深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录
- 前言
- 一、感知机 (Perceptron)
- 1.1 基础介绍
- 1.1.1 感知机是什么?
- 1.1.2 感知机的工作原理
- 1.2 感知机的简单应用:基本逻辑门
- 1.2.1 逻辑与 (Logic AND)
- 1.2.2 逻辑或 (Logic OR)
- 1.2.3 逻辑与非 (Logic NAND)
- 1.3 感知机的实现
- 1.3.1 简单实现 (基于阈值 theta)
- 1.3.2 使用权重和偏置的实现 (基于 b)
- 1.3.3 代码示例:
- 1.3.4 小结
- 1.4 感知机的局限性
- 1.5 多层感知机(MLP)概述
- 二、 全连接神经网络 (Fully Connected Neural Network)
- 2.1 核心结构
- 2.1.1 输入层 (Input Layer)
- 2.1.2 隐藏层 (Hidden Layer)
- 2.1.3 输出层 (Output Layer)
- 2.2 神经网络基础原理与训练流程
- 2.2.1 散点输入 (Scatter Input)
- 2.2.2 前向计算 (Forward Propagation)
- 2.2.3 参数初始化 (Parameter Initialization)
- 2.2.4 损失函数 (Loss Function)
- 2.2.5 开始迭代 (Start Iteration)
- 2.2.6 反向传播 (Backpropagation)
- 2.2.7 结果显示与优化
- 2.3 代码实现
- 三、Softmax
- 四、交叉熵 (Cross-Entropy)
- 五、 独热编码 (One-Hot Encoding)
- 总结
前言
欢迎来到ai的世界,今天,我们将开始ai深度学习的学习。深度学习其实历史也比较悠久,但是随着算力的飞升和算法的进步。现在,我们无疑迎来了ai的时代。那么就跟随笔者一起,跟随文章的步伐,我们一起进入,深度学习基础的学习吧。
一、感知机 (Perceptron)
1.1 基础介绍
感知机,又称神经元,是神经网络与深度学习的基石。它由 Frank Rosenblatt 于 1957 年提出,其核心思想是现代多层神经网络的起源,掌握其构造有助于理解深度学习的底层逻辑。
1.1.1 感知机是什么?
感知机是一种接收多个输入信号,并输出二元结果(1 或 0)的模型。
输入: 接收多个信号,例如 x1, x2, …
输出: 仅有两种状态——1(表示传递信号或激活)或 0(表示不传递信号或未激活)。其信号流动特性类似于电路中的开关行为。
1.1.2 感知机的工作原理
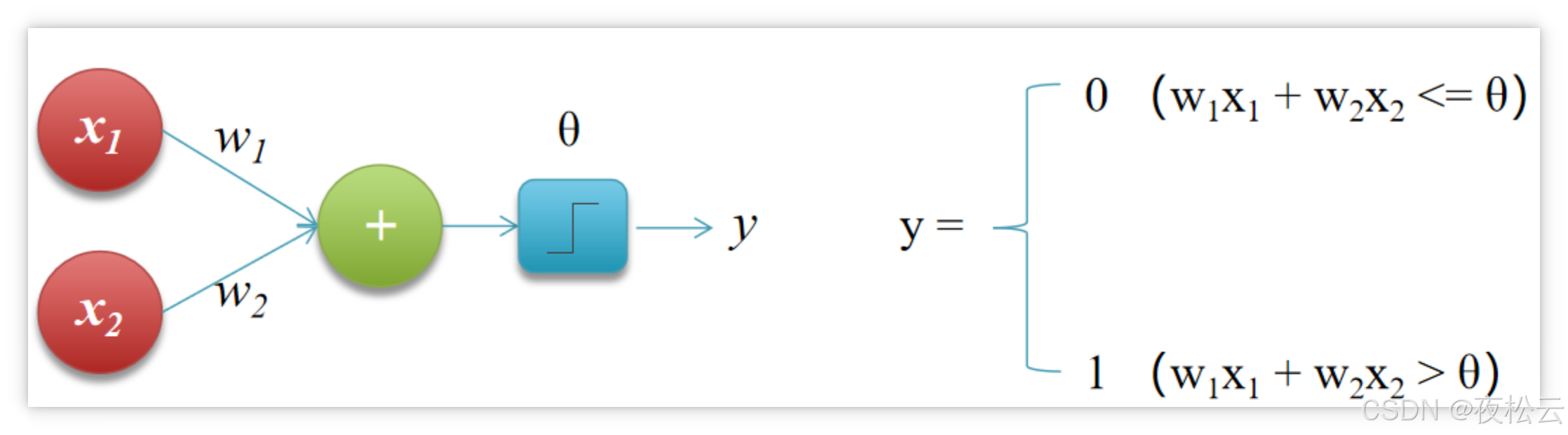
以接收两个输入信号 (x1, x2) 为例,感知机的工作流程如下:
加权求和: 每个输入信号 (x) 都会乘以一个对应的权重 (w)。例如,输入 x1 对应权重 w1,输入 x2 对应权重 w2。然后,将所有加权后的输入信号相加,得到一个总和。
计算示例: 总和 = (x1 * w1) + (x2 * w2)
阈值判断: 将这个加权总和与一个预设的“阈值” (θ) 进行比较。
输出激活:
若加权总和 超过 阈值 θ,感知机被激活,并输出 1。
否则,感知机输出 0。
3. 关键参数
权重 (w): 反映了对应输入信号的重要性。权重值越大,该输入信号对感知机输出的影响越大。
阈值 (θ): 是感知机的激活界限。它决定了加权总和需要达到多高水平才能使感知机被激活并输出1。
1.2 感知机的简单应用:基本逻辑门
本节介绍了感知机在实现基本逻辑门电路方面的应用,包括逻辑与、逻辑或和逻辑与非门。这些逻辑门是数字电路和计算机科学中最基础的组成部分。
1.2.1 逻辑与 (Logic AND)
- 定义: “与门”是一种二输入单输出的门电路。
- 逻辑规则: 当且仅当两个输入信号均为 1 时,输出才为 1;否则(即任一输入为 0 或两个输入均为 0 时),输出为 0。
- 真值表:
| 输入 A | 输入 B | 输出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
1.2.2 逻辑或 (Logic OR)
- 定义: “或门”是一种二输入单输出的逻辑电路。
- 逻辑规则: 只要有一个输入信号是 1,输出就为 1;只有当所有输入信号均为 0 时,输出才为 0。
- 真值表:
| 输入 A | 输入 B | 输出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
1.2.3 逻辑与非 (Logic NAND)
- 定义: “与非门”是一种二输入单输出的逻辑电路。
- 逻辑规则: 它的输出与“与门”的输出完全相反(即对“与门”的输出进行取反)。当两个输入均为 1 时输出 0,否则输出 1。
- 真值表:
| 输入 A | 输入 B | 输出 |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
这段内容详细介绍了感知机的实现,从简单的阈值方式到使用权重和偏置的更通用形式,并通过AND、NAND、OR门的代码示例进行了说明。
1.3 感知机的实现
本节介绍了感知机的两种实现方式,并以AND、NAND、OR门为例进行说明。
1.3.1 简单实现 (基于阈值 theta)
- 概念: 感知机通过计算输入信号与权重的乘积之和,并与一个预设的阈值(
theta)进行比较来决定输出。 - 逻辑: 如果
(x1*w1 + x2*w2)小于等于theta,输出0;否则输出1。 - 示例: AND
def AND(x1, x2):"""实现逻辑AND门的功能。如果输入的加权和超过阈值,则返回1,否则返回0。Args:x1 (int): 第一个输入。x2 (int): 第二个输入。Returns:int: AND门的输出 (0 或 1)。"""w1, w2, theta = 0.5, 0.5, 0.7 # 初始化权重w1, w2和阈值thetatmp = x1 * w1 + x2 * w2 # 计算输入的加权和if tmp <= theta: # 如果加权和小于等于阈值return 0 # 返回0elif tmp > theta: # 如果加权和大于阈值return 1 # 返回1print(AND(0, 0)) # 打印AND(0, 0)的结果
print(AND(1, 0)) # 打印AND(1, 0)的结果
print(AND(0, 1)) # 打印AND(0, 1)的结果
print(AND(1, 1)) # 打印AND(1, 1)的结果
1.3.2 使用权重和偏置的实现 (基于 b)
-
改进: 将阈值
theta转换为偏置b,使感知机的数学表达更通用和统一。- 原条件:
x1*w1 + x2*w2 <= theta - 转换后:
x1*w1 + x2*w2 - theta <= 0 - 令
b = -theta,则变为:x1*w1 + x2*w2 + b <= 0
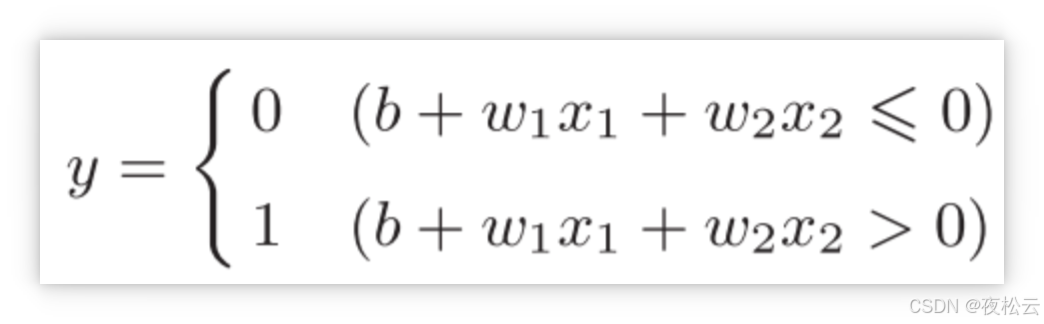
- 原条件:
1.3.3 代码示例:
AND:
import numpy as npdef AND(x1, x2):"""实现逻辑与门。参数:x1 (int): 输入1,可以是0或1。x2 (int): 输入2,可以是0或1。返回:int: 与门的输出,0或1。"""x = np.array([x1, x2]) # 将输入x1和x2转换为NumPy数组w = np.array([0.5, 0.5]) # 权重,用于对输入进行加权b = -0.7 # 偏置,用于调整激活阈值tmp = np.sum(w * x) + b # 计算加权和与偏置的和if tmp <= 0: # 如果和小于或等于0,则输出0return 0else: # 否则(和大于0),则输出1return 1print(AND(0, 0)) # 测试AND(0, 0)
print(AND(1, 0)) # 测试AND(1, 0)
print(AND(0, 1)) # 测试AND(0, 1)
print(AND(1, 1)) # 测试AND(1, 1)
NAND:
import numpy as npdef NAND(x1, x2):"""实现 NAND 逻辑门。参数:x1 (int): 输入1,可以是 0 或 1。x2 (int): 输入2,可以是 0 或 1。返回:int: NAND 运算的结果,0 或 1。"""x = np.array([x1, x2]) # 将输入转换为 NumPy 数组w = np.array([-0.5, -0.5]) # 权重,用于计算加权和b = 0.7 # 偏置项tmp = np.sum(w * x) + b # 计算加权和并加上偏置if tmp <= 0: # 如果和小于或等于0,则输出0return 0else: # 否则,输出1return 1if __name__ == '__main__':print(NAND(0, 0)) # 测试 NAND(0, 0),预期输出 1print(NAND(1, 0)) # 测试 NAND(1, 0),预期输出 1print(NAND(0, 1)) # 测试 NAND(0, 1),预期输出 1print(NAND(1, 1)) # 测试 NAND(1, 1),预期输出 0
OR:
import numpy as npdef OR(x1, x2):"""计算逻辑或(OR)门。参数:x1 (int): 第一个输入,0或1。x2 (int): 第二个输入,0或1。返回:int: 或门的输出,0或1。"""x = np.array([x1, x2]) # 将输入转换为NumPy数组w = np.array([0.5, 0.5]) # 权重b = -0.2 # 偏置tmp = np.sum(w * x) + b # 计算加权和if tmp <= 0: # 激活函数(阶跃函数)return 0else:return 1if __name__ == '__main__':print(OR(0, 0)) # 预期输出: 0print(OR(1, 0)) # 预期输出: 1print(OR(0, 1)) # 预期输出: 1print(OR(1, 1)) # 预期输出: 1
