2025-04-20-CPU-GPU-NPU 的区别及应用前景
CPU-GPU-NPU 的区别及应用前景
参考资料
- CPU、GPU、NPU 的区别_npu 和 gpu 区别-CSDN 博客
- 一文看懂 CPU, GPU, NPU, TPU 是什麼?
- NPU 的概念理解,以及和 CPU/GPU 的区别解析。 - AlphaGeek - 博客园
- AI 实验室:CPU、GPU、TPU 和 NPU 的发展历程和区别
- GPU 进阶笔记(三):华为 NPU/GPU 演进(2024)
概述
现代的计算机, 大多遵守冯诺依曼体系结构,即
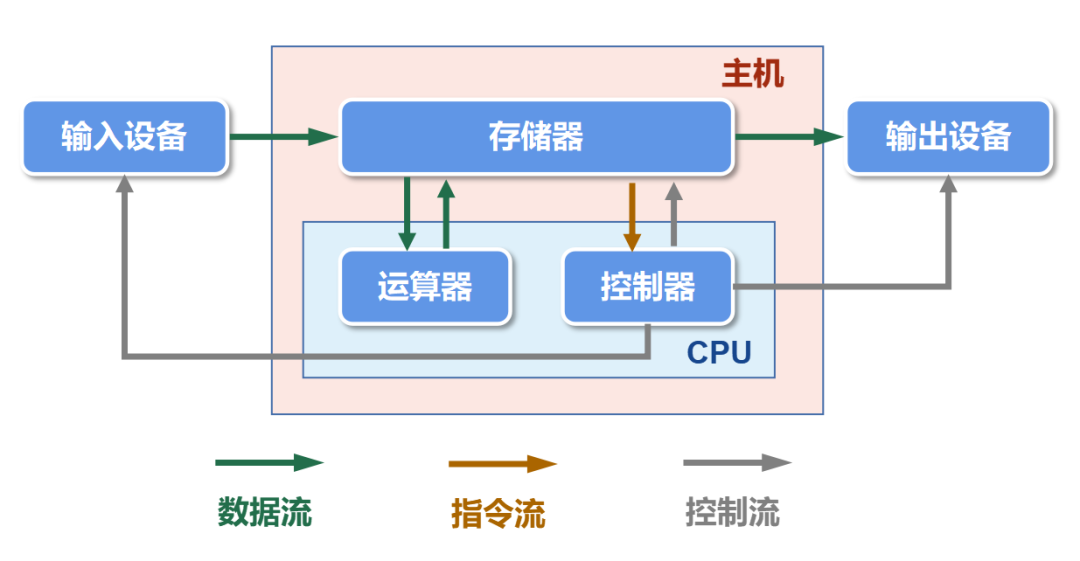
- CPU,即中央处理器,是一台计算机的运算核心和控制核心。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU 由运算器、控制器、寄存器、高速缓存及实现它们之间联系的数据、控制及状态的总线构成
- 存储器,分为外存和内存, 用于存储数据(使用二进制方式存储)
- 输入设备,用户给计算机发号施令的设备
- 输出设备,计算机个用户汇报结果的设备
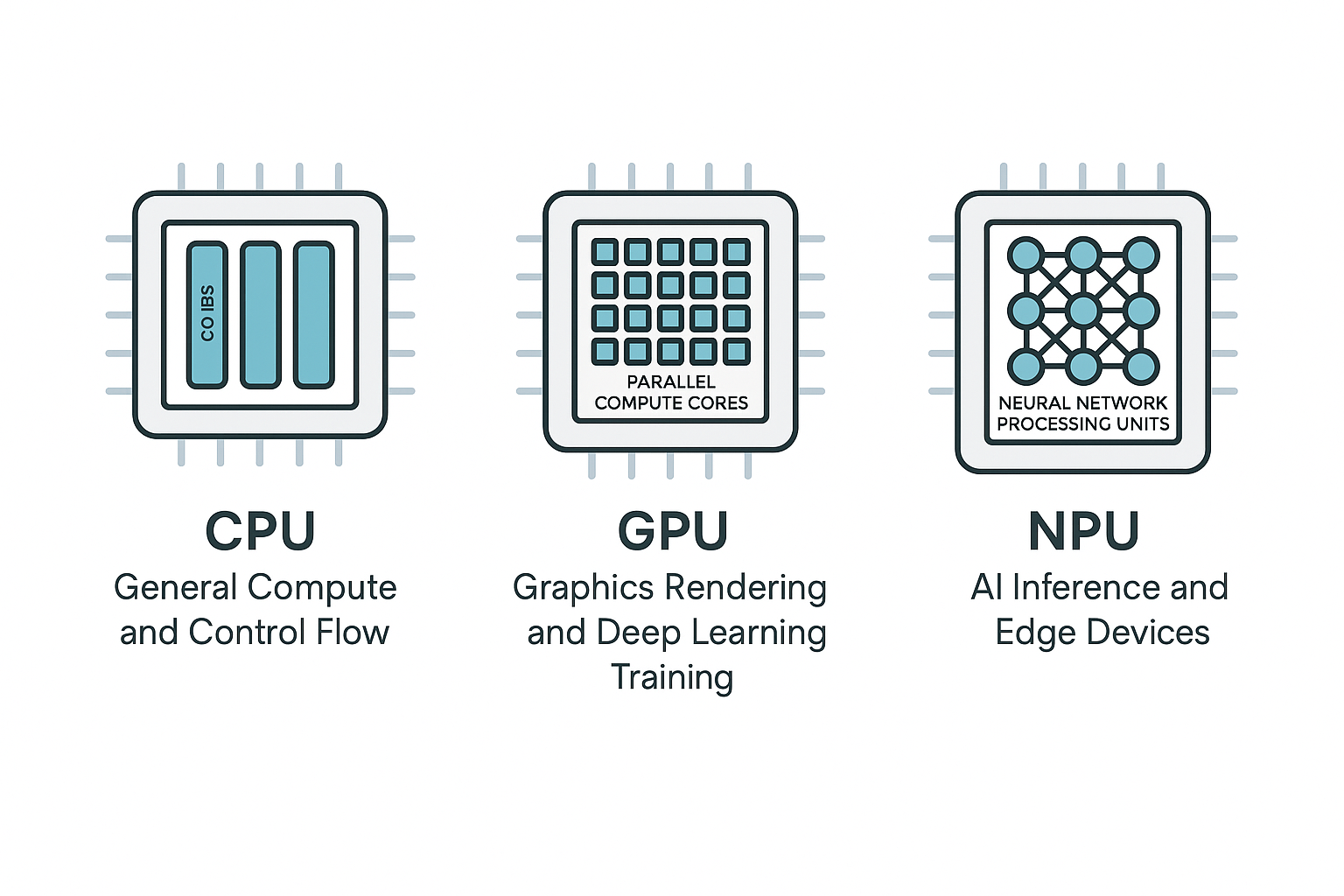
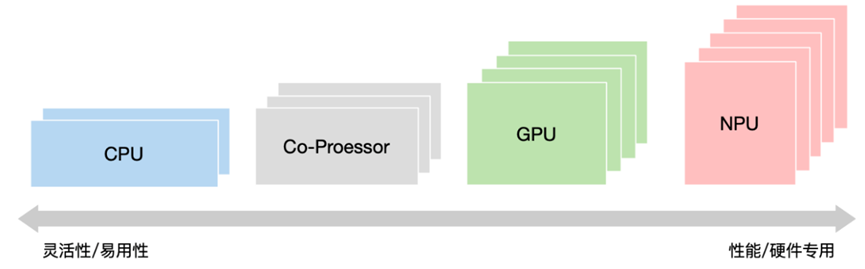
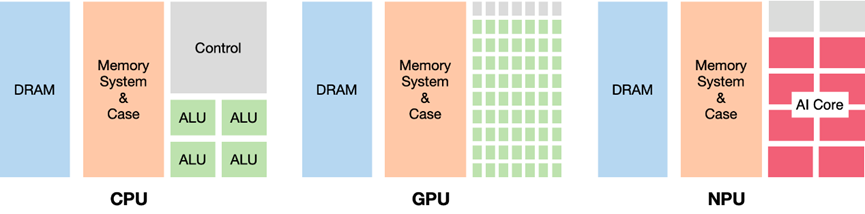
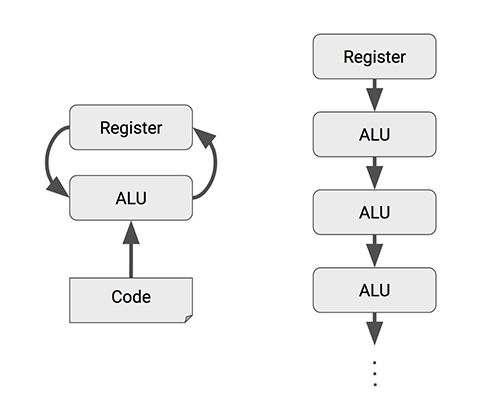
CPU/GPU/NPU 等等都是硬件芯片,简单来说,晶体管既可以用来实现逻辑控制单元, 也可以用来实现运算单元(算力)。 在芯片总面积一定的情况下,就看控制和算力怎么分。
- CPU:通用目的处理器,重逻辑控制;
