ResNet 为什么能解决网络退化问题?通过图片分类案例进行验证
ResNet 为什么能解决网络退化问题?通过图片分类案例进行验证
- 引言
- 深度网络的退化问题
- 残差结构
- 残差结构为什么有效 ?
- 实验效果
- ResNet-34 实战
- 介绍
- 训练与预测
- 模型性能
- 小结
引言
对于卷积神经网络,深度是一个很重要的因素。深度卷积网络自然的整合了低中高不同层次的特征,特征的层次可以靠加深网络的层次来丰富。因此在构建卷积网络时,网络的深度越高,可抽取的特征层次就越丰富越抽象。所以一般我们会倾向于使用更深层次的网络结构,以便取得更高层次的特征。但是更深层的网络结构真的带来了更好的表现吗?
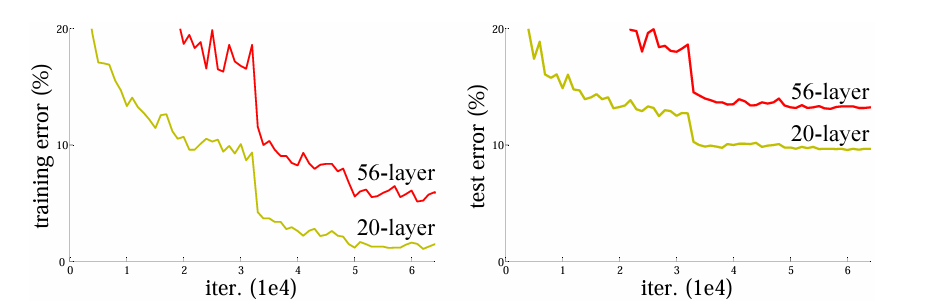
可以看到,拥有56层数的网络结构表现明显差于拥有20层数的网络结构,造成这一现象的原因大概有:
- 过拟合
- 梯度消失/爆炸
- 深度网络的退化
那么导致上述现象的原因到底是哪个呢?
- 过拟合?:过拟合会让网络在训练集上表现得很好,而从上图我们可以看出,无论是在训练集还是测试集中,拥有更深层次的网络表现均比浅层次的网络差,那显然就不是过拟合导致的。
- 梯度消失/爆炸?:梯度消失/爆炸是因为神经网络在反向传播的时候,反向连乘的梯度小于1(或大于1),导致连乘的次数多了之后(网络层数加深),传回浅层网络的梯度过小甚至为0(过大甚至无穷大),这就是梯度消失/爆炸的概念。
- 但我们知道,如今我们已经习惯加入BN层(Batch Normalize),他可以通过规整数据的分布基本解决梯度消失/爆炸的问题,所以这个问题也不是导致深层网络退化的原因。
深度网络的退化问题
我们选择加深网络的层数,是希望深层的网络的表现能比浅层好,或者是希望它的表现至少和浅层网络持平(相当于直接复制浅层网络的特征),可实际的结果却让我们大吃一惊(深度网络退化),接下来我们深究一下导致深度网络退化的原因。
由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的,这也造成了许多不可逆的信息损失。我们试想一下,一个特征的一些有用的信息损失了,那他的表现还能做到持平吗?答案显然是否定的 !
