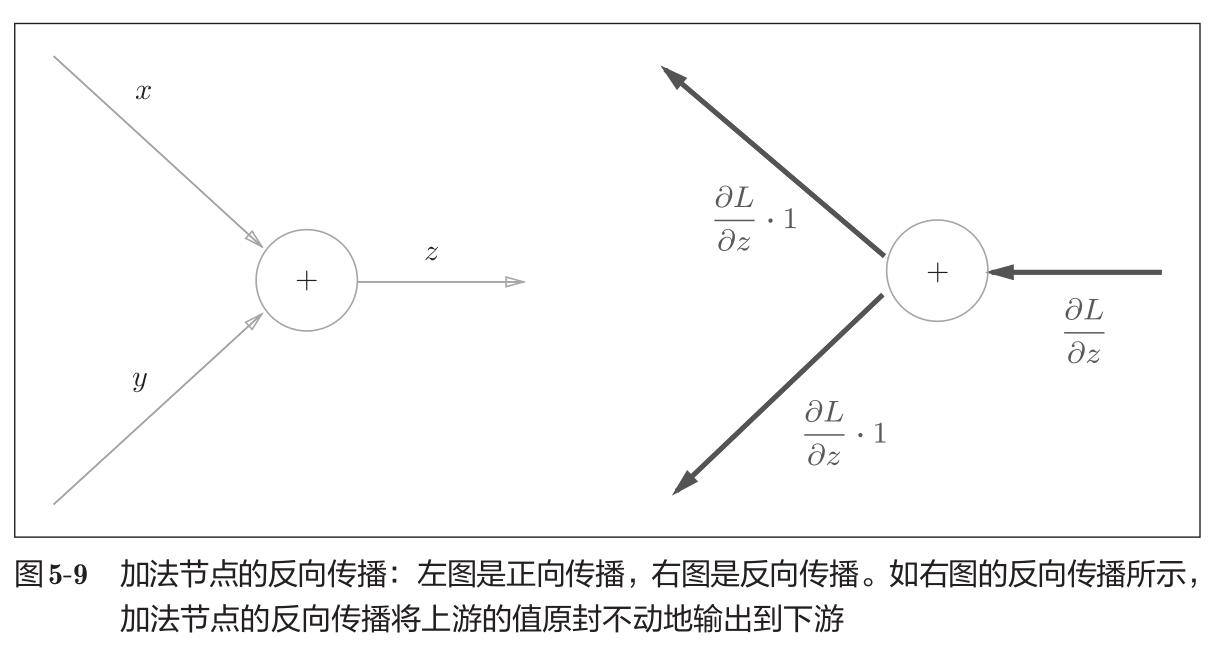
加法节点的反向传播:将输入的值原封不动地传向下一个节点,如下图所示。
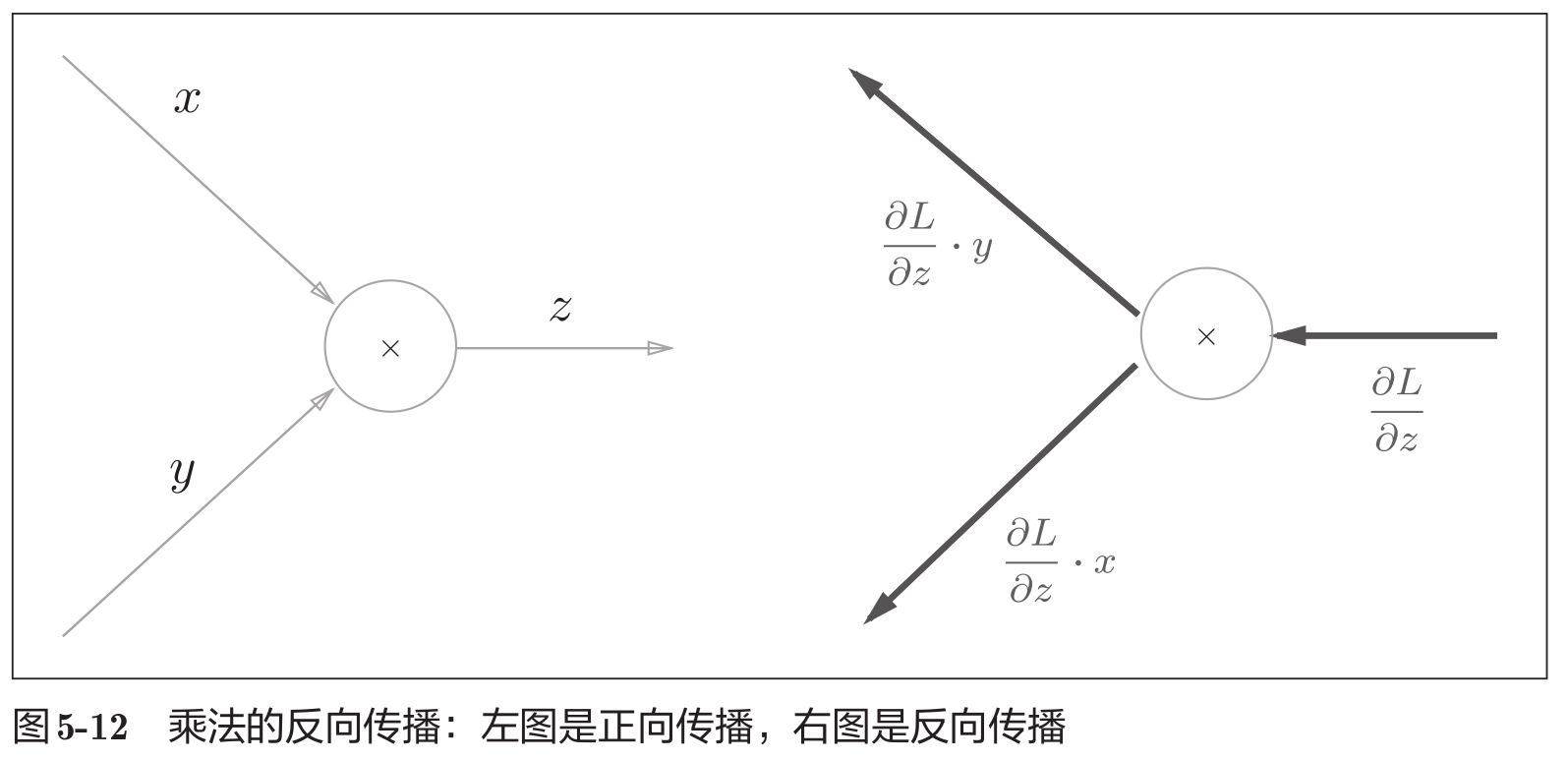
乘法节点的反向传播:将上游的值乘以正向传播时的输入信号的“翻转值”后传递给下游。翻转值表示一种翻转关系,如下图所示。实现乘法节点的反向传播时,要保存正向传播的输入信号。
激活函数层
ReLU层
ReLU (Rectified Linear Unit)由下式表示。
y = { x ( x > 0 ) 0 ( x ≤ 0 ) (9) y = \begin{cases} x & (x>0) \\ 0 & (x\leq0) \end{cases} \tag{9} y={x0(x>0)(x≤0)(9)
y关于x的导数,如下式所示
y = { 1 ( x > 0 ) 0 ( x ≤ 0 ) (10) y = \begin{cases} 1 & (x>0) \\ 0 & (x \leq 0) \end{cases} \tag{10} y={10(x>0)(x≤0)(10)
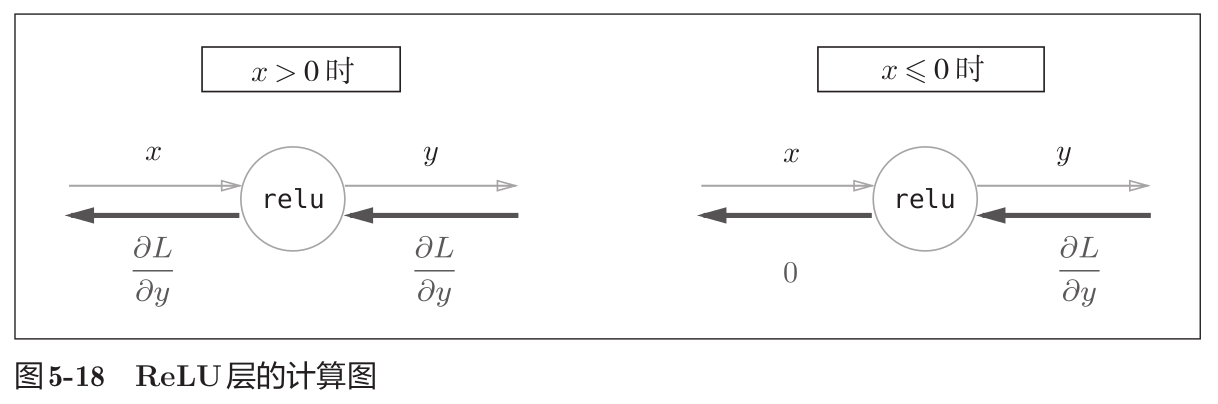
如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处。如下图所示。
Sigmoid层
Sigmoid函数由式(11)表示:
y = 1 1 + e x p ( − x ) (11) y = \frac{1}{1+exp(-x)} \tag{11} y=1+exp(−x)1(11)
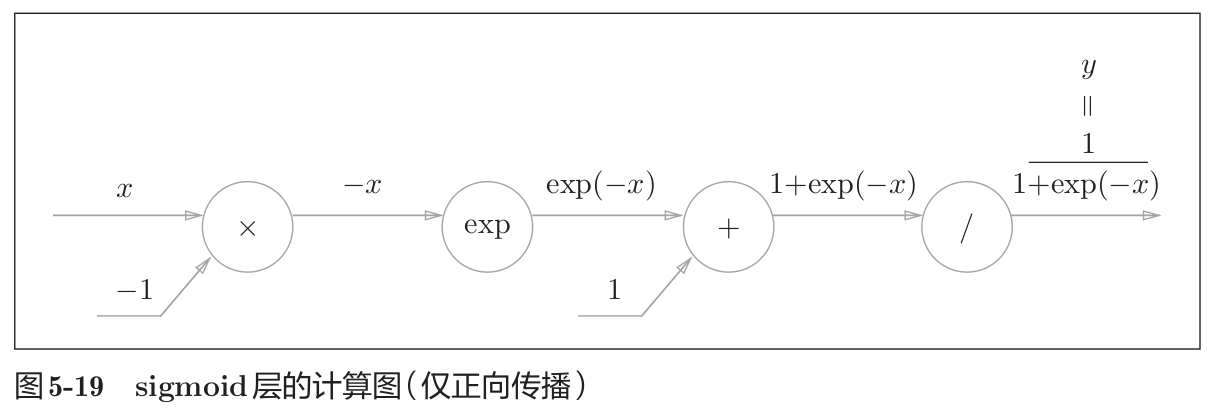
那么,Sigmoid函数如何进行反向传播呢?如下图所示。
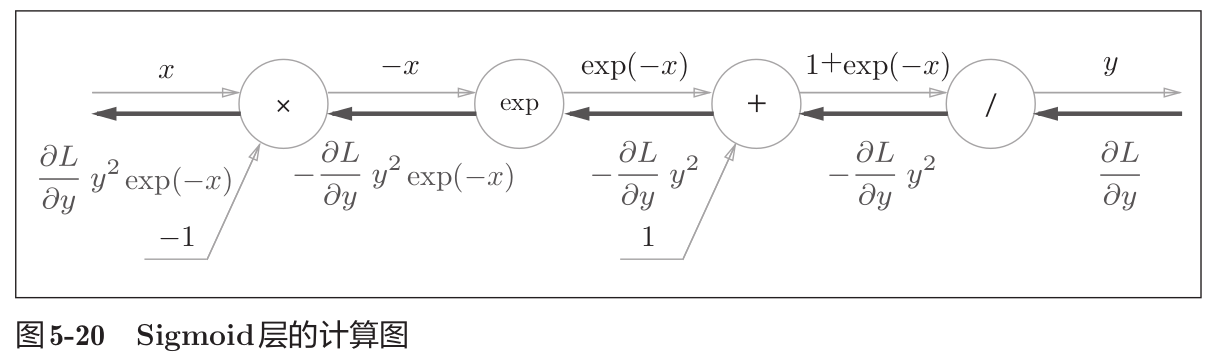
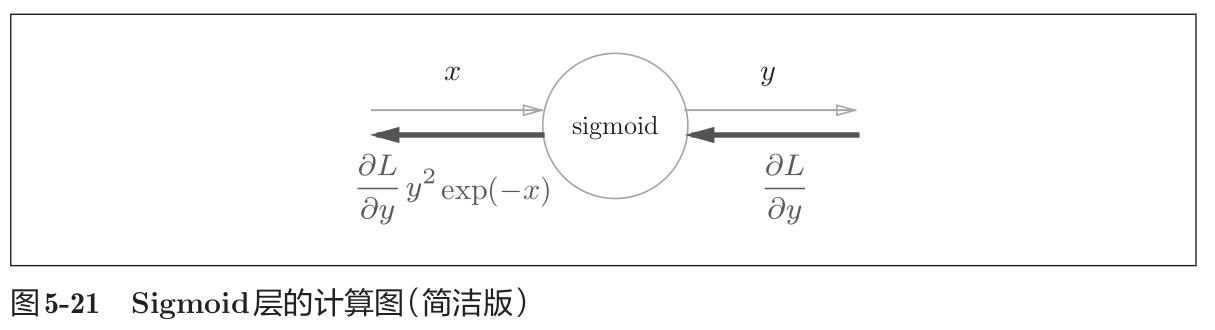
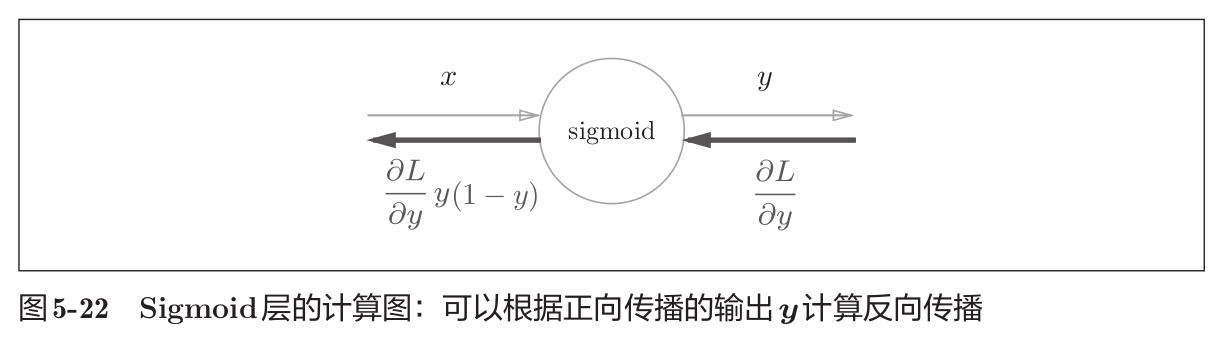
