qemu-kvm源码解析-cpu虚拟化
背景
Qemu 虚拟化中,CPU,内存,中断是虚拟化的核心板块。本章主要对CPU虚拟化源码进行分析
而随着技术的发展包括CPU、内存、网卡等常见外设。硬件层面的虚拟化现在已经是云计算的标配。形成了,qemu作为cpu外层控制面,内核作为cpu调度和执行的数据面,cpu芯片硬件支持运行空间切换的三层相互配合的结构。
运行模式
VMM和VM两种软件,Intel为CPU引入了一种新的模式,叫作VMX operation。VMM执行的模式叫作VMX root operation模式,VM执行的模式叫作VMX non-root operation模式,这两种模式之间的转换叫作VMX转换。从VMX root转换到VMX non-root叫作VM Entry,而从VMX non-root转换到VMX root则叫作VM Exit。每种模式都有自己的ring0和ring3结构。VMX operation与CPU特权级是正交的。在普通的QEMU/KVM架构中,QEMU等用户态软件以及KVM等宿主机的内核都运行在VMX root模式下,在虚拟机也有自己的ring0和ring3。
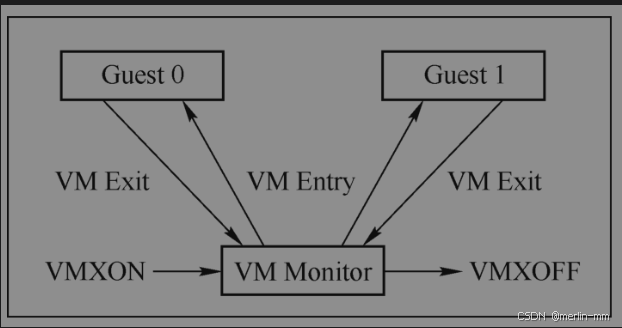
Guest0, Guest1 表示正 运行在 MX non-root operation模式下的cpu,其负责运转正被调度运行的虚拟机。
VMCS
每个虚拟机的VCPU都有一个对应的VMCS区域。VMCS用来管理VMX non-rootOperation的转换以及控制VCPU的行为。操作VMCS的指令包括VMCLEAR、VMPTRLD、VMREAD和VMWRITE。VMCS区域的大小为4KB,VMM通过它的64位地址来对该区域进行访问。VMCS之于VCPU的作用类似于进程描述符之于进程的作用。
VCPU之间会共享物理CPU,VMM负责在多个VCPU之间分配物理CPU,每个VCPU都有自己的描述符,当VMM在切换VCPU运行时需要保存此刻的VCPU状态,从而在下次的VCPU调度中使得VCPU能够从被中断的那个点开始正常运行。
VMCS数据区总共有6个区域,下面对每个区域做简单介绍。
1)Guest-state区域。进行VM Entry时,虚拟机处理器的状态信息从这个区域加载,进行VM Exit时,虚拟机的当前状态信息写入到这个区域。在这个区域中,典型的有各个寄存器的状态以及一些处理器的状态。
2)Host-state区域。当发生VM Exit的时候,需要切换到VMM的上下文运行,此时处理器的状态信息从这个区域加载。
3)VM-execution控制区域。这个区域用来控制处理器在进入VM Entry之后的处
理器行为,这个区域很庞大,包含了多种控制,如哪些时间会引起VM Exit,一个异常位图指示哪些异常会发生VM Exit,APIC的虚拟化控制等。
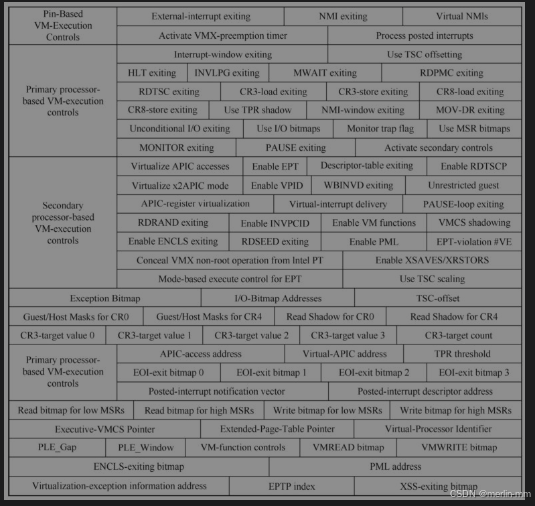
4)VM Exit控制区域。这个区域用来指定虚拟机在发生VM Exit时的行为,如一些寄存器的保存。
5)VM Entry控制区域。这个区域用来指定虚拟机在发生VM Entry时的行为,如一些寄存器的加载,还有一些虚拟机的事件注入。
6)VM Exit信息区域。这个区域包含了最近产生的VM Exit信息,典型的信息包括退出的原因以及相应的数据,如指令执行的退出会记录指令的长度等。
模块交互
虚拟机运行时,用户空间的qemu通过设置文件/dev/kvm 与内核交互,kvm.ko是一组kvm操作接口的声明, 具体到cpu的方法是根据cpu物理类型决定的。
譬如 amd 的cpu将调用 kvm-amd.ko, 而intel 的cpu将调用 kvm-intel.ko中的相关方法实现。
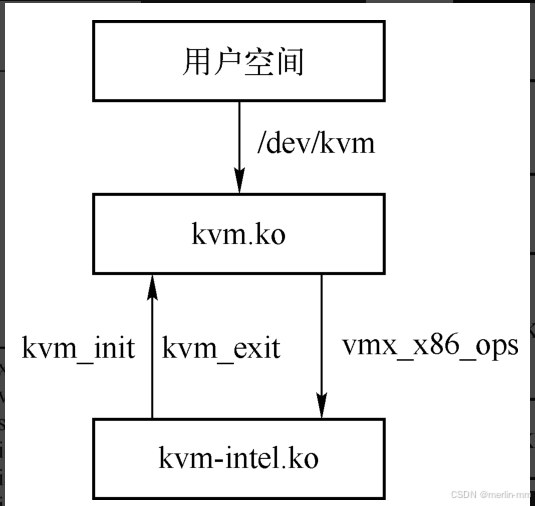
kvm的初始化
下面以使用amd的cpu为例,即kvm.ko调用kvm-amd.ko中的具体实现。
kvm.ko 中具体实现的cpu方法如下, 可见主要有
vcpu创建, vcpu调度抢占, 中断处理等
static struct kvm_x86_ops svm_x86_ops __initdata = {
.name = "kvm_amd",
.hardware_unsetup = svm_hardware_unsetup,
.hardware_enable = svm_hardware_enable,
.hardware_disable = svm_hardware_disable,
.has_emulated_msr = svm_has_emulated_msr,
.vcpu_create = svm_vcpu_create, //vcpu 创建,销毁管理
.vcpu_free = svm_vcpu_free,
.vcpu_reset = svm_vcpu_reset,
.vm_size = sizeof(struct kvm_svm),
.vm_init = svm_vm_init,
.vm_destroy = svm_vm_destroy,
.prepare_switch_to_guest = svm_prepare_switch_to_guest,
.vcpu_load = svm_vcpu_load, // vcpu的数据加载以及保存
.vcpu_put = svm_vcpu_put,
// ...
.sched_in = svm_sched_in, //vcpu的抢占
.nested_ops = &svm_nested_ops,
.deliver_interrupt = svm_deliver_interrupt, //中断处理相关
.pi_update_irte = avic_pi_update_irte,
.setup_mce = svm_setup_mce,
//...
}; 方法的注册在 svm_init 中
static struct kvm_x86_init_ops svm_init_ops __initdata = {
//...
.runtime_ops = &svm_x86_ops, // 底层方法回调
.pmu_ops = &amd_pmu_ops,
};
static int __init svm_init(void)
{
// 注册 amd 的kvm, 其中 svm_init_ops 为具体的kvm相关函数实现
// kvm_init 为虚拟化通用函数,注册 底层具体 实现的kvm方法
r = kvm_init(&svm_init_ops, sizeof(struct vcpu_svm),
__alignof__(struct vcpu_svm), THIS_MODULE);
// ...
}
// amd 对外暴露 amd-kvm 的初始化函数为 svm_init
module_init(svm_init)
module_exit(svm_exit)kvm初始化函数 kvm_init 如下, 主要工作为
-
为每个物理cpu创建了vmc_config 数据,用于后续虚拟机的控制数据,信息数据保存支持。
-
注册了设备文件 /dev/kvm , 以ioctl 的模式提供虚拟机创建,删除等方法支持。
int kvm_init(void *opaque, unsigned vcpu_size, unsigned vcpu_align,
struct module *module)
{
struct kvm_cpu_compat_check c;
int r;
int cpu;
// 架构初始化. 根据架构内型决定,譬如 x86, arm, mips
// x86 未做特别操作
r = kvm_arch_init(opaque);
if (r)
goto out_fail;
r = kvm_irqfd_init();
if (r)
goto out_irqfd;
// 遍历物理cpu,为每个cpu,创建vmcs结构, 用于保存虚拟机相关的控制数据等信息
// 对于amd架构最终会调用 setup_vmcs_config
for_each_online_cpu(cpu) {
smp_call_function_single(cpu, check_processor_compat, &c, 1);
if (r < 0)
goto out_free_2;
}
//...