- GPU:通用目的并行处理器(GPGPU),图形处理器;
- NPU:专用处理器,相比 CPU/GPU,擅长执行更具体的计算任务。
CPU**(Central Processing Unit,中央处理器)**
- CPU 处理器架构和工作原理浅析 - 流星泪 - 博客园
- CPU 结构
对于 CPU 的原理和结构上面两篇博客已经描述的非常清晰了,如有需要请跳转上面两个链接
- 定义:负责执行操作系统及各类应用程序指令,以通用性强、控制流能力强见长。
- 特点:核心数通常较少(如 4~16 核),内核频率高,善于处理复杂的分支和通用计算任务。

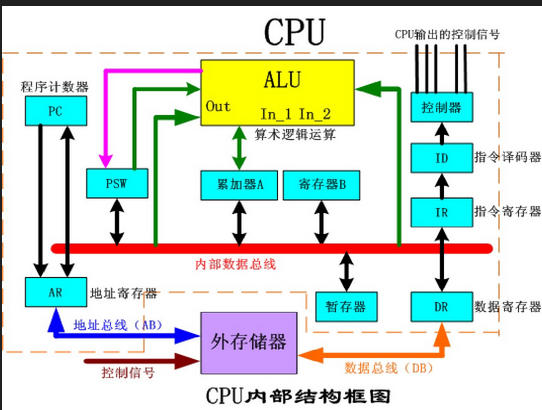
大部分芯片面积都用在了逻辑单元,因此逻辑控制能力强,算力弱(相对 GPU,NPU)。
应用场景
- 操作系统与通用计算:执行各种应用程序逻辑、文件 I/O、网络请求等。
- 轻量级 AI 推理:CPU 在推理任务中仍可胜任一些场景(如桌面级简单模型),但效率不及 GPU/NPU。
- 控制流程复杂的任务:诸如数据库事务处理、复杂分支逻辑的软件。
GPU**(Graphics Processing Unit,图形处理器)**
- GPU 的工作原理
- 一文理清 GPU 工作原理
- GPU 硬件原理架构(一)
显卡分为集显,核显和独显
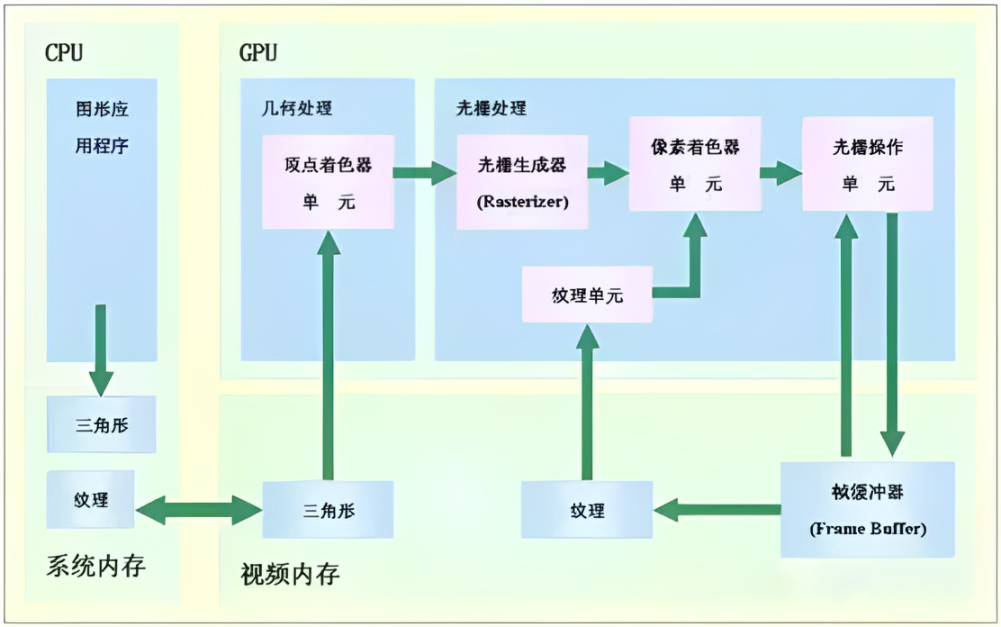

- 定义:最初用于图形渲染,后发展为通用并行计算加速器,具备海量并行计算单元。
- 特点:拥有数百到上千个计算核心(CUDA 核心、流处理器等),擅长大规模矩阵运算和并行数据处理。
大部分芯片面积用在了计算单元,因此并行计算能力强,但逻辑控制弱。 适合图像渲染、矩阵计算之类的并行计算场景。作为协处理器,需要在 CPU 的指挥下工作。