∂ L ∂ y y 2 exp ( − x ) = ∂ L ∂ y 1 ( 1 + exp ( − x ) ) 2 exp ( − x ) = ∂ L ∂ y 1 1 + exp ( − x ) exp ( − x ) 1 + exp ( − x ) = ∂ L ∂ y y ( 1 − y ) (12) \begin{aligned} \begin{aligned} \frac{\partial L}{\partial y}y^2\exp(-x) \end{aligned} & \begin{aligned} & =\frac{\partial L}{\partial y}\frac{1}{(1+\exp(-x))^2}\exp(-x) \end{aligned} \\ & =\frac{\partial L}{\partial y}\frac{1}{1+\exp(-x)}\frac{\exp(-x)}{1+\exp(-x)} \\ & =\frac{\partial L}{\partial y}y(1-y) \end{aligned} \tag{12} ∂y∂Ly2exp(−x)=∂y∂L(1+exp(−x))21exp(−x)=∂y∂L1+exp(−x)11+exp(−x)exp(−x)=∂y∂Ly(1−y)(12)
如上式可得
Affine 层
神经网络的正向传播中,为了计算加权信号的总和,使用了矩阵的乘积运算(Numpy 中是 np.dot())

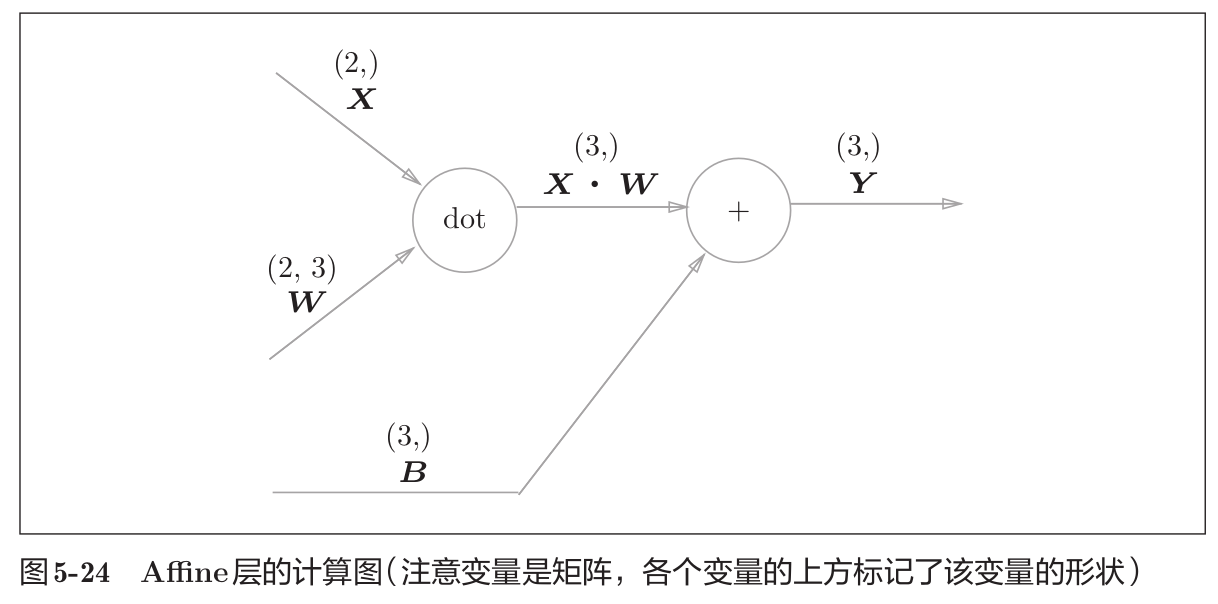
这里,X、W、B分别是形状为(2,)、(2,3)、(3,)的多维数组。这样一来,神经元的加权和可以用 Y = np.dot(X, W) + B 计算出来。然后,Y 经过激活函数转换后,传递给下一层。这就是神经网络正向传播的流程。矩阵的乘积运算的要点是使对应维度的元素个数一致。
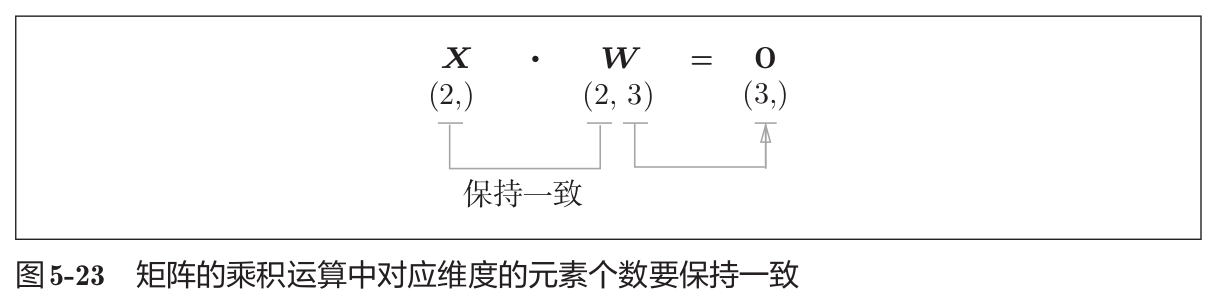
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”。
X、W、B是矩阵(多维数组),以矩阵为对象的反向传播,按矩阵的各个元素进行计算时,步骤和以标量为对象的计算图相同。