1.3.4 小结
- 权重 (w1, w2): 控制输入信号的重要性或影响力。
- 偏置 (b): 调整神经元激活的难易程度。
- 偏置值越大(负值越小,例如
b=-0.1),表示越容易激活(加权和只需超过0.1)。 - 偏置值越小(负值越大,例如
b=-20.0),表示越难激活(加权和需要超过20.0)。
- 偏置值越大(负值越小,例如
- 关键发现: 不同的逻辑门(AND、NAND、OR)虽然功能不同,但它们的感知机构造是相同的,仅仅通过调整权重和偏置的取值就能实现不同的逻辑功能。
1.4 感知机的局限性
感知机(Perceptron)作为最早的神经网络模型之一,虽然在机器学习领域具有里程碑式的意义,但其核心瓶颈在于线性模型的先天缺陷和单层网络的结构限制。这些局限性极大地限制了感知机的应用范围,并最终推动了多层神经网络以及更复杂模型的发展。
具体来说,感知机的局限性主要体现在以下几个方面:
-
无法解决非线性问题: 感知机是一个线性分类器,这意味着它只能找到一个线性决策边界来将数据分成两类。对于数据点在空间中呈现非线性可分的情况(例如异或问题 XOR),感知机无论如何调整权重,都无法找到一条直线或一个超平面将其正确分类。这是感知机最根本的限制。
-
对噪声敏感: 由于其决策边界是硬性的,感知机对训练数据中的噪声点非常敏感。一个或几个异常值可能导致决策边界发生显著偏移,从而影响模型的泛化能力。
-
收敛性问题: 仅当训练数据是线性可分的情况下,感知机学习算法才能保证收敛。如果数据是非线性可分的,感知机将永远无法收敛到一个稳定的解,权重会持续震荡。
-
单层网络结构限制: 感知机是单层网络,只有一个输入层和一个输出层(没有隐藏层)。这种简单的结构使其无法学习到数据中复杂的特征表示和高级抽象概念。相比之下,多层神经网络通过引入隐藏层,可以学习到数据的多层次、非线性特征,从而解决更复杂的问题。
正是因为这些显著的局限性,研究人员开始探索更强大的模型,最终促成了多层感知机(Multi-layer Perceptron, MLP) 以及后来的 深度学习(Deep Learning) 的蓬勃发展,这些模型通过引入非线性激活函数和多层网络结构,克服了感知机的固有缺陷,开启了人工智能的新篇章。
1.5 多层感知机(MLP)概述
多层感知机(Multilayer Perceptron, MLP)又称人工神经网络(Artificial Neural Network, ANN),是一种重要的前馈式神经网络模型。
核心特点:
- 层级结构: MLP除了输入层和输出层外,中间可以包含一个或多个隐藏层。最简单的MLP只含一个隐藏层,构成“三层结构”(输入层-隐藏层-输出层)。
- 全连接: 各层之间是全连接(Fully Connected)的,即前一层的所有神经元都与下一层的所有神经元相连接。
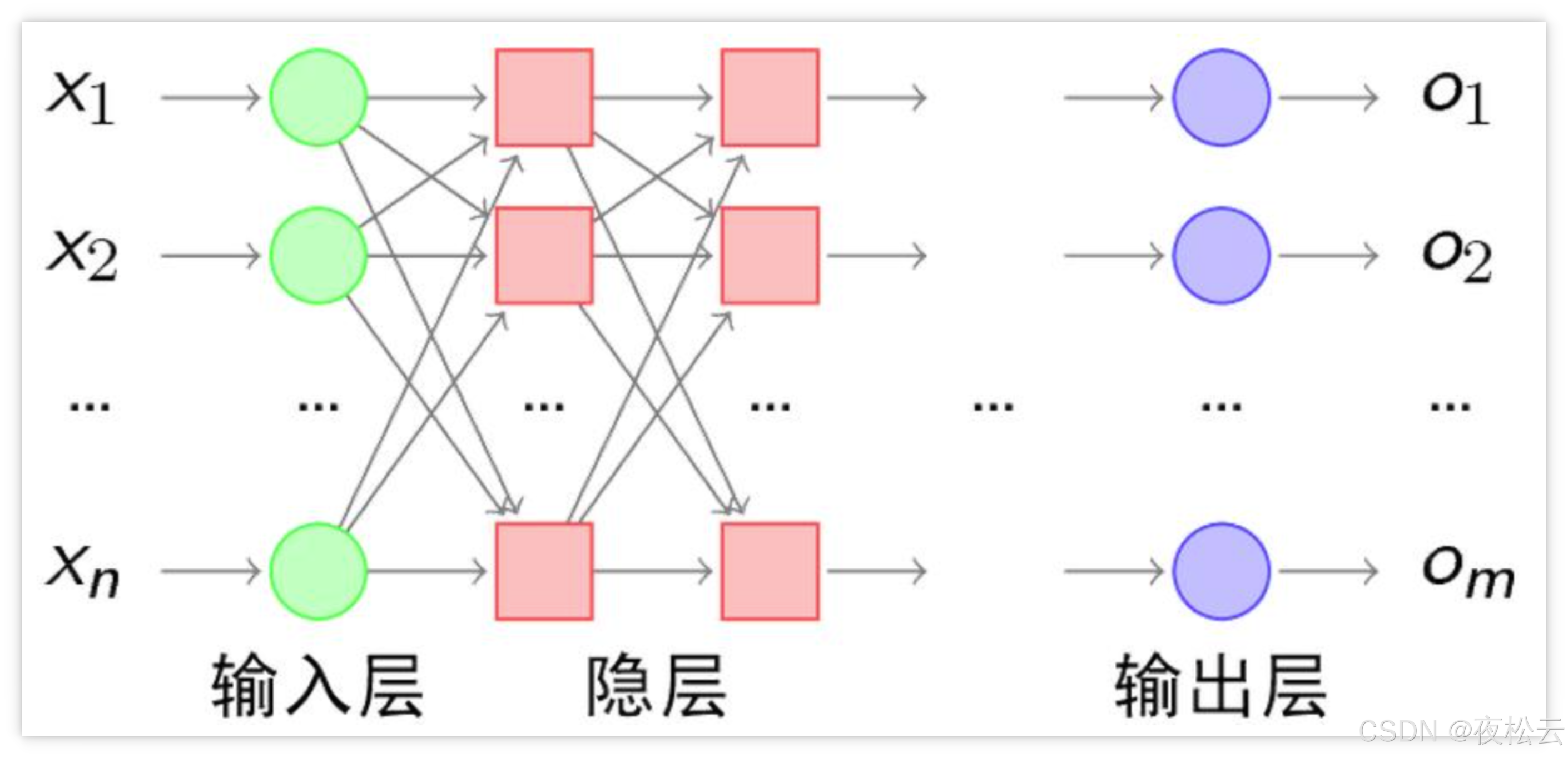
MLP的组成部分(主要三层):
-
输入层 (Input Layer):
- 功能: 接收原始的特征数据。
- 节点数: 等于输入特征的维度。
- 示例: 如图片像素值(扁平化后)、文本的向量表示(词嵌入)。
-
隐藏层 (Hidden Layer):
- 位置: 位于输入层和输出层之间。
- 数量: 可以包含一层或多层神经元。
- 连接: 隐藏层中的神经元通过权重矩阵与前一层(输入层或另一个隐藏层)的神经元连接。
- 核心作用: 是进行特征变换和学习的核心部分。它通过对前一层输入的加权求和并经过激活函数处理,提取出更高层次、更抽象的特征表示,从而发现数据中的复杂模式。
-
输出层 (Output Layer):
- 功能: 根据具体的任务类型输出最终的结果。
- 节点数与激活函数:
- 二分类任务: 通常只包含1个节点,输出一个概率值。
- 多分类任务: 节点数等于类别的数量,常配合Softmax激活函数输出每个类别的概率分布。
二、 全连接神经网络 (Fully Connected Neural Network)
全连接神经网络(Fully Connected Neural Network,简称 FC Neural Network),是人工神经网络中最基础且广泛应用的一种架构。顾名思义,其核心特点是层与层之间节点(神经元)全连接,即前一层的所有节点都与下一层的所有节点相连。它通过学习和调整这些连接的权重与偏置来处理输入信息,实现复杂的模式识别和函数逼近。在工程和学术界,它常被直接简称为“神经网络”。
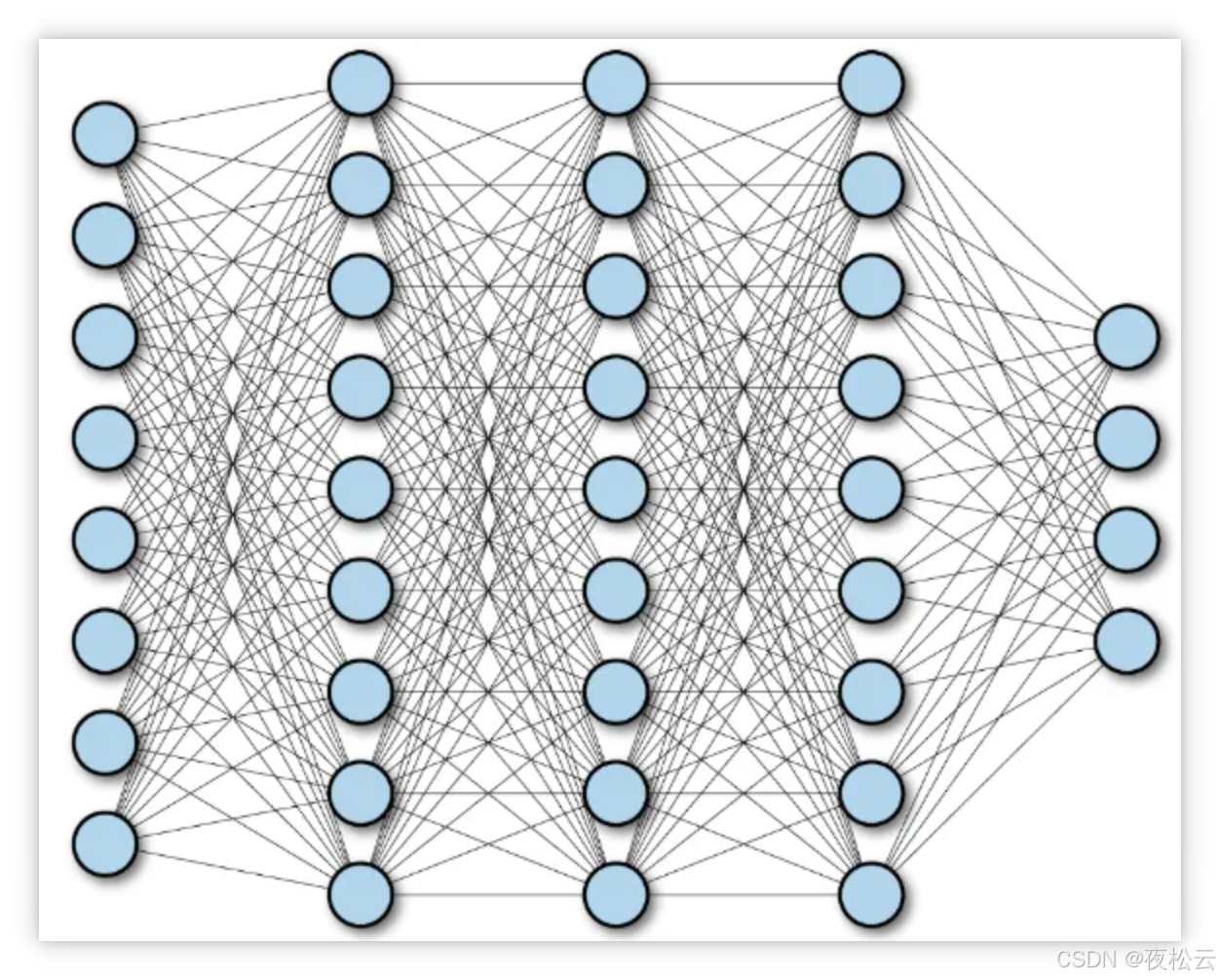
2.1 核心结构
全连接神经网络通常由以下三个核心层次组成:
- 输入层 (Input Layer)
- 隐藏层 (Hidden Layer)
- 输出层 (Output Layer)