应用场景
- 图形渲染与游戏:2D/3D 渲染、物理特效计算。
- 深度学习训练:TensorFlow、PyTorch 等框架常将张量运算 offload 到 GPU,借助其大规模并行加速矩阵运算。
- 科学与工程计算:大规模数值仿真、视频转码、加密/解密算法(通过 CUDA/OpenCL)。
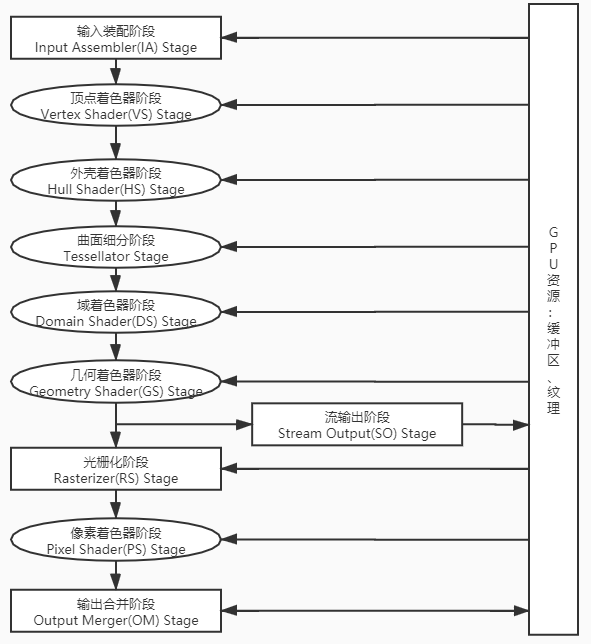
CUDA
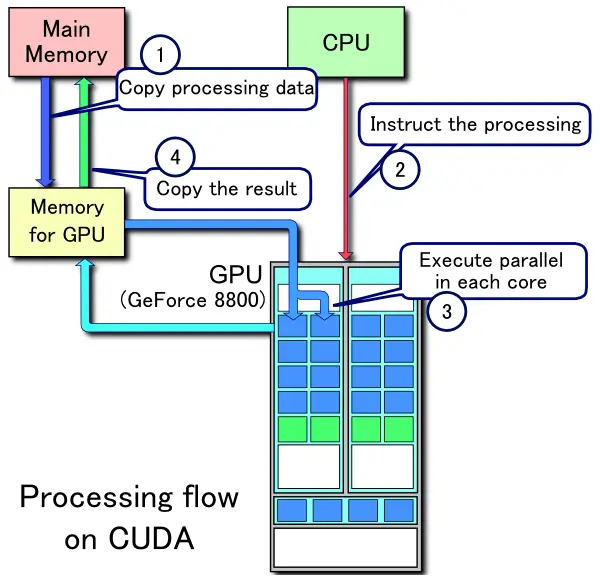
CUDA 是 NVIDIA 推出的并行计算平台与编程模型,允许开发者使用 C/C++(以及其他语言绑定)直接在 GPU 上编写并行代码,将大量浮点与整数运算分配给成百上千个并行执行的 CUDA 核心,从而在深度学习训练、科学计算、图像处理等领域显著提升计算性能。
在这个框架下,CUDA 就像一座“软件桥梁”:它对上层开发者提供了一套统一的 API,开发者只需在 Python、C++ 中调用相应接口,就能将运算任务提交给 GPU;对下层,CUDA 又会自动将这些高层调用翻译成不同 GPU 架构所需的低阶指令。
不论是图形渲染、AI 推理,还是流体模拟等数值运算,都要经过这层“中介”,由 CUDA 负责调度和分派运算到各个并行核心。这样一来,开发者无需关心底层硬件如何切分任务、如何分配资源,只需调用高层接口,就能一键触发 GPU 的海量并行加速,极大简化了并行编程的复杂度。
NPU (Neural Processing Unit,神经网络处理单元)
按照上文所述,CPU 和 GPU 都是较为通用的芯片,但是随着人们的计算需求越来越专业化,人们希望有芯片可以更加符合自己的专业需求,这时,便产生了 ASIC(专用集成电路)的概念。