∂ L ∂ X = ∂ L ∂ Y ⋅ W T ∂ L ∂ W = X T ⋅ ∂ L ∂ Y (13) \frac{\partial L}{\partial\boldsymbol{X}}=\frac{\partial L}{\partial\boldsymbol{Y}}\cdot\boldsymbol{W}^\mathrm{T} \\ \frac{\partial L}{\partial\boldsymbol{W}}=\boldsymbol{X}^\mathrm{T}\cdot\frac{\partial L}{\partial\boldsymbol{Y}} \tag{13} ∂X∂L=∂Y∂L⋅WT∂W∂L=XT⋅∂Y∂L(13)
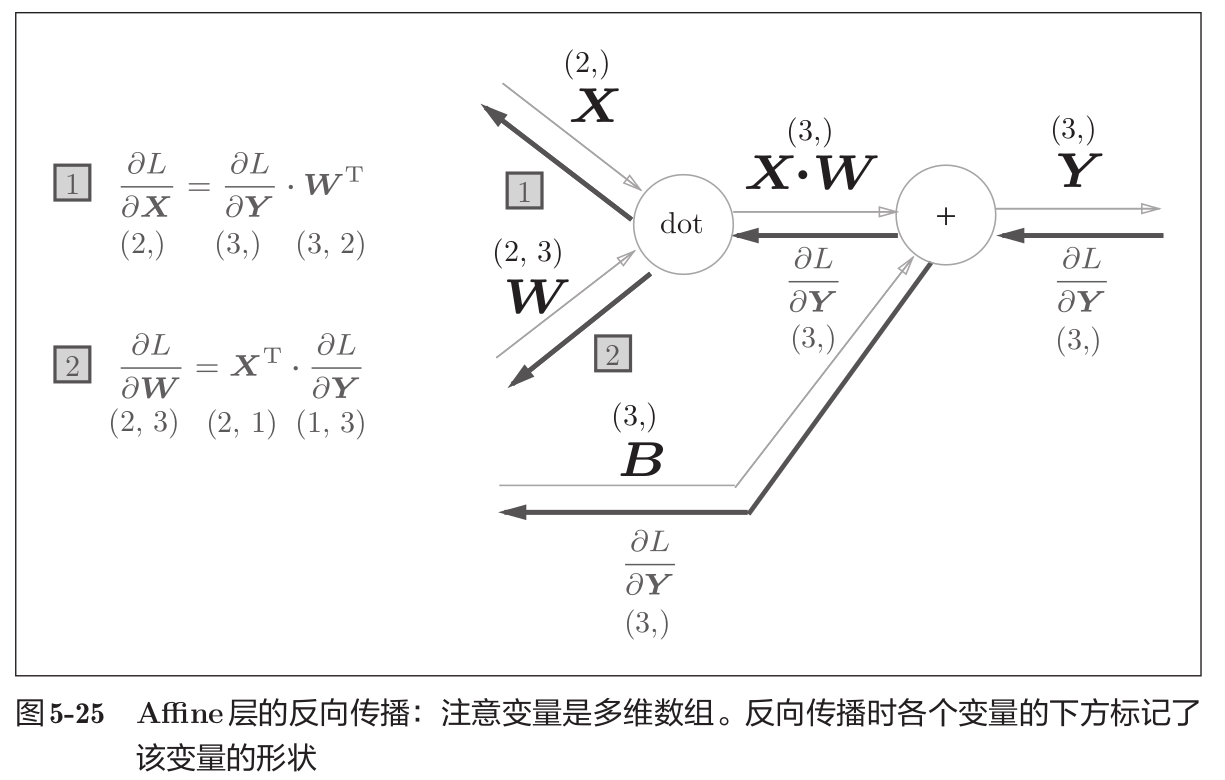
尤其要注意, X 和 ∂ L ∂ X X 和 \frac{\partial L}{\partial X} X和∂X∂L 形状相同, W 和 ∂ L ∂ W W 和 \frac{\partial L}{\partial W} W和∂W∂L 形状相同。
X = ( x 0 , x 1 , ⋯ , x n ) ∂ L ∂ X = ( ∂ L ∂ x 0 , ∂ L ∂ x 1 , ⋯ , ∂ L ∂ x n ) (14) \begin{aligned} & \boldsymbol{X}=(x_0,x_1,\cdots,x_n) \\ & \frac{\partial L}{\partial\boldsymbol{X}}=\left(\frac{\partial L}{\partial x_0},\frac{\partial L}{\partial x_1},\cdots,\frac{\partial L}{\partial x_n}\right) \end{aligned} \tag{14} X=(x0,x1,⋯,xn)∂X∂L=(∂x0∂L,∂x1∂L,⋯,∂xn∂L)(14)
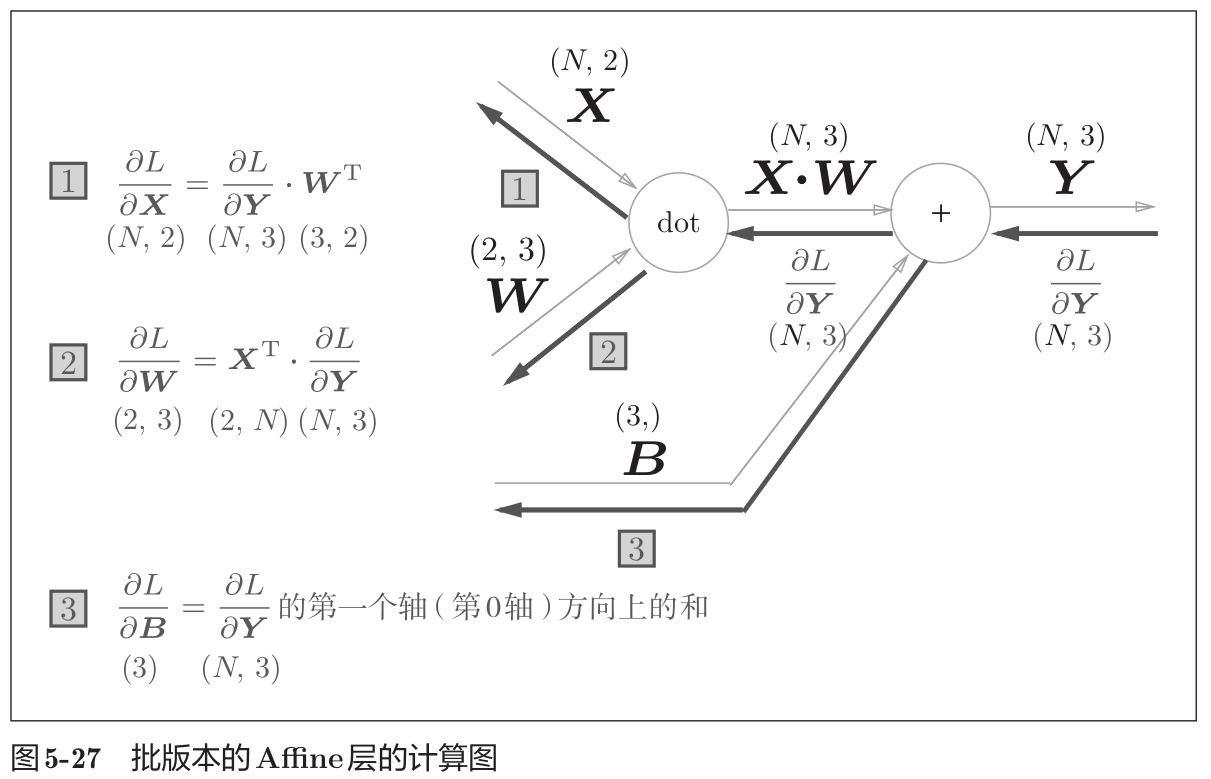
批版本的 Affine 层
前面介绍的 Affine 层的输入 X 是以单个数据为对象的。现在考虑N个数据一起进行正向传播的情况,也就是批版本的 Affine 层。
Softmax-with-Loss 层