每层均由若干个节点(神经元)组成,且层间节点保持全连接特性。
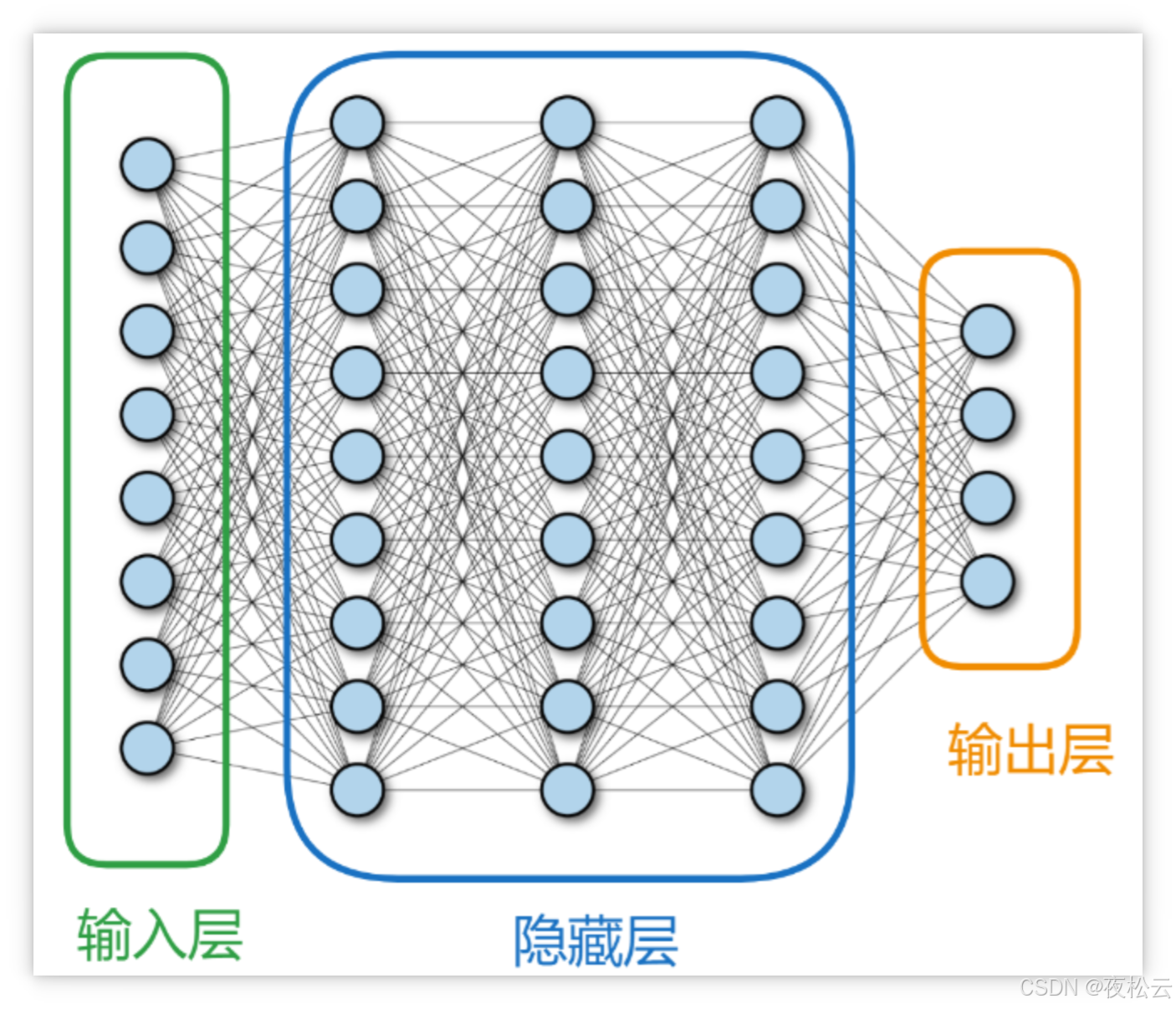
2.1.1 输入层 (Input Layer)
- 数据接收: 尽管深度学习神经网络能处理多种类型的输入(如数值、文字、图像、音频等),但对全连接网络而言,它们必须被转换成 n 维的数值型向量 作为输入。
- 神经元数量: 输入层神经元的数量通常由输入数据的维度决定,可根据任务需求进行调整。
- 数据质量与效率: 为确保训练的有效性与效率,输入数据需满足以下条件:
- 有意义性: 必须是与任务逻辑相关且能反映数据特征的有效信息。无意义的数据(如“抽奖前哈气”)会干扰训练效果,导致模型无法学习到正确模式。
- 效率性: 考虑数据的表示效率。对原始样本进行适当的算法加工(如图像灰度化、标准化、归一化、特征工程等)可以显著提升网络的学习能力和训练速度。
2.1.2 隐藏层 (Hidden Layer)
- 核心组成: 全连接隐藏层是全连接神经网络的核心组成部分。
- 功能定位: 它位于输入层和输出层之间,是数据从输入到输出的转换桥梁。
- 特征提取与抽象: 隐藏层通过引入 非线性激活函数,能够对输入数据进行复杂的非线性特征提取、转换与抽象,从而学习到数据中潜在的复杂模式和关联。这是全连接神经网络能处理非线性问题、拥有强大表达能力的关键。
- 层数与节点数: 一个网络可以包含一个或多个隐藏层(即“深层”神经网络),其数量以及每层神经元的数量是影响模型复杂度和性能的关键超参数,需要根据具体任务进行设计和调优。
2.1.3 输出层 (Output Layer)
- 结果生成: 输出层是全连接神经网络的最后一层,负责生成模型的最终预测结果。
- 神经元数量与激活函数: 其神经元数量和激活函数的选择必须根据具体的任务类型来灵活设置:
- 回归问题 (Regression): 通常使用一个神经元(输出连续值),不使用或使用线性激活函数(Identity Function)。
- 二分类问题 (Binary Classification): 通常使用一个神经元,配合 Sigmoid 激活函数输出 0 到 1 之间的概率值。
- 多分类问题 (Multi-class Classification): 通常使用与类别数量相等的神经元,配合 Softmax 激活函数输出各类别对应的概率分布。
- 任务适配: 正确配置输出层是确保模型能有效解决实际问题的关键。
2.2 神经网络基础原理与训练流程
本文以“衣服尺码接受程度”的拟合问题为例,深入浅出地讲解了全连接神经网络的前向计算、参数初始化、损失函数、迭代训练、反向传播等核心概念。
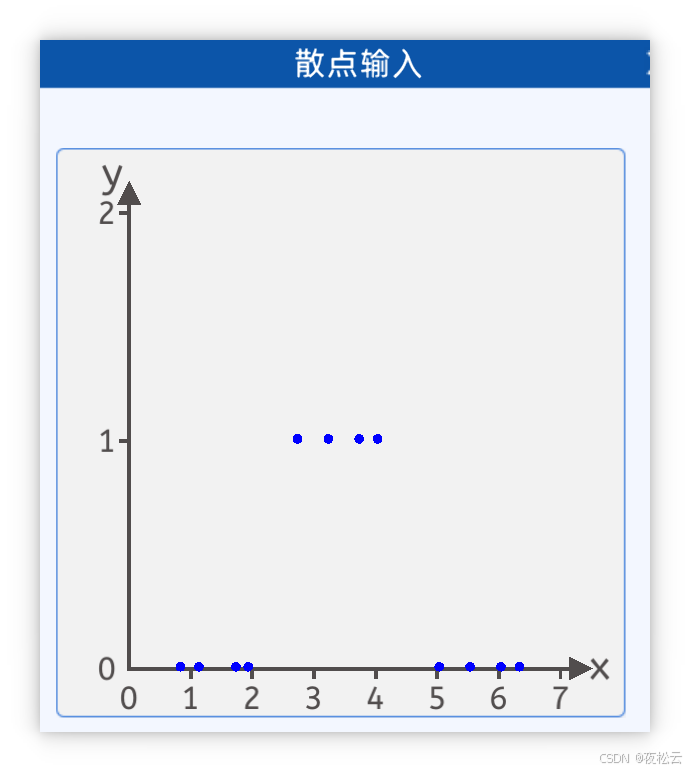
2.2.1 散点输入 (Scatter Input)
问题背景: 调查某人对衣服尺码(横坐标)的接受程度(纵坐标)。当尺码过大或过小都无法穿上。
数据形式: 二维坐标散点图,纵坐标1代表能穿上,0代表穿不上。
目标: 通过神经网络拟合一条曲线,描述尺码与接受度的关系,从而进行预测。
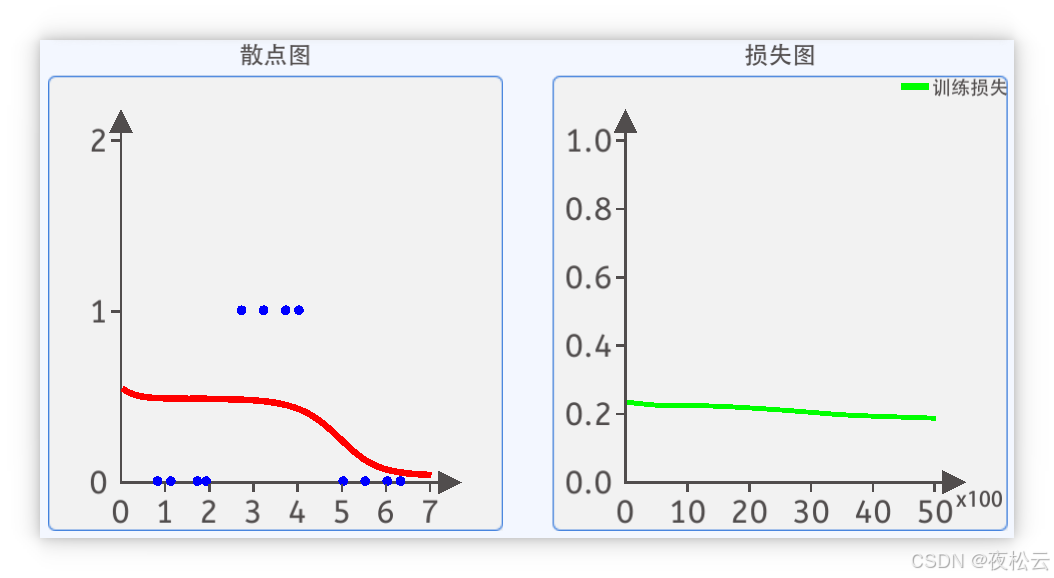
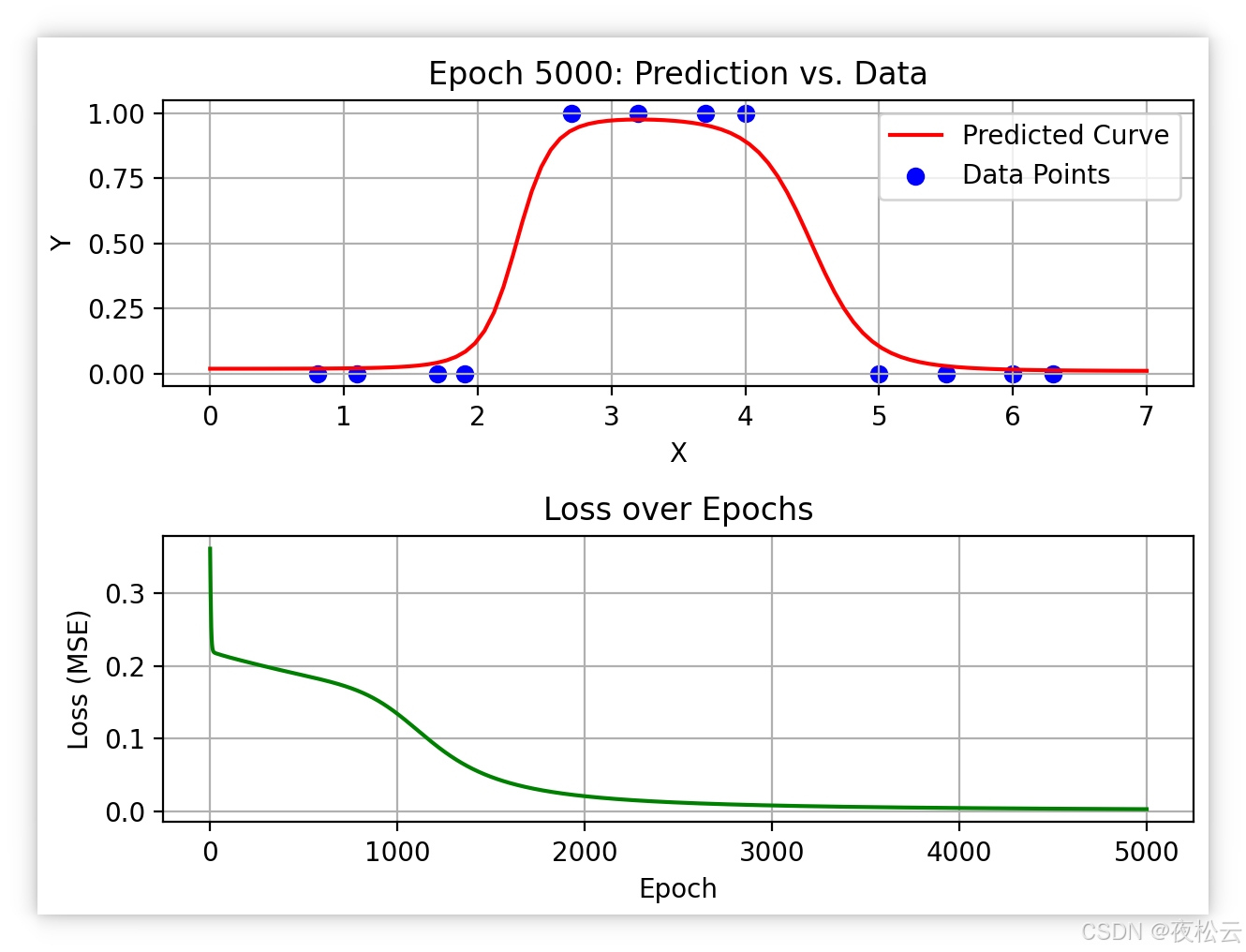
其坐标分别为:[0.8, 0],[1.1, 0],[1.7, 0],[1.9, 0],[2.7, 1],[3.2, 1],[3.7, 1],[4.0, 1],[5.0, 0],[5.5, 0],[6.0, 0],[6.3, 0]
2.2.2 前向计算 (Forward Propagation)
-
核心: 将输入数据通过网络层层计算,最终得到输出。
-
参数:
- 权重 (w): 连接不同节点之间的强度。命名规则:
w_前一层节点索引_本层节点索引_本层层号(如w11_1)。 - 偏置 (b): 调整神经元的激活阈值。命名规则:
b_本层节点索引_本层层号(如b1_1)。
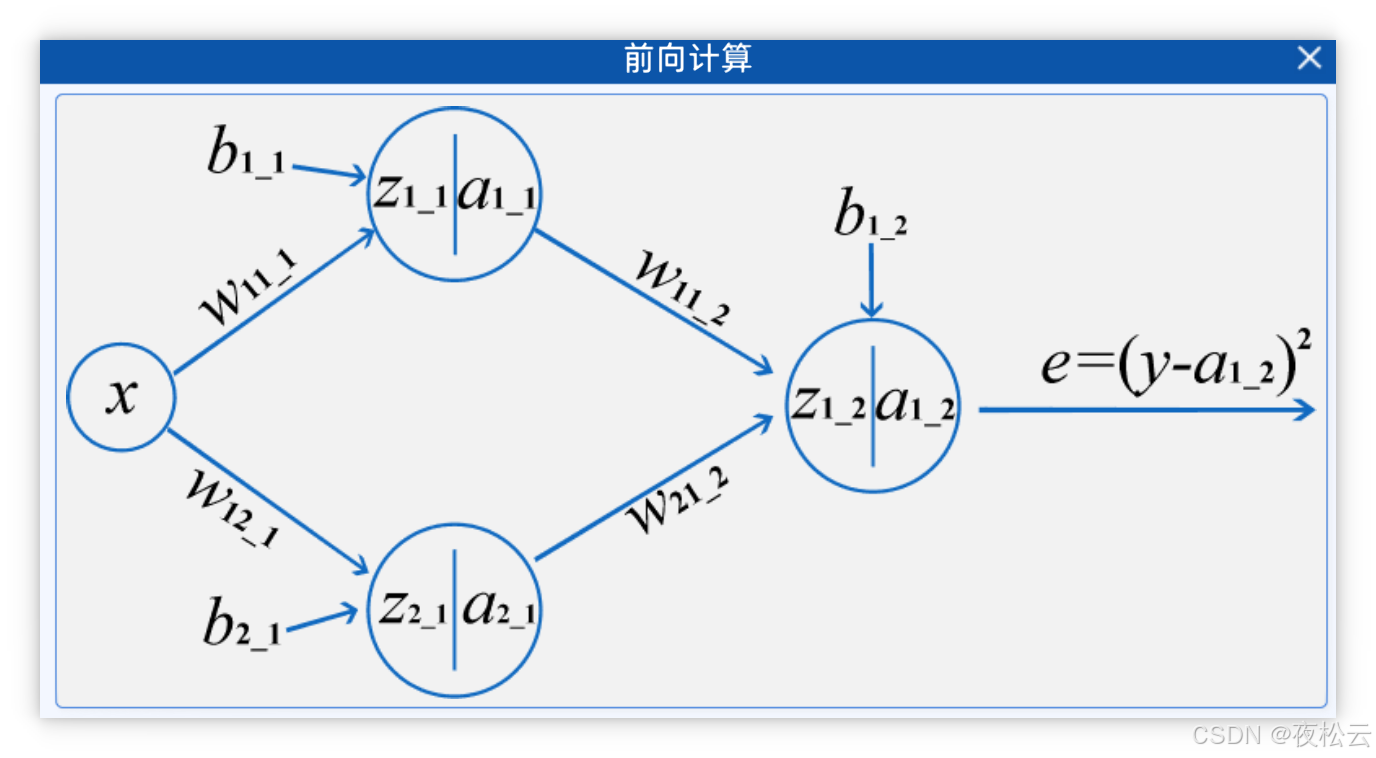
- 权重 (w): 连接不同节点之间的强度。命名规则:
-
节点计算公式:
- 每个节点(从隐藏层开始)的计算分为两步:
- 线性计算 (z):
z = Σ(wij_n * x_i) + b_i_n - 激活 (a):
a = f(z)
- 线性计算 (z):
- 激活函数 (f): 用于引入非线性因素,本实验使用
Sigmoid()函数。 - 举例:
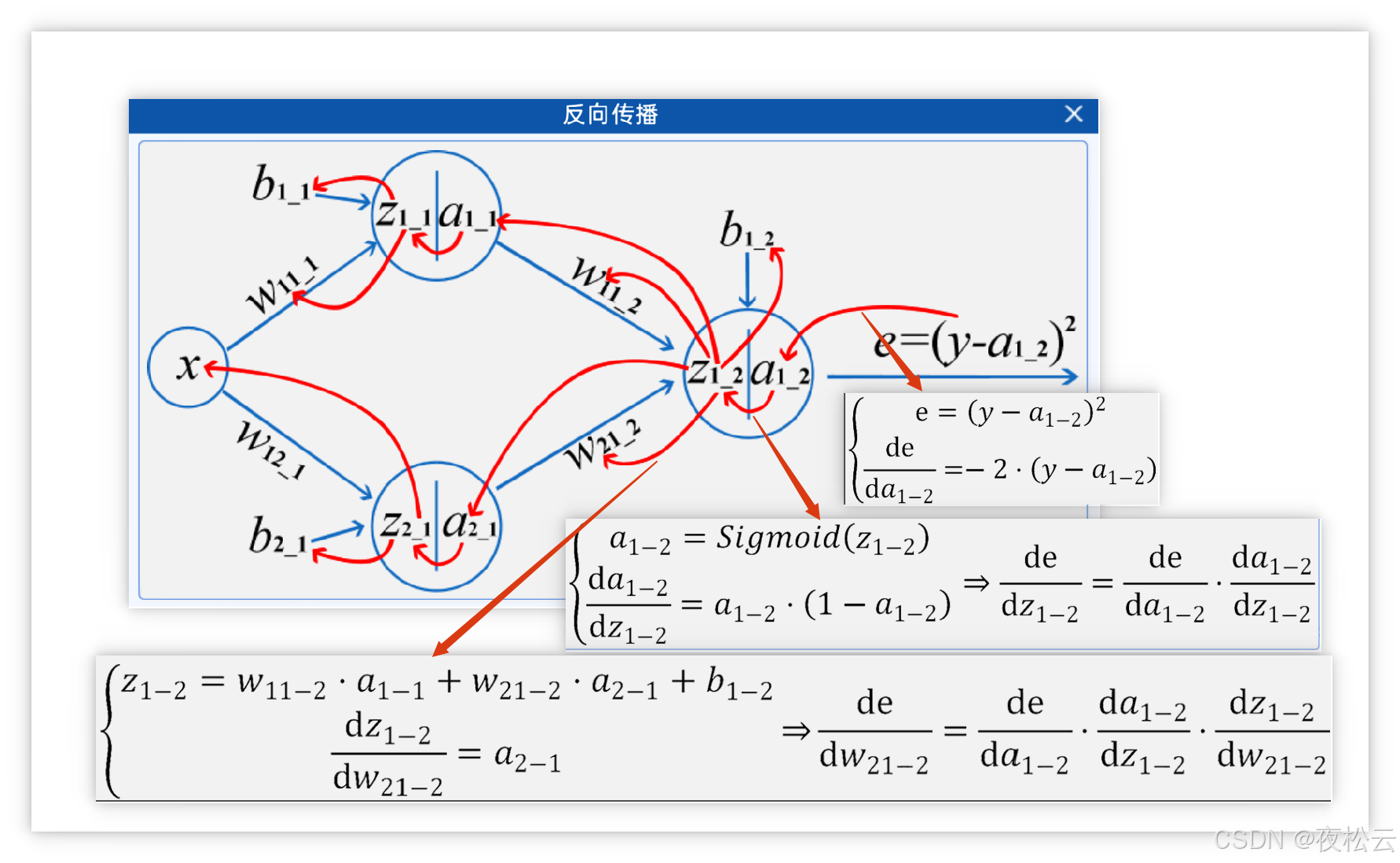
a1_1 = Sigmoid(z1_1),其中z1_1 = w11_1 * x + b1_1。a2_1 = Sigmoid(z2_1),其中z2_1 = w12_1 * x + b2_1。a1_2 = Sigmoid(z1_2),其中z1_2 = w11_2 * a1_1 + w21_1 * a2_1 + b1_2。
- 每个节点(从隐藏层开始)的计算分为两步:
-
损失函数 (Loss Function):
