P9-QA 数据集生成工具
QA 数据集生成工具
本工具用于从文本文件(.txt、.pdf、.docx)生成问答(QA)数据集,基于 Qwen3 语言模型的检索增强生成(RAG)流程。工具支持文档处理、文本分割为语义完整的句子、生成自然且包含明确主语的问题、通过 RAG 生成准确回答,并提供 Gradio 界面用于文件上传、结果展示和数据集下载。
功能
-
文件处理:
- 支持
.txt、.pdf和.docx格式。 - 提取文本内容并分割为语义完整的句子。
- 支持
-
问题生成:
- 使用 Qwen3 模型为每个句子生成自然且相关的问题。
- 润色问题,确保清晰且包含明确主语(例如,将“为什么低着头往前走?”改为“为什么青青低着头往前走?”)。
-
RAG 流程:
- 使用 Chroma 和 HuggingFace 嵌入模型构建向量数据库,实现高效文档检索。
- 结合检索到的文档上下文和 Qwen3 模型生成准确回答。
-
Gradio 界面:
- 提供基于 Web 的文件上传功能。
- 以表格形式展示生成的 QA 对。
- 使用 Matplotlib 绘制柱状图,显示句子数量与 QA 对数量统计。
- 支持下载生成的
.qa.json文件。
-
错误处理:
- 对文件读取、API 调用和 RAG 流程提供健壮的错误处理。
- 提供详细日志记录,便于调试。
环境配置
前提条件
- Python 3.8 或更高版本
- 使用 Conda 或 pip 进行包管理
- (可选)支持 CUDA 的 GPU 以加速嵌入计算
安装步骤
-
创建虚拟环境(推荐):
conda create -n qa_generator python=3.12 conda activate qa_generator -
安装依赖:
pip install openai pdfplumber python-docx langchain langchain-community sentence-transformers chromadb gradio matplotlib pandas python-dotenv -
设置 API 密钥:
- 从 DashScope 平台(Qwen3 提供商)获取 API 密钥。
- 在项目根目录创建
.env文件,添加:API_KEY=你的API密钥 BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1 - 确保代码中通过
python-dotenv加载环境变量(见下方代码)。
-
主要代码:
import os
import json
import re
import time
from pathlib import Path
from typing import List, Optional
import pdfplumber
from docx import Document as DocxDocument
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
import torch
import gradio as gr
import logging
import pandas as pd
import matplotlib.pyplot as plt
from hashlib import md5# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# Qwen3 API 配置(假设从配置文件导入)
from config import API_KEY, BASE_URL
from openai import OpenAI# 初始化 OpenAI 客户端
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)# 全局计数器和缓存
MODEL_CALL_COUNT = 0
QUESTION_CACHE = {}
ANSWER_CACHE = {}# ---------- 文件读取函数 ----------def read_txt(file_path: Path) -> Optional[str]:"""读取txt文件,支持多种编码"""encodings = ['utf-8', 'gbk', 'gb18030', 'gb2312', 'big5', 'utf-16']for enc in encodings:try:with open(file_path, 'r', encoding=enc) as f:return f.read()except Exception:continuereturn Nonedef read_pdf(file_path: Path) -> str:"""读取PDF文件内容"""text = ""with pdfplumber.open(file_path) as pdf:for page in pdf.pages:page_text = page.extract_text()if page_text:text += page_text + "\n"return textdef read_docx(file_path: Path) -> str:"""读取Word文件内容"""doc = DocxDocument(file_path)return "\n".join([para.text for para in doc.paragraphs if