softmax 函数会将输入值正规化之后再输出。比如手写数字识别时,Softmax 层的输出如图所示。

神经网络中进行的处理有推理(inference) 和学习两个阶段。神经网络的推理通常不使用 Softmax 层。当神经网络的推理只需要给出一个答案的情况下,因为此时只对得分最大值感兴趣,所以不需要 Softmax 层。不过,神经网络的学习阶段则需要 Softmax 层。
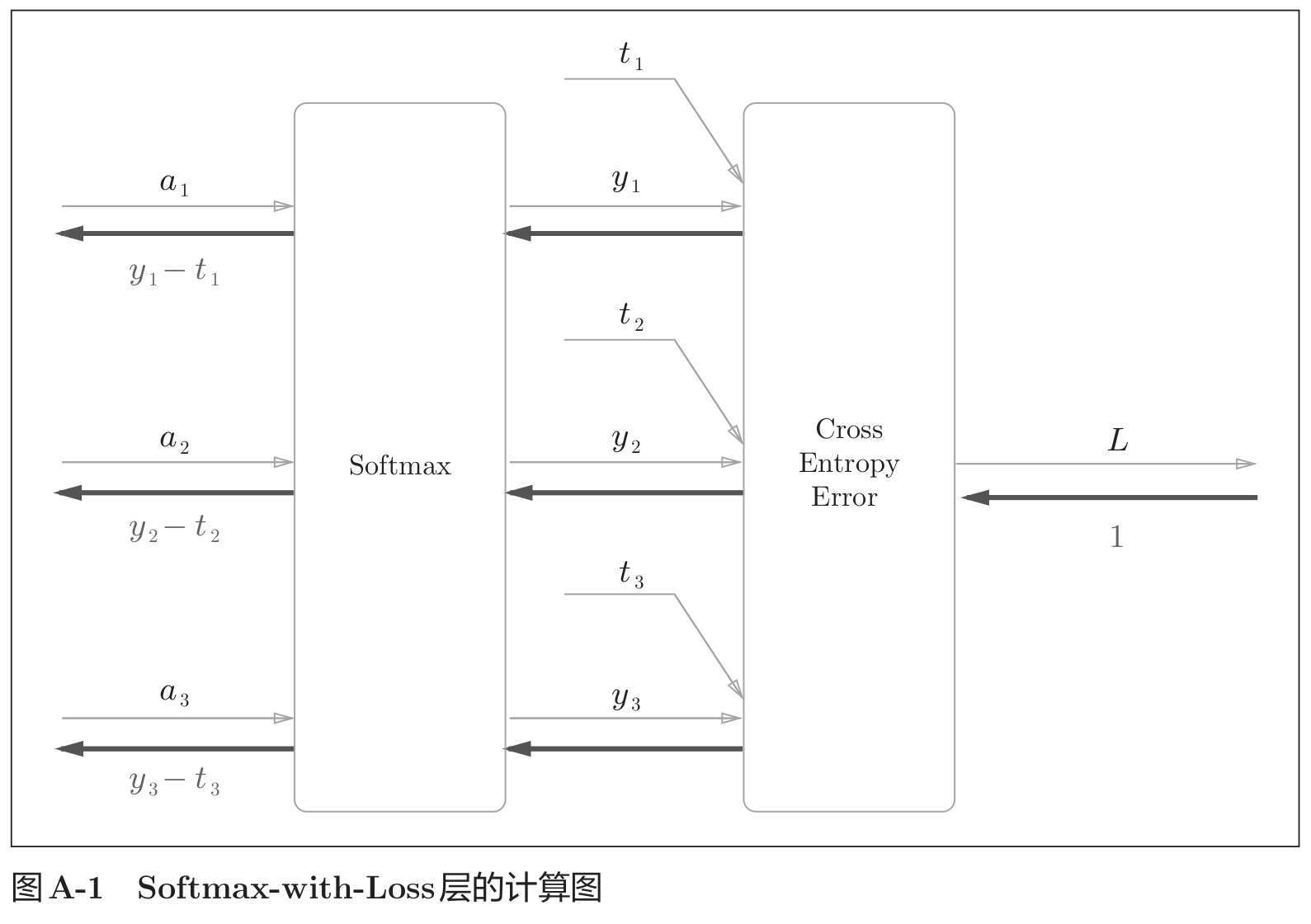
Softmax 层:softmax 函数可由下式表示。
y k = e x p ( a k ) ∑ i = 1 n e x p ( a i ) (15) y_k = \frac{exp(a_k)}{\sum_{i=1}^n exp(a_i)} \tag{15} yk=∑i=1nexp(ai)exp(ak)(15)
Cross Entropy Error层:交叉熵误差可由下式表示。
L = − ∑ k t k l o g y k (16) L = -\sum_k t_k log \ y_k \tag{16} L=−k∑tklog yk(16)
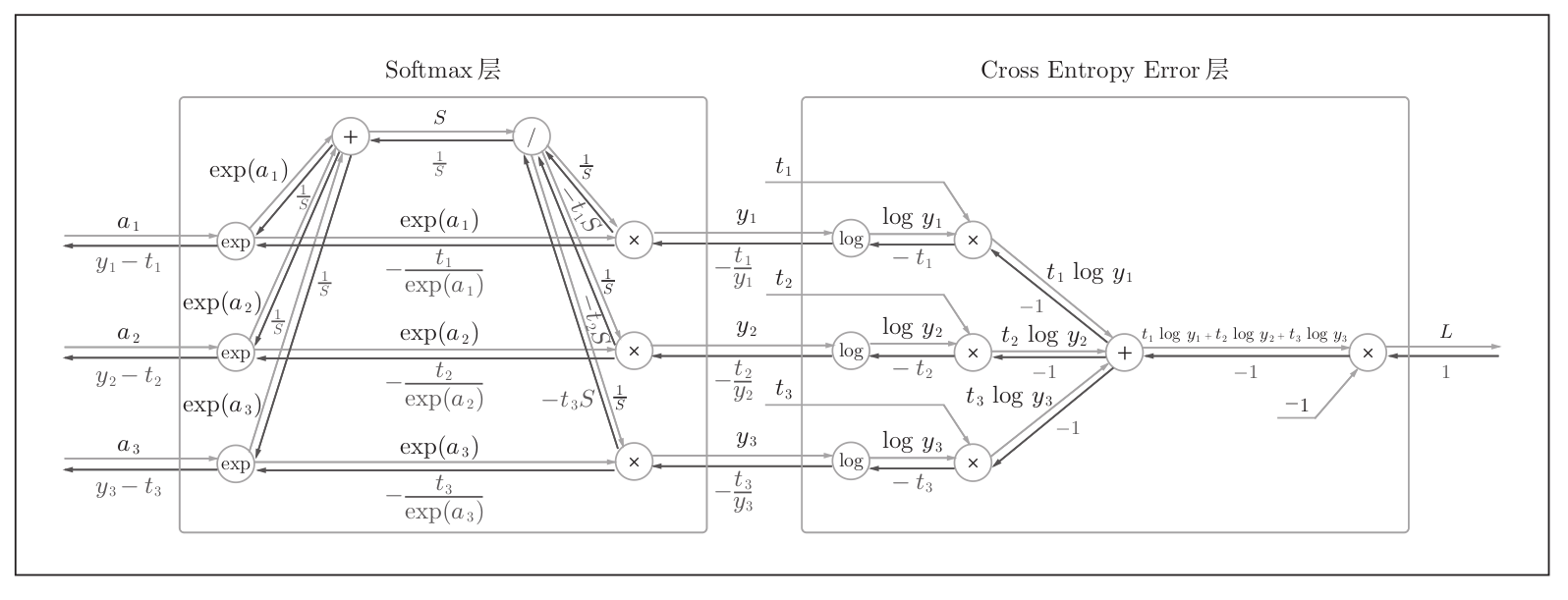
Softmax 层的反向传播得到了 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1-t_1, y_2-t_2, y_3-t_3) (y1−t1,y2−t2,y3−t3)这样“漂亮”的结果。由于 ( y 1 , y 2 , y 3 ) (y_1,y_2,y_3) (y1,y2,y3)是 Softmax 层的输出, ( t 1 , t 2 , t 3 ) (t_1,t_2,t_3) (t1,t2,t3)是监督数据,所以 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1-t_1, y_2-t_2, y_3-t_3) (y1−t1,y2−t2,y3−t3) 是 Softmax 层的输出和教师标签的差分。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
