npu 瑞芯微rk系列,rknn模型转换以及npu使用
NPU介绍
简介
NPU(Neural Processing Unit,神经网络处理单元)是一种专门用于加速人工智能计算任务的处理器。它是为运行复杂的神经网络算法而设计的,通常用于推理(inference)和有时用于训练(training)深度学习模型。NPU是AI加速器的一种,它旨在提供比传统CPU和GPU更高的能效比和性能。
为什么需要npu
-
特定优化:NPU针对深度学习和神经网络计算进行了专门的优化,可以更高效地执行矩阵乘法、卷积运算等深度学习任务。
-
能效比:NPU在执行特定任务时,能效比远高于传统的CPU。它们可以在低功耗下提供高性能,这对于移动设备和边缘计算设备尤为重要。
-
并行处理:NPU设计有大量的并行处理单元,能够同时处理多个计算任务,这对于需要大规模并行处理的深度学习模型来说是一个巨大优势。
NPU与CPU的区别
设计目标
CPU:作为通用处理器,CPU的设计目标是处理各种类型的数据和指令,包括逻辑判断、数值计算等。
NPU:NPU专为深度学习和神经网络计算设计,其硬件和指令集针对这些特定任务进行了优化。
性能
CPU:CPU在处理复杂的通用计算任务时非常灵活,但在执行深度学习任务时,其性能和能效可能不如NPU。
NPU:NPU可以显著提高深度学习任务的计算速度,同时保持较低的功耗。
架构
CPU:CPU通常由多个核心组成,每个核心可以执行顺序计算任务。
NPU:NPU包含大量并行处理单元,这些单元可以同时执行相同的或不同的计算任务。
适用场景
CPU:CPU适用于广泛的计算任务,包括操作系统管理、应用程序运行等。
NPU:NPU专门用于加速深度学习模型中的推理和训练过程。
可编程性
CPU:CPU具有很高的可编程性,可以动态调整来执行不同的任务。
NPU:NPU的可编程性相对较弱,其硬件架构和指令集通常是固定的,优化用于特定的深度学习任务。
总结:NPU的引入是为了更高效地处理AI相关任务,它在性能和能效上对比CPU有明显的优势,但牺牲了一些通用性和可编程性。随着人工智能技术的快速发展,NPU已经成为许多AI设备和系统中的一个关键组件
关键特点和介绍
功能和设计
专用的架构:NPU采用专门为神经网络计算设计的架构,这些架构针对深度学习中的特定操作(如卷积、池化、激活函数等)进行了优化。
能效比:NPU旨在提供高能效比,这意味着它们可以在较低功耗下提供高性能,这对于移动设备和边缘计算非常重要。
应用场景
推理:NPU广泛用于执行推理任务,如图像识别、语音识别、自然语言处理等。
边缘计算:在边缘计算环境中,NPU可以帮助设备在没有云连接的情况下进行本地AI处理。
NPU优势
性能:NPU可以显著提高深度学习模型的处理速度。
能效:由于NPU专为深度学习任务设计,因此在执行这些任务时比传统的CPU或GPU更节能。
简化开发:使用NPU可以简化深度学习应用的开发过程,因为它们通常配备有易于使用的API和软件库。
未来趋势
随着AI技术的不断发展,NPU的设计和功能也在不断进步。未来的NPU可能会集成更先进的特性,如更高效的计算架构、更强大的并行处理能力以及对新型神经网络的支持。
瑞芯微rknpu
发展史
早期发展
瑞芯微电子成立于2001年,最初是一家专注于集成电路设计的公司,主要产品是嵌入式处理器和相关IP。随着人工智能技术的兴起,瑞芯微开始关注到AI计算的需求,并逐步投入资源开发专用的AI加速器。
rknpu的引入