例如,在特征空间里,某些特征维度的值可能是负的,但这些负值可能包含着对于区分不同类别或者表示特定模式的重要信息。当这些负值经过 ReLU 变成 0 后,这部分信息就永远丢失了,导致后续网络层无法利用这些被丢弃的信息来进一步学习和处理数据。
我们用一个直观的例子来感受一下深层网络与浅层网络持平的表现:
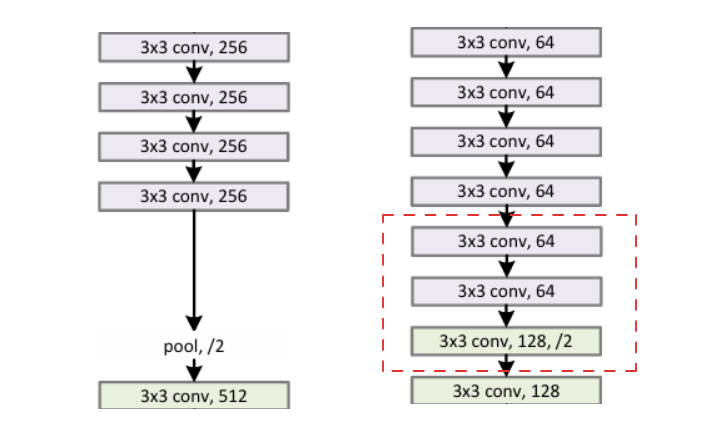
我们把右边的网络理解为左边浅层网络加深了三层(框起来的部分),假如我们希望右边的深层网络与左边的浅层网络持平,即是希望框起来的三层跟没加一样,也就是加的三层的输入等于输出。我们假设这三层的输入为
x
x
x,输出为
H
(
x
)
H(x)
H(x),那么深层网络与浅层网络表现持平的直观理解即是:
H
(
x
)
=
x
H(x) = x
H(x)=x,这种让输出等于输入的方式,就是论文中提到的恒等映射(identity mapping)。
所以ResNet的初衷,就是让网络拥有这种恒等映射的能力,能够在加深网络的时候,至少能保证深层网络的表现至少和浅层网络持平。
残差结构
通过对深度网络退化问题的认识我们已经明白,要让之不退化,根本解决办法就是如何做到恒等映射。事实上,已有的神经网络很难拟合潜在的恒等映射函数 H ( x ) = x H(x) = x H(x)=x。但如果把网络设计为 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x,即直接把恒等映射作为网络的一部分,就可以把问题转化为学习一个残差函数 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x.只要 F ( x ) = 0 F(x) = 0 F(x)=0,就构成了一个恒等映射。 而且,拟合残差至少比拟合恒等映射容易得多。我们看一下残差结构与正常结构对比图:
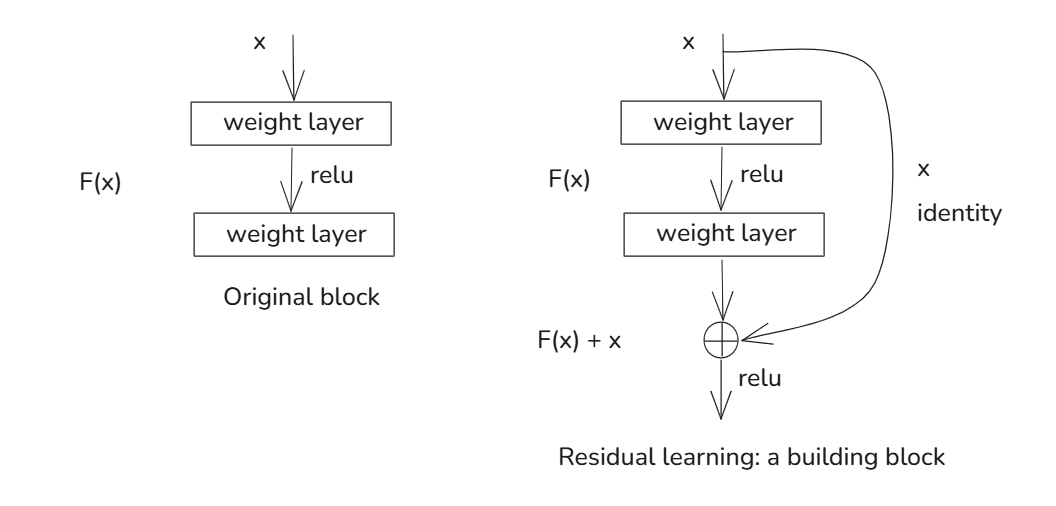
我们可以看到,残差结构比正常的结构多了右侧的曲线,这个曲线也叫作shortcut connection,通过跳接在激活函数前,将上一层(或几层)的输出与本层输出相加,将求和的结果输入到激活函数作为本层的输出。
我们从数学的角度来看残差结构,假设残差结构的输入为
x
x
x, 则输出
H
(
x
)
H(x)
H(x) 等于:
H
(
x
)
=
F
(
x
,
W
i
)
+
x
H(x) = F(x,W_{i}) + x
H(x)=F(x,Wi)+x
其中 F ( x , W i ) F(x,W_{i}) F(x,Wi)就是我们要学习的残差,我们把 x x x移动到等式的左侧,残差就等于 H ( x ) − x H(x) - x H(x)−x,以上图为例,残差就是中间有一个Relu激活的双层权重,即:
F = W 2 ∗ R e l u ( W 1 ∗ x ) F = W_{2} * Relu(W_{1} * x) F=W2∗Relu(W1∗x)
W 1 和 W 2 W_{1}和W_{2} W1和W2是指两个weight layer。
残差结构为什么有效 ?