// 注册CPU在热插拔的时候就会得到通知
r = cpuhp_setup_state_nocalls(CPUHP_AP_KVM_STARTING, "kvm/cpu:starting",
kvm_starting_cpu, kvm_dying_cpu);
if (r)
goto out_free_2;
// 注册系统重启时得到通知
register_reboot_notifier(&kvm_reboot_notifier);
// 创建cpu 结构体的cache
/* A kmem cache lets us meet the alignment requirements of fx_save. */
if (!vcpu_align)
vcpu_align = __alignof__(struct kvm_vcpu);
kvm_vcpu_cache =
kmem_cache_create_usercopy("kvm_vcpu", vcpu_size, vcpu_align,
SLAB_ACCOUNT,
offsetof(struct kvm_vcpu, arch),
offsetofend(struct kvm_vcpu, stats_id)
- offsetof(struct kvm_vcpu, arch),
NULL);
if (!kvm_vcpu_cache) {
r = -ENOMEM;
goto out_free_3;
}
kvm_chardev_ops.owner = module;
register_syscore_ops(&kvm_syscore_ops);
// 注册 cpu 抢占进入时的回调
// 注册 cpu 放弃资源,让度时的回调
kvm_preempt_ops.sched_in = kvm_sched_in;
kvm_preempt_ops.sched_out = kvm_sched_out;
kvm_init_debug();
r = kvm_vfio_ops_init();
if (WARN_ON_ONCE(r))
goto err_vfio;
/*
* Registration _must_ be the very last thing done, as this exposes
* /dev/kvm to userspace, i.e. all infrastructure must be setup!
*/
// /dev/kvm 文件描述符中 ioctl操作方法的注册
r = misc_register(&kvm_dev);
if (r) {
pr_err("kvm: misc device register failed\n");
goto err_register;
}
return 0;
// ....
}
EXPORT_SYMBOL_GPL(kvm_init);
// /dev/kvm 的 ioctl 操作方法, 如开启虚拟机,关闭虚拟机等
static struct file_operations kvm_chardev_ops = {
.unlocked_ioctl = kvm_dev_ioctl,
.llseek = noop_llseek,
KVM_COMPAT(kvm_dev_ioctl),
};
static struct miscdevice kvm_dev = {
KVM_MINOR,
"kvm",
&kvm_chardev_ops,
};amd cpu对应的vmc_config 数据构造, 每个物理cpu对应一个,用于做该物理cpu 对vpcu的数据记录支持。
static __init int setup_vmcs_config(struct vmcs_config *vmcs_conf,
struct vmx_capability *vmx_cap)
{
u32 vmx_msr_low, vmx_msr_high;
u32 _pin_based_exec_control = 0;
u32 _cpu_based_exec_control = 0;
u32 _cpu_based_2nd_exec_control = 0;
u64 _cpu_based_3rd_exec_control = 0;
u32 _vmexit_control = 0;
u32 _vmentry_control = 0;
u64 misc_msr;
int i;
/*
* LOAD/SAVE_DEBUG_CONTROLS are absent because both are mandatory.
* SAVE_IA32_PAT and SAVE_IA32_EFER are absent because KVM always
* intercepts writes to PAT and EFER, i.e. never enables those controls.
*/
struct {
u32 entry_control;
u32 exit_control;
} const vmcs_entry_exit_pairs[] = {
{ VM_ENTRY_LOAD_IA32_PERF_GLOBAL_CTRL, VM_EXIT_LOAD_IA32_PERF_GLOBAL_CTRL },
{ VM_ENTRY_LOAD_IA32_PAT, VM_EXIT_LOAD_IA32_PAT },
{ VM_ENTRY_LOAD_IA32_EFER, VM_EXIT_LOAD_IA32_EFER },
{ VM_ENTRY_LOAD_BNDCFGS, VM_EXIT_CLEAR_BNDCFGS },
{ VM_ENTRY_LOAD_IA32_RTIT_CTL, VM_EXIT_CLEAR_IA32_RTIT_CTL },
};
memset(vmcs_conf, 0, sizeof(*vmcs_conf));
if (adjust_vmx_controls(KVM_REQUIRED_VMX_CPU_BASED_VM_EXEC_CONTROL,
KVM_OPTIONAL_VMX_CPU_BASED_VM_EXEC_CONTROL,
MSR_IA32_VMX_PROCBASED_CTLS,
&_cpu_based_exec_control))
return -EIO;
// ...
rdmsrl(MSR_IA32_VMX_MISC, misc_msr);
vmcs_conf->size = vmx_msr_high & 0x1fff;
vmcs_conf->basic_cap = vmx_msr_high & ~0x1fff;
vmcs_conf->revision_id = vmx_msr_low;
vmcs_conf->pin_based_exec_ctrl = _pin_based_exec_control;
vmcs_conf->cpu_based_exec_ctrl = _cpu_based_exec_control;
vmcs_conf->cpu_based_2nd_exec_ctrl = _cpu_based_2nd_exec_control;
vmcs_conf->cpu_based_3rd_exec_ctrl = _cpu_based_3rd_exec_control;
vmcs_conf->vmexit_ctrl = _vmexit_control;
vmcs_conf->vmentry_ctrl = _vmentry_control;
vmcs_conf->misc = misc_msr;
return 0;
}
虚拟机的创建
qemu创建虚拟机
以kvm模式创建虚拟机为例
当在QEMU命令行加入--enable-kvm时,解析会进入下面的case分支。
case QEMU_OPTION_enable_kvm:
qdict_put_str(machine_opts_dict, "accel", "kvm");
break;这里给machine optslist这个参数项加了一个accel=kvm参数,之后main函数会调用configure_accelerator(current_machine),该函数会从machine的参数列表中取出accel的值,找出所属的类型,然后调用accel_init_machine。
int accel_init_machine(AccelState *accel, MachineState *ms)
{
AccelClass *acc = ACCEL_GET_CLASS(accel);
int ret;
ms->accelerator = accel;
*(acc->allowed) = true;
// 这里根据enable-kvm 最终会调用kvm_init
ret = acc->init_machine(ms);
//...
}kvm_init 函数如下,主要工作为
-
创建保存该虚拟机相关信息的 KVMState 结构
-
调用ioctl 创建虚拟机,并将虚拟机相关信息放入创建的KVMState 结构
static int kvm_init(MachineState *ms)
{
s = KVM_STATE(ms->accelerator);
//...
ret = kvm_ioctl(s, KVM_GET_API_VERSION, 0);
if (ret < KVM_API_VERSION) {
if (ret >= 0) {
ret = -EINVAL;
}
fprintf(stderr, "kvm version too old\n");
goto err;
}
if (ret > KVM_API_VERSION) {
ret = -EINVAL;
fprintf(stderr, "kvm version not supported\n");
goto err;
}
//...
do {
ret = kvm_ioctl(s, KVM_CREATE_VM, type);
} while (ret == -EINTR);
// ...
s->coalesced_mmio = kvm_check_extension(s, KVM_CAP_COALESCED_MMIO);
s->coalesced_pio = s->coalesced_mmio &&
kvm_check_extension(s, KVM_CAP_COALESCED_PIO);
/*
* Enable KVM dirty ring if supported, otherwise fall back to
* dirty logging mode
*/
ret = kvm_dirty_ring_init(s);
if (ret < 0) {
goto err;
}
// ...
s->max_nested_state_len = kvm_check_extension(s, KVM_CAP_NESTED_STATE);
s->irq_set_ioctl = KVM_IRQ_LINE;
if (kvm_check_extension(s, KVM_CAP_IRQ_INJECT_STATUS)) {
s->irq_set_ioctl = KVM_IRQ_LINE_STATUS;
}
// ...
kvm_state = s;
ret = kvm_arch_init(ms, s);
if (ret < 0) {
goto err;
}
//...
}kvm创建虚拟机
Kvm 收到qemu对设备文件 /dev/kvm 的 KVM_CREATE_VM 操作后将执行虚拟机的创建逻辑
static long kvm_dev_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
long r = -EINVAL;
switch (ioctl) {
// ...
case KVM_CREATE_VM:
r = kvm_dev_ioctl_create_vm(arg);
break;
// ...
