Python 训练营打卡 Day 50
预训练模型 CBAM注意力
现在我们思考下,是否可以对于预训练模型增加模块来优化其效果,这里我们会遇到一个问题:
预训练模型的结构和权重是固定的,如果修改其中的模型结构,是否会大幅影响其性能。其次是训练的时候如何训练才可以更好的避免破坏原有的特征提取器的参数。
所以今天的内容,我们需要回答2个问题。
- resnet18中如何插入cbam模块?
- 采用什么样的预训练策略,能够更好的提高效率?
可以很明显的想到,如果是resnet18+cbam模块,那么大多数地方的代码都是可以复用的,模型定义部分需要重写。先继续之前的代码
所以很容易的想到之前第一次使用resnet的预训练策略:先冻结预训练层,然后训练其他层。之前的其它层是全连接层(分类头),现在其它层还包含了每一个残差块中的cbam注意力层
resnet结构解析
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 定义通道注意力
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):"""通道注意力机制初始化参数:in_channels: 输入特征图的通道数ratio: 降维比例,用于减少参数量,默认为16"""super().__init__()# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征self.max_pool = nn.AdaptiveMaxPool2d(1)# 共享全连接层,用于学习通道间的关系# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层nn.ReLU(), # 非线性激活函数nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层)# Sigmoid函数将输出映射到0-1之间,作为各通道的权重self.sigmoid = nn.Sigmoid()def forward(self, x):"""前向传播函数参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:调整后的特征图,通道权重已应用"""# 获取输入特征图的维度信息,这是一种元组的解包写法b, c, h, w = x.shape# 对平均池化结果进行处理:展平后通过全连接网络avg_out = self.fc(self.avg_pool(x).view(b, c))# 对最大池化结果进行处理:展平后通过全连接网络max_out = self.fc(self.max_pool(x).view(b, c))# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道return x * attention #这个运算是pytorch的广播机制## 空间注意力模块
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 通道维度池化avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)attention = self.conv(pool_out) # 卷积提取空间特征return x * self.sigmoid(attention) # 特征与空间权重相乘## CBAM模块
class CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=7):super().__init__()self.channel_attn = ChannelAttention(in_channels, ratio)self.spatial_attn = SpatialAttention(kernel_size)def forward(self, x):x = self.channel_attn(x)x = self.spatial_attn(x)return ximport torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理(与原代码一致)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)通过与训练resnet18来查看模型结构
import torch
import torchvision.models as models
from torchinfo import summary #之前的内容说了,推荐用他来可视化模型结构,信息最全# 加载 ResNet18(预训练)
model = models.resnet18(pretrained=True)
model.eval()# 输出模型结构和参数概要
summary(model, input_size=(1, 3, 224, 224))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [1, 1000] --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
==========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================经典的 ResNet-18 模型可以将其看作一个处理流水线,图像数据从一端进去,分类结果从另一端出来。整个过程可以分为三个主要部分:
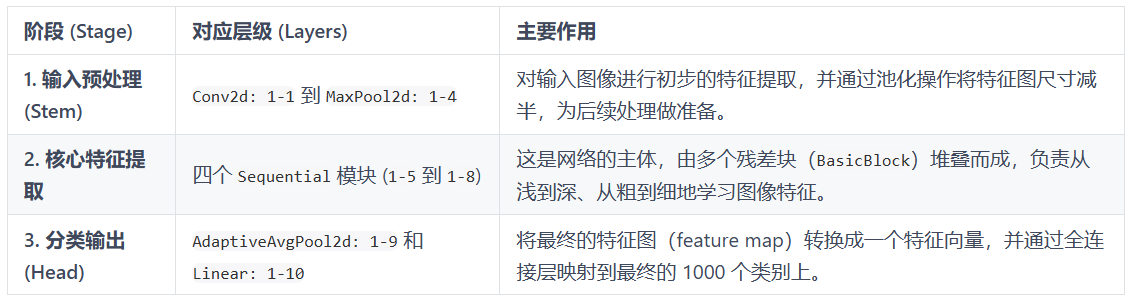
CBAM放置位置
import torch
import torch.nn as nn
from torchvision import models# 自定义ResNet18模型,插入CBAM模块
class ResNet18_CBAM(nn.Module):def __init__(self, num_classes=10, pretrained=True, cbam_ratio=16, cbam_kernel=7):super().__init__()# 加载预训练ResNet18self.backbone = models.resnet18(pretrained=pretrained) # 修改首层卷积以适应32x32输入(CIFAR10)self.backbone.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)self.backbone.maxpool = nn.Identity() # 移除原始MaxPool层(因输入尺寸小)# 在每个残差块组后添加CBAM模块self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)# 修改分类头self.backbone.fc = nn.Linear(in_features=512, out_features=num_classes)def forward(self, x):# 主干特征提取x = self.backbone.conv1(x)x = self.backbone.bn1(x)x = self.backbone.relu(x) # [B, 64, 32, 32]# 第一层残差块 + CBAMx = self.backbone.layer1(x) # [B, 64, 32, 32]x = self.cbam_layer1(x)# 第二层残差块 + CBAMx = self.backbone.layer2(x) # [B, 128, 16, 16]x = self.cbam_layer2(x)# 第三层残差块 + CBAMx = self.backbone.layer3(x) # [B, 256, 8, 8]x = self.cbam_layer3(x)# 第四层残差块 + CBAMx = self.backbone.layer4(x) # [B, 512, 4, 4]x = self.cbam_layer4(x)# 全局平均池化 + 分类x = self.backbone.avgpool(x) # [B, 512, 1, 1]x = torch.flatten(x, 1) # [B, 512]x = self.backbone.fc(x) # [B, 10]return x# 初始化模型并移至设备