关于残差结构为什么那么有效,大体上可以从四个方面进行解释:
-
加了残差结构后就是给了输入 x x x多一个选择,在神经网络学习到这层的参数是冗余的时候它可以选择直接走这条“跳接”曲线,跳过这个冗余层,而不需要再去拟合参数使得输出 H ( x ) H(x) H(x)等于 x x x。
-
因为学习残差的计算量比学习输出等于输入小。假设普通网络为 A A A,残差网络为 B B B,输入为2,输出为2(输入和输出一样是为了模拟冗余层需要恒等映射的情况),那么普通网络就是 A ( 2 ) = 2 A(2) = 2 A(2)=2,而残差网络就是 B ( 2 ) = F ( 2 ) + 2 = 2 B(2) = F(2) + 2 = 2 B(2)=F(2)+2=2,显然残差网络中的 F ( 2 ) = 0 F(2) = 0 F(2)=0。网络中权重一般会初始化成0附近的数,那么我们就很容易理解,为什么让 F ( 2 ) F(2) F(2)(经过权重矩阵)拟合0会比 A ( 2 ) = 2 A(2) = 2 A(2)=2容易了。
-
ReLU能够将负数激活为0,而正数输入等于输出。这相当于过滤了负数的线性变化,让 F ( x ) = 0 F(x) = 0 F(x)=0变得更加容易。
-
我们知道残差网络可以表示成 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x,这就说明了在求输出 H ( x ) H(x) H(x)对输入 x x x的导数(梯度),也就是在反向传播的时候, H ′ ( x ) = F ′ ( x ) + 1 H'(x) = F'(x) + 1 H′(x)=F′(x)+1,残差结构的这个常数1也能保证在求梯度的时候梯度不会消失。
下面给出网络的结构图,左到右分别是VGG,没有残差的PlainNet,有残差的ResNet :
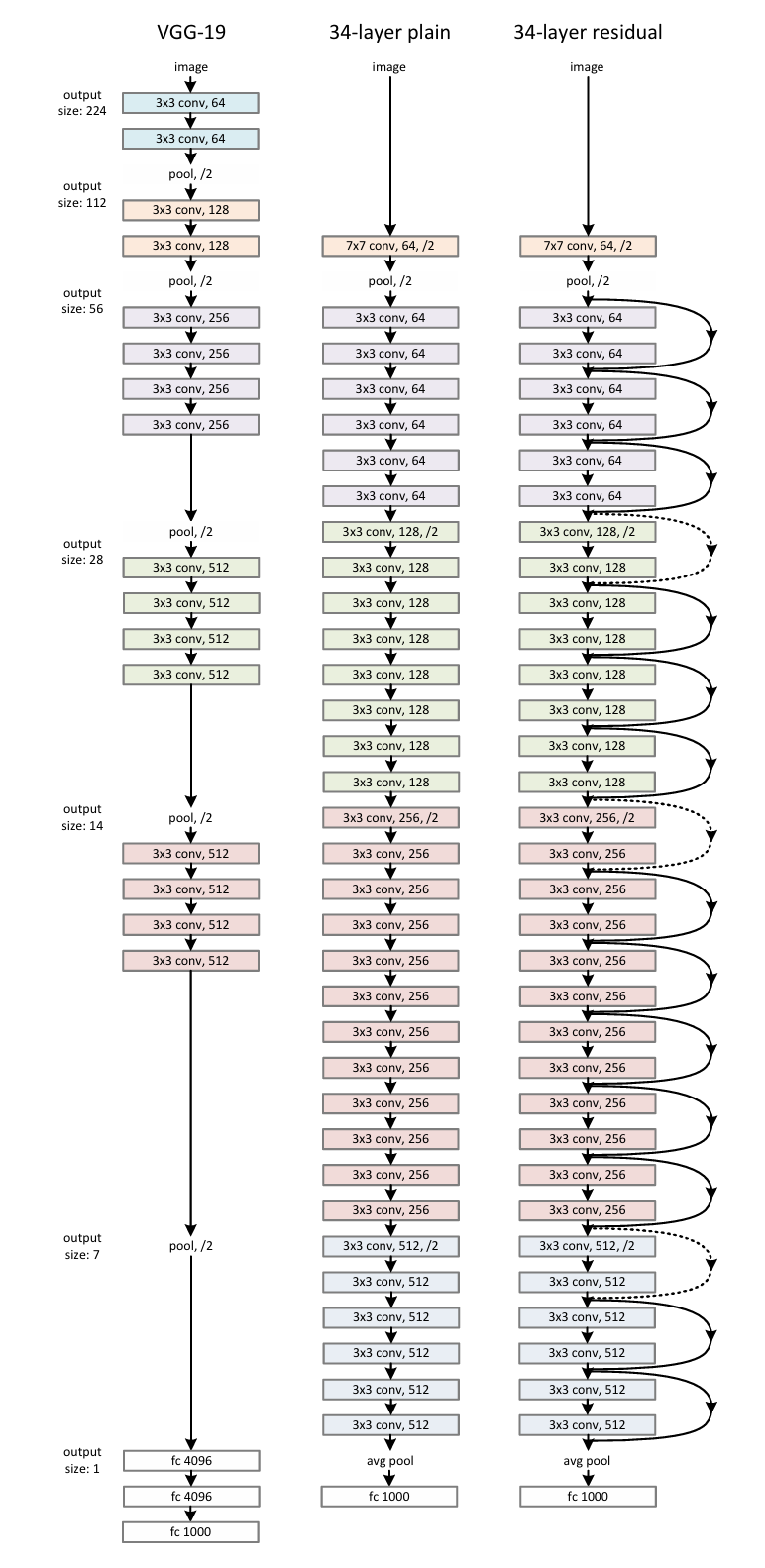
注意: 在ResNet中有的跳接线是实线,有的跳接线是虚线。虚线的代表这些模块前后的维度不一致,因为去掉残差结构的Plain网络还是和VGG一样,也就是每隔n层进行下采样但深度翻倍(VGG通过池化层下采样,ResNet通过卷积)。这里就有两个情况:
- 空间上不一致时,需要给输入的X做一个线性的映射
H ( x ) = F ( x , W i ) + x → H ( x ) = F ( x , W i ) + W s x H(x) = F(x, W_i) + x \rightarrow H(x) = F(x, W_i) + W_s x H(x)=F(x,Wi)+x→H(x)=F(x,Wi)+Wsx
- 深度上不一致时,有两种解决方法,一种是在跳接过程中加一个1×1的卷积层进行升维,另一种则是直接补零(先做下采样),实验后发现两种方法都可以。
针对比较深的神经网络,作者也考虑到计算量,会先用1×1的卷积将输入的256维降到64维,然后通过1×1恢复。这样做的目的是减少参数量和计算量。
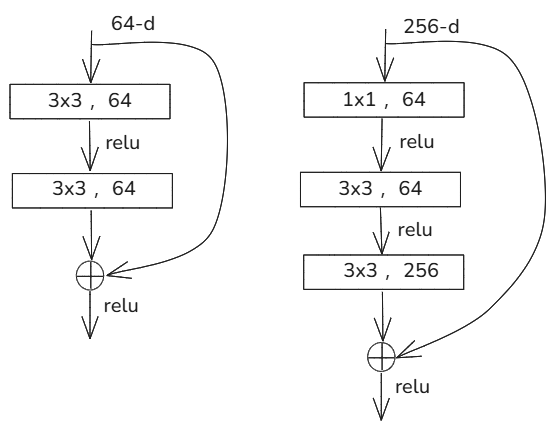
实验效果
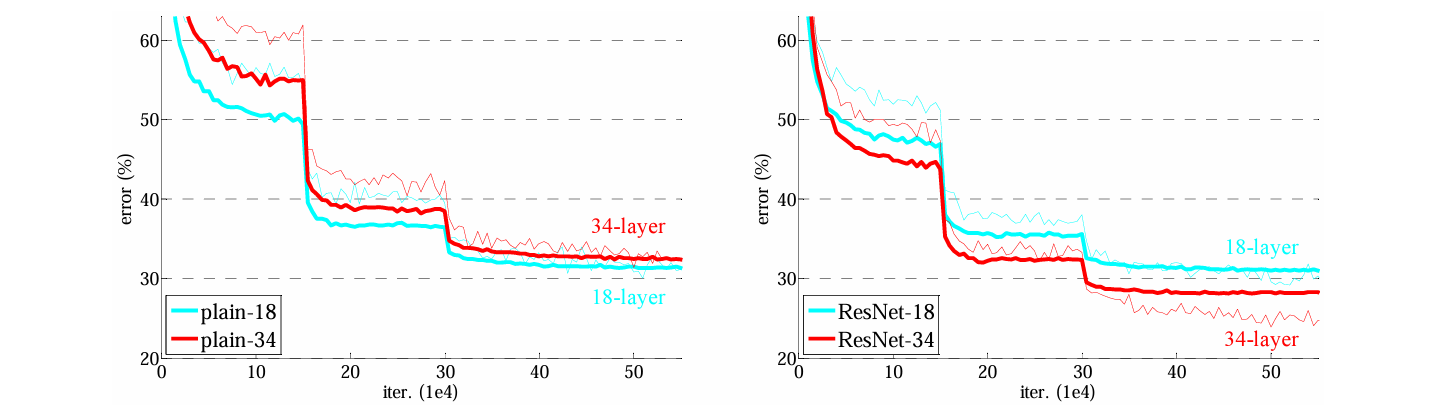
下图对比了18层的神经网络和34层的神经网络,发现残差结构确实解决了网络的退化问题:
