从代码学习深度学习 - 子词嵌入 PyTorch版
文章目录
- 前言
- fastText模型
- 字节对编码(BPE)
- 1. 初始化
- 2. 迭代合并
- 3. 应用BPE进行分词
- BPE 与 PyTorch
- 总结
前言
在自然语言处理(NLP)的早期阶段,词嵌入技术如Word2Vec和GloVe彻底改变了我们表示词汇的方式。它们能够将单词映射到低维稠密向量空间,捕捉词汇间的语义关系。然而,这些模型通常将每个单词视为一个独立的原子单元。这意味着它们难以处理:
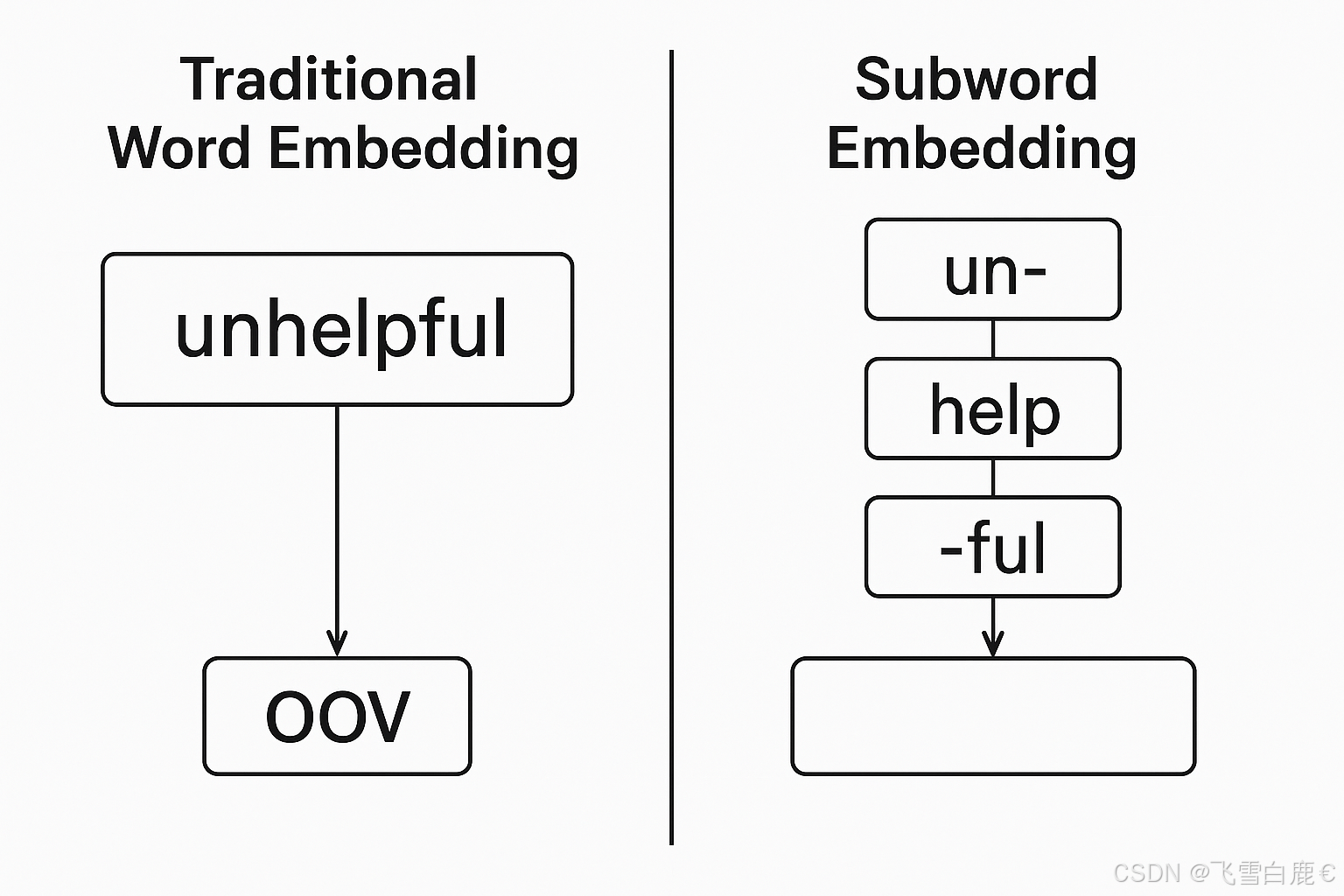
- 词形变化:例如,“help”,“helps”,“helped”和“helping”虽然词根相同,但会被视为完全不同的词,拥有独立的向量表示,无法共享学习到的信息。
- 罕见词和未登录词(Out-of-Vocabulary, OOV):对于训练集中未出现或出现次数极少的词,模型无法为其生成有意义的向量。
- 词的内部结构:像“dog”和“dogs”,“cat”和“cats”,或者“boy”和“boyfriend”这类具有明显内部结构和派生关系的词,传统词嵌入模型无法有效利用这些信息。
为了解决这些问题,子词嵌入(Subword Embedding) 的概念应运而生。其核心思想是将词分解为其组成部分(子词),然后基于这些子词来构建词的表示。这样做的好处是:
- 共享统计强度:形态相似的词(如“helping”和“eating”)会共享一些子词(如“-ing”),从而共享它们子词向量的参数。
- 处理OOV词:即使一个词在训练集中未出现,只要它的子词出现过,模型依然可以为其构建一个合理的向量表示。
- 更细粒度的语义:通过子词,模型可以捕捉到词缀(前缀、后缀)等形态学信息。
本文将重点介绍两种与子词嵌入相关的技术:fastText模型 和 字节对编码(Byte Pair Encoding, BPE)。我们将通过代码实例深入理解BPE的原理和实现,并探讨它如何为现代NLP模型(尤其是基于PyTorch等深度学习框架的模型)提供强大的文本表示能力。
完整代码:下载链接
fastText模型
在跳元模型(Skip-gram)和连续词袋模型(CBOW)中,同一词的不同变形形式(如"help", “helps”, “helped”)直接由不同的向量表示,不需要共享参数。为了利用形态学信息,fastText模型 提出了一种子词嵌入方法,其中子词是一个字符 n n n-gram。fastText可以被认为是子词级的跳元模型,它不直接学习词级向量表示,而是将每个中心词的向量表示为其所有子词向量之和。
具体来说,以单词“where”为例,在fastText中获取其子词的步骤如下:
- 在词的开头和末尾添加特殊字符“<”和“>”,以将前缀和后缀与其他子词区分开来。词变为“<where>”。
- 然后,从词中提取字符 n n n-gram。例如,当 n = 3 n=3 n=3时,我们将获得长度为3的所有子词:“<wh”“whe”“her”“ere”“re>”。
- 除了这些 n n n-gram子词,fastText还会将整个词本身(加上尖括号,如“<where>”)作为一个特殊的子词。
在fastText中,对于任意词 w w w,用 G w \mathcal{G}_w Gw表示其长度在指定范围(例如3到6)之间的所有子词与其特殊子词的并集。词表就变成了所有词的子词的集合。假设 z g \mathbf{z}_g zg是词典中子词 g g g的向量,则跳元模型中作为中心词的词 w w w的向量 v w \mathbf{v}_w vw是其子词向量的和:
v w = ∑ g ∈ G w z g . \mathbf{v}_w = \sum_{g\in\mathcal{G}_w} \mathbf{z}_g. vw