model = ResNet18_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)import time# ======================================================================
# 4. 结合了分阶段策略和详细打印的训练函数
# ======================================================================
def set_trainable_layers(model, trainable_parts):print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")for name, param in model.named_parameters():param.requires_grad = Falsefor part in trainable_parts:if part in name:param.requires_grad = Truebreakdef train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs):optimizer = None# 初始化历史记录列表,与你的要求一致all_iter_losses, iter_indices = [], []train_acc_history, test_acc_history = [], []train_loss_history, test_loss_history = [], []for epoch in range(1, epochs + 1):epoch_start_time = time.time()# --- 动态调整学习率和冻结层 ---if epoch == 1:print("\n" + "="*50 + "\n🚀 **阶段 1:训练注意力模块和分类头**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)elif epoch == 6:print("\n" + "="*50 + "\n✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc", "backbone.layer3", "backbone.layer4"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)elif epoch == 21:print("\n" + "="*50 + "\n🛰️ **阶段 3:解冻所有层,进行全局微调**\n" + "="*50)for param in model.parameters(): param.requires_grad = Trueoptimizer = optim.Adam(model.parameters(), lr=1e-5)# --- 训练循环 ---model.train()running_loss, correct, total = 0.0, 0, 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录每个iteration的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 按你的要求,每100个batch打印一次if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_loss_history.append(epoch_train_loss)train_acc_history.append(epoch_train_acc)# --- 测试循环 ---model.eval()test_loss, correct_test, total_test = 0, 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_loss_history.append(epoch_test_loss)test_acc_history.append(epoch_test_acc)# 打印每个epoch的最终结果print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 训练结束后调用绘图函数print("\n训练完成! 开始绘制结果图表...")plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)# 返回最终的测试准确率return epoch_test_acc# ======================================================================
# 5. 绘图函数定义
# ======================================================================
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend(); plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend(); plt.grid(True)plt.tight_layout()plt.show()# ======================================================================
# 6. 执行训练
# ======================================================================
model = ResNet18_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
epochs = 50print("开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练...")
final_accuracy = train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# torch.save(model.state_dict(), 'resnet18_cbam_finetuned.pth')
# print("模型已保存为: resnet18_cbam_finetuned.pth")