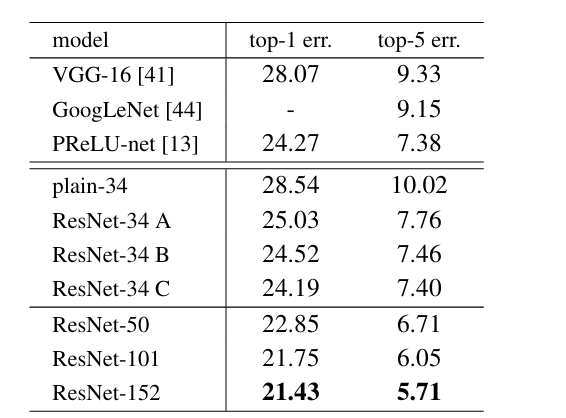
此外 ResNet 原论文中还对比了在 ImgaeNet 上的测试结果,发现 ResNet 确实效果非常好:
ResNet-34 实战
介绍
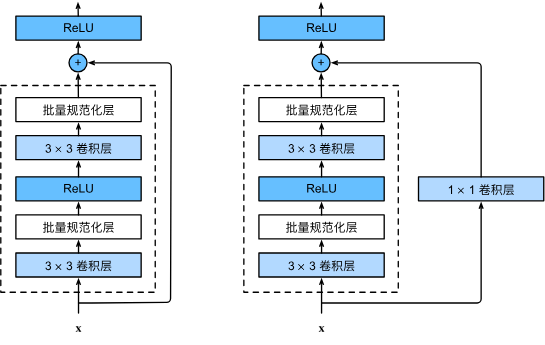
下图是ResNet的基础架构–残差块(residual block)。 在残差块中,输入可通过跨层数据线路更快地向前传播。
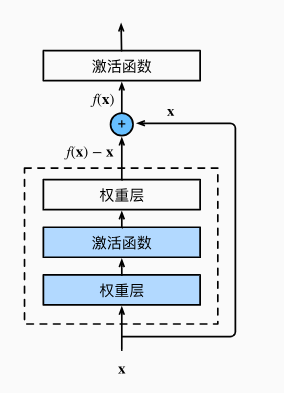
ResNet沿用了VGG完整的 3 × 3 3 \times 3 3×3卷积层设计。残差块里首先有2个有相同输出通道数的 3 × 3 3 \times 3 3×3卷积层。每个卷积层后接一个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的 1 × 1 1 \times 1 1×1卷积层来将输入变换成需要的形状后再做相加运算。
残差块的实现如下:
import torch.nn as nn
from torch.nn import functional as F
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
如下图所示,此代码生成两种类型的网络: 一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。 另一种是当use_1x1conv=True时,添加通过 1 x 1 卷积调整通道和分辨率。
# 输入和输出形状一致的情况
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
# 输出: torch.Size([4, 3, 6, 6])
# 增加输出通道数的同时,减半输出的高和宽
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape
# 输出: torch.Size([4, 6, 3, 3])
训练与预测
训练使用到的数据集和AlexNet保持一致,因此这里就不再给出数据集下载链接和数据集加载代码了。
图片分类实战 – 分别基于LeNet,AlexNet,VGG进行实现
1. 模型定义 1.模型定义 1.模型定义
import torch.nn as nn
import torch
from torch.utils import model_zoo
# 定义基础残差块,适用于较浅的 ResNet 如 ResNet34
class BasicBlock(nn.Module):
# 扩展系数,基础残差块输出通道数与输入通道数相同,扩展系数为 1
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
# 第一个 3x3 卷积层,用于特征提取,步长可调整,不使用偏置
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
# 第一个批量归一化层,加速模型收敛
self.bn1 = nn.BatchNorm2d(out_channel)
# ReLU 激活函数,引入非线性
self.relu = nn.ReLU()
# 第二个 3x3 卷积层,步长固定为 1,不使用偏置
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