ASIC 是指依产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。当然这概念不用记,简单来说就是定制化芯片。
因为 ASIC 很“专一”,只做一件事,所以就会比 CPU、GPU 等能做很多件事的芯片在某件事上做的更好,实现更高的处理速度和更低的能耗。但相应的,ASIC 的生产成本也非常高。
NPU 与超异构计算杂谈 - 吴建明 wujianming - 博客园
- 定义:专为深度学习推理(Inference)设计的专用加速器。
- 特点:在硬件层面高度优化了矩阵乘加运算、卷积操作,以及常见的神经网络算子,通常集成于 SoC(System-on-Chip)中,拥有极高的能效比。
也是协处理器。在 wikipedia 中没有专门的 NPU (Neural Processing Unit) 页面,而是归到 AI Processors 大类里面, 指的是一类特殊目的硬件加速器,更接近 ASIC,硬件实现神经网络运算, 比如张量运算、卷积、点积、激活函数、多维矩阵运算等等。
如果还不清楚什么是神经网络,可以看看 以图像识别为例,关于卷积神经网络(CNN)的直观解释(2016)。
在这些特殊任务上,比 CPU/GPU 这种通用处理器效率更高,功耗更小,响应更快(比如一个时钟周期内可以完成几十万个乘法运算), 因此适合用在手机、边缘计算、物联网等等场景。
应用场景
- 边缘端 AI 推理:智能手机(人脸识别、AI 拍照、语音助手)、智能摄像头(实时目标检测、行为分析)、物联网设备(智能音箱、家居安防)。
- 数据中心推理加速:在服务器侧为海量请求提供低延迟 AI 预测(如推荐系统、在线广告投放)。
- 专用智能芯片(如 AI 手机 SoC、智能驾驶芯片):为计算机视觉、自动驾驶、工业检测等应用提供高效算力。
TPU ( Tensor Processing Unit 张量处理单元)