神经网络学习的目的就是通过调整权重参数,使神经网络的输出(Softmax的输出)接近教师标签。因此,必须将神经网络的输出与教师标签的误差高效地传递给前面的层。刚刚的 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1-t_1, y_2-t_2, y_3-t_3) (y1−t1,y2−t2,y3−t3) 正是 Softmax 层的输出与教师标签的差,直接表示了当前神经网络的输出与教师标签的误差。
7. 过拟合
在机器学习中,过拟合是一个很常见的问题。**过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。**机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的为观测数据,也希望模型可以进行正确的识别。
为什么深度学习容易过拟合呢?简单地说,深度神经网络通常拥有大量的参数(权重),这使得它们具备极强的学习能力(“容量”高)。如果训练数据不够多或者不够多样化,或者训练时间太长,模型就容易“记住”训练数据,而不是“理解”它。
发生过拟合的原因主要有以下两个:
- 模型拥有大量参数、表现力强。
- 训练数据少。
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。
对于所有权重,权值衰减方法都会为损失函数加上 $\frac{1}{2} \lambda W^2 。因此,在求权重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数 。因此,在求权重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数 。因此,在求权重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数\lambda W$。
Dropout
Dropout 是一种非常简单、高效且被广泛使用的正则化技术,专门用于减少深度神经网络中的过拟合。
Dropout 是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递,如下图所示。