# 第二个批量归一化层
self.bn2 = nn.BatchNorm2d(out_channel)
# 下采样模块,用于处理输入和输出特征图尺寸或通道数不匹配的情况
self.downsample = downsample
def forward(self, x):
# 保存输入作为捷径连接
identity = x
# 如果需要下采样,对输入进行下采样操作
if self.downsample is not None:
identity = self.downsample(x)
# 通过第一个卷积层
out = self.conv1(x)
# 进行批量归一化
out = self.bn1(out)
# 应用 ReLU 激活函数
out = self.relu(out)
# 通过第二个卷积层
out = self.conv2(out)
# 进行批量归一化
out = self.bn2(out)
# 将捷径连接与卷积输出相加
out += identity
# 再次应用 ReLU 激活函数
out = self.relu(out)
return out
# 定义完整的 ResNet 模型
class ResNet(nn.Module):
def __init__(self,
block, # 使用的残差块类型,如 BasicBlock 或 Bottleneck(适用于较深的残差块)
blocks_num, # 每个残差层包含的残差块数量
num_classes=1000, # 分类的类别数
include_top=True, # 是否包含全连接层
):
super(ResNet, self).__init__()
# 是否包含全连接层的标志
self.include_top = include_top
# 初始输入通道数
self.in_channel = 64
# 第一个 7x7 卷积层,用于初步特征提取,步长为 2
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
# 第一个批量归一化层
self.bn1 = nn.BatchNorm2d(self.in_channel)
# ReLU 激活函数
self.relu = nn.ReLU(inplace=True)
# 最大池化层,用于下采样
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 构建第一个残差层
self.layer1 = self._make_layer(block, 64, blocks_num[0])
# 构建第二个残差层,步长为 2
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
# 构建第三个残差层,步长为 2
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
# 构建第四个残差层,步长为 2
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
# 全局平均池化层,将特征图转换为固定大小
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 全连接层,用于分类