- In-Datacenter Performance Analysis of a Tensor Processing Unit(论文)
- Google 深度揭秘 TPU:一文看懂运算原理,以及为何碾压 GPU
- TPU 原理技术与 xPU - 吴建明 wujianming - 博客园
TPU:这里特制 Google 的 Tensor Processing Unit,目的跟 NPU 差不多。对 TPU 和 GPU 的使用场景区别有一个非常形象的比喻:
如果外面下雨了,你其实并不需要知道每秒到底有多少滴雨, 而只要知道雨是大还是小。 与此类似,神经网络通常不需要 16/32bit 浮点数做精确计算,可能 8bit 整型预测的精度就足以满足需求了。
RISC,CISC 和 TPU 指令集
可编程性是 TPU 的另一个重要设计目标。TPU 不是设计用来运行某一种神经网络,而是要能加速许多不同类型的模型。
大多数当代 CPU 都采用了精简指令集(RISC)。但 Google 选择复杂指令集(CISC)作为 TPU 指令集的基础,这一指令集侧重于运行更复杂的任务。
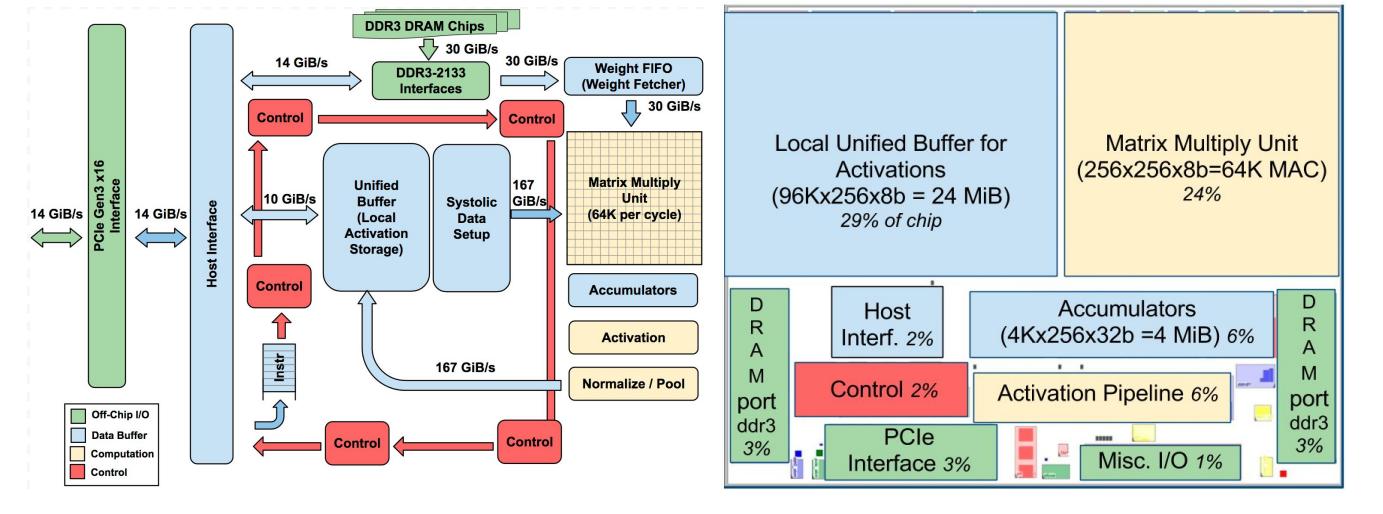
TPU 包括以下计算资源:
- 矩阵乘法单元(MUX):65,536 个 8 位乘法和加法单元,运行矩阵计算
- 统一缓冲(UB):作为寄存器工作的 24MB 容量 SRAM
- 激活单元(AU):硬件连接的激活函数
矩阵乘法单元的并行计算

Google TPU 中通过 MAC 模块进行矩阵乘法的加速,官方给出的加速矩阵乘法运算示意图如上 Google 为其设计了 MXU 作为矩阵处理器,可以在单个时钟周期内处理数十万次运算,也就是矩阵(Matrix)运算。
脉动阵列