- 前向计算的最终结果用于计算损失。
- 本实验使用 均方误差 (MSE):
e = (y - a1_2)^2,其中y是真实值,a1_2是网络输出。
2.2.3 参数初始化 (Parameter Initialization)
在进行前向计算之前,需要初始化网络中的所有权重 w 和偏置 b,以及学习率。
参数的修改会直接影响拟合曲线的形状。
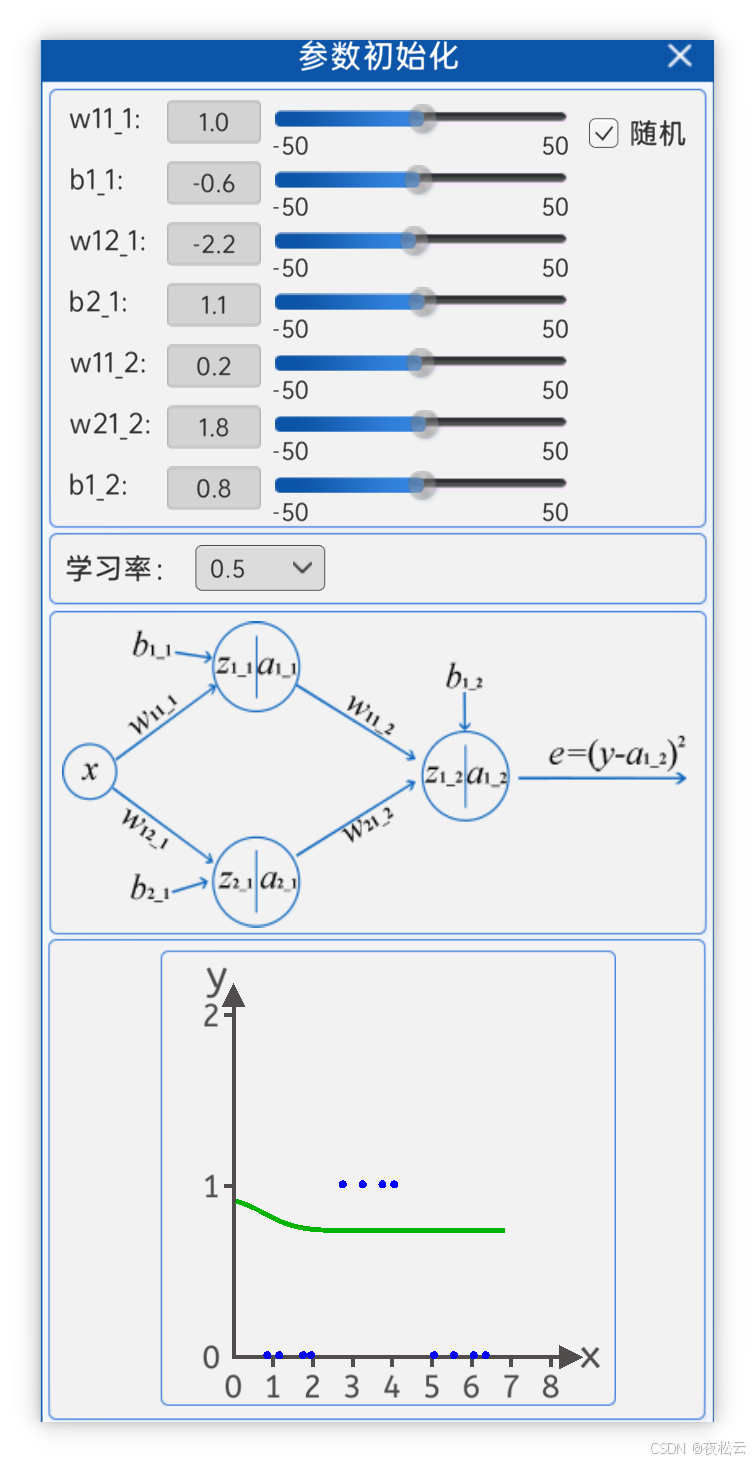
2.2.4 损失函数 (Loss Function)
明确了目标是拟合曲线,因此选用MSE作为损失函数,衡量模型输出与真实数据之间的差异。
2.2.5 开始迭代 (Start Iteration)
神经网络通过不断的迭代更新参数来训练。
由于神经网络模型复杂、参数量大,迭代次数通常很多(本实验默认5000次)。
注意:简单的网络结构拟合复杂曲线可能较困难。
2.2.6 反向传播 (Backpropagation)
目的: 在每次迭代中,计算损失函数对所有参数(w 和 b)的梯度(导数)。
核心原理: 链式求导法则 (Chain Rule)。
定义: 当函数是复合函数时(如神经网络层间关系),求导时需遵循逐层求导并相乘的原则。
单变量例子: 若 h(x) = f(g(x)), 则 h'(x) = f'(g(x)) * g'(x)。
多变量例子: 若 z=f(u,v) 且 u=u(x,y), v=v(x,y),则 ∂z/∂x = (∂f/∂u) * (∂u/∂x) + (∂f/∂v) * (∂v/∂x)。
应用: 通过链式法则,可以有效地计算损失对每一层参数的梯度,为后续的参数更新提供依据。
2.2.7 结果显示与优化
-
2.7 显示频率设置 (Display Frequency Setting)
- 用于控制在训练过程中,拟合线和损失函数显示的频率,方便观察训练进展。
-
2.8 梯度下降显示 (Gradient Descent Display)
- 可视化组件,实时显示:
- 每个参数值随迭代次数的更新情况。
- 基于当前参数值绘制的拟合曲线。
- 当前参数值下的损失值。
- 随着迭代次数增加,参数不断更新,损失值会逐渐下降。
- 可视化组件,实时显示:
2.3 代码实现
# 导入相关库
import numpy as np # 导入 NumPy 库,用于进行数值计算,特别是数组操作
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图表# 1. 散点输入
# 定义一组散点数据,每行代表一个样本,第一列是特征 X,第二列是标签 Y
points = np.array([[0.8, 0],[1.1, 0],[1.7, 0],[1.9, 0],[2.7, 1],[3.2, 1],[3.7, 1],[4.0, 1],[5.0, 0],[5.5, 0],[6.0, 0],[6.3, 0]])# 将输入样本的特征和标签分开
X = points[:, 0] # 从 points 数组中提取所有行的第一列,作为特征 X
Y = points[:, 1] # 从 points 数组中提取所有行的第二列,作为标签 Y# 2. 前向计算
# 定义 Sigmoid 激活函数
def sigmoid(x):"""Sigmoid 激活函数,将输入值 x 映射到 (0, 1) 区间。常用于神经网络的输出层,尤其是在二分类问题中。"""return 1 / (1 + np.exp(-x))# 定义神经网络的前向传播函数
def forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, x):"""神经网络的前向传播过程。这是一个包含一个隐藏层(两个神经元)和一个输出层(一个神经元)的神经网络。参数:w11_1, b1_1: 第一个隐藏层神经元1的权重和偏置w12_1, b2_1: 第一个隐藏层神经元2的权重和偏置w11_2, w21_2, b1_2: 输出层神经元的权重和偏置 (w11_2 连接隐藏层神经元1到输出层, w21_2 连接隐藏层神经元2到输出层)x: 输入特征返回值:a1_1: 隐藏层神经元1的激活值a2_1: 隐藏层神经元2的激活值a1_2: 输出层神经元的激活值 (即预测结果)"""# 隐藏层第一个神经元z1_1 = w11_1 * x + b1_1 # 线性组合a1_1 = sigmoid(z1_1) # 激活# 隐藏层第二个神经元z2_1 = w12_1 * x + b2_1 # 线性组合a2_1 = sigmoid(z2_1) # 激活# 输出层神经元z1_2 = a1_1 * w11_2 + a2_1 * w21_2 + b1_2 # 线性组合 (接收来自两个隐藏层神经元的输出)a1_2 = sigmoid(z1_2) # 激活return a1_1, a2_1, a1_2 # 返回各层激活值# 3. 参数初始化