瑞芯微在原有的处理器产品基础上,引入了rknpu技术,这是一种专门为神经网络计算设计的硬件加速器。rknpu的引入标志着瑞芯微正式进入AI处理器市场,并为用户提供了一种高效的AI计算解决方案。
rknpu的迭代
瑞芯微不断迭代其rknpu产品线,推出了多个版本的NPU,每个版本都在性能、能效和兼容性方面进行了改进。以下是一些关键的迭代:
RK3399Pro:这是瑞芯微推出的一款集成了NPU核心的高性能AI处理器,适用于需要强大AI计算能力的场景。
RK1808:这款SoC集成了NPU,适用于边缘计算和工业自动化等领域,提供了平衡的性能和能效。
RK3566/RK3568:这些是瑞芯微推出的新一代处理器,其中集成了第三代rknpu,提供了更高的性能和能效比。
RK3588:瑞芯微 RK3588 芯片内置 NPU,是 RKNPU 第四代的代表产品。
- 支持三核合作模式,双核合作模式,核心单独工作模式。
- 支持整数 4、整数 8、整数 16、浮点 16、Bfloat 16 和 tf32 运算
- 内置的 NPU 支持 INT4/INT8/INT16/FP16/TF32 混合操作
- 推理工具支持:TensorFlow、Caffe、Tflite、Pytorch、Onnx NN、Android NN等
- 高达 6 TOPS 的神经网络加速处理性能。
技术进步
随着技术的进步,瑞芯微的rknpu在以下几个方面取得了显著的发展:
- 性能提升:瑞芯微不断优化NPU架构,提高了算力,使得rknpu能够处理更复杂的神经网络模型。
- 能效优化:通过改进设计和制造工艺,瑞芯微的rknpu在低功耗下依然能够提供高性能。
- 软件生态:瑞芯微为rknpu提供了软件开发工具和API,支持多种神经网络框架,使得开发者能够更容易地集成AI功能。
市场应用
瑞芯微的rknpu已经被广泛应用于多个领域,包括智能摄像头、智能家居、边缘计算、工业自动化等。随着AI技术的普及,rknpu的市场应用范围也在不断扩大。
未来展望
瑞芯微继续在AI领域进行研发投入,未来可能会推出更先进的rknpu产品,以满足不断增长的市场需求和应对激烈的行业竞争。
rknpu开发环境部署
在虚拟机下新建一个目录来存放rknn仓库,在这里我建一个mlknpu的文件夹,并将RKNN-Toolkit2仓 库存放至该目录下
mkdir mlknpu
cd mlknpu下载
通过指令下载,注意:虚拟机网络需要开启代理
git clone https://github.com/airockchip/rknn-toolkit2.git --depth 1RKNN-Toolkit2 工具
介绍
RKNN-Toolkit2 是由瑞芯微电子(Rockchip)开发的一款深度学习模型优化和推理工具,旨在帮助开发者在瑞芯微SoC上进行AI应用的开发。
主要特点和功能
模型转换
- 支持将多种深度学习框架的模型(如Caffe、TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch等)转换为RKNN格式,使其能够在瑞芯微的NPU(神经处理单元)上运行。
- 支持RKNN模型的导入和导出,便于在不同的环境中使用。
量化功能
- 支持将浮点模型量化为定点模型,以减少模型大小和提高推理速度。目前支持的量化方法包括非对称量化(asymmetric quantized-8和asymmetric quantized-16)以及混合量化。
模型推理
- 能够在PC上模拟NPU运行RKNN模型,从而获取推理结果。
- 支持将RKNN模型分发到指定的NPU设备上进行推理,获取推理结果。
性能和内存评估