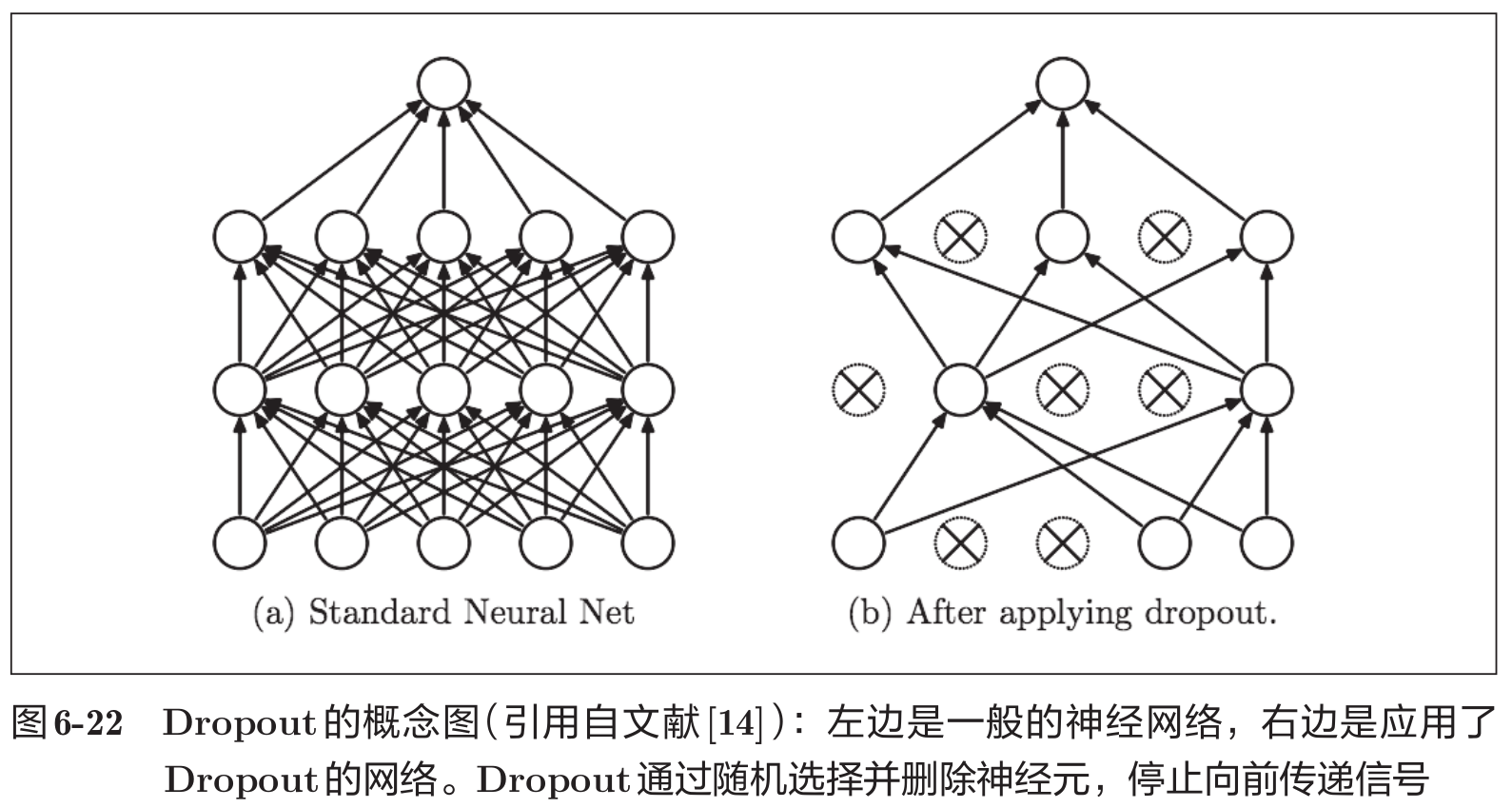
训练时,每传递一次数据,就会随机选择要删除的神经元。然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出。
下面对Dropout进行详细展开。
训练阶段:
1.随机选择:对于网络中的每一层(通常是隐藏层,有时输入层也适用,输出层一般不使用),在每次训练样本(或小批量)的前向传播过程中,以预先设定的概率 p (dropout rate),独立地、随机地决定是否“删除”该层中的每个神经元。
- p 是一个超参数,表示一个神经元被丢弃的概率。通常设置在 0.2~0.5 之间。例如,p=0.5表示每个神经元有 50% 的几率在本次前向传播中被丢弃。
- 这个随机选择通常通过伯努利随机变量(Bernoulli Random Variables)来实现,为每个神经元生成一个0(删除)或1(保留)的掩码。
2.关闭神经元:被选中的神经元会被临时移除。具体来说:
- 该神经元的输出值被强制设置为0。
- 与该神经元相关的所有输入和输出连接在本次前向传播中也被临时切断。
3.前向传播:仅使用未被丢弃的神经元(“子网络”)进行本次训练样本的前向传播计算损失。
4.反向传播:仅通过这个被“瘦身”的网络进行误差反向传播和参数(权重)更新。只有未被丢弃的神经元的权重会在本次迭代中得到更新。
5.重复:处理下一个训练样本(或小批量)时,重新随机生成一组新的丢弃掩码。这意味着每次迭代,网络的结构都在随机变化。
预测阶段(测试/推理阶段):
1.使用完整网络:在模型部署或评估时,不再丢弃任何神经元。使用完整的、训练好的网络进行预测。
2.权重缩放:这里有一个关键点。因为在训练时,每个神经元只以1-p的概率被激活(保留)。为了保证在预测时,神经元输出的期望值(均值)与训练时一致,需要对神经元的权重进行缩放。
- 最常见的方法:在预测时,将该层每个神经元的输出权重乘以保留概率(1-p)。
- 另一种等价方法(Inverted Dropout):在训练时,对未被丢弃的神经元的输出进行放大,即乘以1/(1-p)。这样在预测时使用完整网络且不做任何缩放,神经元的期望输出值就与训练时一致了。这种方法在实践中更常用,因为它只在训练时增加一次计算,预测时不需要额外操作。
