[NLP]课程期末知识点总结
NLP课程期末知识点总结
- 期末重点说明
- 第01章_引言+绪论
- 第02章_基于规则的自然语言处理
- 第03章_文本分类
- 第04章_语言模型
- 第05章_文本表示
- 第06章_卷积神经网络
- 第07章_循环神经网络
- 第08章_8-1_Transformer
- 第08章_8-2_预训练模型
- 第09章_信息抽取
示例:
可能会考
一定会考
期末重点说明
10道选择题 1分*10
8道简答题(2~3个子问题) 90分
内容:
上课课堂练习&提问模型理解
每章一个问题,CNN,transformer等等
朴素贝叶斯文本分类计算
绪论自然语言处理的基本概念
主要内容是ppt的内容,搜索资料加深对模型的理解
第01章_引言+绪论
感觉概念都不重要,应该不会默写,那也太无聊了。
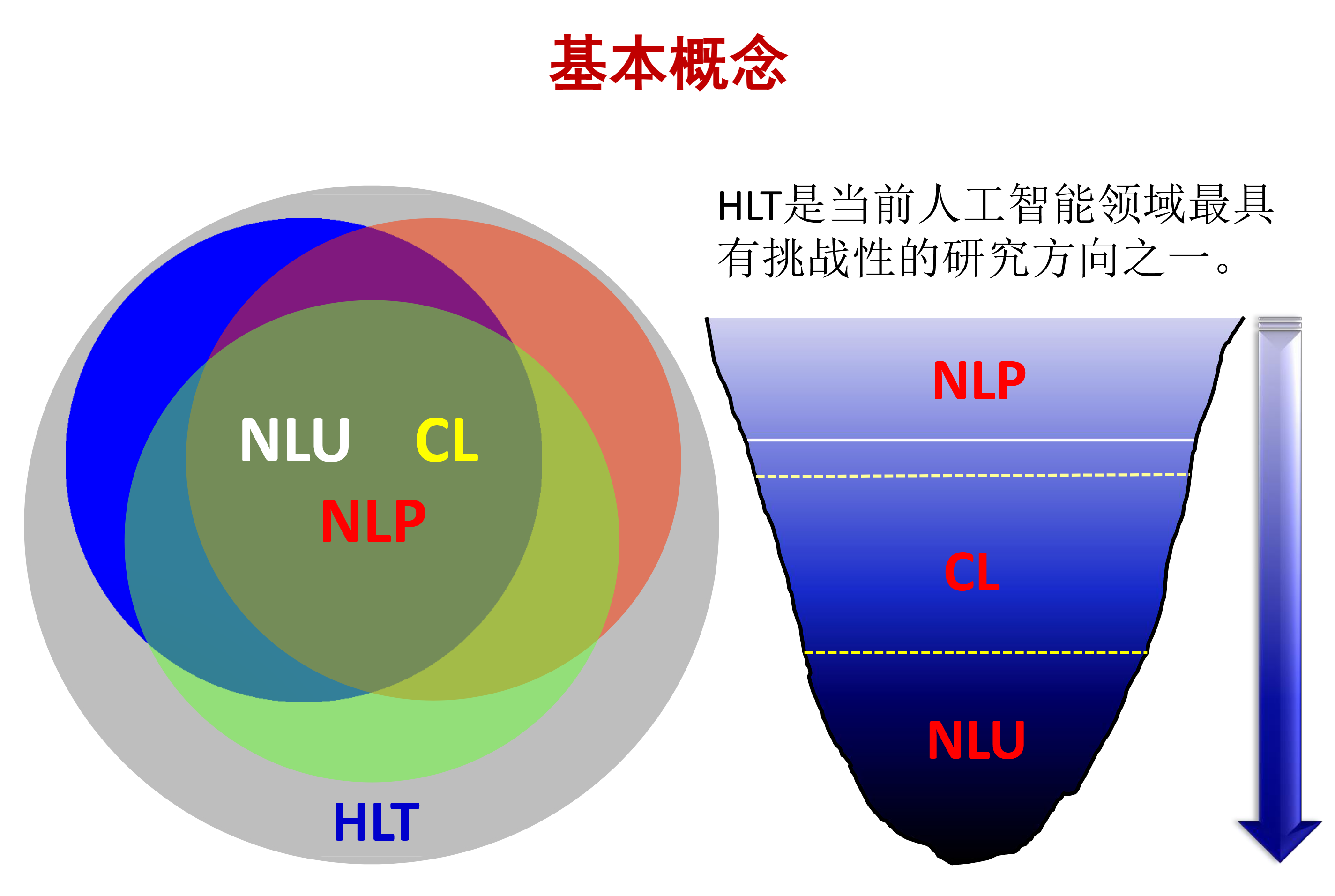
语言学