- 提供性能评估功能,帮助开发者分析模型在不同NPU设备上的性能表现。
- 支持内存评估,以便开发者了解模型在不同平台上的内存占用情况。
环境搭建
- 支持使用miniconda或Anaconda创建虚拟环境,以便在不同的开发环境中隔离依赖和配置。
平台兼容性
- RKNN-Toolkit2可以在PC平台上使用,同时也可以在瑞芯微的主板上使用。
编程接口
- 提供Python接口,方便开发者使用Python进行模型转换、推理和性能评估。
- 提供C/C++接口,供开发者在瑞芯微的硬件平台上部署和运行RKNN模型。
安装RKNN-Toolkit2 环境
安装python
Python建议安装3.8版本
sudo apt-get install python3
python3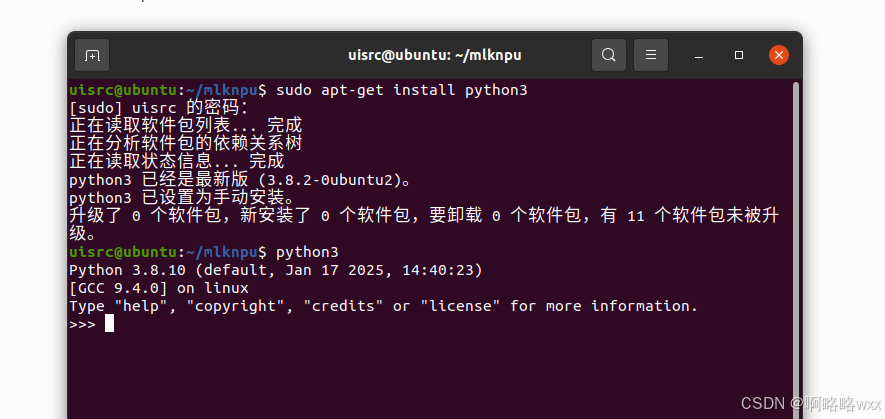
安装miniforge
获取miniforge安装包有两种方法,第一种方法直接从米联客资料包获取

第二种方法就是通过指令下载,同样需要代理,建议第一种方式
wget -c https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh
通过以下命令安装miniforge
chmod 777 Miniforge3-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh安装过程中按enter和输入yes即可
检查是否安装成功
conda -V
创建toolkit2
创建一个名为toolkit2的python3.8环境:
conda create -n toolkit2 python=3.8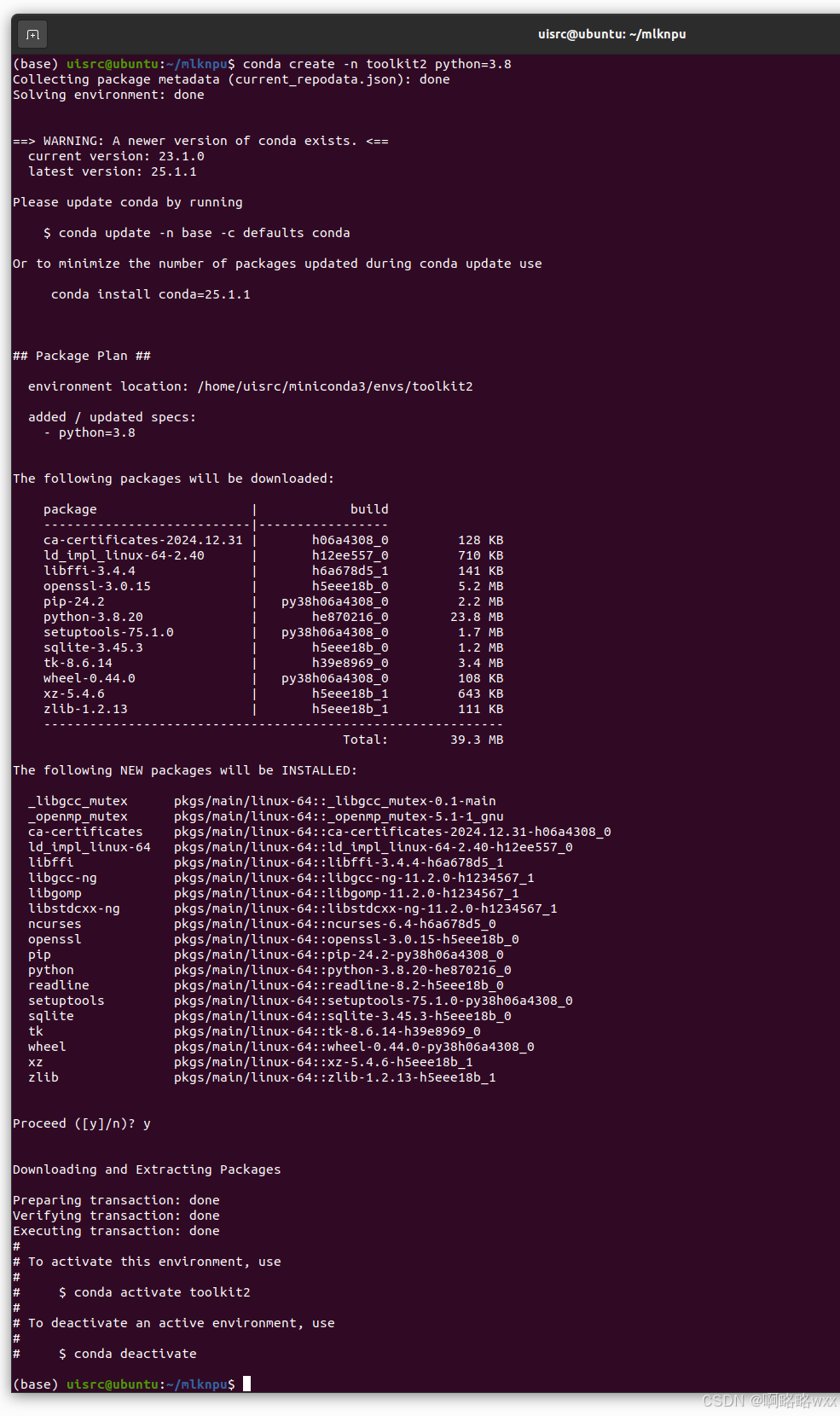
激活toolkit2环境,然后在此环境安装RKNN-Toolkit2:
conda activate toolkit2
安装RKNN-Toolkit2
在激活toolkit2环境下安装
方法有两种
pip安装
第一种通过pip源安装
pip install rknn-toolkit2 -i Simple index升级指令
pip install rknn-toolkit2 -i https://pypi.org/simple --upgrade本地安装
第二种方法就是本地wheel包安装
进入到rknn-toolkit2目录
cd mlknpu/rknn-toolkit2-master/rknn-toolkit2/packages/x86_64输入指令下载,请自行确认requirements文件
# python3.8 x86_64 对应 requirements_cp38.txt
# python3.8 ARM64 对应 arm64_requirements_cp38.txt
pip install -r requirements_cp38-2.3.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装 RKNN-Toolkit2
# 请根据不同的 python 版本及处理器架构,选择不同的 wheel 安装包文件:
# 其中 x.x.x 是 RKNN-Toolkit2 版本号,cpxx 是 python 版本号,<arch> 是处理器架构类型 (x86_64 对应x86_64/aarch64 对应 ARM64)
pip install rknn_toolkit2-2.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple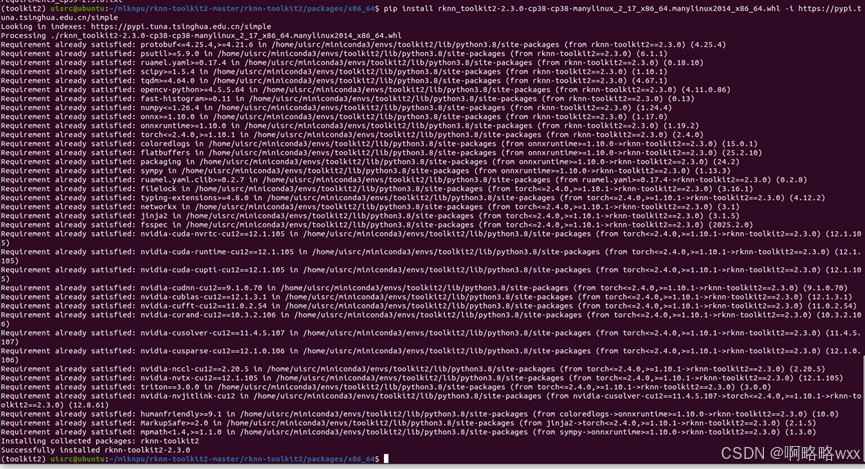