# 初始化神经网络的权重和偏置
# 这些初始值是随机选择的,也可以根据经验或其他方法进行初始化
w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2 = 0.1, 0.6, 0.9, -1.5, 0.1, 0.9, 0.2
lr = 0.5 # 学习率 (learning rate),控制每次参数更新的步长# 4. 损失函数
def loss_func(y, y_hat):"""定义均方误差 (Mean Squared Error, MSE) 损失函数。用于衡量模型预测值 (y_hat) 与真实值 (y) 之间的差异。"""loss = np.mean((y - y_hat) ** 2) # 计算所有样本的平方误差的平均值return loss# 5. 迭代 (训练过程)
# 用于绘图的 x 轴范围
x_values = np.linspace(0, 7, 100) # 在 0 到 7 之间生成 100 个等间隔的点
loss_list = [] # 用于记录每个 epoch 的损失值
epoches_list = [] # 用于记录每个 epoch 的编号# 设置迭代次数 (训练轮数)
epoches = 5000
for epoch in range(1, epoches + 1): # 从 1 到 epoches 进行迭代# 计算损失函数# 使用当前参数进行前向传播,得到预测值 a1_2a1_1, a2_1, a1_2 = forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, X)loss = loss_func(Y, a1_2) # 计算当前预测值与真实标签之间的损失loss_list.append(loss) # 将当前损失值添加到列表中epoches_list.append(epoch) # 将当前 epoch 编号添加到列表中# print(loss) # 可以打印每次迭代的损失,但通常只在特定频率打印# 反向传播 (计算梯度)# 损失对输出层激活值 a1_2 的梯度deda1_2 = -2 * (Y - a1_2) # 均方误差损失对 a1_2 的导数# 损失对输出层线性组合 z1_2 的梯度# dedz1_2 = deda1_2 * sigmoid_derivative(z1_2) = deda1_2 * a1_2 * (1 - a1_2)dedz1_2 = deda1_2 * a1_2 * (1 - a1_2)# 损失对输出层权重 w11_2 和 w21_2 的梯度dedw11_2 = np.mean(dedz1_2 * a1_1) # 损失对 w11_2 的梯度,求平均dedw21_2 = np.mean(dedz1_2 * a2_1) # 损失对 w21_2 的梯度,求平均# 损失对输出层偏置 b1_2 的梯度dedb1_2 = np.mean(dedz1_2) # 损失对 b1_2 的梯度,求平均# 损失对隐藏层神经元1激活值 a1_1 的梯度# deda1_1 = dedz1_2 * w11_2 (根据链式法则)deda1_1 = dedz1_2 * w11_2# 损失对隐藏层神经元1线性组合 z1_1 的梯度# dedz1_1 = deda1_1 * sigmoid_derivative(z1_1) = deda1_1 * a1_1 * (1 - a1_1)dedz1_1 = deda1_1 * (a1_1 * (1 - a1_1))# 损失对隐藏层神经元1权重 w11_1 的梯度dedw11_1 = np.mean(dedz1_1 * X) # 损失对 w11_1 的梯度,求平均# 损失对隐藏层神经元1偏置 b1_1 的梯度dedb1_1 = np.mean(dedz1_1) # 损失对 b1_1 的梯度,求平均# 损失对隐藏层神经元2激活值 a2_1 的梯度# deda2_1 = dedz1_2 * w21_2 (根据链式法则)deda2_1 = dedz1_2 * w21_2# 损失对隐藏层神经元2线性组合 z2_1 的梯度# dedz2_1 = deda2_1 * sigmoid_derivative(z2_1) = deda2_1 * a2_1 * (1 - a2_1)dedz2_1 = deda2_1 * a2_1 * (1 - a2_1)# 损失对隐藏层神经元2权重 w12_1 的梯度dedw12_1 = np.mean(dedz2_1 * X) # 损失对 w12_1 的梯度,求平均# 损失对隐藏层神经元2偏置 b2_1 的梯度dedb2_1 = np.mean(dedz2_1) # 损失对 b2_1 的梯度,求平均# 梯度更新 (使用梯度下降法更新参数)# 参数 = 参数 - 学习率 * 梯度w11_2 = w11_2 - lr * dedw11_2w21_2 = w21_2 - lr * dedw21_2b1_2 = b1_2 - lr * dedb1_2w11_1 = w11_1 - lr * dedw11_1b1_1 = b1_1 - lr * dedb1_1w12_1 = w12_1 - lr * dedw12_1b2_1 = b2_1 - lr * dedb2_1# 7. 