计算语言学CL

自然语言理解NLU

自然语言处理NLP

中文信息处理


人类语言技术HLT
Human Language Technology
各名词范围可视化
三种不同的语系

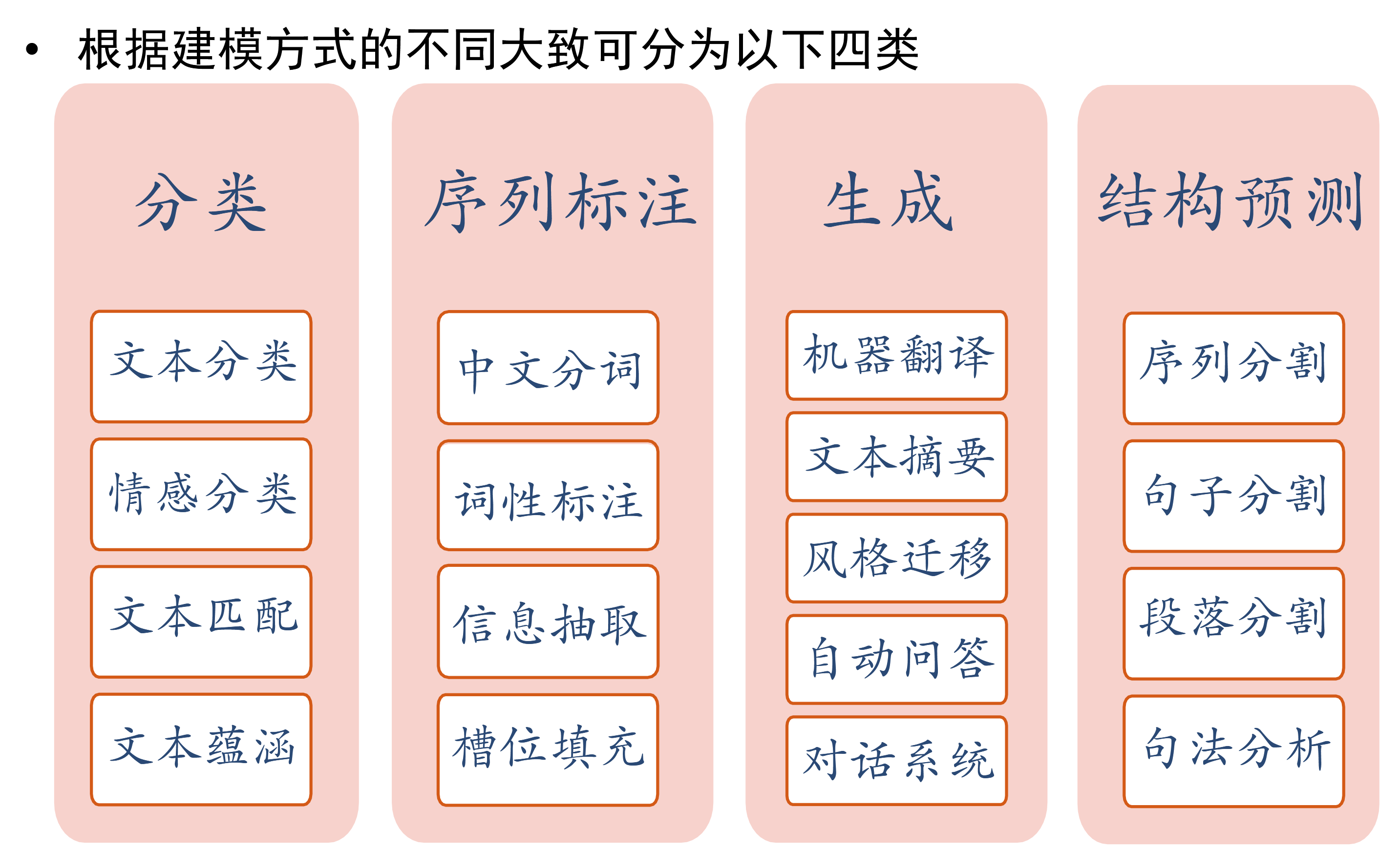
NLP研究内容
