Python Day51 学习(日志Day20复习)
补充:关于“适应度函数”
适应度函数(Fitness Function)是用来衡量一个解(或模型)“好坏”的函数,常见于遗传算法、进化算法、贝叶斯优化等智能优化方法中。
通俗理解:
适应度函数就像“打分标准”,用来评价每一个候选解的优劣。分数越高,说明这个解越优秀,越接近我们想要的目标。
在机器学习/优化中的作用:
- 输入:一个解(比如一组超参数、一个模型结构等)
- 输出:一个分数(比如准确率、损失值的相反数、收益等)
例子:
- 如果你在做分类问题,适应度函数可以是模型在验证集上的准确率。
- 如果你在做回归问题,适应度函数可以是负均方误差(MSE 越小越好,所以取负数让分数越大越好)。
总结:
适应度函数就是用来“打分”,帮助算法找到最优解的标准。分数越高,解越好。
关注在输出结果上
输出:
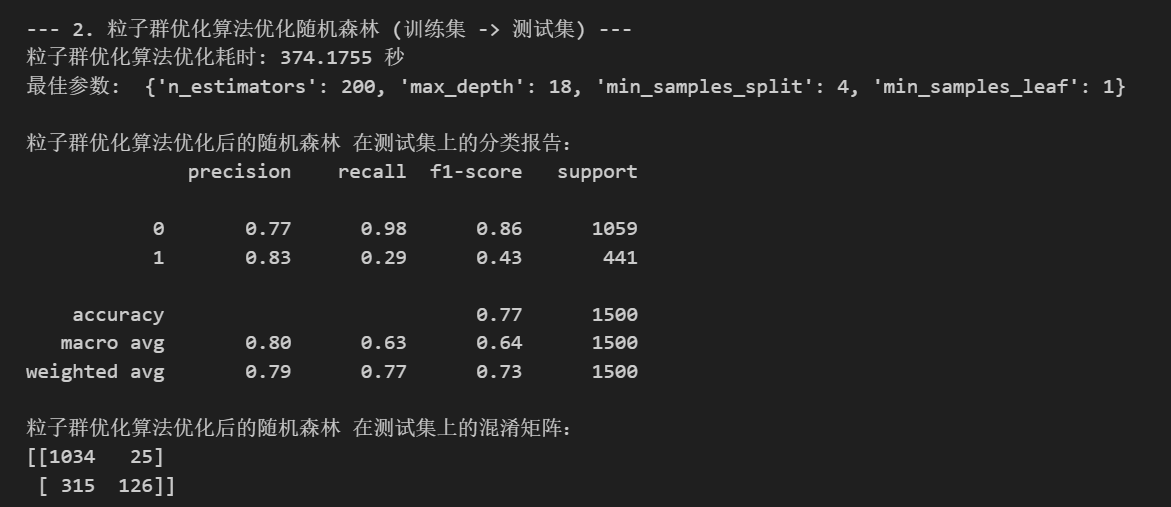
模型整体表现
- 准确率(accuracy):0.77,说明模型在测试集上有77%的样本预测正确。
对不同类别的表现
-
类别0(未违约):
- 精确率(precision):0.77
- 召回率(recall):0.98
- F1值:0.86
- 说明:模型对未违约用户识别得非常好,几乎不会漏掉未违约的样本(召回率高),但有一部分违约用户被误判为未违约(精确率略低于召回率)。
-
类别1(违约):
- 精确率:0.83
- 召回率:0.29
- F1值:0.43
- 说明:模型对违约用户的识别能力较弱,只有29%的违约用户被正确识别出来(召回率低),但一旦模型判断为违约,准确性还是比较高的(精确率高)。
混淆矩阵分析
- [[1034, 25], [315, 126]]
- 1034:真正例(未违约预测对了)
- 25:假正例(未违约被误判为违约)
- 315:假负例(违约被误判为未违约)
- 126:真负例(违约预测对了)
- 说明:模型更容易把违约用户预测成未违约(漏判较多),但很少把未违约预测成违约(错杀较少)。
类别不平衡影响
- 违约样本(1)召回率低,说明模型对少数类(违约)不敏感,容易漏判。
- 这在实际金融风控中可能不是理想结果,因为漏掉违约风险较大。
优化效果
- 粒子群优化后,模型参数为:
n_estimators=200, max_depth=18, min_samples_split=4, min_samples_leaf=1,说明模型容量较大,拟合能力较强,但对少数类的识别还可以进一步提升(比如通过调整类别权重、采样方法等)。
手写笔记复习


今日复习到这里,这一部分主要关注其输入输出,会调用即可。明日继续,加油!!!@浙大疏锦行