MXU 有着与传统 CPU、GPU 截然不同的架构,称为脉动阵列(systolic array)。之所以叫“脉动”,是因为在这种结构中,数据一波一波地流过芯片,与心脏跳动供血的方式类似。
架构上的主要区别
以上对比可概括为:
- CPU:“万金油”式处理器,几乎什么都能做,但不擅长大规模并行计算;
- GPU:并行吞吐巨大的加速引擎,不仅做图形,还广泛用于深度学习训练;
- NPU:进一步聚焦于 AI 推理,将神经网络最常用的算子在硬件层面高度裁剪,能耗与性能比最优。
发展现状与应用前景
CPU 未来动向
- 专用指令集扩展:为了更好地兼顾 AI 推理性能,现代 CPU 已在向量指令(如 Intel AVX-512、ARM SVE)倾斜。
- 异构集成:如 AMD 的 APU、Intel 的集成显卡(iGPU),未来更多 SoC 将把 CPU、GPU、NPU 三者集成在一个芯片内,形成协同加速。
- 边缘侧轻量化 AI 推理:通过框架优化(如 ONNX Runtime)在 CPU 上做低精度推理(INT8/FP16),降低能耗。
GPU 的发展趋势
- Tensor 核心与混合精度:从 NVIDIA 的 Volta 架构开始,GPU 内已集成专用张量核心(Tensor Core),提高深度学习训练/推理效率。
- 异构并行:更多厂商(AMD、Intel、以及新兴的 AI 芯片公司)推出专用于 AI 的 GPU 级别加速器,支持 FP16、INT8、INT4 等低精度运算。
- 云端与数据中心规模化部署:GPU 在云计算平台(AWS、Azure、Google Cloud)作为主力推理与训练设备,将继续占据主流地位。
NPU 的前景展望
- 能效领先:随着 5G+IoT+AIoT 的普及,边缘端对低功耗高效能的 AI 芯片需求激增,NPU 市场规模将持续扩大。