技术现状
一个有意思的问题:
但是我感觉n的个数可能有错

第02章_基于规则的自然语言处理
流程,依赖人类专家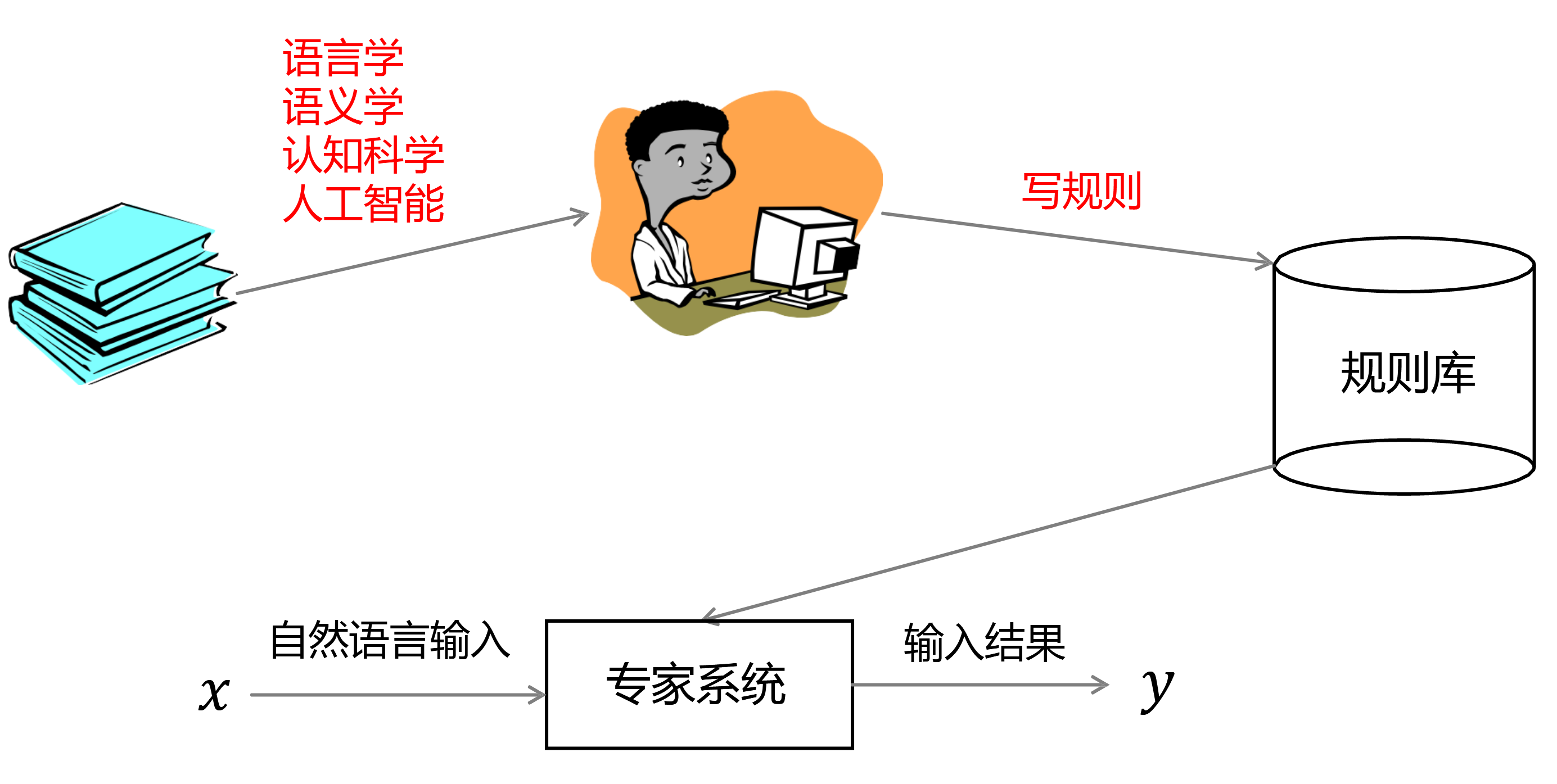
规则方法适用的情况/任务
- 词法分析:

可能重要一些的点:
- 形态还原基本算法:

- 分词方法罗列&缺点


- 词性标注看着一点不重要
- 命名实体识别后续课程应该有详细讲
- 机器翻译也只是浅浅概述
第03章_文本分类
文本分类常用数据集
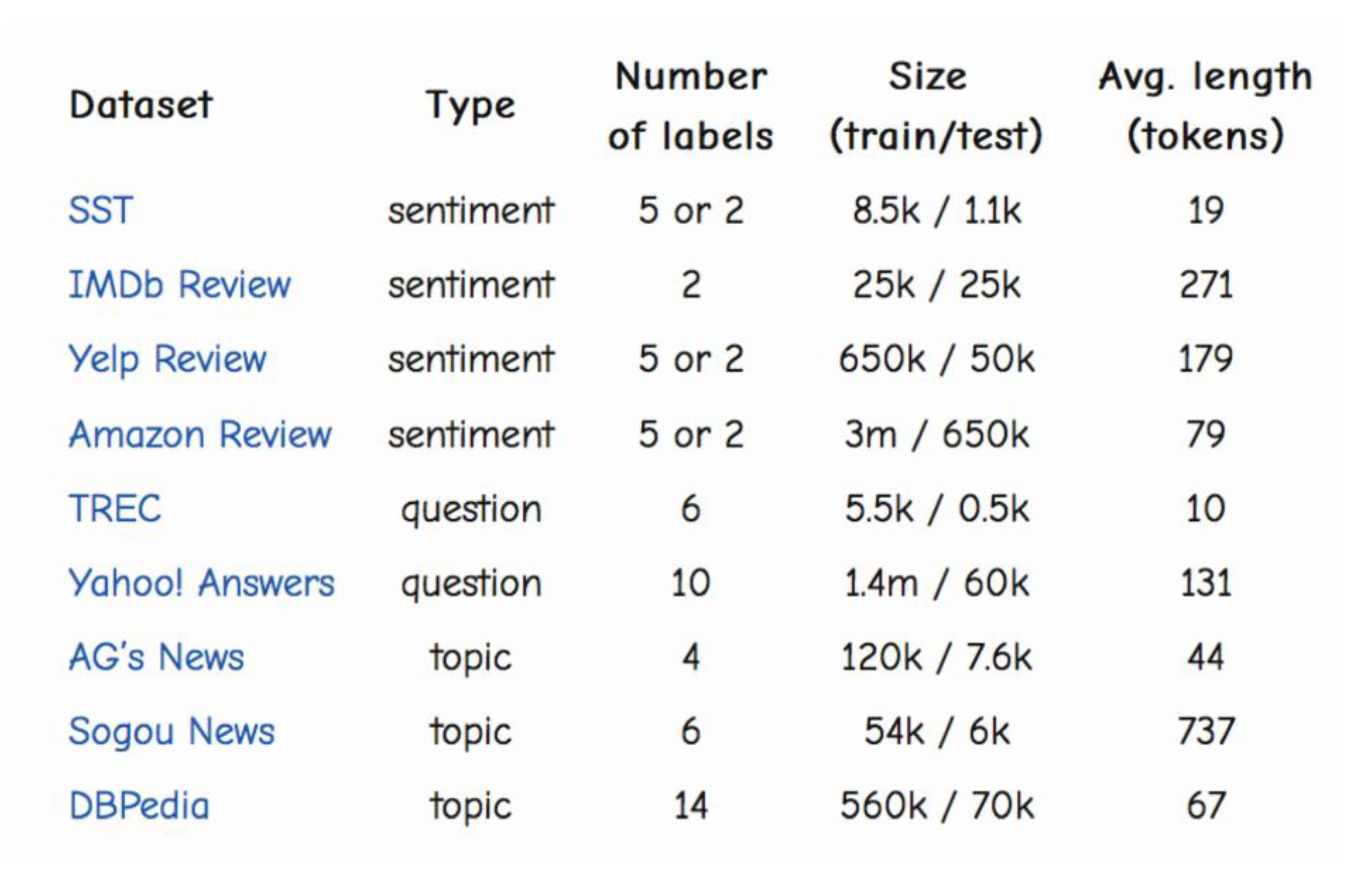
传统机器学习方法的流程
特征表示、特征选择、分类
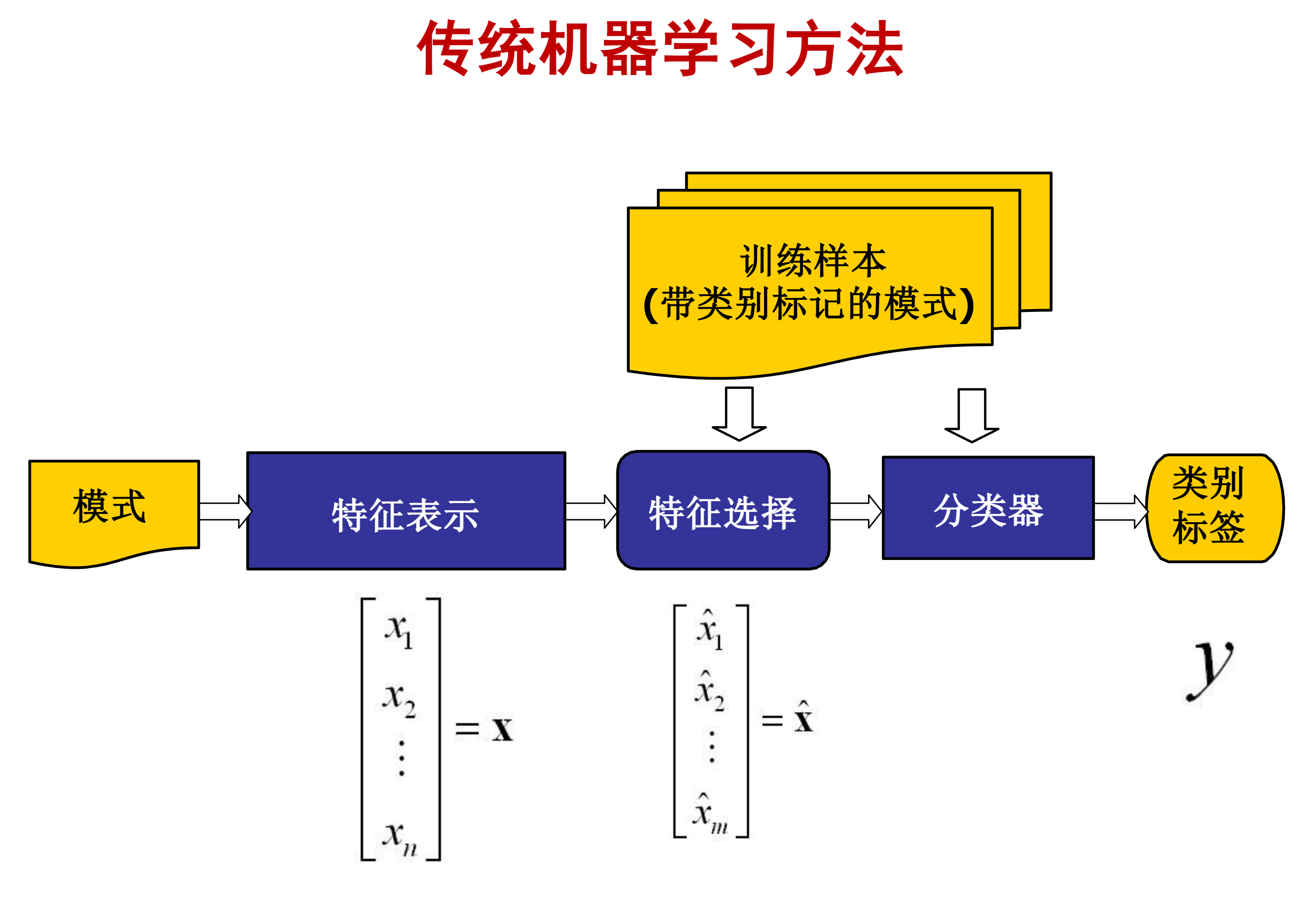
- 文本的形式化表示是反映文本内容和区分不同文本的有效途径
- 文本表示——向量空间模型(vector space model, VSM)