}
kvm_dev_ioctl_create_vm 主要工作为:
-
创建虚拟机
-
返回代表虚拟机的文件描述符,该文件描述符注册了虚拟机对应的操作回调
static int kvm_dev_ioctl_create_vm(unsigned long type)
{
// 创建虚拟机,并获得虚拟机文件描述符
kvm = kvm_create_vm(type, fdname);
if (IS_ERR(kvm)) {
r = PTR_ERR(kvm);
goto put_fd;
}
// 为即将返回的虚拟机文件描述符注册 对虚拟机的 ioctl方法回调
file = anon_inode_getfile("kvm-vm", &kvm_vm_fops, kvm, O_RDWR);
if (IS_ERR(file)) {
r = PTR_ERR(file);
goto put_kvm;
}
return r
}
kvm对虚拟机的具体创建与初始化如下
static struct kvm *kvm_create_vm(unsigned long type, const char *fdname)
{
// 分配虚拟机的句柄, 内含kvm 通用数据
struct kvm *kvm = kvm_arch_alloc_vm();
struct kvm_memslots *slots;
int r = -ENOMEM;
int i, j;
if (!kvm)
return ERR_PTR(-ENOMEM);
// ...
// 根据构架(mips, x86, arm..)向kvm 句柄中填充对应构架的属性
r = kvm_arch_init_vm(kvm, type);
if (r)
goto out_err_no_arch_destroy_vm;
// 轮询所有物理cpu,调用对应构建注册的 hardware_enable函数开启vmx支持
r = hardware_enable_all();
if (r)
goto out_err_no_disable;
#ifdef CONFIG_HAVE_KVM_IRQFD
INIT_HLIST_HEAD(&kvm->irq_ack_notifier_list);
#endif
r = kvm_init_mmu_notifier(kvm);
if (r)
goto out_err_no_mmu_notifier;
r = kvm_coalesced_mmio_init(kvm);
if (r < 0)
goto out_no_coalesced_mmio;
r = kvm_create_vm_debugfs(kvm, fdname);
if (r)
goto out_err_no_debugfs;
r = kvm_arch_post_init_vm(kvm);
if (r)
goto out_err;
// 将虚拟机使用放入链表管理
mutex_lock(&kvm_lock);
list_add(&kvm->vm_list, &vm_list);
mutex_unlock(&kvm_lock);
preempt_notifier_inc();
kvm_init_pm_notifier(kvm);
// ...
}
static void hardware_enable_nolock(void *junk)
{
//...
r = kvm_arch_hardware_enable();
//...
}vcpu的创建
CPU的定义
由于QEMU能够模拟多种CPU模型,因此需要一套继承结构来表示CPU对象,CPU模型的继承结构如下。
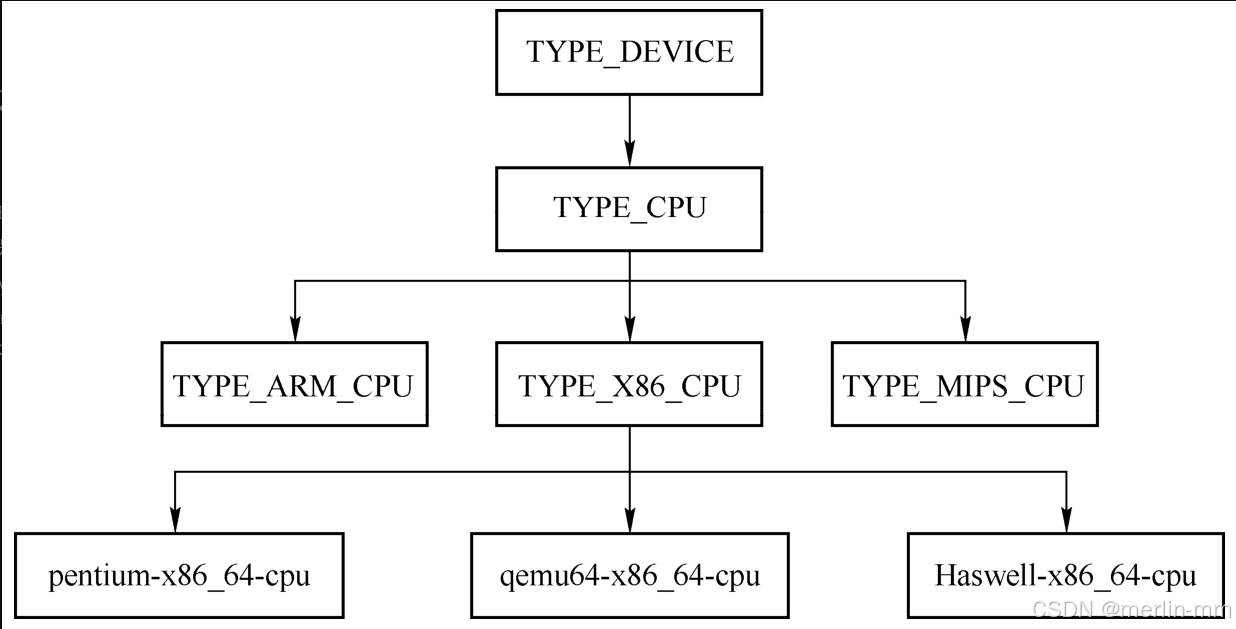
QEMU支持的x86 CPU都定义在一个builtin_x86_defs数组中,该数组的类型为X86CPUDefinition,定义如下。
name表示CPU的名字;level表示CPUID指令支持的最大功能号;xlevel表示CPUID扩展质量支持的最大功能号;vendor、family、model和stepping都表示CPU的基本信息,其中vendor是以NULL结尾的ASCII字符串;features是一个记录CPU特性的数组;model_id表示CPU的全名。
/* Base definition for a CPU model */
typedef struct X86CPUDefinition {
const char *name;
uint32_t level;
uint32_t xlevel;
/* vendor is zero-terminated, 12 character ASCII string */
char vendor[CPUID_VENDOR_SZ + 1];
int family;
int model;
int stepping;
FeatureWordArray features;
const char *model_id;
const CPUCaches *const cache_info;
/*
* Definitions for alternative versions of CPU model.
* List is terminated by item with version == 0.
* If NULL, version 1 will be registered automatically.
*/
const X86CPUVersionDefinition *versions;
const char *deprecation_note;
} X86CPUDefinition;TYPE_X86_CPU是指一种CPU构架类型,该构架类型的CPU都使用X86CPUDefinition 进行定义,并放在 builtin_x86_defs 数组中,如下
static const X86CPUDefinition builtin_x86_defs[] = {
{
.name = "qemu64",
.level = 0xd,
.vendor = CPUID_VENDOR_AMD,
.family = 15,
.model = 107,
.stepping = 1,
.features[FEAT_1_EDX] =
PPRO_FEATURES |
CPUID_MTRR | CPUID_CLFLUSH | CPUID_MCA |
CPUID_PSE36,
.features[FEAT_1_ECX] =
CPUID_EXT_SSE3 | CPUID_EXT_CX16,
.features[FEAT_8000_0001_EDX] =
CPUID_EXT2_LM | CPUID_EXT2_SYSCALL | CPUID_EXT2_NX,
.features[FEAT_8000_0001_ECX] =
CPUID_EXT3_LAHF_LM | CPUID_EXT3_SVM,
.xlevel = 0x8000000A,
.model_id = "QEMU Virtual CPU version " QEMU_HW_VERSION,
},
{
.name = "kvm64",
.level = 0xd,
.vendor = CPUID_VENDOR_INTEL,
.family = 15,
.model = 6,
.stepping = 1,
// ...
.model_id = "Common KVM processor"
},
{
.name = "qemu32",
.level = 4,
.vendor = CPUID_VENDOR_INTEL,
.family = 6,
.model = 6,
.stepping = 3,
.features[FEAT_1_EDX] =
PPRO_FEATURES,
.features[FEAT_1_ECX] =
CPUID_EXT_SSE3,
.xlevel = 0x80000004,
.model_id = "QEMU Virtual CPU version " QEMU_HW_VERSION,
},
{
.name = "kvm32",
.level = 5,
// ...
},
//...
}
循环调用该数组对cpu进行注册
函数x86_register_cpudef_type从一个X86CPUDefinition结构构造出一个TypeInfo结构,并调用type_register进行类型的注册。
static void x86_cpu_register_types(void)
{
int i;
type_register_static(&x86_cpu_type_info);
for (i = 0; i < ARRAY_SIZE(builtin_x86_defs); i++) {
// 注册 x86 构架的cpu
x86_register_cpudef_types(&builtin_x86_defs[i]);
}
type_register_static(&max_x86_cpu_type_info);
type_register_static(&x86_base_cpu_type_info);
}最终将调用下列函数
每个X86CPUDefinition 都会注册为 X86CPUClass结构, 而每个不同CPU的信息以及名称的异构信息
来自X86CPUDefinition 中不同CPU注册的的信息差异
static void x86_cpu_cpudef_class_init(ObjectClass *oc, void *data)
{
X86CPUModel *model = data;
X86CPUClass *xcc = X86_CPU_CLASS(oc);
CPUClass *cc = CPU_CLASS(oc);
xcc->model = model;
xcc->migration_safe = true;
cc->deprecation_note = model->cpudef->deprecation_note;
}
static void x86_register_cpu_model_type(const char *name, X86CPUModel *model)
{
g_autofree char *typename = x86_cpu_type_name(name);
TypeInfo ti = {
.name = typename,
.parent = TYPE_X86_CPU,
.class_init = x86_cpu_cpudef_class_init,
.class_data = model,
};
type_register(&ti);
}cpu 实例的继承关系如下
ArchX86 代表一个x86虚拟CPU
/**
* X86CPU:
* @env: #CPUX86State
* @migratable: If set, only migratable flags will be accepted when "enforce"
* mode is used, and only migratable flags will be included in the "host"
* CPU model.