验证
验证RKNN-Toolkit2 环境有没有安装成功
# 进入 Python 交互模式
# 导入 RKNN 类
python
from rknn.api import RKNN
rknn实验
RKNN Model Zoo介绍
RKNN Model Zoo 仓库是一个由瑞芯微电子(Rockchip)提供的开源项目,它是RKNN(Rockchip Neural Network)推理框架的一部分。这个仓库包含了一系列预训练的深度学习模型和相关的工具,旨在帮助开发者在瑞芯微的芯片上快速部署和测试AI应用。
特点
以下是RKNN Model Zoo 仓库的一些主要特点:
预训练模型:仓库中包含了多种预训练的深度学习模型,这些模型通常是在瑞芯微的NPU(神经网络处理单元)上进行了优化和测试的。这些模型涵盖了不同的应用场景,如图像分类、目标检测、人脸识别等。
模型转换工具:RKNN Model Zoo 提供了工具来帮助开发者将其他深度学习框架(如TensorFlow、PyTorch、Caffe等)的模型转换为RKNN支持的格式。这包括了一些转换脚本和指南,以便开发者能够轻松地进行模型迁移。
性能评估:仓库中还包含了用于评估模型性能的工具,如基准测试脚本和性能分析工具,这有助于开发者在部署前了解模型在不同瑞芯微芯片上的表现。
示例代码:RKNN Model Zoo 还提供了示例代码,展示了如何使用RKNN框架加载和运行模型,以及如何集成到应用程序中。
社区支持:作为一个开源项目,RKNN Model Zoo 仓库还吸引了广泛的社区支持。开发者和使用者可以提交问题、贡献代码或分享他们的经验,以促进社区的交流和项目的改进。
兼容性:RKNN Model Zoo 设计为与瑞芯微的NPU和芯片系列兼容,包括RK1808、RK3399、RK3566、RK3588等。
更新和维护 :瑞芯微会定期更新RKNN Model Zoo 仓库,以包括最新的模型和工具,并确保与最新版本的RKNN框架保持兼容。
获取源码
获取RKNN Model Zoo 仓库有两种方法
- 第一种方法,直接从米联客rk3588资料包获取
- 在虚拟机输入指令获取RKNN Model Zoo 仓库
指令
git clone https://github.com/airockchip/rknn_model_zoo.git --depth 1
我们进入RKNN Model Zoo 仓库
我们先获取一个onnx模型,以onnx模型为例,转换成rknn模型
获取模型方式
进入到/home/uisrc/mlknpu/rknn_model_zoo/examples/yolov5/model路径下
输入指令下载该模型
chmod 777 download_model.sh
./download_model.sh
我们切换到toolkit2环境下,然后进行模型转换输入指令
python convert.py ../model/yolov5s_relu.onnx rk3588 i8 ../model/yolov5s_relu.rknn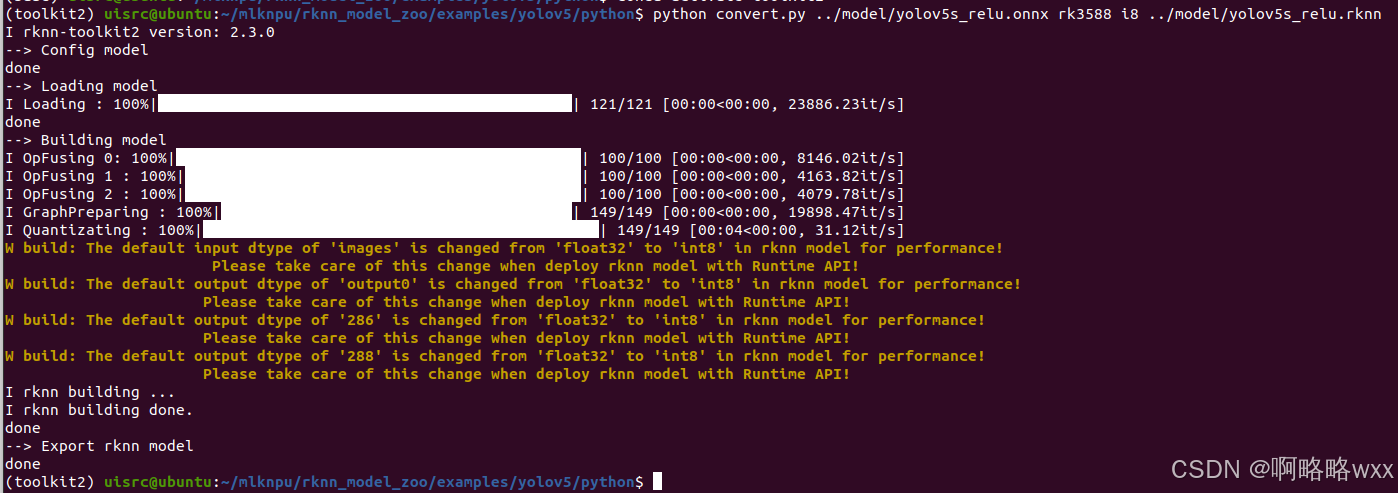
这时候我们就会发现多出一个rknn模型,该模型可以再rk3588开发板上运行
onnx在电脑主机运行 (rknn python demo)
我们先运行一下onnx模型查看一下效果