- 特征项是词语:可称为词袋模型(bag-of-words,BOW)
- 特征项权重
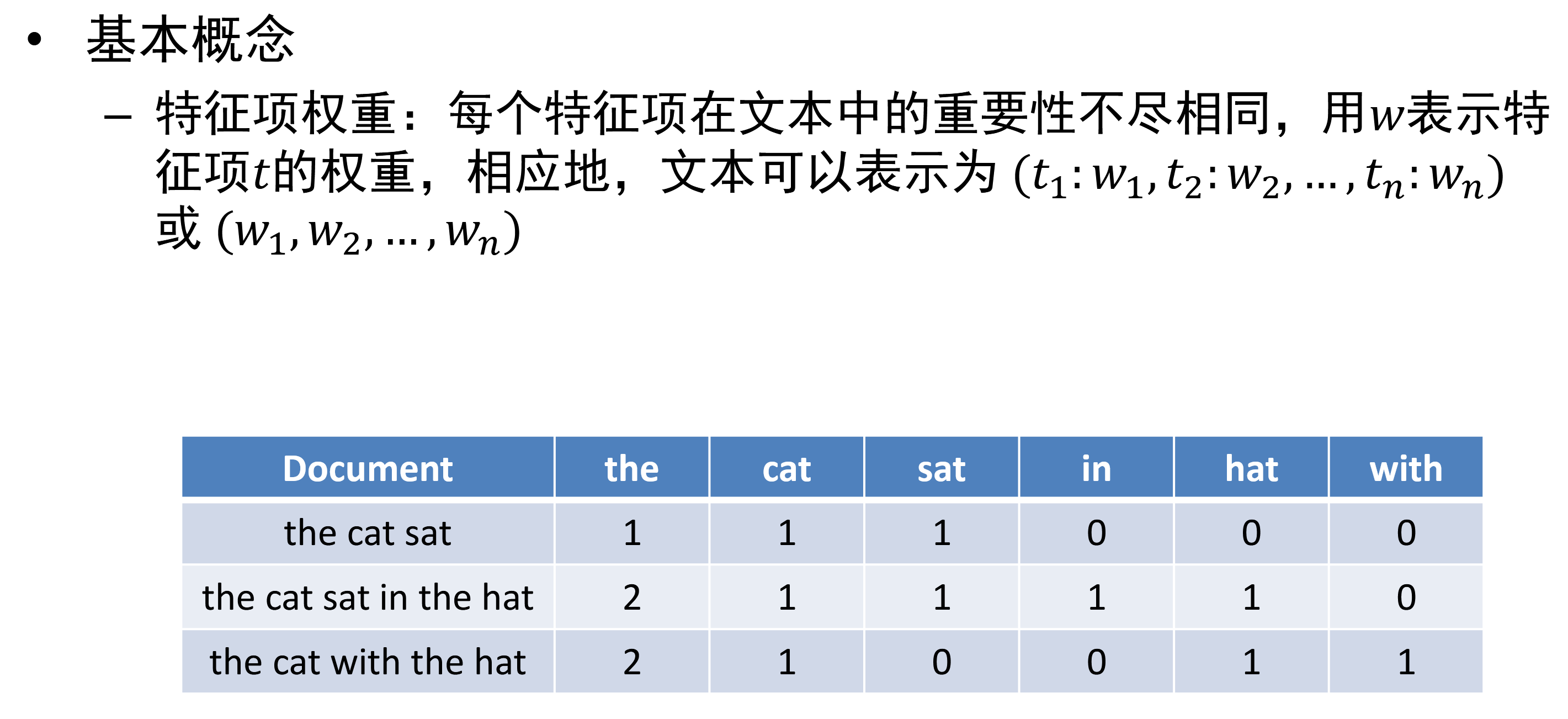
- 布尔变量
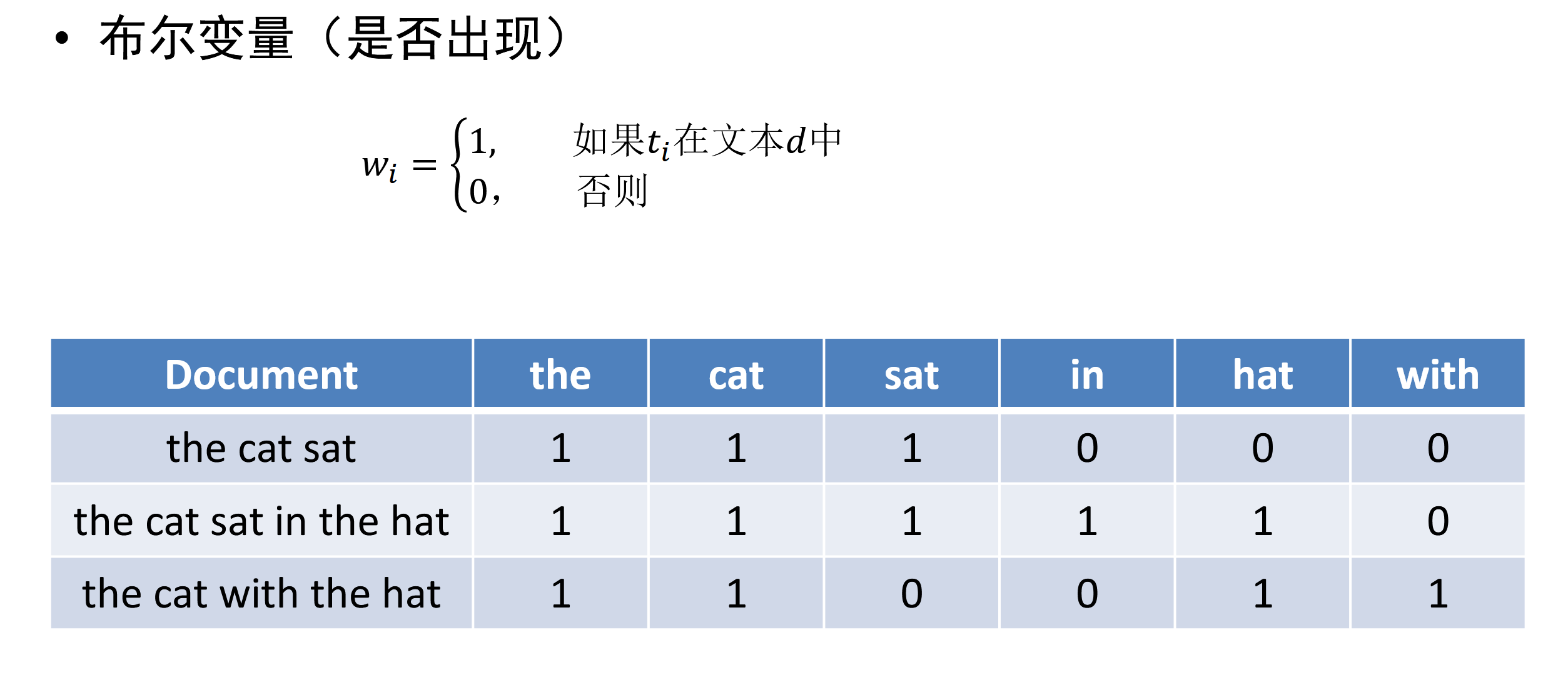
- 词频(可以直接使用次数,也可以 log ( t f i + 1 ) \log(tf_i + 1) log(tfi+1))

