昇腾CANN集合通信技术解读——细粒度分级流水算法
随着AI技术的演进,模型的计算复杂度和参数量呈现几何级数增长,这使得传统单机单卡部署在算力供给与显存容量方面显得力不从心,从而直接推动了分布式训练/推理技术的快速发展。今年年初爆火的DeepSeek在训练及推理Prefill阶段采用了分级流水AlltoAll算法,具体实现为:首先在Server间执行Token传输,当Token到达目标Server后,再在目标Server内执行Bcast操作,Server内和Server间的操作以Token为粒度进行流水掩盖。
HCCL支持细粒度的分级流水算法,基于Atlas A2 训练系列产品,可大幅提升DeepSeek集群训练中Allgather、ReduceScatter、AlltoAll等集合通信算子的执行效率。
1、简单分级算法存在的问题
为降低网络流量冲突,AI计算集群中常常采用Server内Server间分级网络架构,即Server内通过直连电缆互联,Server间同号卡通过交换机互联。
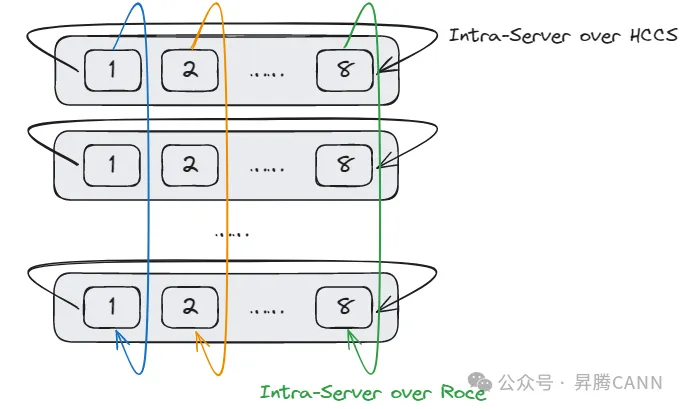
然而,在Server内Server间分级网络对应的全局通信域中执行集合通信算子,将面临以下两个挑战:
1)Server内链路和Server间链路带宽不同,一般情况下Server内带宽大于Server间带宽,如果使用全局Ring或RHD(Recursive Halving Doubling)算法会存在慢链路的问题。
2)不同Server的不同号卡之间无直连链路,算法设计时,需要考虑连通性问题。
为了解决上述问题,在Server内Server间分级网络中,通常使用分级算法,将全局通信操作分解为多层次的局部操作,利用分阶段、分层递进的方式优化通信效率。例如Allgather操作,Server间先执行一次同号卡间的Allgather(下图红色箭头),再在Server内执行一次Allgather(下图蓝色箭头)。
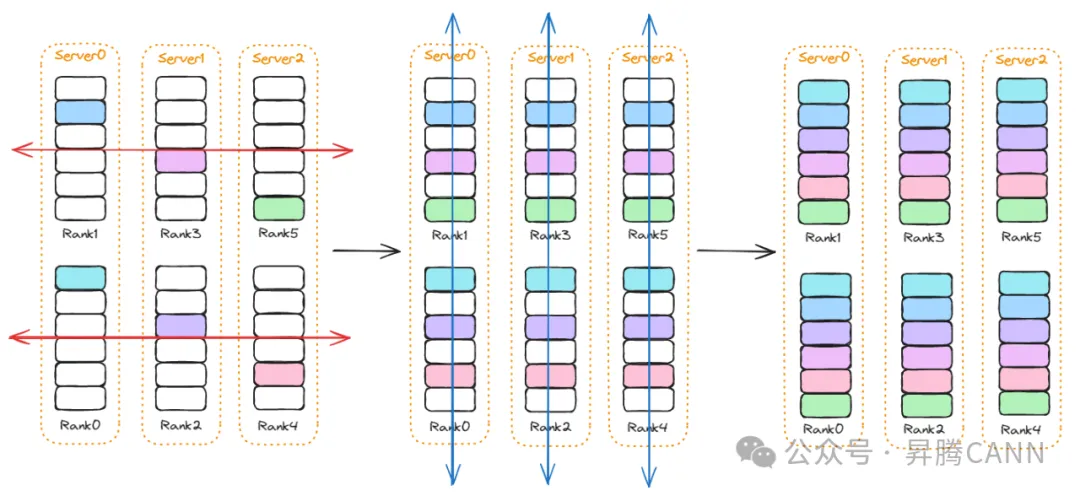
该分级算法仍然存在一些问题:
1)带宽浪费:上图中Server间数据传输时,Server内的链路处于空闲状态,无法实现带宽利用率的最大化。
2)存在离散数据:以Rank0为例,Server间完成数据传输后,持有Rank0、Rank2、Rank4的数据,这三块数据在Server内数据传输过程中需要发送到Rank1上,但是这三块数据在Rank1上并不是连续分布的,如果将这三块数据分别发送到Rank1上,会引入每次发送的头开销;如果将这三块数据合并发送,又需要引入数据重排的开销。
2、细粒度分级流水算法技术解读
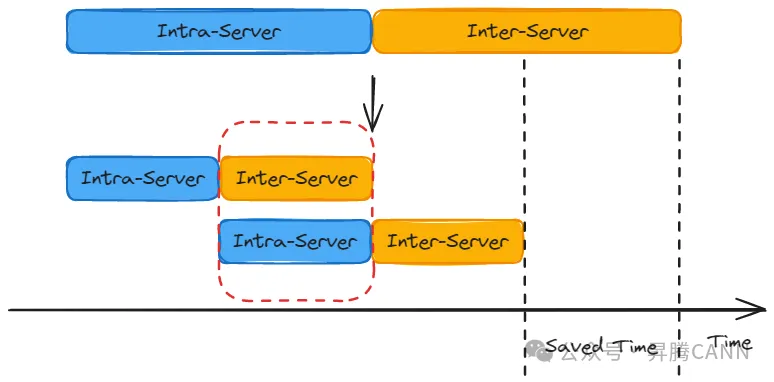
带宽浪费的问题,通常采用流水的方式解决。如下图所示,通过切分数据块,使得完成一部分Server内的数据传输后,就可以开始Server间的数据传输,同时启动第二部分的Server内数据传输。这样,Server内和Server间的数据传输可以并行进行(如红框所示),从而提高总的带宽利用率。