在电脑主机运行onn模型,输入指令
python yolov5.py --model_path ../model/yolov5s_relu.onnx --img_show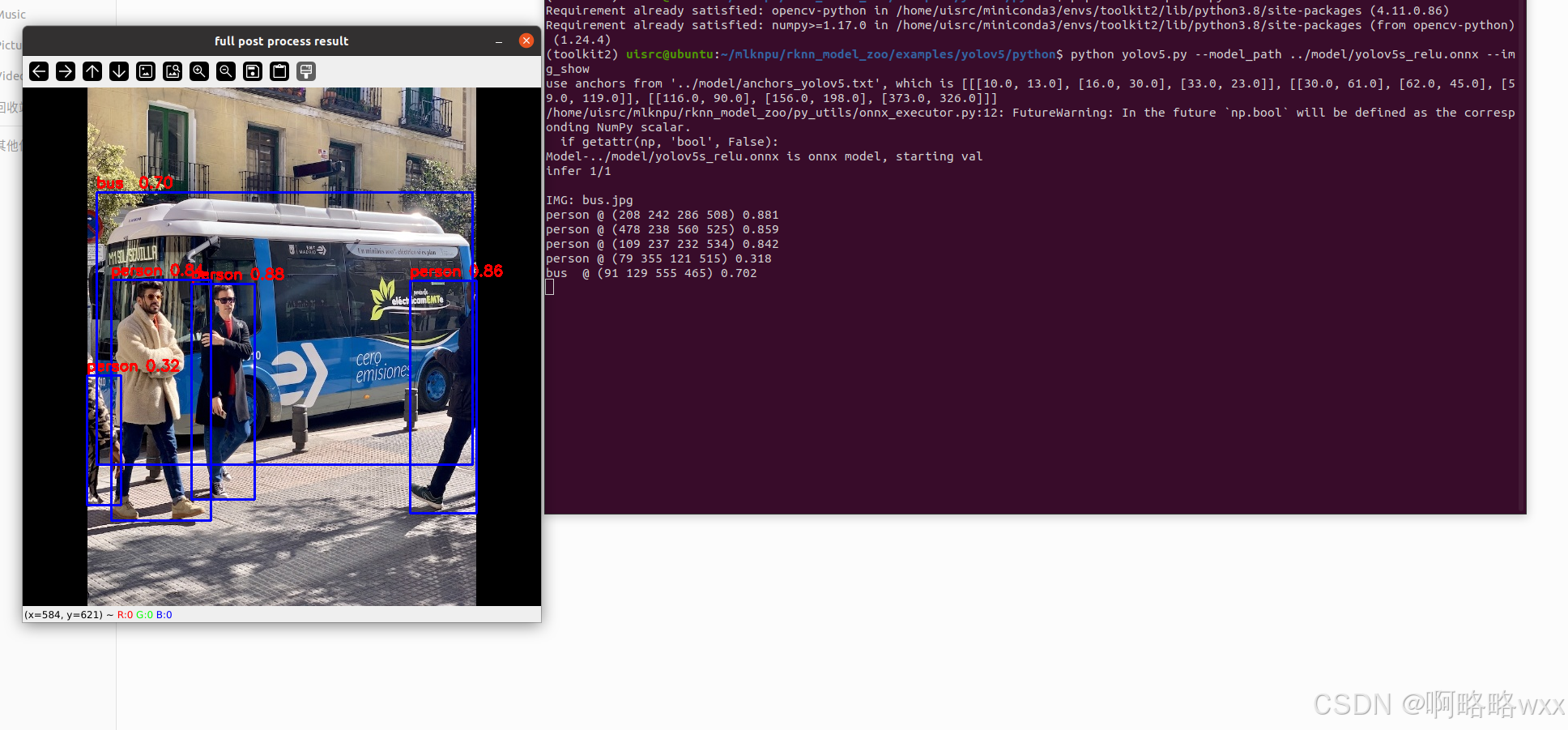
ps:如果想在开发板上运行,直接把模型后缀onnx改成rknn即可,在开发板运行指令如下
python yolov5.py --model_path ../model/yolov5s_relu.rknn --target rk3588onnx模型介绍
在这里对onnx模型做一下简单的介绍
概念
ONNX(Open Neural Network Exchange)模型是一种开放的神经网络交换格式,它允许不同的深度学习框架之间无缝地交换和部署训练好的模型。以下是ONNX模型的详细介绍以及它可以在哪些架构上运行:
ONNX模型介绍
目标:ONNX的目的是解决不同深度学习框架之间模型兼容性问题,使用户能够在不同的框架和平台上共享和部署模型,而无需重新训练。
特性:
- 跨平台部署:ONNX模型可以在多种硬件和软件平台上运行,包括但不限于移动设备、嵌入式设备和云服务器。
- 框架互操作性:支持将模型从一个框架(如PyTorch、TensorFlow等)转换为ONNX格式,然后在另一个框架中加载和使用。
- 模型优化:ONNX提供了工具和技术来优化模型,提高性能和效率,减少存储和计算成本。
- 扩展性:用户可以定义和使用自定义运算符和层,增加了模型的灵活性。
- 社区支持:ONNX由一个活跃的开源社区维护和发展,提供文档、工具和示例代码。
ONNX模型可以运行的架构
- CPU:ONNX模型可以在基于x86和ARM架构的CPU上运行。
- GPU:支持NVIDIA GPU(通过CUDA)、AMD GPU(通过ROCm)以及其他支持OpenCL的GPU。
- TPU:ONNX模型也可以部署在Google的Tensor Processing Units上。
- FPGA:某些特定硬件,如FPGA,也支持ONNX模型的部署。
- 云平台:ONNX模型可以部署到主流云平台,如Azure、AWS和Google Cloud。
- 移动和嵌入式设备:ONNX支持在Android和iOS等移动操作系统上运行,以及各种嵌入式设备。
- 自定义硬件:ONNX的扩展性允许在自定义硬件上部署模型。
通过这种跨平台的兼容性,ONNX极大地简化了深度学习模型从开发到部署的流程,提高了开发效率和模型的灵活应用性。
rknn模型介绍
RKNN(Rapid Kernel Neural Network)模型是针对边缘计算设备,特别是Rockchip(瑞芯微)芯片平台优化的一种神经网络模型格式。
RKNN模型基本概念
- 模型格式:RKNN模型是一种专为边缘设备设计的神经网络模型格式,其文件后缀通常为`.rknn`。
- 设计目的:RKNN模型旨在优化模型在Rockchip芯片上的运行性能,特别是在处理速度和功耗方面,使得深度学习模型可以在资源受限的设备上高效运行。
- 转换过程:通常,RKNN模型是由其他通用深度学习框架(如TensorFlow、PyTorch、ONNX等)训练得到的模型转换而来的。
RKNN模型的特点
- 性能优化:RKNN模型经过优化,可以在Rockchip芯片上的NPU(神经网络处理器)上实现更快的推理速度和更低的功耗。
- 模型量化:支持将浮点数模型量化为定点数模型,这可以减少模型大小,加快模型的运行速度,并降低功耗。