为什么要 log ( t f i + 1 ) \log(tf_i+1) log(tfi+1)?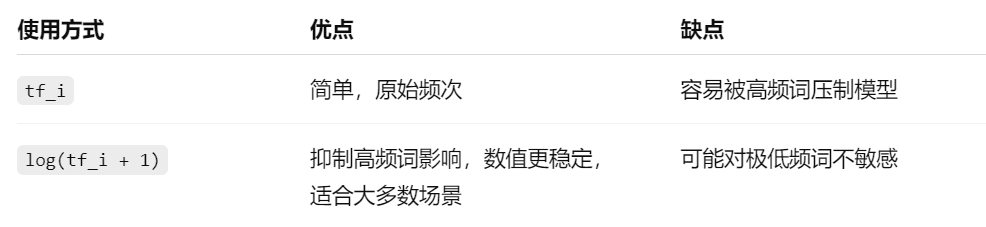
- 逆文档频率
- N:语料库中总文档数
- d f t df_t dft:包含词t的文档数量
- 如果一个词在很多文档中都出现,它的重要性就低(比如“的”、“是”)。如果一个词只在少数文档中出现,它的重要性就高(比如“黑洞”、“爱因斯坦”)。
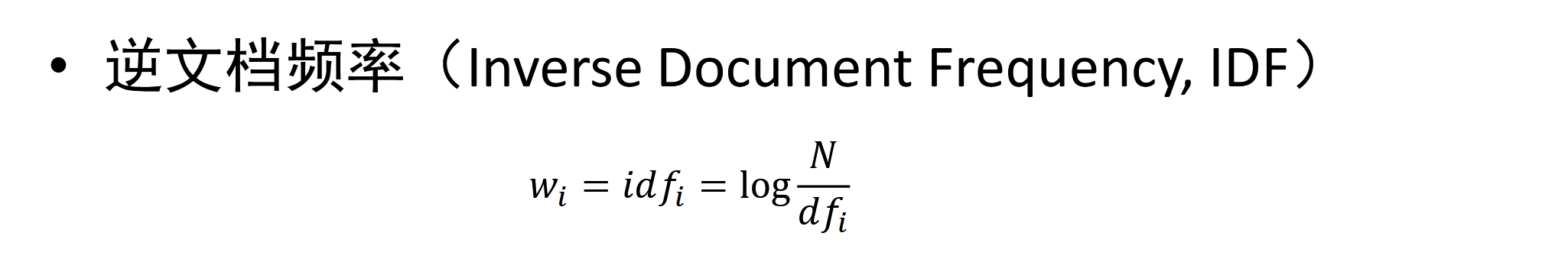
- TF_IDF
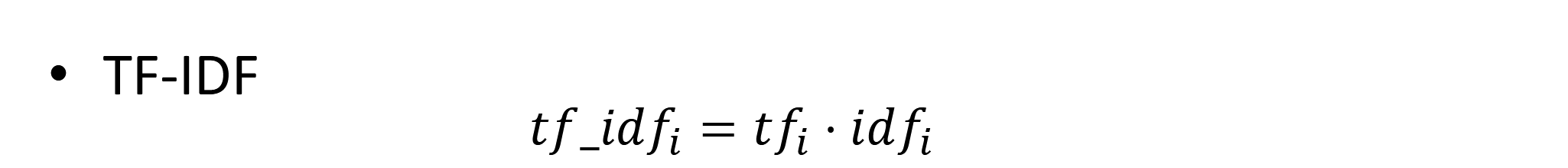
- 布尔变量
- 特征选择
- 文档频率
- 一个特征的文档频率是指在文档集中含有该特征的文档数目

