AI进展不止于基准:深度解析Grok 3的局限
基准测试长期以来一直是AI评估的基石,但任何认真的AI科学家都知道它们是可以被“游戏化”的。
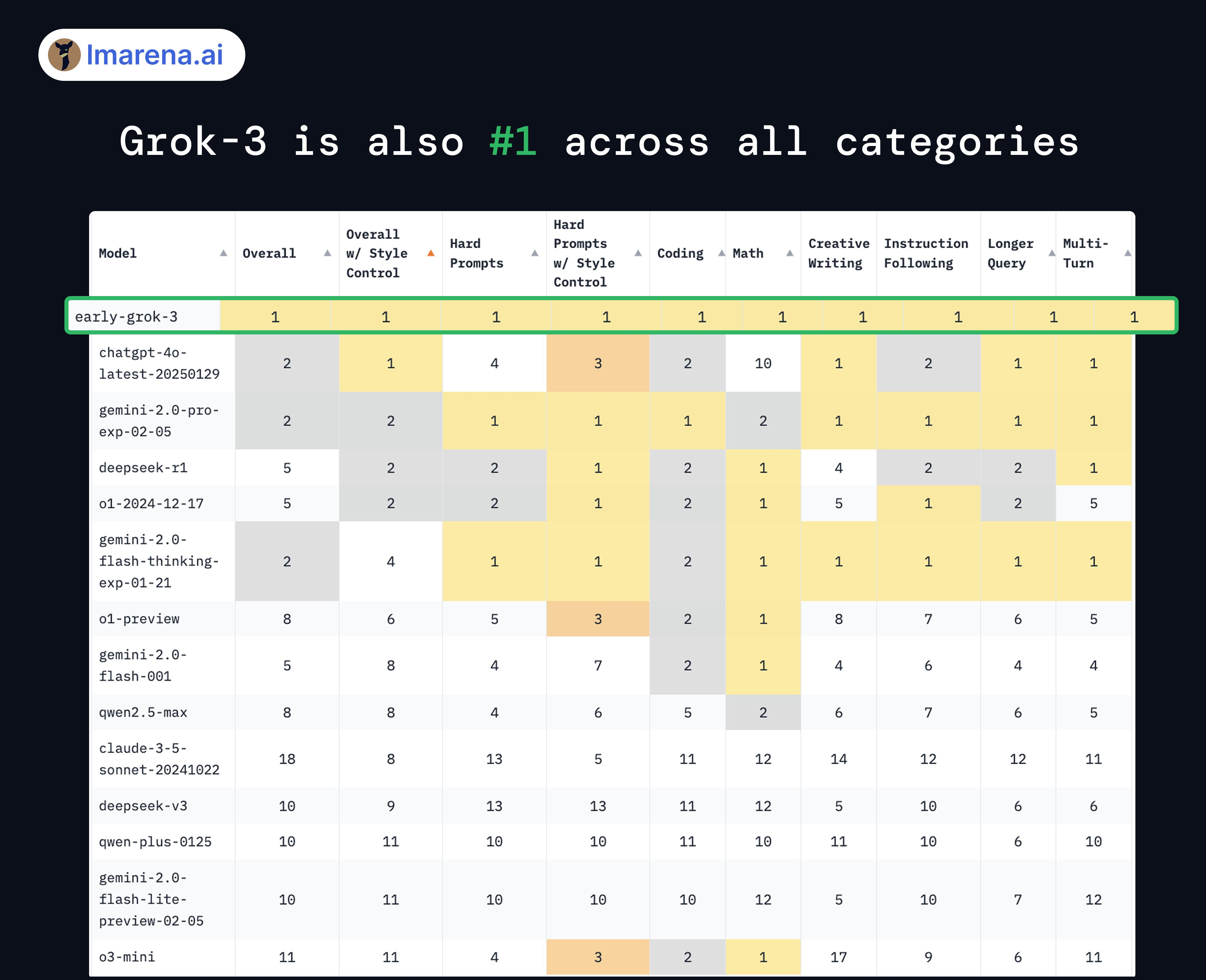
我曾经详细写过这个问题,甚至LMsys也不得不调整其盲测格式——将Grok 3用不同的标签代替,而不仅仅是隐藏品牌——以减少品牌偏见。
高能力AI,尤其是像GPT-4级别的模型,或那些依赖测试时计算的模型,其问题不仅仅是原始的性能指标。没有任何基准测试能够完全捕捉到两个根本性挑战。

第一个主要问题是当前模型无法进行多层次的战略推理。
如果我们将任何复杂问题拆解成不同的层次——扫描、优化与计划、以及实施——任何一个阶段的错误都会在最终输出中引发灾难性后果。
测试时的计算无法解决这个问题,因为这个问题嵌入在这些模型如何按顺序处理信息的方式中。
第二个问题是理解新知识。
大模型的标准知识差距通常在6到8个月之间。
即使通过最新的信息进行微调,依然有证据表明新引入的事实与预训练期间建立的基础知识之间可能会出现矛盾。
这里的核心