- 易于部署:RKNN模型可以直接部署到支持Rockchip芯片的设备上,通过RKNN提供的API进行调用和运行。
- 硬件兼容性:RKNN模型与Rockchip的芯片系列兼容,包括RK3588、RK3576、RK3566/RK3568、RK3562等。
数据采集评估
rknn_model_zoo/datasets 目录存放数据集,用于精度评估,需要先下载评估数据集并保存至该目录。
对于YOLOv5模型,需要下载 COCO 数据集。进入 rknn_model_zoo/datasets/COCO 目录,运行 download_eval_dataset.py 脚本
cd /home/uisrc/mlknpu/rknn_model_zoo/datasets/COCO
python download_eval_dataset.py安装pycocotools
pip install pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple这里简单介绍一下pycocotools
‘pycocotools’ 是一个开源的 Python 库,它提供了一个接口来访问和操作 COCO(Common Objects in Context)数据集。COCO 数据集是一个广泛使用的数据集,它包含了大量的图像和相应的注释,这些注释涵盖了目标检测、实例分割、人体关键点检测、素材分割和图像字幕生成等多个任务。
以下是 ‘pycocotools’ 的一些关键特点:
- 数据加载:‘pycocotools’ 支持读取 COCO 格式的标注文件,为模型的训练和验证提供数据支持。
- 数据解析:它能够解析图像的元数据,包括图像 ID、宽度、高度,以及图像中对象的边界框(bounding boxes)和分割掩码(segmentation masks)。
- 数据生成:根据需要,`pycocotools` 可以生成训练所需的批处理数据,包括图像、边界框和分割掩码等。
- 评估指标计算:该库提供了 COCO 数据集的官方评估指标,如平均精度(Average Precision, AP)和 Intersection over Union(IoU)等,用于评估模型性能。
- 结果可视化:`pycocotools` 支持将检测或分割的结果可视化,这可以帮助研究人员直观地理解模型的效果。
在目标检测和实例分割任务中,`pycocotools` 起到了非常重要的作用,因为它使得处理 COCO 数据集变得更加容易和高效。它常被用于以下场景:
- 研究:研究人员可以利用 `pycocotools` 来加载和评估他们在 COCO 数据集上的实验结果。
- 开发:开发人员可以通过 `pycocotools` 来集成 COCO 数据集的支持,开发新的目标检测或分割算法。
- 教育:教育工作者可以利用这个库来教授计算机视觉相关课程,特别是涉及到目标检测和实例分割的课程。
运行 yolov5.py 脚本
如果在自己主机上运行,请使用onnx模型,运行指令如下
python yolov5.py --model_path ../model/yolov5s_relu.onnx --img_folder ../../../datasets/COCO/val2017 --coco_map_test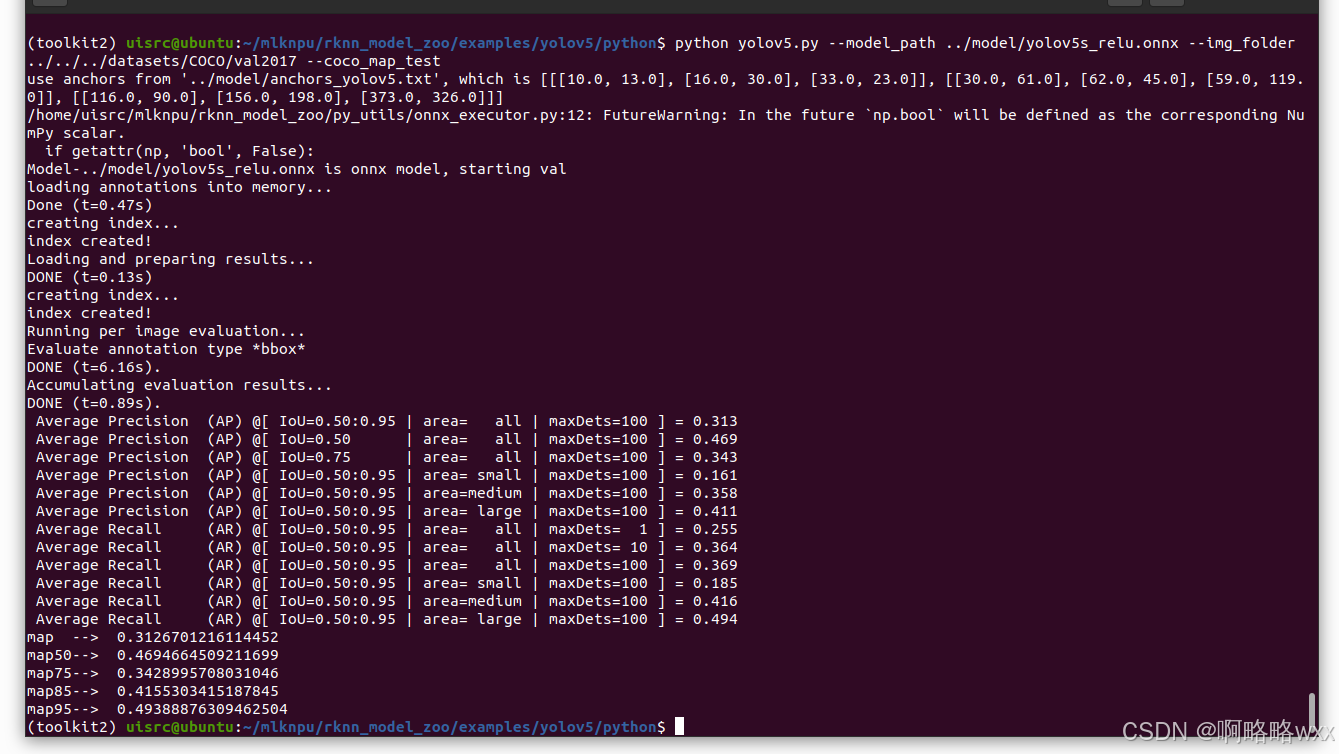
这段文本展示了使用 YOLOv5 模型在 COCO 数据集上进行目标检测任务后的评估结果。下面是各项指标的详细解释:
Average Precision (AP): 这是目标检测中的一个关键评价指标,它衡量模型预测的目标边界框与真实边界框之间的匹配程度。AP 值是针对不同 Intersection over Union (IoU) 阈值(通常从 0.5 到 0.95,以 0.05 为步长)计算出的平均精度。
-
- [IoU=0.50:0.95]:表示计算 AP 时使用的 IoU 阈值范围。
- [area= all]:表示考虑所有大小的对象。
- [maxDets=100]:表示在计算 AP 时,对于每个图像最多考虑 100 个检测框。
例如,Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.313 表示在所有大小对象上,IoU 阈值在 0.5 到 0.95 范围内,每个图像最多考虑 100 个检测框时,模型检测的平均精度为 0.313。
- 针对不同大小的对象(small, medium, large),还会分别计算 AP。这通常是按照对象的面积来定义的,例如 small 对象的面积小于 32x32 像素。
- Average Recall (AR): 这是另一个重要的评价指标,它衡量模型能够召回多少真实的目标边界框。与 AP 类似,AR 也是针对不同的 IoU 阈值和最大检测数计算的。
- map和 map@xx:这是模型性能的一种总结性指标,表示在不同 IoU 阈值下的 mean Average Precision (mAP)。这里的 `map` 是所有 IoU 阈值的平均值。
- `map`:通常表示 mAP@[IoU=0.50:0.95 | area= all | maxDets=100],即所有 IoU 阈值、所有对象大小和最多 100 个检测框的平均精度。
- `map50`, `map75`, `map85`, `map95`:这些指标分别表示在特定的 IoU 阈值(0.5, 0.75, 0.85, 0.95)下的 mAP。
具体到文本中的结果:
- 模型在所有大小对象上的 mAP 为 0.313。
- 在 IoU 阈值为 0.50 的情况下,mAP 为 0.469。
- 在 IoU 阈值为 0.75 的情况下,mAP 为 0.343。
- 对于小、中、大对象,分别计算出的 AP 值为 0.161、0.358 和 0.411。
- 对于不同的检测数量(1, 10, 100),分别计算出的 AR 值。
这些指标为评估和比较不同目标检测模型提供了标准化的度量。通常来说,AP 和 AR 值越高,模型的性能越好。
RKNN C demo 使用方法
实验一共有两种代码,一种是C语言还有一种是python语言 。python是解释性语言,而C语言不一样,需要提前编译成独立模块,所以在这里我们需要多一步——交叉编译。
第一步准备模型,运行download_model.sh脚本
./download_model.sh
注意:文件路径
第二步模型转换,转换成rknn模型,模型转换需要用到python,切换到toolkit2
我们切换终端路径
cd /home/uisrc/mlknpu/rknn_model_zoo/examples/yolov5/python/然后切换到toolkit2环境
conda activate toolkit2输入指令开始模型转换
python convert.py ../model/yolov5s_relu.onnx rk3588 i8 ../model/yolov5s_relu.rknn
C demo需要编译成一个独立的可执行文件,不同于python,python是解释性语言,可以直接运行。