显示频率设置和绘图# 每 100 个 epoch (或者在第一个 epoch) 打印信息并更新图表if epoch == 1 or epoch % 100 == 0:print(f"epoch:{epoch},loss:{loss:.4f}") # 打印当前 epoch 和损失值,保留四位小数# 清除当前图形,准备绘制新的图表plt.clf()# 创建一个 2 行 1 列的子图布局,并在第一个子图 (上部) 绘制散点图和预测曲线plt.subplot(2, 1, 1)# 使用当前更新的参数,对 x_values 进行前向传播,得到预测曲线a1_1, a2_1, a1_2_pred = forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, x_values)plt.plot(x_values, a1_2_pred, color='red', label='Predicted Curve') # 绘制预测曲线,设置为红色# 绘制原始数据散点图plt.scatter(X, Y, color='blue', label='Data Points') # 绘制散点图,设置为蓝色plt.title(f'Epoch {epoch}: Prediction vs. Data') # 添加标题plt.xlabel('X') # 添加 x 轴标签plt.ylabel('Y') # 添加 y 轴标签plt.legend() # 显示图例plt.grid(True) # 显示网格# 在第二个子图 (下部) 绘制损失值随 epoch 变化的曲线plt.subplot(2, 1, 2)plt.plot(epoches_list, loss_list, color='green') # 绘制损失曲线plt.title('Loss over Epochs') # 添加标题plt.xlabel('Epoch') # 添加 x 轴标签plt.ylabel('Loss (MSE)') # 添加 y 轴标签plt.grid(True) # 显示网格plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域plt.pause(0.1) # 暂停 0.1 秒,以便可以看到动画效果# 8. 梯度下降显示
plt.show() # 训练结束后,保持最后一个图表显示
三、Softmax
Softmax是一种常用于分类任务的激活函数,其核心作用是将一组任意实数输入值转换为[0,1]区间内的概率分布。Softmax的输出可以被直接理解为输入属于每个类别的概率。
1. “Soft”与“Hard”的区别
- Hardmax(硬最大值): 仅选择输入值中的单一最大值,做出“非黑即白”的判断。例如,在一组数值中直接找出最大元素。在多分类场景(如一篇文章可能包含多个主题)中,这种单一判断往往不合理。
- Softmax(软最大值): 引入了“soft”的概念。它不再唯一确定最大值,而是为每个可能的分类结果都赋予一个介于0到1之间的概率值,以此来表征属于该类别的可能性。
2. 数学公式
Softmax函数的数学公式如下:
S o f t m a x ( y ) = e y i ∑ e y i Softmax(y)=\frac{e^{y_{i}}}{\sum e^{y_{i}}} Softmax(y)=∑eyieyi
其中, e x e^x ex表示指数函数,即 e x p ( x ) exp(x) exp(x)。
关键特性:根据公式,无论最终分类有多少个类别,所有输出概率之和恒为1。
3. 作用
Softmax函数的主要作用是将:
- 一组实数输入值映射到(0,1)区间内。
- 输出一个概率分布。
- 输出的每个值代表输入属于对应类别的概率。
- 所有类别的概率之和为1。
4. 代码实现(示例)
#导入相关库
import numpy as np # 导入NumPy库,用于进行数值计算x = np.array([1, 2, 3, 4]) # 初始化一个NumPy数组x
t1 = np.exp(x[0]) / np.sum(np.exp(x)) # 计算第一个元素的softmax概率
t2 = np.exp(x[1]) / np.sum(np.exp(x)) # 计算第二个元素的softmax概率
t3 = np.exp(x[2]) / np.sum(np.exp(x)) # 计算第三个元素的softmax概率
t4 = np.exp(x[3]) / np.sum(np.exp(x)) # 计算第四个元素的softmax概率
print(t1 + t2 + t3 + t4) # 打印所有softmax概率之和,验证其是否为1四、交叉熵 (Cross-Entropy)
交叉熵是信息论中用于衡量两个概率分布之间差异的度量。在分类问题中,它具体衡量模型预测的类别概率分布与真实标签分布之间的差异。
交叉熵的通用公式为:
H ( p , q ) = − ∑ p ( i ) log q ( i ) H(p,q)=-\sum p(i)\log q(i) H(p,q)=−∑p(i)logq(i)
其中:
- p ( i ) p(i) p(i):真实分布中第 i i i 个类别的概率。
- q ( i ) q(i) q(i):模型预测的第 i i i 个类别的概率。
- l o g log log:以 e e e 为底的自然对数。
在机器学习和深度学习中,常见的交叉熵损失函数有两种形式:
-
二分类交叉熵 (Binary Cross-Entropy, BCE)
用于二分类问题。H ( y , y ^ ) = − ( y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ) H(y, \hat{y}) = - (y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})) H(y,y^)=−(ylog(y^)+(1−y)log(1−y^))
其中:
- y y y:真实标签(通常为 0 或 1)。
- y ^ \hat{y} y^:模型的预测概率(通常是经过 Sigmoid 激活函数后的输出)。
-
多分类交叉熵 (Categorical Cross-Entropy, CCE)
用于多分类问题。H ( y , y ^ ) = − ∑ i y i log ( y ^ i ) H(y, \hat{y}) = - \sum_{i} y_i \log(\hat{y}_i) H(y,y^)=−∑iyilog(y^i)
其中:
- y i y_i yi:真实标签的第 i i i 个元素(在独热编码中,真实类别对应位置为 1,其余为 0)。
- y ^ i \hat{y}_i y^i:模型的预测概率的第 i i i 个元素(通常是经过 Softmax 激活函数后的输出)。
在训练神经网络时,我们的目标是最小化交叉熵损失。通过最小化此损失,模型会调整其参数,使模型的预测概率分布尽可能地接近真实的标签分布。这样的训练过程有助于提高模型对不同类别的分类准确性。
以下是对所提供内容的整理:
五、 独热编码 (One-Hot Encoding)
独热编码是一种将离散型特征(如类别变量)转换为二进制向量的编码方式。
-
核心思想:用唯一的二进制位表示每个类别,确保向量中只有一个位置为 1,其余为 0。
-
示例:在三分类问题中,真实标签“狗”可以被独热编码为
[0,1,0]。 -
神经网络结构:
- 输入层:包含 2 个节点(代表 2 个输入特征)。
- 隐藏层:包含 1 个节点。
- 输出层:节点数与分类类别数一致(例如,对于三分类任务,输出层有 3 个节点)。
-
处理流程:神经网络的输出层结果会先经过 Softmax 函数计算得到各类别的概率,然后将这些概率与真实标签带入交叉熵公式,最终得到损失值。
训练效果与结论
该组件通过两个训练阶段的示例展示了Softmax与交叉熵在分类任务中的有效性:
-
阶段一(30 轮训练):
- 以真实标签“狗”的独热编码
[0,1,0]为例,经过 30 轮训练后,Softmax 输出中“狗”的概率显著高于“猫”和“虎”。 - 此时,计算得到的交叉熵损失为 0.164,表明分类效果已经较好。

- 以真实标签“狗”的独热编码
-
阶段二(60 轮训练):
- 随着训练轮数增加到 60 轮,损失值进一步减小。
- Softmax 输出的“狗”的概率更接近于 1,说明模型对“狗”这一类别的预测置信度更高。

-
结论:
- Softmax 与交叉熵的结合对于分类任务是高效且有效的。
- 因此,它们在图像识别、自然语言处理(NLP)等多种分类算法中被广泛且共同使用。
总结
本文系统性地介绍了深度学习的入门基础,从最原始的感知机(Perceptron)概念入手,阐述了其作为神经网络基石的原理、工作方式(加权求和与阈值判断)以及通过调整权重和偏置实现基本逻辑门(AND, OR, NAND)的简单应用。同时,文章深入探讨了感知机在处理非线性问题上的局限性,从而自然引出了多层感知机(MLP)和全连接神经网络(FCNN)的必要性。
文章详细解析了全连接神经网络的层级结构(输入层、隐藏层、输出层)及其各自的功能,特别强调了隐藏层通过非线性激活函数进行复杂特征提取的核心作用。接着,以一个具体的“衣服尺码接受度”拟合问题为例,文章循序渐进地讲解了神经网络的训练流程:包括前向计算(参数、节点计算公式、激活函数如Sigmoid)、参数初始化、损失函数(均方误差MSE)、迭代训练以及最为关键的反向传播(利用链式求导法则计算梯度并更新参数)。文中还提供了完整的Python代码实现,直观展示了训练过程中损失的下降和拟合曲线的演变。
最后,文章介绍了分类任务中不可或缺的几个核心概念:Softmax激活函数(将实数转换为概率分布),交叉熵损失函数(衡量预测分布与真实分布差异),以及独热编码(将类别转换为二进制向量)。通过这些内容的介绍,读者将对深度学习中最基础的神经网络模型、训练机制以及分类问题的处理方式有一个全面而清晰的理解。