*
* An x86 CPU.
*/
struct ArchCPU {
// X86 cpu 继承自 CPUState
CPUState parent_obj;
// 包含 CPUX86State 结构
CPUX86State env;
bool force_features;
bool expose_kvm;
bool expose_tcg;
// ...
/* if true the CPUID code directly forwards
* host monitor/mwait leaves to the guest */
struct {
uint32_t eax;
uint32_t ebx;
uint32_t ecx;
uint32_t edx;
} mwait;
//...
}CPUState 表示cpu通用数据,其中有核数,线程数,以及 kvm 相关数据
struct CPUState {
/*< private >*/
DeviceState parent_obj;
/* cache to avoid expensive CPU_GET_CLASS */
CPUClass *cc;
/*< public >*/
int nr_cores;
int nr_threads;
struct QemuThread *thread;
#ifdef _WIN32
QemuSemaphore sem;
#endif
int thread_id;
// ...
/* Only used in KVM */
int kvm_fd;
struct KVMState *kvm_state;
struct kvm_run *kvm_run;
struct kvm_dirty_gfn *kvm_dirty_gfns;
uint32_t kvm_fetch_index;
uint64_t dirty_pages;
int kvm_vcpu_stats_fd;
//...
};CPUX86State 中保存x86 cpu的特有数据
包括通用寄存器、eip、eflags段寄存器等寄存器的值,还有KVM相关的异常和中断信息以及CPUID的信息
typedef struct CPUArchState {
/* standard registers */
target_ulong regs[CPU_NB_REGS];
target_ulong eip;
target_ulong eflags; /* eflags register. During CPU emulation, CC
flags and DF are set to zero because they are
stored elsewhere */
// ...
/* KVM-only so far */
uint16_t fpop;
uint16_t fpcs;
uint16_t fpds;
uint64_t fpip;
uint64_t fpdp;
//...
} CPUX86State;CPU类的初始化
注册的x86 设备类信息包含 x86 类的初始化,实例的初始化
static const TypeInfo x86_cpu_type_info = {
.name = TYPE_X86_CPU,
.parent = TYPE_CPU,
.instance_size = sizeof(X86CPU),
.instance_align = __alignof(X86CPU),
.instance_init = x86_cpu_initfn,
.instance_post_init = x86_cpu_post_initfn,
.abstract = true,
.class_size = sizeof(X86CPUClass),
.class_init = x86_cpu_common_class_init,
};CPU类初始化 x86_cpu_common_class_init
注意其中具现化函数作了反转,具现化类时将现调用 x86_cpu_realizefn, 再调用 父类 CPU的具现化
static void x86_cpu_common_class_init(ObjectClass *oc, void *data)
{
X86CPUClass *xcc = X86_CPU_CLASS(oc);
CPUClass *cc = CPU_CLASS(oc);
DeviceClass *dc = DEVICE_CLASS(oc);
ResettableClass *rc = RESETTABLE_CLASS(oc);
FeatureWord w;
// 注册具现化函数,注意该方式将 x86_cpu_realizefn 注册到父类
// 将父类的具现化函数注册到该子类
device_class_set_parent_realize(dc, x86_cpu_realizefn,
&xcc->parent_realize);
device_class_set_parent_unrealize(dc, x86_cpu_unrealizefn,
&xcc->parent_unrealize);
// ...
// 注册附带属性
object_class_property_add(oc, "family", "int",
x86_cpuid_version_get_family,
x86_cpuid_version_set_family, NULL, NULL);
object_class_property_add(oc, "model", "int",
x86_cpuid_version_get_model,
x86_cpuid_version_set_model, NULL, NULL);
object_class_property_add(oc, "stepping", "int",
x86_cpuid_version_get_stepping,
x86_cpuid_version_set_stepping, NULL, NULL);
object_class_property_add_str(oc, "vendor",
x86_cpuid_get_vendor,
x86_cpuid_set_vendor);
object_class_property_add_str(oc, "model-id",
x86_cpuid_get_model_id,
x86_cpuid_set_model_id);
object_class_property_add(oc, "tsc-frequency", "int",
x86_cpuid_get_tsc_freq,
x86_cpuid_set_tsc_freq, NULL, NULL);
//...
}CPU的实例化
按照继承关系,首先调用TYPE_CPU的对象初始化函数cpu_common_initfn,该函数很简单,就是设置一些初始值。TYPE_X86_CPU的初始化函数是x86_cpu_initfn。每一个CPU创建的时候都会调用该函数,该函数的主要作用是创建X86 CPU实例的各种属性。
x86_cpu_initfn 流程如下
-
注册x86 构架 cpu通用信息
-
注册x86构架不同cpu芯片的差异性信息,信息来源cpu的model结构。
static void x86_cpu_initfn(Object *obj)
{
X86CPU *cpu = X86_CPU(obj);
X86CPUClass *xcc = X86_CPU_GET_CLASS(obj);
CPUX86State *env = &cpu->env;
env->nr_dies = 1;
// ...
object_property_add_alias(obj, "kvm_nopiodelay", obj, "kvm-nopiodelay");
object_property_add_alias(obj, "kvm_mmu", obj, "kvm-mmu");
object_property_add_alias(obj, "kvm_asyncpf", obj, "kvm-asyncpf");
object_property_add_alias(obj, "kvm_asyncpf_int", obj, "kvm-asyncpf-int");
object_property_add_alias(obj, "kvm_steal_time", obj, "kvm-steal-time");
object_property_add_alias(obj, "kvm_pv_eoi", obj, "kvm-pv-eoi");
object_property_add_alias(obj, "kvm_pv_unhalt", obj, "kvm-pv-unhalt");
object_property_add_alias(obj, "kvm_poll_control", obj, "kvm-poll-control");
object_property_add_alias(obj, "svm_lock", obj, "svm-lock");
object_property_add_alias(obj, "nrip_save", obj, "nrip-save");
object_property_add_alias(obj, "tsc_scale", obj, "tsc-scale");
// ...
if (xcc->model) {
x86_cpu_load_model(cpu, xcc->model);
}
}CPU的具现化
CPU类型初始化、对象实例初始化之后,还需要具现化才能让CPU对象可用
static void x86_cpu_realizefn(DeviceState *dev, Error **errp)
{
CPUState *cs = CPU(dev);
X86CPU *cpu = X86_CPU(dev);
X86CPUClass *xcc = X86_CPU_GET_CLASS(dev);
CPUX86State *env = &cpu->env;
Error *local_err = NULL;
static bool ht_warned;
unsigned requested_lbr_fmt;
// ...
// 检查物理机cpu是否支持该虚拟cpu
x86_cpu_filter_features(cpu, cpu->check_cpuid || cpu->enforce_cpuid);
if (cpu->enforce_cpuid && x86_cpu_have_filtered_features(cpu)) {
error_setg(&local_err,
accel_uses_host_cpuid() ?
"Host doesn't support requested features" :
"TCG doesn't support requested features");
goto out;
}
// ...
/*
* note: the call to the framework needs to happen after feature expansion,
* but before the checks/modifications to ucode_rev, mwait, phys_bits.
* These may be set by the accel-specific code,
* and the results are subsequently checked / assumed in this function.
*/
// cpu_exec_realizefn函数调用cpu_list_add函数将
// 正在初始化的CPU对象添加到一个全局链表cpus上
cpu_exec_realizefn(cs, &local_err);
if (local_err != NULL) {
error_propagate(errp, local_err);
return;
}
// ...
// 根据QEMU使用的加速器来执行对应的CPU初始化函数
// 如在KVM下会调用qemu_kvm_start_vcpu
qemu_init_vcpu(cs);
//...
}kvm_start_vcpu_thread 创建了线程, 执行 kvm_vcpu_thread_fn, 即与kvm 交互的 cpu 运转的管理逻辑
static void kvm_start_vcpu_thread(CPUState *cpu)
{
char thread_name[VCPU_THREAD_NAME_SIZE];
cpu->thread = g_malloc0(sizeof(QemuThread));
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
snprintf(thread_name, VCPU_THREAD_NAME_SIZE, "CPU %d/KVM",
cpu->cpu_index);
// 线程启动的 kvm_vcpu_thread_fn 中运行vcpu 的业务运算
qemu_thread_create(cpu->thread, thread_name, kvm_vcpu_thread_fn,
cpu, QEMU_THREAD_JOINABLE);
// ....