我这里采用交叉编译C语言
在虚拟机进行交叉编译C语言需要进行一些环境部署
第一步安装gcc交叉编译器
交叉编译工具在米联客npu的工具包里
把该文件放到虚拟机上然后解压到相应路径下
sudo tar zxvf gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.gz -C /opt/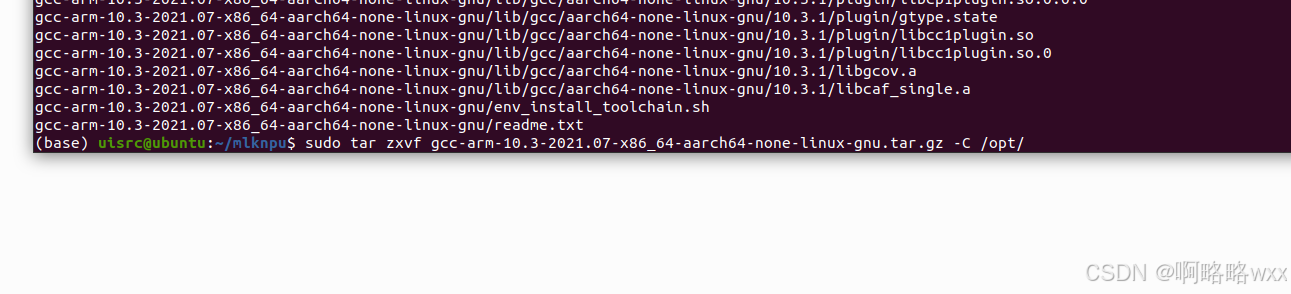
解压完成后

cd /opt/
ls
cd gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnupwd //获取编译工具路径

我们到虚拟机该路径下
/home/uisrc/mlknpu/rknn_model_zoo
看到一个build-linux.sh文件,我们修改一下里面的编译工具路径
在build-linux.sh文件里添加编译工具路径
我这里添加的是
GCC_COMPILER=/opt/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu
(实际路径以自己解压编译工具路径为准)
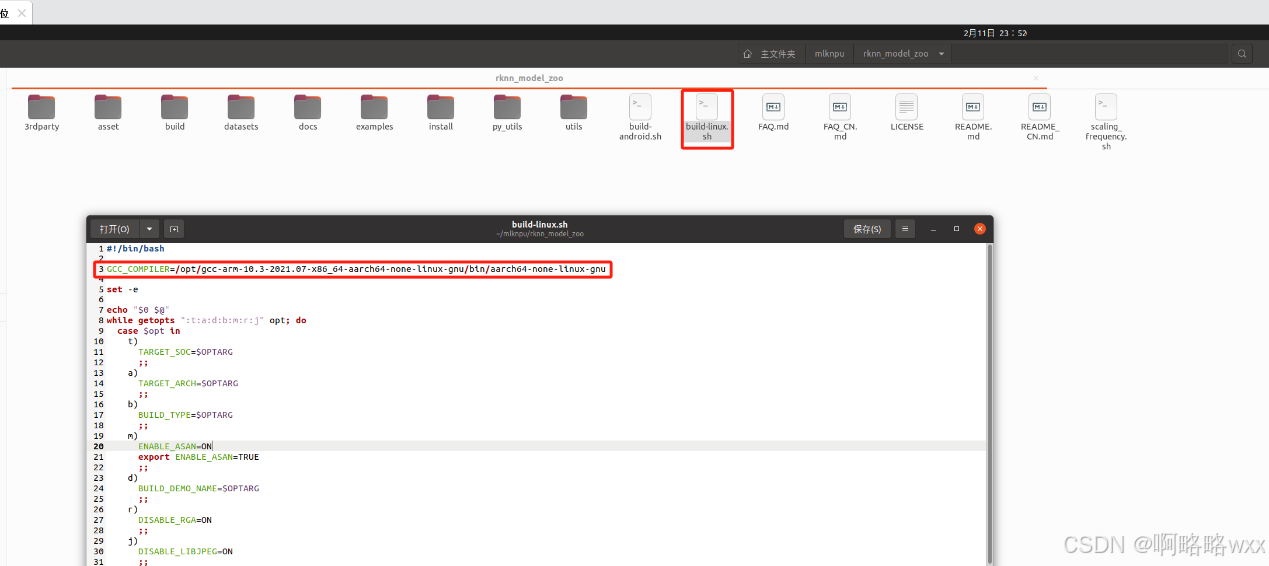
改完保存之后打开终端,开始编译C语言文件
记得给build-linux.sh加一个权限
chmod 777 build-linux.sh然后运行脚本
./build-linux.sh -t rk3588 -a aarch64 -d yolov5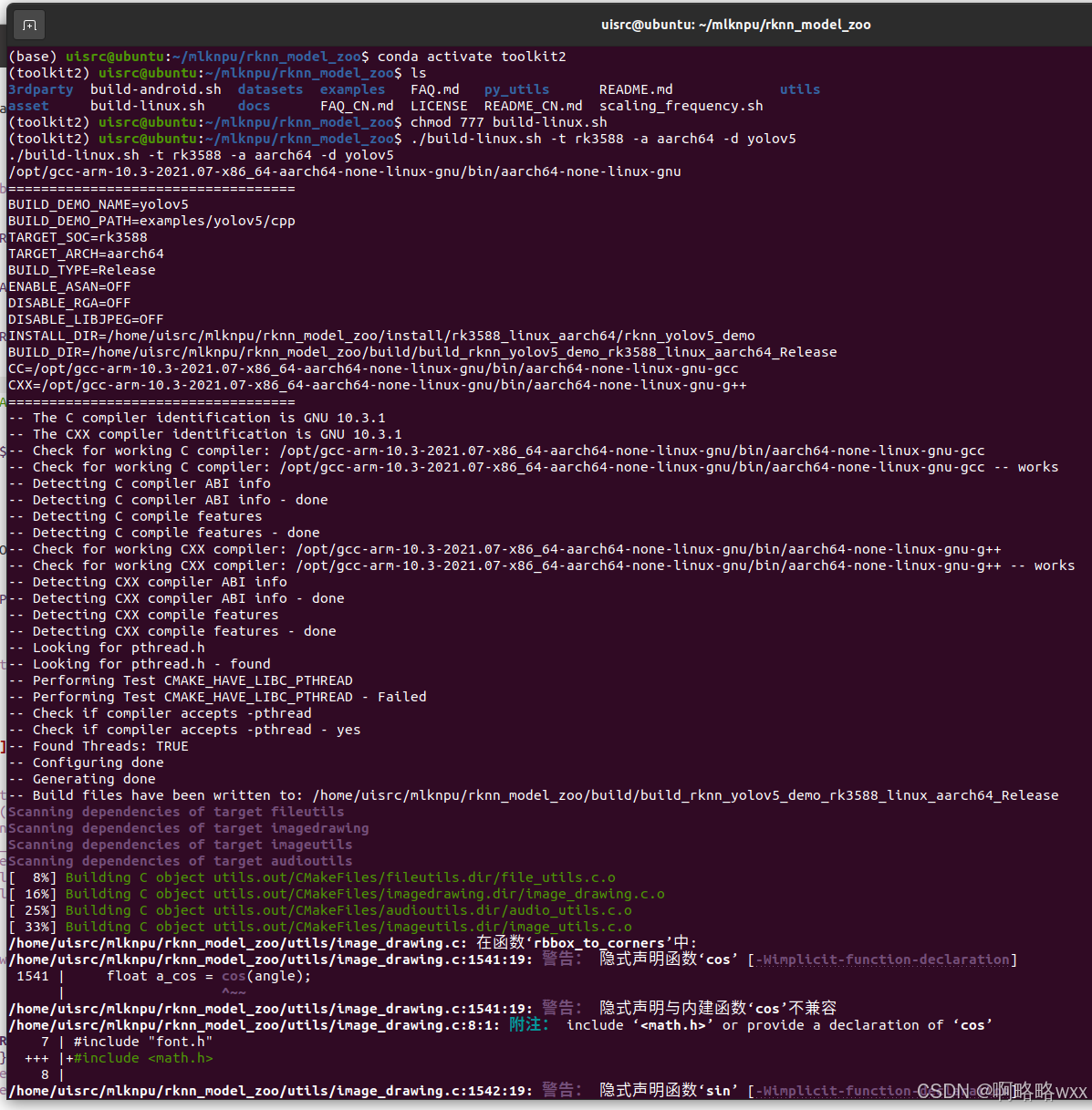
编译成功后,我们会发现多一个文件夹install,这就是编译好的可执行文件,以及测试图片等相关文件。
我们放在板卡运行之前,做一下板卡准备工作,首先Linux系统必须要有。
检查板卡安装RKNPU2环境
- 先确认rknpu2驱动版本
在板卡执行命令查看rknpu2驱动版本
dmesg | grep -i rknpu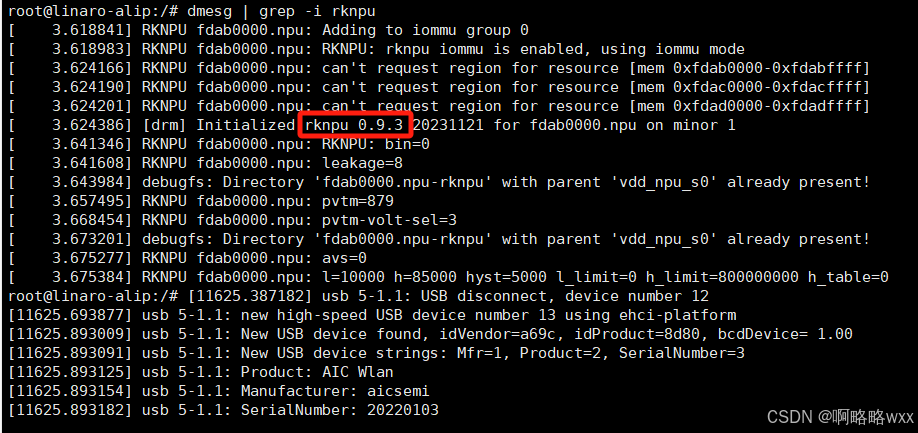
查看rknpu2驱动版本,版本建议>=0.9.2
检查RKNPU2环境是否安装
#启动rknn_server
restart_rknn.sh如果出现以下信息表示rknn_server服务成功,即已经安装RKNPU2环境

检查rknnserver和rknpu2runtime库版本是否一致
#查询rknn_server版本
strings /usr/bin/rknn_server | grep -i "rknn_server version"#查询librknnrt.so库版本
strings /usr/lib/librknnrt.so | grep -i "librknnrt version"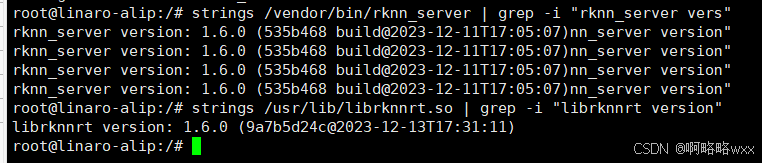
至此板卡准备工作已经完成。
开发板运行demo
在开发板能运行C demo
我们将虚拟机编译好的install文件夹传到开发板上
然后进入到该路径下

设置环境依赖包
export LD_LIBRARY_PATH=./lib
./rknn_yolov5_demo model/yolov5s_relu.rknn model/bus.jpg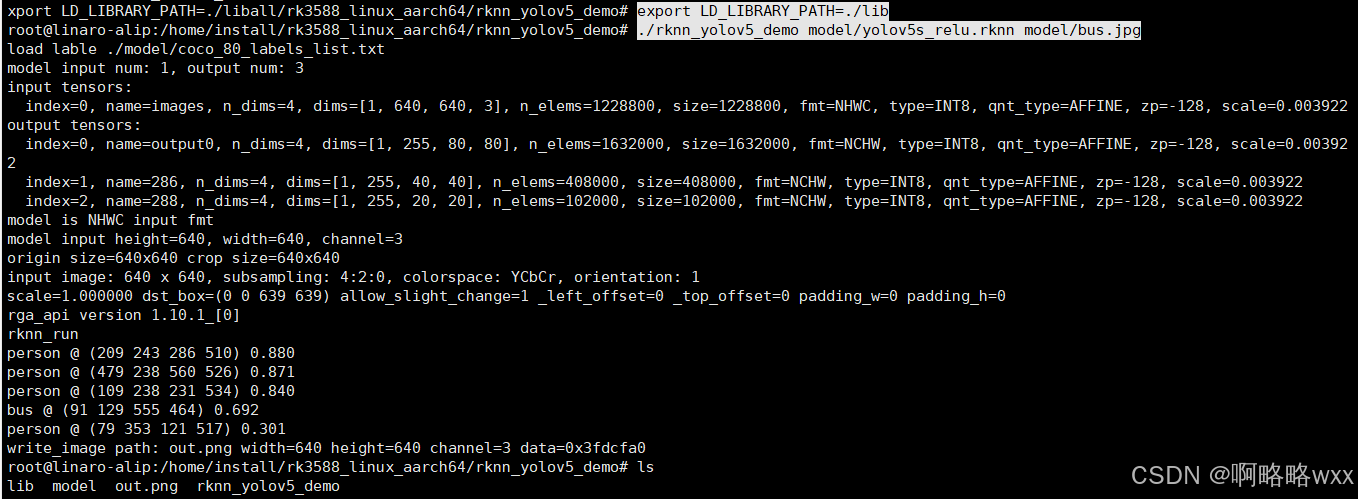
我们可以看到多出一个out.pang文件

这就是识别结果