- 互信息
- 基本概念

- 互信息(感觉说的不是很清楚)

- 基本概念
- 信息增益(IG):原来的熵减去已知某一特征信息后的熵

- 一个特征的文档频率是指在文档集中含有该特征的文档数目
- 文档频率
计算信息增益

- 分类算法
- 监督学习
- 生成式模型:朴素贝叶斯
为什么朴素贝叶斯算法是生成式模型
先理解判别式和生成式的区别
朴素贝叶斯建模了 P ( x ∣ c j ) P(x|c_j) P(x∣cj)

- 生成式模型:朴素贝叶斯
NB决策
M是词表大小
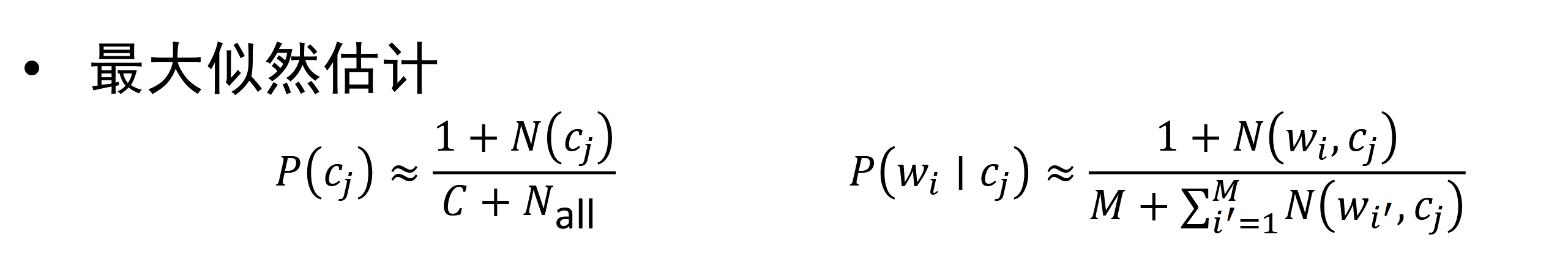
判别式模型只是浅浅略过。。
- 文本分类性能评估
- 正确率
- 宏:每类求R\P后平均