para.text.strip()])def read_file(file_path: Path) -> Optional[str]:"""通用文件读取器"""suffix = file_path.suffix.lower()if suffix == ".txt":return read_txt(file_path)elif suffix == ".pdf":return read_pdf(file_path)elif suffix == ".docx":return read_docx(file_path)else:logger.error(f"不支持的文件类型: {suffix}")return None# ---------- 句子分割函数 ----------def split_sentences(text: str) -> List[str]:"""使用正则表达式分割句子,并进行后处理"""pattern = re.compile(r"([^。!?!?…]*[。!?!?…]+)")sentences = [match.group(0).strip() for match in pattern.finditer(text) if match.group(0).strip()]return [s for s in sentences if len(s.strip()) >= 5 and re.search(r'[^\s。!?!?…]', s)]# ---------- 问题生成和润色函数 ----------def generate_questions_batch(sentences: List[str]) -> List[Optional[str]]:"""批量生成问题"""global MODEL_CALL_COUNTprompt = ("你是一个问答数据集生成助手。给定一组中文陈述句,生成自然、简洁且与句子内容相关的问题,""适合用于问答数据集。每个问题应以疑问词开头(如‘什么’‘谁’‘为什么’‘如何’等)。\n\n""输入句子:\n" +"\n".join(f"{i+1}. {sentence}" for i, sentence in enumerate(sentences)) +"\n\n输出格式:\n""[\n {\"index\": 1, \"question\": \"生成的问题1\"},\n {\"index\": 2, \"question\": \"生成的问题2\"},\n ...\n]\n")try:completion = client.chat.completions.create(model="qwen-plus",messages=[{"role": "system", "content": "你是一个问答数据集生成助手。"},{"role": "user", "content": prompt}],temperature=0.7,max_tokens=1000)MODEL_CALL_COUNT += 1result = completion.choices[0].message.content.strip()if result.startswith("```json"):result = result[7:].strip()if result.endswith("```"):result = result[:-3].strip()result = result.replace('\\"', '"')questions = json.loads(result)output = [None] * len(sentences)for q in questions:index = q["index"] - 1if 0 <= index < len(sentences):sentence_hash = md5(sentences[index].encode('utf-8')).hexdigest()QUESTION_CACHE[sentence_hash] = q["question"]output[index] = q["question"]return outputexcept Exception as e:logger.error(f"批量生成问题失败: {e}")return [None] * len(sentences)def refine_questions_batch(questions: List[str], sentences: List[str]) -> List[Optional[str]]:"""批量润色问题"""global MODEL_CALL_COUNTprompt = ("你是一个问题润色助手。给定一组问题和对应的原始句子,润色每个问题,使其更自然、清晰,并适合用于问答数据集。""确保问题包含明确的主语,避免使用模糊代词(如‘他’‘她’‘它’)或无主语表述。""如果问题缺少主语,从原始句子中提取合适的主语并融入问题。\n\n""输入:\n" +"\n".join(f"{i+1}. 原始句子:{sentences[i]}\n 原始问题:{questions[i]}" for i in range(len(questions))) +"\n\n输出格式:\n""[\n {\"index\": 1, \"question\": \"润色后的问题1\"},\n {\"index\": 2, \"question\": \"润色后的问题2\"},\n ...