虽然这种方法可以解决带宽利用率不足的问题,但是通过切分数据块的方式进行流水掩盖,会导致单次数据传输的数据量变小,头开销占比过大,通信效率降低,而且无法解决离散数据的问题。
因此,采用细粒度分级流水算法,一方面挖掘通信算法本身的数据依赖,另一方面结合流水并行的方式,解决带宽利用率不足与离散数据的问题。以Allgather为例,Server间的通信选择Ring算法,Server内的通信选择Full Mesh算法。让我们先回顾一下Ring算法的步骤:假设共有n个Server,那么Ring算法会执行n-1步操作,在第i步时,本Rank将获得前i个Rank上的数据。
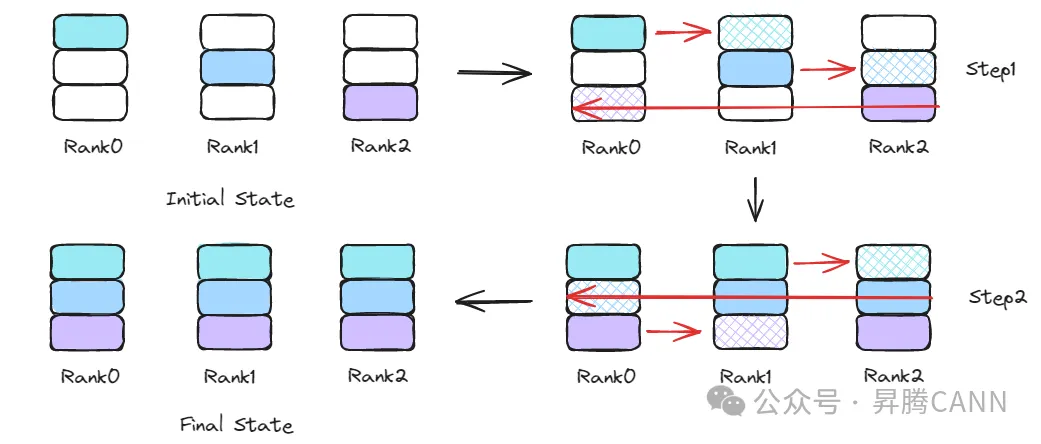
在简单分级算法中,执行完全部n-1步操作后才会进行Server内的数据传输。然而,观察Rank上每个步骤的数据状态可以发现:每完成一步数据传输,都会有新的数据块被传输到Rank上,该数据块在下一步数据传输时,可以同时完成Server间的数据传输和Server内的数据传输。如下中图所示,绿色数据块从Rank5被发送到Rank1上(仅陈述部分Rank的行为,其它Rank对称处理),在接下来的步骤中,Rank1继续向Rank3发送绿色数据块(Ring算法标准步骤),同时Rank1也可以向同Server中的Rank0发送绿色数据块。

继续执行Ring算法,每一步在进行Server间数据传输的同时,还会向Server内其它Rank传输上一步接收到的数据块,Ring算法的最后一个步骤结束后,仅需要在Server内再进行一次数据块的传输即可完成全部算法步骤(Rank初始数据块的Server内传输操作,可以隐藏在Ring算法的第一步中进行),Rank0上的全部传输任务编排如下图所示,LocalCpy操作仅在输入输出内存不同场景中执行,用于将数据块从输入内存移动到输出内存,在输入输出内存相同场景中,则无需执行该操作。
该算法利用Ring算法的数据依赖关系,实现了Server内/Server间的并发执行,以提高带宽利用率。同时,由于该算法的切分方式是对传输数据块进行重排,每次数据传输所操作的数据块仅包含一个Rank的初始数据,因此在跨卡传输时,数据可以直接传输到最终位置,从而避免了离散数据的问题。
3、性能收益评估
让我们对该算法进行简单的收益分析,假设n个Server,每个Server中有m张卡,Server内采用Full Mesh通信算法,每条链路的带宽为bw_a,Server间Clos连接,带宽为bw_e;假设输入数据量s足够大,仅考虑带宽时延,并且bw_a > bw_e。
采用简单分级算法,算子耗时为:
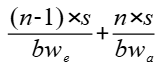
采用细粒度分级流水算法,算子耗时为:
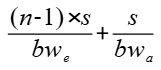
可以看到,当bw_e和bw_a接近时,n越大,算法性能提升越大,最大提升接近1倍。
4、更多学习资源
HCCL集合通信库,通过高性能集合通信算法、计算通信统一硬化调度、计算通信高性能并发等创新技术,可充分利用硬件资源,显著提升大模型通信效率。欢迎昇腾社区HCCL学习专区,获取海量学习资源。

昇腾社区HCCL信息专区