}KVM 中CPU的创建
Qemu 中创建 cpu时将 通过创建虚拟机时返回的fd执行ioctl, 命令类型为 KVM_CREATE_VCPU
内核收到调用后在 --enable-kvm 模式下将执行 kvm_vm_ioctl_create_vcpu
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
if (kvm->mm != current->mm || kvm->vm_dead)
return -EIO;
switch (ioctl) {
case KVM_CREATE_VCPU:
r = kvm_vm_ioctl_create_vcpu(kvm, arg);
break;
//...
}kvm_vm_ioctl_create_vcpu 流程为
-
针对不同的构架调用不同的vcpu创建流程创建vcpu
-
使用创建的vcpu获得设备文件fd
/*
* Creates some virtual cpus. Good luck creating more than one.
*/
static int kvm_vm_ioctl_create_vcpu(struct kvm *kvm, u32 id)
{
int r;
struct kvm_vcpu *vcpu;
struct page *page;
//...
vcpu = kmem_cache_zalloc(kvm_vcpu_cache, GFP_KERNEL_ACCOUNT);
if (!vcpu) {
r = -ENOMEM;
goto vcpu_decrement;
}
//...
kvm_vcpu_init(vcpu, kvm, id);
// 根据构架注册的回调函数初始化vcpu
r = kvm_arch_vcpu_create(vcpu);
if (r)
goto vcpu_free_run_page;
// ...
/* Now it's all set up, let userspace reach it */
kvm_get_kvm(kvm);
// 使用vcpu 结构获得 vcpu对应的文件操作描述符
r = create_vcpu_fd(vcpu);
if (r < 0) {
xa_erase(&kvm->vcpu_array, vcpu->vcpu_idx);
kvm_put_kvm_no_destroy(kvm);
goto unlock_vcpu_destroy;
}
//...
return r;
}kvm下且为amd的 物理cpu,在 vcpu创建时将调用下列函数
static int svm_vcpu_create(struct kvm_vcpu *vcpu)
{
struct vcpu_svm *svm;
struct page *vmcb01_page;
struct page *vmsa_page = NULL;
int err;
BUILD_BUG_ON(offsetof(struct vcpu_svm, vcpu) != 0);
svm = to_svm(vcpu);
err = -ENOMEM;
vmcb01_page = alloc_page(GFP_KERNEL_ACCOUNT | __GFP_ZERO);
if (!vmcb01_page)
goto out;
//...
err = avic_init_vcpu(svm);
if (err)
goto error_free_vmsa_page;
svm->msrpm = svm_vcpu_alloc_msrpm();
if (!svm->msrpm) {
err = -ENOMEM;
goto error_free_vmsa_page;
}
// 创建 存放 虚拟cpu信息的 svm 结构
svm->x2avic_msrs_intercepted = true;
svm->vmcb01.ptr = page_address(vmcb01_page);
svm->vmcb01.pa = __sme_set(page_to_pfn(vmcb01_page) << PAGE_SHIFT);
// 将当前物理cpu的svm指针 指向 创建的 vcpu 对应的 svm 结构。
svm_switch_vmcb(svm, &svm->vmcb01);
//...
return err;
}
void svm_switch_vmcb(struct vcpu_svm *svm, struct kvm_vmcb_info *target_vmcb)
{
svm->current_vmcb = target_vmcb;
svm->vmcb = target_vmcb->ptr;
}Qemu与kvm的数据共享
Qemu 与 kvm 间的数据共享是 qemu调用内存映射后,触发kvm缺页处理后,返回需要管理的数据映射地址。
int kvm_init_vcpu(CPUState *cpu, Error **errp)
{
KVMState *s = kvm_state;
long mmap_size;
int ret;
// 向内核发起请求查询 vcpu 对应 数据页大小
mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0);
if (mmap_size < 0) {
ret = mmap_size;
error_setg_errno(errp, -mmap_size,
"kvm_init_vcpu: KVM_GET_VCPU_MMAP_SIZE failed");
goto err;
}
// 申请 将 内核中 vcpu 信息页映射到用户空间
cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED,
cpu->kvm_fd, 0);
if (cpu->kvm_run == MAP_FAILED) {
ret = -errno;
error_setg_errno(errp, ret,
"kvm_init_vcpu: mmap'ing vcpu state failed (%lu)",
kvm_arch_vcpu_id(cpu));
goto err;
}
// 使用映射的内核中的 vcpu信息
if (s->coalesced_mmio && !s->coalesced_mmio_ring) {
s->coalesced_mmio_ring =
(void *)cpu->kvm_run + s->coalesced_mmio * PAGE_SIZE;
}
// ...
return ret;
}Kvm 中收到对vcpu句柄 内存映射时
从其代码可以看到,内核会在QEMU把对应的数据与虚拟地址空间联系起来。访问第一页的时候,实际上会访问到kvm_vcpu结构中类型为kvm_run的run成员;访问第二页的时候会访问到kvm_vcpu中类型为kvm_vcpu_arch的arch成员;访问第三页的时候会访问到整个虚拟机结构KVM中的coalesced_mmio_ring成员
static const struct vm_operations_struct kvm_vcpu_vm_ops = {
.fault = kvm_vcpu_fault,
};
static vm_fault_t kvm_vcpu_fault(struct vm_fault *vmf)
{
struct kvm_vcpu *vcpu = vmf->vma->vm_file->private_data;
struct page *page;
if (vmf->pgoff == 0)
page = virt_to_page(vcpu->run);
#ifdef CONFIG_X86
else if (vmf->pgoff == KVM_PIO_PAGE_OFFSET)
page = virt_to_page(vcpu->arch.pio_data);
#endif
#ifdef CONFIG_KVM_MMIO
else if (vmf->pgoff == KVM_COALESCED_MMIO_PAGE_OFFSET)
page = virt_to_page(vcpu->kvm->coalesced_mmio_ring);