- 集成化与定制化:手机 SoC(如华为麒麟、苹果 A 系列)以及汽车/工业级芯片中将越来越普遍地集成 NPU;同时,也会出现多种定制化 NPU(例如自动驾驶专用 NPU、医疗影像专用 NPU)。
- GPNPU(GPU + NPU 的融合):未来会有更多将 GPU 与 NPU 功能融合在一颗芯片上的设计,以兼顾通用并行计算与 AI 推理效率,推动 AI 端云协同。
- 生态与软件栈完善:从硬件到软件框架(如 TensorRT、OpenVINO、NNAdapter、CAMERA),都将围绕 NPU 优化,使开发者可以更方便地将模型部署到 NPU 上。
总结
CPU(中央处理器)适合通用计算,处理广泛任务但不擅长并行处理。GPU(图形处理器)专为并行任务设计,广泛用于图形渲染和 AI 模型训练。NPU(神经处理单元)优化 AI 和机器学习任务,特别在边缘计算中因能效高而受青睐。未来,NPU 可能更多集成到移动设备和 IoT 设备中,GPU 继续主导 AI 训练和高性能计算,CPU 维持通用计算核心。
CPU、GPU 和 NPU 是现代计算的核心组件,各有独特功能和应用。CPU(中央处理器)是通用计算的核心,设计上处理广泛任务,如运行操作系统和生产力软件,但不擅长并行处理。GPU(图形处理器)专为并行任务优化,拥有数千核心,适合图形渲染和 AI 模型训练,如深度学习加速。NPU(神经处理单元)则是为 AI 和机器学习设计,优化矩阵运算,能效高,特别适合边缘计算和实时 AI 任务,如智能手机的图像识别。
小结:
- 在通用计算领域,CPU 依旧是基础,但其 AI 加速能力会更多依赖于向量化指令和异构协同;
- GPU 将继续主导深度学习训练,并向 AI 推理、科学计算等方向拓展;
- NPU 则在边缘 AI 推理场景中大放异彩,并与 GPU 形成 “端 + 云” 协同加速架构。