在ARM+Ascend NPU上适配Step-Audio模型
A+K场景下运行Step Audio模型
1.概述
1.1 Step-Audio简介
Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱等。其核心技术突破体现在以下四大技术亮点:
• 1300亿多模态模型: 单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat。
• 高效数据生成链路: 基于130B 突破传统 TTS 对人工采集数据的依赖,生成高质量的合成音频数据,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。
• 精细语音控制: 支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
• 扩展工具调用: 通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
1.2 Step-Audio-NPU在X86适配情况
当前step-audio模型已经在A+X环境上打通,并已经在魔乐社区上发表,具体可以参考:https://modelers.cn/models/StepFun/Step-Audio-npu
2 Step-Audio-NPU在ARM上的适配
2.1 服务器 & 容器环境信息
服务器系统环境(这里展示本次运行的环境,当作参考)
root@2:/data/zjun/onnxruntime/build/Linux/Release/dist# uname -a
Linux 2 4.19.90-vhulk2211.3.0.h1960.eulerosv2r10.aarch64 #1 SMP Sat Dec 7 01:22:24 UTC 2024 aarch64 aarch64 aarch64 GNU/Linux
容器环境(这里展示本次运行的环境,当作参考)
容器镜像:
swr.cn-central-221.ovaijisuan.com/wh-aicc-fae/mindie:37131-ascend_24.1.rc2-cann_8.0.rc2-py_3.10-ubuntu_22.04-aarch64-mindie_1.0.RC2.01
这里的Mind IE的镜像装好了CANN(容器的CANN版本是cann_8.0.rc2,理论上装CANN8.0即可),并且操作系统是ubuntu。
2.2 环境准备
ARM环境上的环境配置信息与x86上的配置信息一致,如下:
软件包 版本
CANN 8.0.0
PTA 6.0.0
HDK 24.1.0
PYTORCH 2.1.0
PYTHON 3.10
2.2.1 Pytorch & PTA安装
CANN、PTA、HDK的环境安装,请按照https://modelers.cn/models/StepFun/Step-Audio-npu中CANN安装进行准备,如果有容器装好了直接使用容器,这里不再赘述。
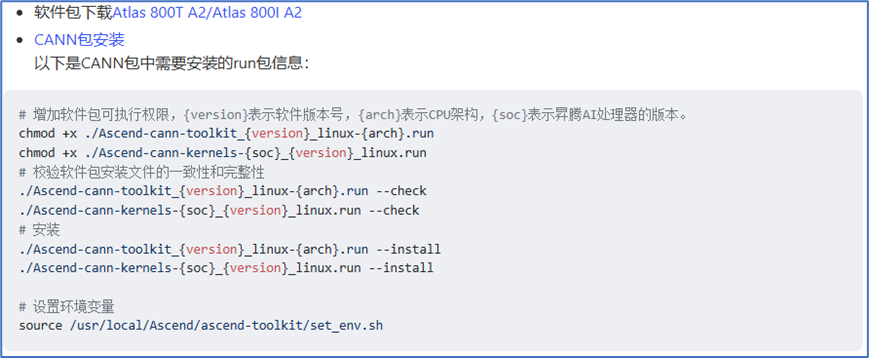
Pytorch & Ascend Extension for PyTorch ARM上安装
以下是python3.10,pytorch2.1.0,PTA插件版本6.0.0,系统架构是AArch64,CANN版本是8.0.0的安装信息:
# 下载PyTorch安装包
wget https://download.pytorch.org/whl/cpu/torch-2.1.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 下载torch_npu插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.0-pytorch2.1.0/torch_npu-2.1.0.post10-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装命令
pip3 install torch-2.1.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch_npu-2.1.0.post10-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl具体安装,可以参考:
(https://www.hiascend.com/document/detail/zh/Pytorch/600/configandinstg/instg/insg_0001.html)
2.3 依赖包安装
修改requirements.txt中的依赖信息,具体如下:
• torch2.3.1 -> torch2.1.0
• torchaudio2.3.1 -> torchaudio 2.1.0
• torchvision0.18.1 -> torchvision0.16
• 注释掉 # onnxruntime-gpu ==1.17.0
2.3.1 安装onnxruntime-cann
参考Ascend NPU上适配Step-Audio模型
2.3.2 安装其它依赖
其它依赖请执行
pip install -r requirements.txt
2.3.3 whisper安装
模型对whisper有依赖,请安装
pip install openai-whisper
3、模型运行
3.1 模型权重下载
具体下载请参照https://modelers.cn/models/StepFun/Step-Audio-npu中模型权重下载章节:
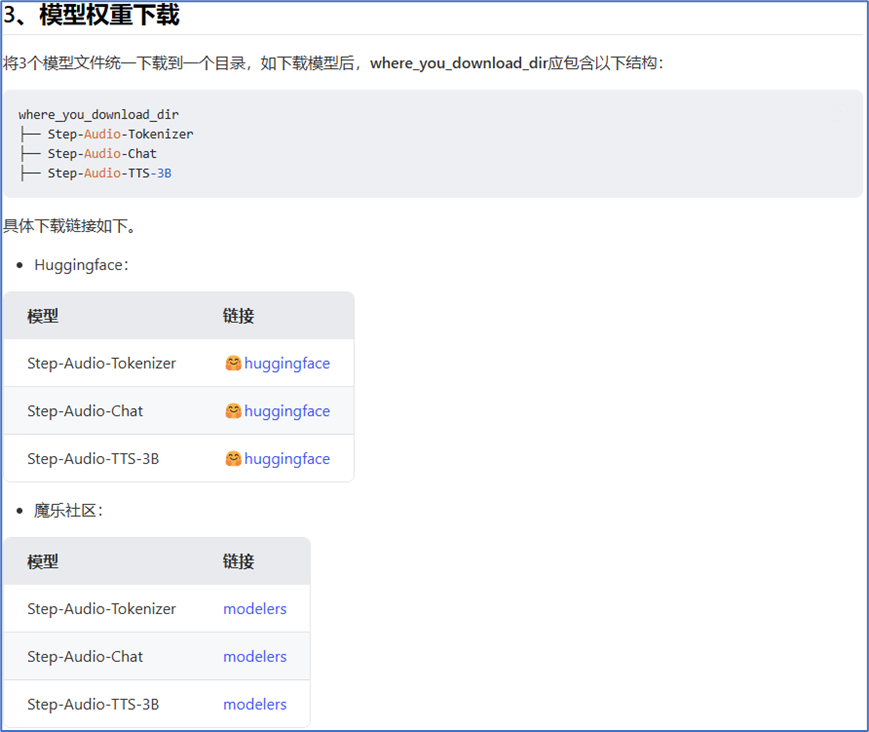
where_you_download_dir假设为audio-weight,那么目录audio-weight应包含以下结构。
audio-weight
├── Step-Audio-Tokenizer
├── Step-Audio-Chat
├── Step-Audio-TTS-3B通过git下载注意一定要安装git lfs,ubuntu安装的命令如下:
Apt install git-lfs
通过以下命令下载后,请检查权重的大小是否匹配。(没有安装lfs,下载过程很快,而且权重safetensors的大小会明显不对)
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B3.2 模型运行
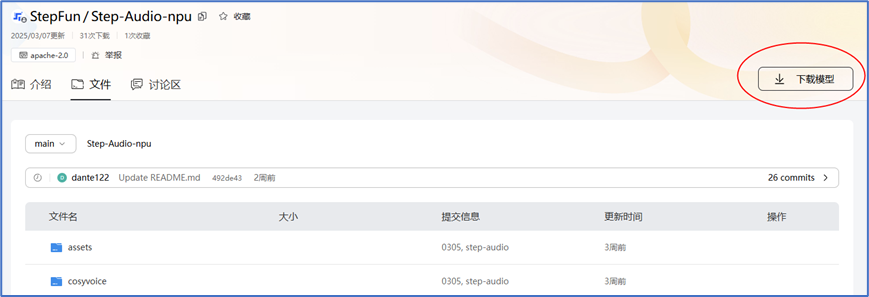
3.2.1 下载已适配npu模型
进入链接:https://modelers.cn/models/StepFun/Step-Audio-npu/tree/main,下载模型
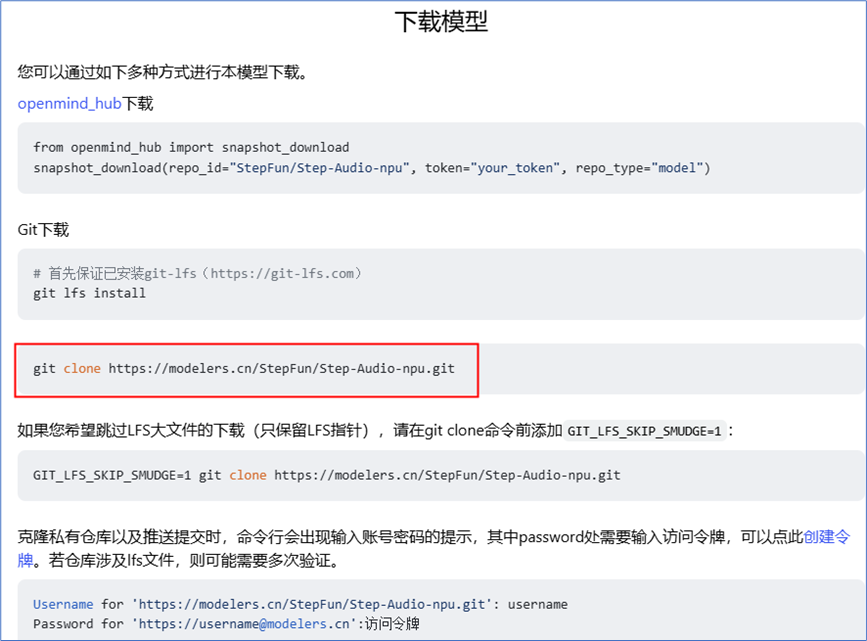
接着执行下载命令。(这里演示通过git下载,且lfs已经安装,所以只需要执行红框中命令即可,也可以通过openmind_hub下载)
下载成功后的目录内容如下:
3.2.2 执行推理
执行CANN相关的环境变量
source /usr/local/Ascend/ascend-toolkit/`在这里插入代码片`set_env.sh
3.2.2.1 语音合成推理
使用默认音色进行语音合成推理或使用新音色进行克隆。这里演示使用tts进行推理。进入到Step-Audio-npu目录,执行如下命令:
ASCEND_RT_VISIBLE_DEVICES=0 python tts_inference.py --model-path /home/audio-weight --output-path output-tts --synthesis-type tts
注意:
/home/audio-weight为上述模型权重下载的具体路径。
output-tts为提前创建的wav文件输出路径。
上述命令执行成功后,会在output-tts生成:

3.2.2.2 离线推理
支持端到端音频/文本输入与音频/文本输出的推理流程。
ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python offline_inference.py --model-path /home/audio-weight
注意:
/home/audio-weight为上述模型权重下载的具体路径。
提前创建好output文件夹,用来放置输出,否则报错。
上述命令执行成功后,会在output生成
