NLP学习路线图(四十):文本与图像结合
清晨,你随手拍下窗外的朝霞分享到朋友圈,指尖轻敲:“破晓时分的温柔,值得早起。” 此刻,文本与图像在你手中完成了一次自然的协同表达——而这正是多模态NLP(自然语言处理)探索的核心:如何让机器像人类一样,理解交织在文字与画面中的丰富语义。当GPT-4能解读医学影像报告,电商平台精准推荐图文匹配的商品,盲人辅助工具“看见”并描述世界,我们已然站在人机交互新纪元的门口。
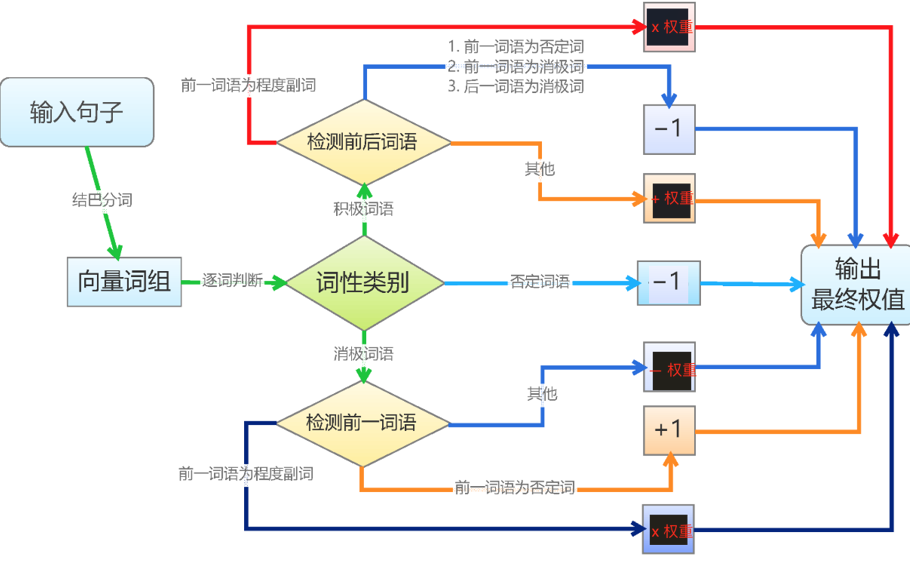
一、跨越感官鸿沟:多模态学习的必然性
单一模态的局限在真实世界面前日益凸显:
-
信息割裂陷阱:纯文本模型将“一只橘猫趴在键盘上”理解为抽象符号,无法感知画面中的萌态与混乱;纯CV模型看到日落照片,却读不懂配文“夕阳无限好”的惆怅。
-
人类认知本质:我们天生融合视觉、听觉、语言等多通道输入。婴儿通过指向苹果并听到“apple”建立关联,而非孤立学习。
-
场景需求爆发:社交媒体内