#endif
else if (kvm_page_in_dirty_ring(vcpu->kvm, vmf->pgoff))
page = kvm_dirty_ring_get_page(
&vcpu->dirty_ring,
vmf->pgoff - KVM_DIRTY_LOG_PAGE_OFFSET);
else
return kvm_arch_vcpu_fault(vcpu, vmf);
get_page(page);
vmf->page = page;
return 0;
}vcpu的运行
VCPU的状态转移
为了更好地理解VCPU的运行,本节首先介绍与VCPU运行密切相关的一个概念,即VMCS。每个VCPU都会有一个对应的VMCS,VMCS的物理地址会作为操作数提供给VMX的指令。VMCS总共有如下4种状态。
1)Inactive:即只是分配和初始化VMCS结构或者是执行VMCLEAR指令之后的状态。
2)working:CPU在一个VMCS上执行了VMPTRLD指令或者产生VM exit之后所处的状态,这个时候CPU还是在VMX root状态。
3)Active:当前VMCS执行了VMPTRLD指令,同一个CPU执行了另一个VCPU的VMPTRLD之后,前一个VMCS所处的状态。
4)controlling:当CPU在一个VMCS上执行了VMLAUNCH指令之后CPU所处的VMX non-root状态。
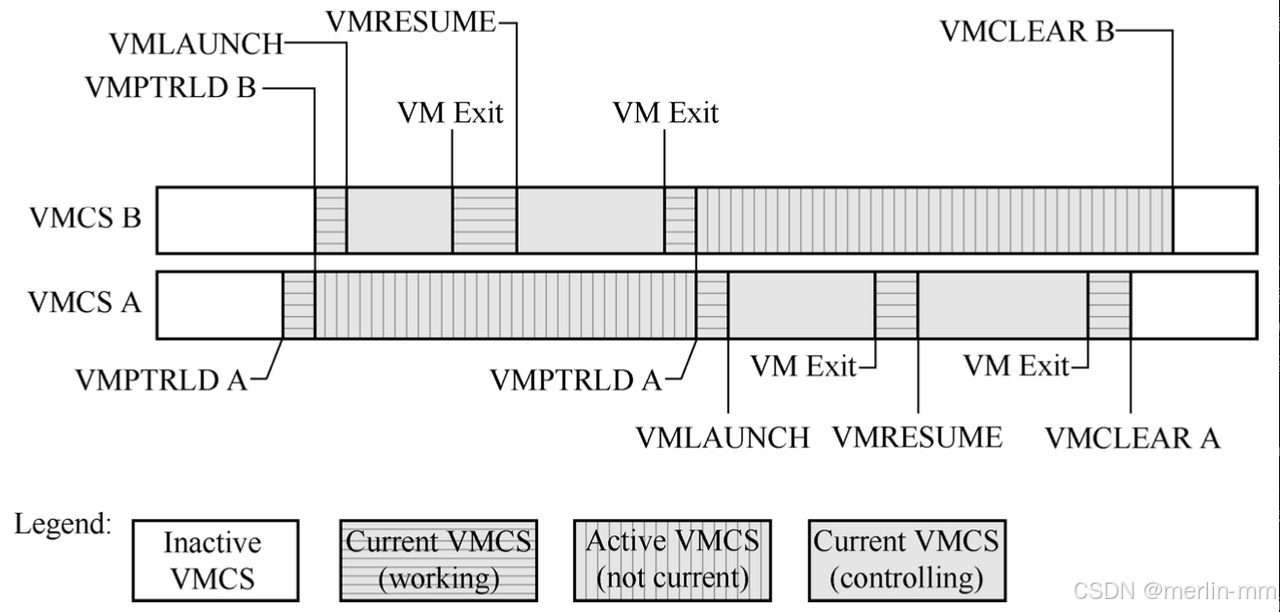
VCPU的运行步骤
要让一个虚拟机运行起来的步骤
-
在非分页内存中分配一个4KB对齐的VMCS区域,其大小通过IA32_VMX_BASIC MSR得到,对于KVM,这个过程主要是通过vmx_create_vcpu调用alloc_vmcs来完成的。
-
初始化VMCS区域的版本标识(VMCS区域的前31位),这也是通过IA32_VMX_BASIC SMR得到的,清除VMCS区域前4个字节的31位,对于KVM,这个过程在alloc_vmcs_cpu中完成。
-
使用VMCS的物理地址作为操作数执行VMCLEAR指令,这会将当前CPU的working-VMCS指针指向FFFFFFFF_FFFFFFFFH,指令执行完成之后检查RFLAGS.CF=0以及RFLAGS.ZE=0,对于KVM,这个过程主要通过loaded_vmcs_clear函数最终调用vmcs_clear来完成。
-
使用VMCS的物理地址执行VMPTRLD指令,这个时候CPU的working-VMCS指针指向VMCS区域的物理地址,对于KVM,这个过程通过vmx_vcpu_load调用vmcs_load来完成。
-
执行VMWRITE指令,初始化VMCS的host-state区域,当产生VM exit后,这个区域会用来创建宿主机的CPU状态和上下文,host-state区域包括控制寄存器(CR0、CR3以及CR4),段寄存器(CS、SS、DS、ES、FS、GS、TR)以及RSP、RIP和一些MSR寄存器,对于KVM,这个过程主要在vmx_vcpu_setup函数中完成。
-
执行VMWRITE指令,初始化VMCS中的VM-exit control区域、VM-entrycontrol区域以及VM-execution control区域。这些区域的某些数据需要根据VMXcapability MSR的报告设置,如MSR寄存器报告在当前CPU上某些位只能设置为0,对于KVM,这个过程主要在vmx_vcpu_setup函数中完成。
-
执行VMWRITE指令,初始化guest-state区域,当CPU进入VMX non-root模式 时会根据这些数据创建上下文,对于KVM,这个过程主要在vmx_vcpu_reset中完成。
-
guest-state的设置需要满足如下条件。① 如果虚拟机需要模拟一个从BIOS启动的完整OS,则需要将guest的状态设置为物理CPU加电时的状态。② 需要将VMM不能截获的guest-state数据正确设置,如通用寄存器、CR2控制寄存器、调试寄存器、浮点数寄存器等。
-
执行VMLAUNCH,使得CPU处于VMX non-root状态,如果这个过程出错,将会设置RFLAGS.CF或者RFLAGS.ZF,对于KVM,这个过程在vmx_vcpu_run中完成。
Qemu中VCPU的运行
qemu在vcpu的具现化中,启动了线程,在线程中执行方法 kvm_vcpu_thread_fn 如下
在循环中持续运转vcpu
static void *kvm_vcpu_thread_fn(void *arg)
{
CPUState *cpu = arg;
int r;
// ...
do {
//调用cpu_can_run来判断是否可以运行,如果cpu->stop和cpu->stopped都是false,
//说明可以运行,如果当前CPU不可运行,
//则调用qemu_wait_io_event将CPU等待在cpu->halt_cond条件上。
// 当 暂停后恢复虚拟机,中断事件处理完毕后等 都将 通过 resume_all_vcpus将 vcpu 线程
// 再次唤醒
if (cpu_can_run(cpu)) {
// 运转 vcpu 业务
r = kvm_cpu_exec(cpu);
if (r == EXCP_DEBUG) {
cpu_handle_guest_debug(cpu);
}
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
// ...
}
void qemu_wait_io_event(CPUState *cpu)
{
bool slept = false;
while (cpu_thread_is_idle(cpu)) {
if (!slept) {
slept = true;
qemu_plugin_vcpu_idle_cb(cpu);
}
// 线程进入条件睡眠
qemu_cond_wait(cpu->halt_cond, &bql);
}
if (slept) {
qemu_plugin_vcpu_resume_cb(cpu);
}
qemu_wait_io_event_common(cpu);
}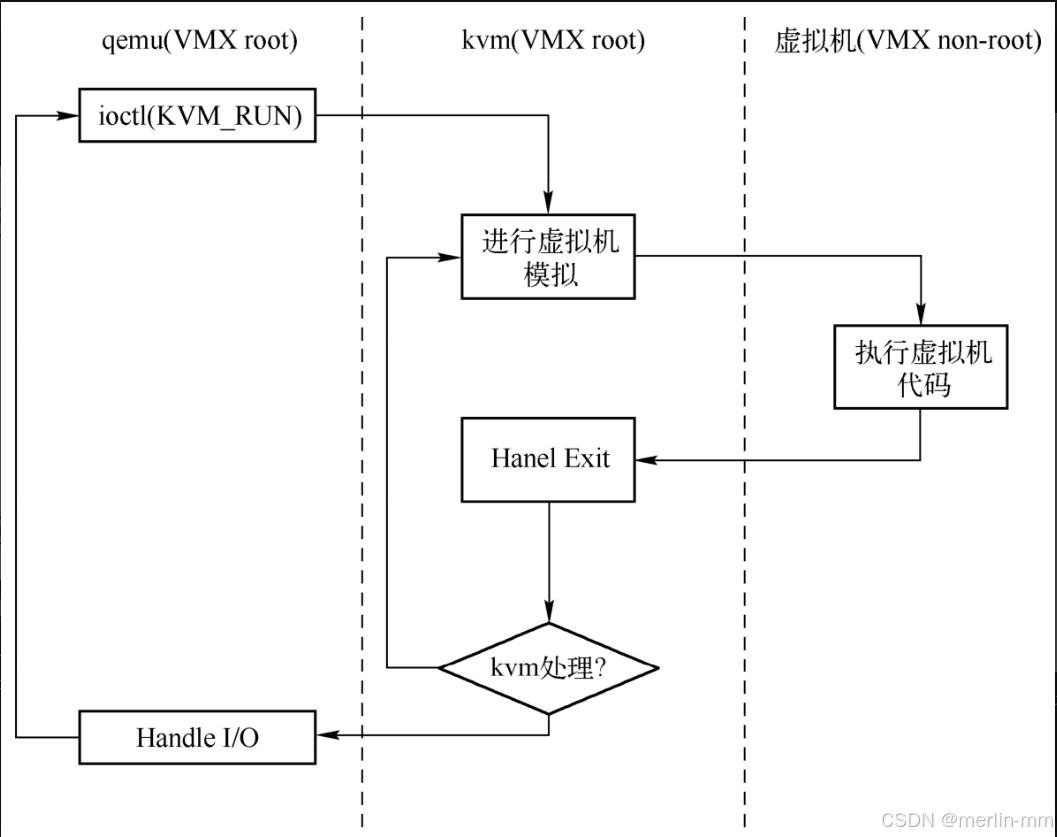
KVM中VCPU的运行
继续分析qemu调用 kvm_vcpu_ioctl(cpu, KVM_RUN, 0) 后内核的运行。
内核中调用 kvm_arch_vcpu_ioctl_run 处理 KVM_RUN事件。
kvm_arch_vcpu_ioctl_run 主要调用 vcpu_run 的逻辑运行vcpu
* Called within kvm->srcu read side. */
static int vcpu_run(struct kvm_vcpu *vcpu)
{
int r;
vcpu->arch.l1tf_flush_l1d = true;
for (;;) {
/*
* If another guest vCPU requests a PV TLB flush in the middle
* of instruction emulation, the rest of the emulation could
* use a stale page translation. Assume that any code after
* this point can start executing an instruction.
*/
vcpu->arch.at_instruction_boundary = false;
// 判断 vcpu 是否可运行,如果可以则会调用vcpu_enter_guest来进入虚拟机
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu);
} else {
// 在 io 中断, cpu所在虚拟机暂停等时候, 让度该cpu 调度
r = vcpu_block(vcpu);
}
if (r <= 0)
break;
kvm_clear_request(KVM_REQ_UNBLOCK, vcpu);
//...