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 对卷积层的权重进行 Kaiming 初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
# 如果步长不为 1 或者输入输出通道数不匹配,需要进行下采样
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
# 添加第一个残差块,可能包含下采样
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride
))
# 更新输入通道数
self.in_channel = channel * block.expansion
# 添加剩余的残差块
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel
))
return nn.Sequential(*layers)
def forward(self, x):
# 通过第一个 7x7 卷积层
x = self.conv1(x)
# 进行批量归一化
x = self.bn1(x)
# 应用 ReLU 激活函数
x = self.relu(x)
# 通过最大池化层
x = self.maxpool(x)
# 通过四个残差层
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
# 通过全局平均池化层
x = self.avgpool(x)
# 将特征图展平为一维向量
x = torch.flatten(x, 1)
# 通过全连接层进行分类
x = self.fc(x)
return x
# 定义 ResNet34 的预训练模型链接
model_urls = {
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth'
}
def resnet34(model_name="resnet34", pretrained=False, num_classes=1000, include_top=True, **kwargs):
assert model_name in model_urls, "Warning: model number {} not in model_urls dict!".format(model_name)
# 创建 ResNet34 模型
model = ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top, **kwargs)
if pretrained:
# 加载预训练权重
state_dict = model_zoo.load_url(model_urls[model_name])
# 排除最后的全连接层的键名(假设是 'fc')
model_dict = model.state_dict()
# 过滤掉全连接层的权重(如果有的话)
pretrained_dict = {k: v for k, v in state_dict.items() if k in model_dict and k != 'fc.weight' and k != 'fc.bias'}
# 加载特征提取层的权重
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
# 冻结特征提取层的权重
for name, param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = False
return model
这里我们将会基于预训练好的ResNet-34进行微调,和先前基于预训练好的VGG-16进行微调一样,我们会冻结 ResNet - 34 的特征提取部分(卷积层),替换 ResNet - 34 的分类部分(全连接层)。
2. 训练 2.训练 2.训练
import torch
import torch.nn as nn
from torchvision import transforms
import torch.optim as optim
from tqdm import tqdm
from cnn.alexNet.utils import MyDataSet, read_split_data
from cnn.resnet.model import resnet34
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data("./flower_photos")
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=32,
shuffle=True,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=32,
shuffle=False,
collate_fn=val_dataset.collate_fn)
net = resnet34(model_name="resnet34",pretrained=True,num_classes=5,include_top=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './resnet34.pth'
# 保存准确率最高的那次模型的路径
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# 开启Dropout
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss:{:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
# 关闭Dropout
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / len(val_dataset)
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 如果当前准确率大于历史最优准确率,就将当前的准确率赋给最优准确率,并将参数进行保存
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
训练效果如下:
using cuda:0 device.
3670 images were found in the dataset.
2939 images for training.
731 images for validation.