Dropout 为什么能防止过拟合?Dropout 通过以下几种机制有效减少过拟合:
1.打破复杂的协同适应: 这是最主要的原因。神经网络中,某些神经元之间可能形成复杂的依赖关系(协同适应),这些依赖在训练数据上很有效,但在新数据上很脆弱。Dropout 强制每个神经元不能过度依赖少数特定的其他神经元,因为它依赖的伙伴随时可能被“丢弃”。这促使神经元学习更鲁棒的特征,这些特征在多种随机子网络组合下都有效。
2.模型平均(近似): Dropout 可以被视为一种高效的模型平均形式。每次迭代训练一个不同的随机子网络。最终用于预测的完整网络,可以看作是对所有这些可能的子网络预测结果的一种加权平均。平均多个不同的模型通常能显著提高泛化能力并减少方差(过拟合)。
3.引入噪声: Dropout 在训练过程中向激活函数注入了随机噪声。这可以被看作是一种正则化形式,迫使模型对输入的小扰动不那么敏感,从而学习更泛化的特征。
4.隐式的特征组合: 由于神经元被随机丢弃,网络被迫在每次前向传播中使用不同的特征组合。这鼓励了特征的冗余表示和更丰富的组合方式。
8. 几个网络
VGG 是由卷积层和池化层构成的基础的CNN,它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16” 或 “VGG19”)。
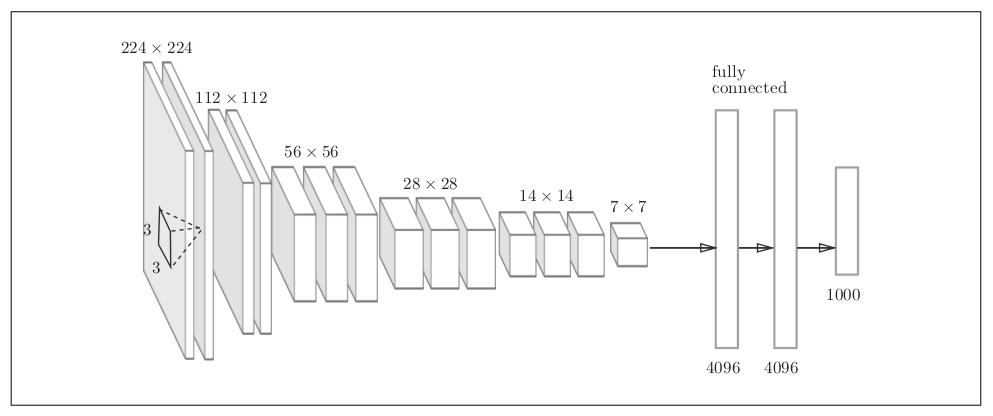
VGG中需要注意的地方是,基于3x3的小型滤波器的卷积层的运算是连续运行的。重复进行“卷积层叠加2次到4次,再通过优化池化层将大小减半”的处理,最后经由全连接层输出结果。
GoogLeNet 的网络结构如图所示, 图中的矩形表示卷积层、池化层等。
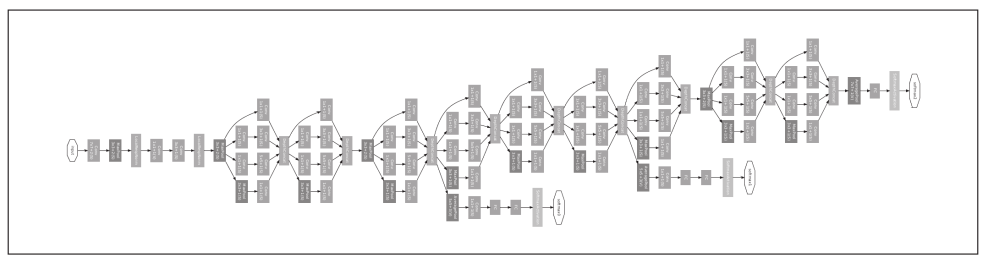
与之前介绍的CNN结构相同,不过,GoogLeNet 的特征是,网络不仅在纵向上有深度,在横向上也有深度(广度)。
GoogLeNet在横向上有“宽度”,这就称为“Inception”结构,以下图所示的结构为基础。