}
return r;
}vcpu_enter_guest 主要流程为
-
进入guest前处理挂出的中断请求等。
-
准备guest模式。
-
切换cpu到gust模式运行。
static int vcpu_enter_guest(struct kvm_vcpu *vcpu)
{
int r;
bool req_int_win =
dm_request_for_irq_injection(vcpu) &&
kvm_cpu_accept_dm_intr(vcpu);
fastpath_t exit_fastpath;
bool req_immediate_exit = false;
// 处理中断请求
if (kvm_request_pending(vcpu)) {
if (kvm_check_request(KVM_REQ_VM_DEAD, vcpu)) {
r = -EIO;
goto out;
}
// ...
}
if (kvm_check_request(KVM_REQ_EVENT, vcpu) || req_int_win ||
kvm_xen_has_interrupt(vcpu)) {
++vcpu->stat.req_event;
r = kvm_apic_accept_events(vcpu);
if (r < 0) {
r = 0;
goto out;
}
if (vcpu->arch.mp_state == KVM_MP_STATE_INIT_RECEIVED) {
r = 1;
goto out;
}
r = kvm_check_and_inject_events(vcpu, &req_immediate_exit);
if (r < 0) {
r = 0;
goto out;
}
if (req_int_win)
static_call(kvm_x86_enable_irq_window)(vcpu);
if (kvm_lapic_enabled(vcpu)) {
update_cr8_intercept(vcpu);
kvm_lapic_sync_to_vapic(vcpu);
}
}
r = kvm_mmu_reload(vcpu);
if (unlikely(r)) {
goto cancel_injection;
}
preempt_disable();
// 准备从宿主机切换到客户机gust上下文模式
// 当为 amd 的物理 cpu时,对应函数为 svm_prepare_switch_to_guest
static_call(kvm_x86_prepare_switch_to_guest)(vcpu);
/*
* Disable IRQs before setting IN_GUEST_MODE. Posted interrupt
* IPI are then delayed after guest entry, which ensures that they
* result in virtual interrupt delivery.
*/
local_irq_disable();
/* Store vcpu->apicv_active before vcpu->mode. */
smp_store_release(&vcpu->mode, IN_GUEST_MODE);
// ...
for (;;) {
/*
* Assert that vCPU vs. VM APICv state is consistent. An APICv
* update must kick and wait for all vCPUs before toggling the
* per-VM state, and responsing vCPUs must wait for the update
* to complete before servicing KVM_REQ_APICV_UPDATE.
*/
WARN_ON_ONCE((kvm_vcpu_apicv_activated(vcpu) != kvm_vcpu_apicv_active(vcpu)) &&
(kvm_get_apic_mode(vcpu) != LAPIC_MODE_DISABLED));
// cpu进入guest 模式运行, amd 构架 cpu对应函数为 svm_vcpu_run
exit_fastpath = static_call(kvm_x86_vcpu_run)(vcpu);
if (likely(exit_fastpath != EXIT_FASTPATH_REENTER_GUEST))
break;
if (kvm_lapic_enabled(vcpu))
static_call_cond(kvm_x86_sync_pir_to_irr)(vcpu);
if (unlikely(kvm_vcpu_exit_request(vcpu))) {
exit_fastpath = EXIT_FASTPATH_EXIT_HANDLED;
break;
}
}
// ...
}svm_prepare_switch_to_guest 是一个与 AMD SVM (Secure Virtual Machine) 技术相关的函数,用于准备从宿主机切换到客户机(Guest)模式时的上下文。
主要功能
-
加载客户机的 VMCB (Virtual Machine Control Block)
-
VMCB 是 AMD SVM 的核心数据结构,包含虚拟机的状态和控制字段。
svm_prepare_switch_to_guest确保当前的 VMCB 被正确加载到硬件中。
-
-
配置控制寄存器 (CR3)
-
根据客户机的需求,设置 CR3 寄存器以指向客户机的页表,从而确保客户机的内存访问正确。
-
-
同步客户机状态
-
检查和更新客户机的运行状态(如寄存器、标志位等),将其与 VMCB 的内容同步。
-
-
设置处理器模式
-
如果客户机使用不同的 CPU 模式(如保护模式、长模式),则该函数会准备这些模式的切换。
-
-
检查必要的标志和配置
-
包括处理 TSC 偏移、控制寄存器影子值以及其他与虚拟化相关的配置。
-
在 Linux 内核中的 KVM 模块中,svm_vcpu_run 函数是 AMD SVM(Secure Virtual Machine)架构下用于运行虚拟 CPU(vCPU)的核心函数。它的主要作用是通过硬件虚拟化支持切换到客户机模式运行虚拟机代码,同时处理客户机模式和宿主机模式之间的切换。
static __no_kcsan fastpath_t svm_vcpu_run(struct kvm_vcpu *vcpu)
{
struct vcpu_svm *svm = to_svm(vcpu);
// ...
pre_svm_run(vcpu);
// 加载 guest 的状态到cpu, 准备进入guest模式
kvm_load_guest_xsave_state(vcpu);
kvm_wait_lapic_expire(vcpu);
// ...
// cpu 切换入guest模式运行
svm_vcpu_enter_exit(vcpu, spec_ctrl_intercepted);
if (!sev_es_guest(vcpu->kvm))
reload_tss(vcpu);
if (!static_cpu_has(X86_FEATURE_V_SPEC_CTRL))
x86_spec_ctrl_restore_host(svm->virt_spec_ctrl);
if (!sev_es_guest(vcpu->kvm)) {
vcpu->arch.cr2 = svm->vmcb->save.cr2;
vcpu->arch.regs[VCPU_REGS_RAX] = svm->vmcb->save.rax;
vcpu->arch.regs[VCPU_REGS_RSP] = svm->vmcb->save.rsp;
vcpu->arch.regs[VCPU_REGS_RIP] = svm->vmcb->save.rip;
}
vcpu->arch.regs_dirty = 0;
if (unlikely(svm->vmcb->control.exit_code == SVM_EXIT_NMI))
kvm_before_interrupt(vcpu, KVM_HANDLING_NMI);
// guest 模式退出时,cpu 加载 host 模式
kvm_load_host_xsave_state(vcpu);
// ...
/*
* We need to handle MC intercepts here before the vcpu has a chance to
* change the physical cpu
*/
// 部分中断退出时, 由kvm直接处理,不用返回用户层 qemu处理中断
if (unlikely(svm->vmcb->control.exit_code ==
SVM_EXIT_EXCP_BASE + MC_VECTOR))
svm_handle_mce(vcpu);
svm_complete_interrupts(vcpu);
if (is_guest_mode(vcpu))
return EXIT_FASTPATH_NONE;
return svm_exit_handlers_fastpath(vcpu);
}
svm_vcpu_enter_exit 调用__svm_sev_es_vcpu_run 或 __svm_vcpu_run 使 cpu 切换运行在guest模式。
__svm_sev_es_vcpu_run 和 __svm_vcpu_run 是 AMD SVM 虚拟化中的两个核心函数,它们的主要区别在于处理虚拟机加密状态的支持,尤其是针对 AMD SEV (Secure Encrypted Virtualization) 和 SEV-ES (SEV Encrypted State) 技术的不同需求。
static noinstr void svm_vcpu_enter_exit(struct kvm_vcpu *vcpu, bool spec_ctrl_intercepted)
{
struct vcpu_svm *svm = to_svm(vcpu);
guest_state_enter_irqoff();
if (sev_es_guest(vcpu->kvm))
__svm_sev_es_vcpu_run(svm, spec_ctrl_intercepted);
else
__svm_vcpu_run(svm, spec_ctrl_intercepted);
guest_state_exit_irqoff();
}
__svm_vcpu_run 使用汇编调用底层进, cpu 进入 guest 模式运行
/**
* __svm_vcpu_run - Run a vCPU via a transition to SVM guest mode
* @svm: struct vcpu_svm *
* @spec_ctrl_intercepted: bool
*/
SYM_FUNC_START(__svm_vcpu_run)
//...
.ifnc _ASM_ARG1, _ASM_DI
/*
* Stash @svm in RDI early. On 32-bit, arguments are in RAX, RCX
* and RDX which are clobbered by RESTORE_GUEST_SPEC_CTRL.
*/
mov %_ASM_ARG1, %_ASM_DI
.endif
/* Clobbers RAX, RCX, RDX. */
RESTORE_GUEST_SPEC_CTRL
/*
* Use a single vmcb (vmcb01 because it's always valid) for
* context switching guest state via VMLOAD/VMSAVE, that way
* the state doesn't need to be copied between vmcb01 and
* vmcb02 when switching vmcbs for nested virtualization.
*/
mov SVM_vmcb01_pa(%_ASM_DI), %_ASM_AX
1: vmload %_ASM_AX
//...
/* Enter guest mode */
sti
// 调用 vmrun cpu 进入 guest模式 运行
3: vmrun %_ASM_AX
//...