- 微:每类TP等加起来求R\P

- P-R(纵轴P,横轴R)
- ROC(纵轴TPR,横轴FPR)
第04章_语言模型
- 传统语言模型
-
n元文法
此时还是考虑前面所有历史基元- 语句的先验概率:前面所有的词出现的情况下这个词出现的概率(连乘)

但是存在参数量爆炸的问题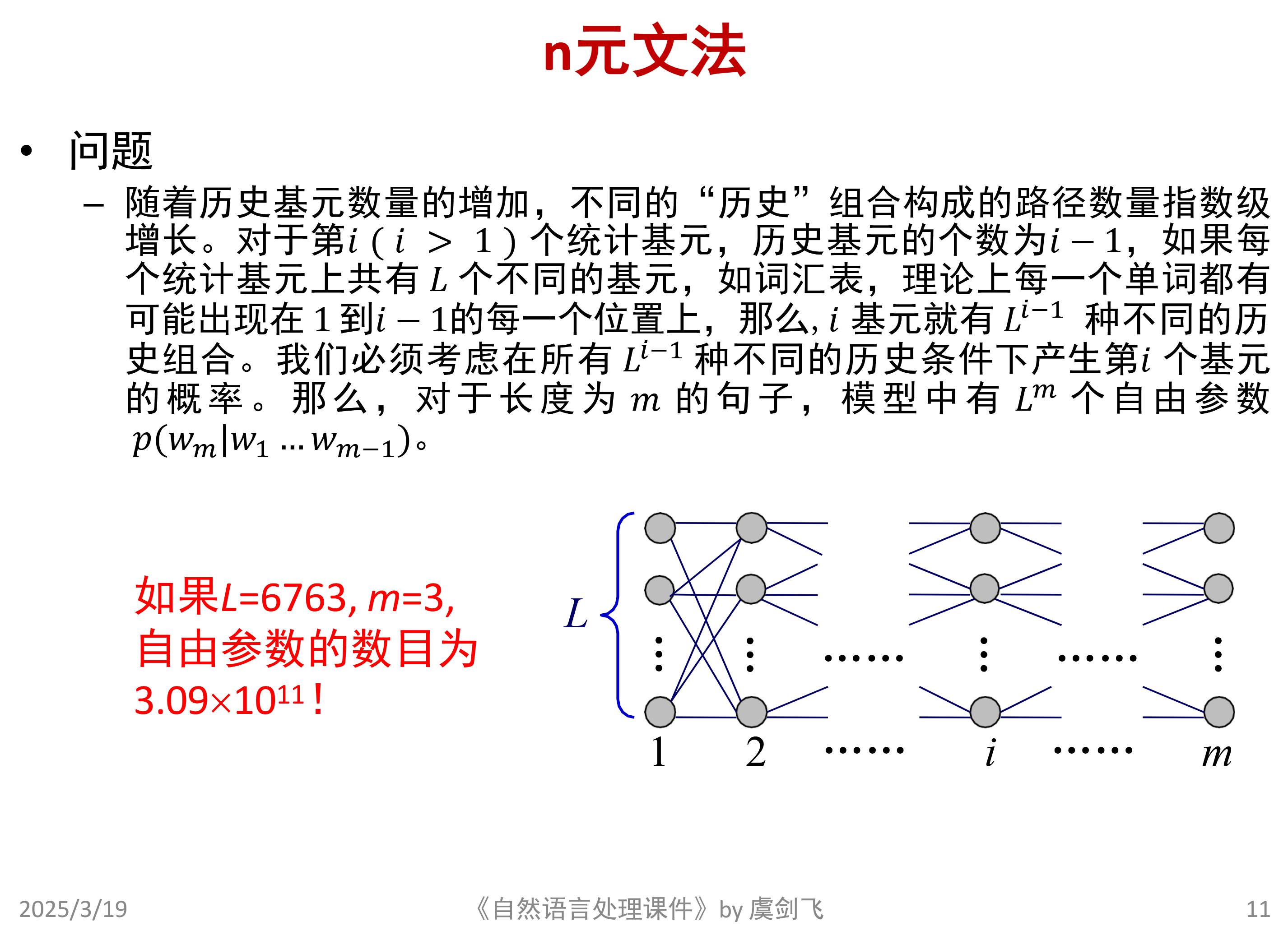
解决问题的思路:将历史基元映射到等价类。
引出n元文法,只考虑前面n-1个历史基元。
< - 语句的先验概率:前面所有的词出现的情况下这个词出现的概率(连乘)