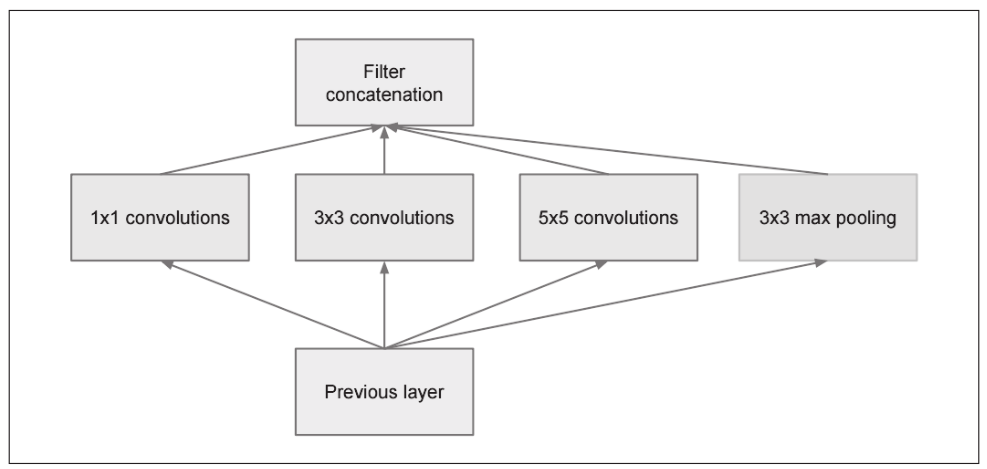
Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。GoogLeNet 的特征就是将这个 Inception 结构用作一个构件(构成元素)。此外,在GoogLeNet中,很多地方都使用了大小为 1x1 的滤波器的卷积层。这个 1x1 的卷积运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理。
ResNet 是微软团队开发的网络。它的特征在于具有比以前的网络更深的结构。
在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。ResNet 中,为了解决这类问题,导入了“快捷结构”(也称为“捷径”或“小路”)。导入这个快捷结构后,就可以随着层的加深而不断提高性能了(当然,层的加深也是有限度的)。
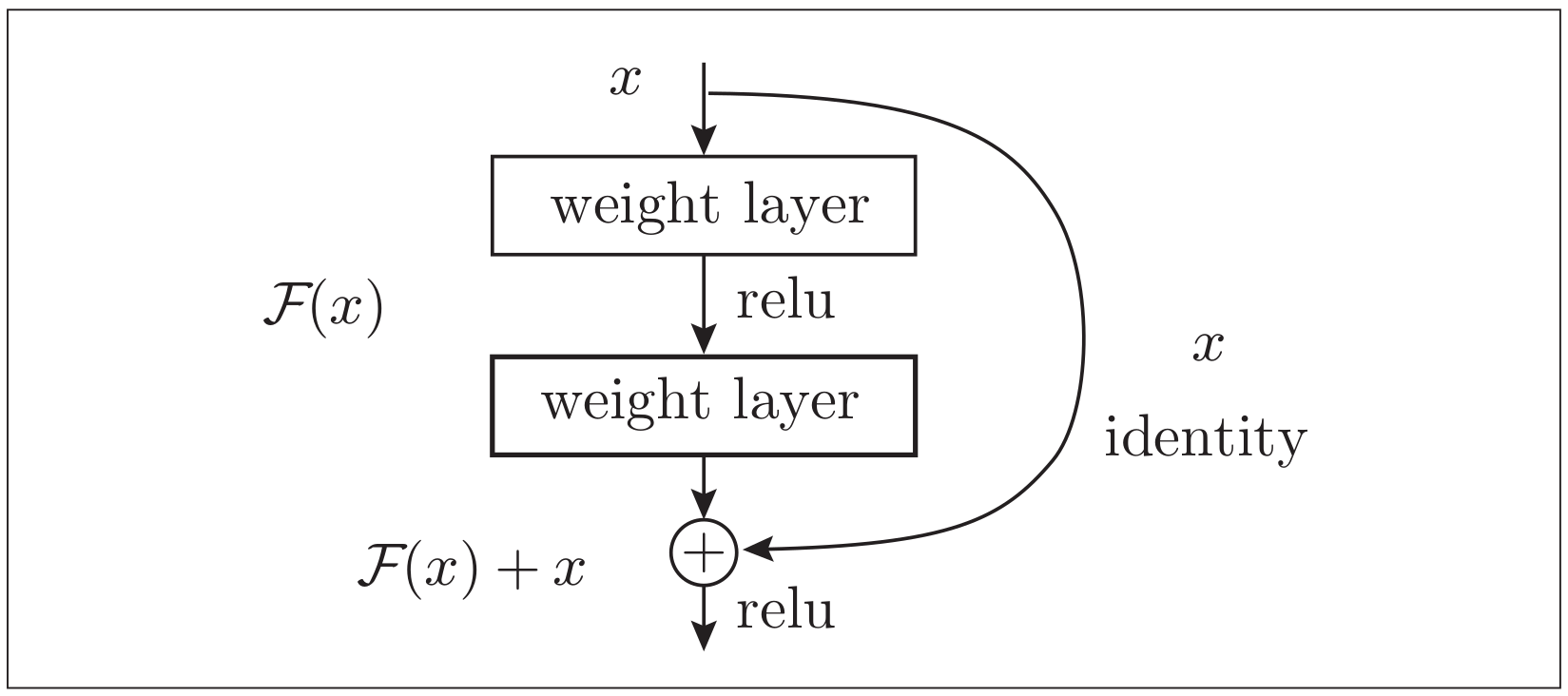
如上图所示,在连续2层的卷积层中,将输入 x 跳着连接至 2 层后的输出。这里的重点是,通过快捷结构,原来的2层卷积层的输出 F ( x ) 变成了 F ( x ) + x ∘ \mathcal{F}(x)变成了\mathcal{F}(x)+x_\circ F(x)变成了F(x)+x∘ 通过引入这种快捷结构,即使加深层,也能高效地学习。这是因为,通过快捷结构,反向传播时信号可以无衰减地传递。
快捷结构只是原封不动地传递输入数据,所以反向传播时会将来自上游的梯度原封不动地传向下游。这里的重点是不对来自上游的梯度进行任何处理,将其原封不动地传向下游。因此,基于快捷结构,不用担心梯度会变小(或变大),能够向前一层传递“有意义的梯度”。通过这个快捷结构,之前因为加深层而导致的梯度变小的梯度消失问题就有望得到缓解。
ResNet 以前面的VGG网络为基础,引入快捷结构以加深层,其结构如下图所示。

如上图所示, ResNet 通过以2个卷积层为间隔跳跃式地连接来加深层。另外,根据实验的结果,即便加深到150层以上,识别精度也会持续提高。
关于ResNet,之后有时间再仔细学习详细分析一下…