SYM_FUNC_END(__svm_vcpu_run)vcpu的调度
虚拟机的每一个VCPU都对应宿主机中的一个线程,通过宿主机内核调度器进行统一调度管理。如果不将虚拟机的VCPU线程绑定到物理CPU上,那么VCPU线程可能在每次运行时被调度到不同的物理CPU上,KVM必须能够处理这种情况。
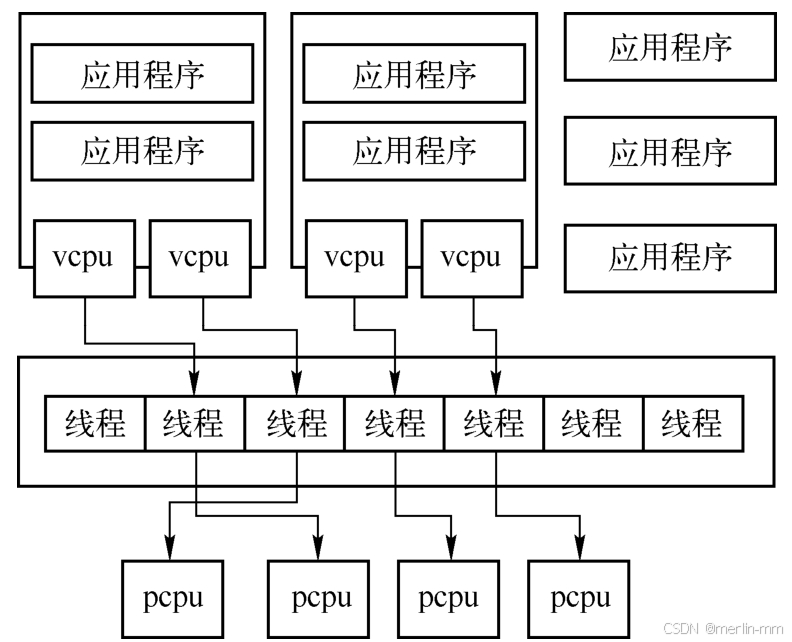
VCPU调度到不同物理CPU的基本步骤,然后再对源码进行分析。
-
在源物理CPU执行VMCLEAR指令,这可以保证将当前CPU关联的VMCS相关缓存数据冲刷到内存中。
-
在目的VMCS区域以VCPU的VMCS物理地址为操作数执行VMPTRLD指令。
-
在目的VMCS区域执行VMLAUNCH指令。
vcpu_load 将 对应 vcpu的vmcs 加载到物理cpu, 并开始抢占,抢占到后调用sched_in 后该物理cpu开始运行对应vcpu的逻辑。
vpu_put 则相反,是将物理cpu中的 vcpu对应数据刷写回vmcs, 并将该物理cpu与vcpu解除绑定,在被抢占后调用sched_out。
当物理cpu没有关联或抢占vcpu任务时也会调度执行host主机上的普通线程。
如下图,cpu在 pcpu1, vcpu1, pcpu2, 普通线程间切换。
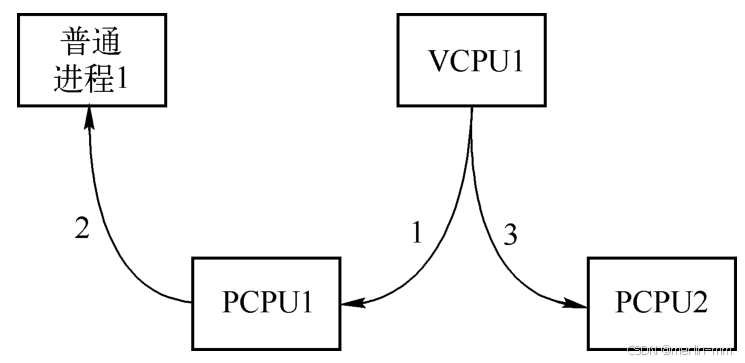
一个VCPU相关ioctl调用过程中的VCPU与物理CPU关联和解除关联的相关函数调用。

CPU虚拟化的调试
在kvm.ko 的 vcpu_run 处打断点
(gdb) b vcpu_run
Breakpoint 1 at 0xffffffffa023fdd1: file arch/x86/kvm/x86.c, line 10718.
(gdb) c
qemu启动虚拟机并运转,内核调试触发vcpu_run 进入vcpu配置
Breakpoint 1, vcpu_run (vcpu=0xffff88810259c800) at arch/x86/kvm/x86.c:10718
10718 vcpu->arch.l1tf_flush_l1d = true;
(gdb) bt
#0 vcpu_run (vcpu=0xffff88810259c800) at arch/x86/kvm/x86.c:10718
#1 kvm_arch_vcpu_ioctl_run (vcpu=vcpu@entry=0xffff88810259c800) at arch/x86/kvm/x86.c:10950
#2 0xffffffffa020deee in kvm_vcpu_ioctl (filp=0xffff888105c65200, ioctl=<optimized out>, arg=0) at arch/x86/kvm/../../../virt/kvm/kvm_main.c:4107
#3 0xffffffff8149656d in vfs_ioctl (arg=0, cmd=<optimized out>, filp=0xffff888105c65200) at fs/ioctl.c:51
#4 __do_sys_ioctl (arg=0, cmd=<optimized out>, fd=<optimized out>) at fs/ioctl.c:870
#5 __se_sys_ioctl (arg=0, cmd=<optimized out>, fd=<optimized out>) at fs/ioctl.c:856
#6 __x64_sys_ioctl (regs=<optimized out>) at fs/ioctl.c:856
#7 0xffffffff82089199 in do_syscall_x64 (nr=<optimized out>, regs=0xffffc900008c7f58) at arch/x86/entry/common.c:50
#8 do_syscall_64 (regs=0xffffc900008c7f58, nr=<optimized out>) at arch/x86/entry/common.c:80
#9 0xffffffff822000aa in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
设置vcpu相关,将物理cpu切换为guest模式后将触发物理cpu抢占调入
在抢占调入回调出打断点 b kvm_arch_sched_in, 继续运行,可见从设置cpu关联cpu后到 物理cpu抢占执行vcpu逻辑的调用链。
(gdb) b kvm_arch_sched_in
Breakpoint 2 at 0xffffffffa02443c0: file arch/x86/kvm/x86.c, line 12109.
(gdb) c
Continuing.
Breakpoint 2, kvm_arch_sched_in (vcpu=vcpu@entry=0xffff88810259c800, cpu=cpu@entry=0) at arch/x86/kvm/x86.c:12109
12109 {
(gdb) l
12104
12105 __read_mostly DEFINE_STATIC_KEY_FALSE(kvm_has_noapic_vcpu);
12106 EXPORT_SYMBOL_GPL(kvm_has_noapic_vcpu);
12107
12108 void kvm_arch_sched_in(struct kvm_vcpu *vcpu, int cpu)
12109 {
12110 struct kvm_pmu *pmu = vcpu_to_pmu(vcpu);
12111
12112 vcpu->arch.l1tf_flush_l1d = true;
12113 if (pmu->version && unlikely(pmu->event_count)) {
(gdb) bt
#0 kvm_arch_sched_in (vcpu=vcpu@entry=0xffff88810259c800, cpu=cpu@entry=0) at arch/x86/kvm/x86.c:12109
#1 0xffffffffa020acd0 in kvm_sched_in (pn=0xffff88810259c808, cpu=0) at arch/x86/kvm/../../../virt/kvm/kvm_main.c:5822
#2 0xffffffff81136bc5 in __fire_sched_in_preempt_notifiers (curr=<optimized out>) at kernel/sched/core.c:4859
#3 fire_sched_in_preempt_notifiers (curr=<optimized out>) at kernel/sched/core.c:4865
#4 finish_task_switch (prev=0xffff888106eeb380) at kernel/sched/core.c:5188
#5 0xffffffff8209c1b7 in context_switch (rf=0xffffc900008c7cd0, next=0xffff8881002a4d40, prev=<optimized out>, rq=<optimized out>) at kernel/sched/core.c:5302
#6 __schedule (sched_mode=sched_mode@entry=0) at kernel/sched/core.c:6612
#7 0xffffffff8209d363 in schedule () at kernel/sched/core.c:6688
#8 0xffffffff811c7f29 in xfer_to_guest_mode_work (ti_work=8, vcpu=<optimized out>) at kernel/entry/kvm.c:17
#9 xfer_to_guest_mode_handle_work (vcpu=vcpu@entry=0xffff88810259c800) at kernel/entry/kvm.c:47
#10 0xffffffffa02401e0 in vcpu_run (vcpu=0xffff88810259c800) at arch/x86/kvm/x86.c:10754
#11 kvm_arch_vcpu_ioctl_run (vcpu=vcpu@entry=0xffff88810259c800) at arch/x86/kvm/x86.c:10950
#12 0xffffffffa020deee in kvm_vcpu_ioctl (filp=0xffff888105c65200, ioctl=<optimized out>, arg=0) at arch/x86/kvm/../../../virt/kvm/kvm_main.c:4107
#13 0xffffffff8149656d in vfs_ioctl (arg=0, cmd=<optimized out>, filp=0xffff888105c65200) at fs/ioctl.c:51