\n]\n")try:completion = client.chat.completions.create(model="qwen-plus",messages=[{"role": "system", "content": "你是一个问题润色助手,擅长补充主语并优化问题表述。"},{"role": "user", "content": prompt}],temperature=0.5,max_tokens=1000)MODEL_CALL_COUNT += 1result = completion.choices[0].message.content.strip()if result.startswith("```json"):result = result[7:].strip()if result.endswith("```"):result = result[:-3].strip()result = result.replace('\\"', '"')refined_questions = json.loads(result)output = [None] * len(questions)for q in refined_questions:index = q["index"] - 1if 0 <= index < len(questions):output[index] = q["question"]return outputexcept Exception as e:logger.error(f"批量问题润色失败: {e}")return [None] * len(questions)# ---------- RAG 系统构建 ----------def build_rag_chain(documents: List[Document]) -> any:"""构建RAG链,用于回答问题"""try:text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)splits = text_splitter.split_documents(documents)embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5",model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"})vectorstore = Chroma.from_documents(documents=splits,embedding=embedding_model)retriever = vectorstore.as_retriever(search_kwargs={"k": 4})prompt_template = ChatPromptTemplate.from_template("""你是一个有用的助手。根据以下文档上下文回答问题。**文档上下文**:{context}**问题**:{question}提供简洁且准确的回答。""")def qwen_generate(inputs: dict) -> str:global MODEL_CALL_COUNTquestion = inputs["question"]question_hash = md5(question.encode('utf-8')).hexdigest()if question_hash in ANSWER_CACHE:logger.info(f"答案缓存命中: {question}")return ANSWER_CACHE[question_hash]context = inputs["context"]messages = [{"role": "system", "content": "你是一个有用的助手。"},{"role": "user", "content": prompt_template.format(context=context, question=question)}]completion = client.chat.completions.create(model="qwen-plus",messages=messages,temperature=0.7,max_tokens=200)MODEL_CALL_COUNT += 1answer = completion.choices[0].message.contentANSWER_CACHE[question_hash] = answerreturn answerdef format_docs(docs):return "\n\n".join([doc.page_content.strip() for doc in docs])rag_chain = ({"context": retriever | format_docs,"question": RunnablePassthrough(),}| RunnablePassthrough.assign(answer=qwen_generate)| (lambda x: x["answer"]))return rag_chainexcept Exception as e:logger.error(f"构建 RAG 链失败: {str(e)}")raise# ---------- QA 数据集生成函数 ----------def generate_qa_dataset(file, refine: bool = True) -> tuple[str, str, pd.DataFrame, plt.Figure, int]:"""处理上传的文件并生成QA数据集"""global MODEL_CALL_COUNTMODEL_CALL_COUNT = 0 # 重置计数器try:if file is None:return "请上传文件!", "", pd.DataFrame(), None, 0# 获取文件路径并验证file_path = Path(file.name)logger.info(f"处理文件: {file_path}")# 验证是否为文件且文件类型支持if not file_path.is_file():return f"错误:'{file_path}' 是一个目录,请上传单个文件!", "", pd.DataFrame(), None, 0if file_path.suffix.lower() not in [".pdf", ".docx", ".txt"]:return f"错误:不支持的文件类型 '{file_path.suffix}',请上传 .pdf、.docx 或 .txt 文件!", "", pd.DataFrame(), None, 0# 读取文件内容text = read_file(file_path)if not text:return "无法读取文件内容!", "", pd.DataFrame(), None, 0# 分割句子sentences = split_sentences(text)logger.info(f"共分出 {len(sentences)} 句")# 构建 RAG 链documents = [Document(page_content=text, metadata={"source": str(file_path)})]rag_chain = build_rag_chain(documents)# 批量生成问题questions = generate_questions_batch(sentences)# 收集有效问题和对应句子valid_pairs = [(q, s) for q, s in zip(questions, sentences) if q]if not valid_pairs:return "未生成有效问题!", "", pd.DataFrame(), None, MODEL_CALL_COUNTquestions_to_refine, sentences_for_refine = zip(*valid_pairs)# 批量润色问题(如果启用)if refine:refined_questions = refine_questions_batch(questions_to_refine, sentences_for_refine)else:refined_questions = list(questions_to_refine)qa_pairs = []for q, rq, s in zip(questions_to_refine, refined_questions, sentences_for_refine):if rq:answer = rag_chain.invoke(rq)qa_pairs.append({"question": rq,"answer": answer})logger.info(f"生成 QA 对: Q: {rq} A: {answer}")else:logger.warning(f"问题润色失败: {q}")# 保存数据集output_path = file_path.with_suffix('.qa.json')with open(output_path, 'w', encoding='utf-8') as f:json.dump(qa_pairs, f, ensure_ascii=False, indent=2)logger.info(f"问答对已保存至 {output_path}")# 创建表格数据qa_df = pd.DataFrame(qa_pairs, columns=["question", "answer"])# 创建 Matplotlib 柱状图fig, ax = plt.subplots(figsize=(6, 4))categories = ["Sentences", "QA Pairs", "Model Calls"]counts = [len(sentences), len(qa_pairs), MODEL_CALL_COUNT]bars = ax.bar(categories, counts, color=["#36A2EB", "#FF6384", "#4BC0C0"])ax.set_ylabel("Count")ax.set_title("Processing Statistics")for bar in bars:height = bar.get_height()ax.text(bar.get_x() + bar.get_width() / 2, height + 0.1, int(height), ha='center')plt.tight_layout()status = f"文件处理成功!共生成 {len(qa_pairs)} 个QA对,保存至 {output_path},大模型调用次数:{MODEL_CALL_COUNT}"return status, str(output_path), qa_df, fig, MODEL_CALL_COUNTexcept Exception as e:logger.error(f"处理失败: {str(e)}")return f"处理失败: {str(e)}", "", pd.DataFrame(), None, 0# ---------- Gradio 界面 ----------def main():"""启动 Gradio 界面"""with gr.Blocks(title="QA Dataset Generator") as demo:gr.Markdown("# QA 数据集生成工具")gr.Markdown("上传一个 PDF、Word 或文本文件,系统将自动生成问答数据集,并提供可视化结果和模型调用统计。")# 文件上传和选项file_input = gr.File(label="上传文件", file_types=[".pdf", ".docx", ".txt"])refine_option = gr.Checkbox(label="润色问题(增加模型调用次数)", value=True)status_output = gr.Textbox(label="处理状态")download_output = gr.File(label="下载 QA 数据集")table_output = gr.Dataframe(label="生成的 QA 对", headers=["question", "answer"])chart_output = gr.Plot(label="处理统计")model_call_output = gr.Textbox(label="大模型调用次数")# 处理按钮process_button = gr.Button("生成 QA 数据集")process_button.click(fn=generate_qa_dataset,inputs=[file_input, refine_option],outputs=[status_output, download_output, table_output, chart_output, model_call_output])demo.launch()if __name__ == "__main__":main()
运行步骤
-
准备输入文件:
- 将
.txt、.pdf或.docx文件放置在脚本可访问的目录。 - 示例:包含青青、玉珍等角色故事的
Chapter_004.txt文件。
- 将
-
运行脚本:
python qa_dataset_generator.py- 启动 Gradio 界面,默认地址为
http://127.0.0.1:7860。
- 启动 Gradio 界面,默认地址为
-
使用 Gradio 界面:
- 上传文件:点击“上传文件”按钮,选择
.txt、.pdf或.docx文件。 - 生成 QA 数据集:点击“生成 QA 数据集”按钮处理文件。
- 查看结果:
- 处理状态:显示生成的 QA 对数量和输出文件路径。
- QA 对表格:展示生成的问题和回答,问题包含明确主语。
- 统计图表:显示句子数量和 QA 对数量的柱状图。
- 下载:下载生成的
.qa.json文件。
- 上传文件:点击“上传文件”按钮,选择
-
输出:
- QA 数据集保存为
<输入文件名>.qa.json,位于输入文件目录或 Gradio 临时目录。 - 示例输出(
Chapter_004.txt):[{"question": "为什么林老爷让小棠牵着青青的手出去?","answer": "林老爷让小棠牵着青青的手出去,是为了在皇帝生气的情况下,小心护着青青离开皇宫..."},... ]
- QA 数据集保存为
示例工作流程
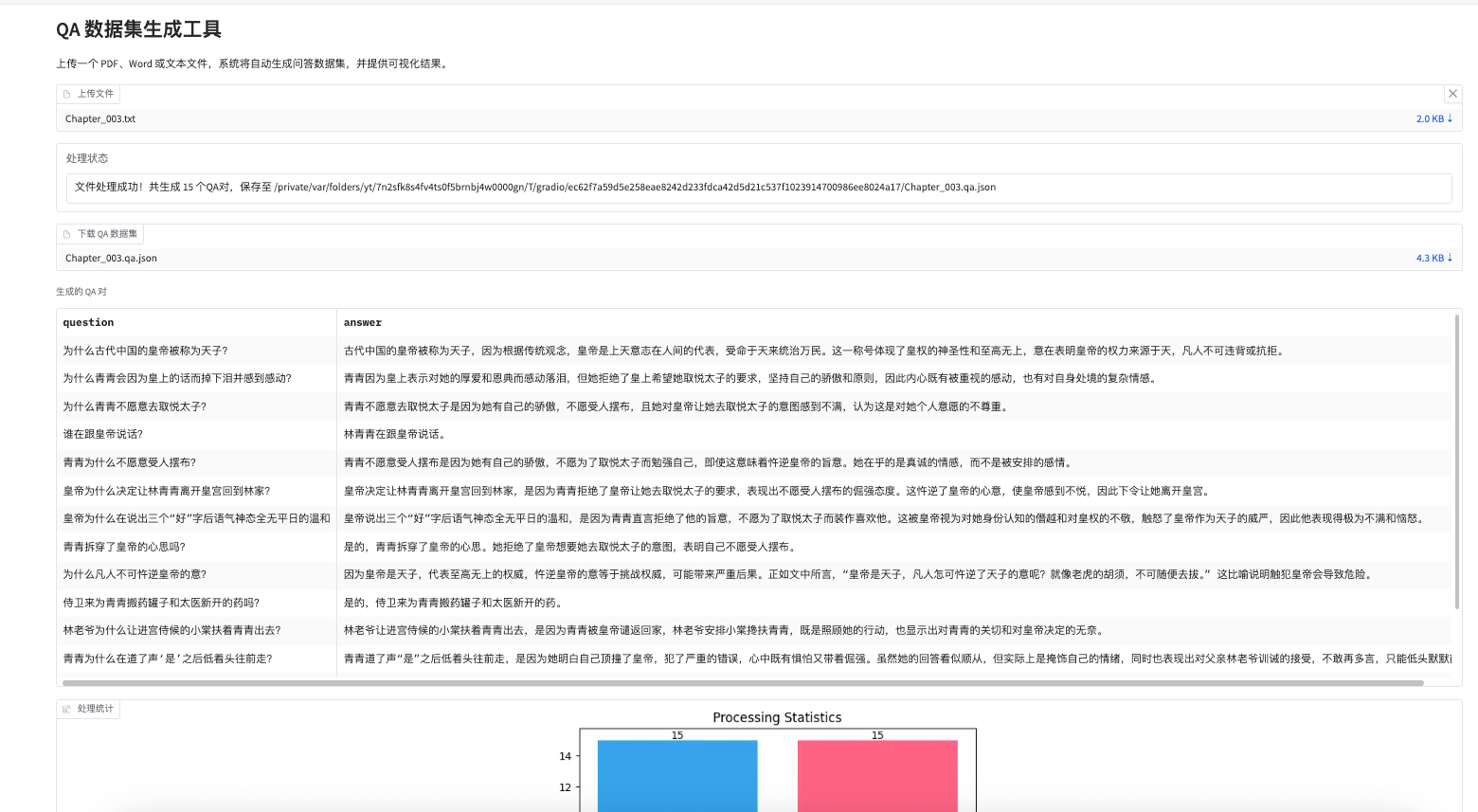
- 上传:上传包含青青、玉珍等角色故事的
Chapter_004.txt。 - 处理:工具将文本分割为句子,生成问题,补充主语,使用 RAG 生成回答。
- 输出:
- 状态:
文件处理成功!共生成 18 个 QA 对,保存至 Chapter_004.qa.json - 表格:展示类似“为什么青青低着头往前走?”的 QA 对。
- 图表:显示句子数量(例如 20)和 QA 对数量(例如 18)的柱状图。
- 下载:提供
Chapter_004.qa.json文件。
- 状态:
注意事项
- API 密钥安全:切勿硬编码 API 密钥,建议使用
.env文件存储。 - 性能:大型文件可能增加处理时间和 API 成本,建议分割大文件。
- Gradio 界面:确保 Gradio 服务器运行以访问 Web 界面。使用
demo.launch(share=True)可公开分享(需 Gradio 账户)。 - 依赖问题:如遇到
chromadb或sentence-transformers问题,确保 Python 环境干净且版本兼容。
故障排除
- API 错误:检查
.env文件中的 API 密钥和网络连接,查看日志中的 HTTP 状态码。 - 表格显示问题:确保
pandas和gradio为最新版本(pip install --upgrade pandas gradio)。 - 图表渲染问题:确认
matplotlib正确安装(pip install matplotlib)。 - 文件读取错误:确保输入文件未损坏且为支持的格式(
.txt、.pdf、.docx)。 - 目录错误:若提示
IsADirectoryError,确保上传的是文件而非文件夹。