train loss:100%[**************************************************->]1.018
100%|██████████| 92/92 [00:30<00:00, 3.03it/s]
100%|██████████| 23/23 [00:08<00:00, 2.72it/s]
[epoch 1] train_loss: 1.408 val_accuracy: 0.627
train loss:100%[**************************************************->]0.890
100%|██████████| 92/92 [00:30<00:00, 3.03it/s]
100%|██████████| 23/23 [00:07<00:00, 3.22it/s]
[epoch 2] train_loss: 0.987 val_accuracy: 0.746
train loss:100%[**************************************************->]0.875
100%|██████████| 92/92 [00:29<00:00, 3.10it/s]
100%|██████████| 23/23 [00:07<00:00, 3.21it/s]
[epoch 3] train_loss: 0.804 val_accuracy: 0.800
train loss:100%[**************************************************->]0.735
100%|██████████| 92/92 [00:30<00:00, 3.00it/s]
100%|██████████| 23/23 [00:06<00:00, 3.34it/s]
[epoch 4] train_loss: 0.693 val_accuracy: 0.834
train loss:100%[**************************************************->]0.640
100%|██████████| 92/92 [00:28<00:00, 3.23it/s]
100%|██████████| 23/23 [00:06<00:00, 3.31it/s]
[epoch 5] train_loss: 0.626 val_accuracy: 0.837
train loss:100%[**************************************************->]0.527
100%|██████████| 92/92 [00:31<00:00, 2.95it/s]
100%|██████████| 23/23 [00:07<00:00, 3.04it/s]
[epoch 6] train_loss: 0.580 val_accuracy: 0.845
train loss:100%[**************************************************->]0.432
100%|██████████| 92/92 [00:29<00:00, 3.08it/s]
100%|██████████| 23/23 [00:07<00:00, 3.26it/s]
[epoch 7] train_loss: 0.539 val_accuracy: 0.847
train loss:100%[**************************************************->]0.456
100%|██████████| 92/92 [00:28<00:00, 3.26it/s]
100%|██████████| 23/23 [00:06<00:00, 3.36it/s]
[epoch 8] train_loss: 0.518 val_accuracy: 0.852
train loss:100%[**************************************************->]0.574
100%|██████████| 92/92 [00:30<00:00, 3.01it/s]
100%|██████████| 23/23 [00:07<00:00, 3.22it/s]
[epoch 9] train_loss: 0.498 val_accuracy: 0.854
train loss:100%[**************************************************->]0.467
100%|██████████| 92/92 [00:30<00:00, 3.06it/s]
100%|██████████| 23/23 [00:07<00:00, 3.23it/s]
[epoch 10] train_loss: 0.480 val_accuracy: 0.859
Finished Training
3. 预测 3.预测 3.预测
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import resnet34
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
img = Image.open("img.png")
plt.imshow(img)
img = data_transform(img)
# expand batch dimension , 处理后变成[batch, C, H, W]
img = torch.unsqueeze(img, dim=0)
# read class_indict -- 读取索引对应的类别名称
json_file = open('./class_indices.json', "r")
class_indict = json.load(json_file)
model = resnet34(model_name="resnet34",pretrained=False,num_classes=5,include_top=True).to(device)
model.load_state_dict(torch.load("./resnet34.pth"))
# 进入eval模式,即关闭dropout方法
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
# 打印类别名称以及预测正确的概率
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
预测图片:

预测效果如下:

模型性能
模型性能统计代码如下:
from ptflops import get_model_complexity_info
model = resnet34(model_name="resnet34",pretrained=False,num_classes=5,include_top=True)
flops, params = get_model_complexity_info(model, (3, 224, 224), as_strings=True, print_per_layer_stat=True)
print('flops: ', flops, 'params: ', params)
各层统计信息:
| 层名称 | 参数量(Params) | 参数量占比 | 计算量(MACs) | 计算量占比 | 层类型及参数 |
|---|---|---|---|---|---|
| conv1 | 9.41 k | 0.044% | 118.01 MMac | 3.207% | Conv2d (3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) |
| bn1 | 128 | 0.001% | 1.61 MMac | 0.044% | BatchNorm2d (64, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| relu | 0 | 0.000% | 802.82 KMac | 0.022% | ReLU (inplace = True) |
| maxpool | 0 | 0.000% | 802.82 KMac | 0.022% | MaxPool2d (kernel_size = 3, stride = 2, padding = 1, dilation = 1, ceil_mode = False) |
| layer1 - BasicBlock(合并) | 221.95 k | 1.043% | 697.25 MMac | 18.949% | BasicBlock(多个,合并统计) |
| layer2 - BasicBlock(合并) | 1.12 M | 5.245% | 876.07 MMac | 23.810% | BasicBlock(多个,合并统计) |
| layer3 - BasicBlock(合并) | 6.82 M | 32.049% | 1.34 GMac | 36.358% | BasicBlock(多个,合并统计) |
| layer4 - BasicBlock(合并) | 13.11 M | 61.607% | 642.75 MMac | 17.468% | BasicBlock(多个,合并统计) |
| avgpool | 0 | 0.000% | 25.09 KMac | 0.001% | AdaptiveAvgPool2d (output_size=(1, 1)) |
| fc | 2.56 k | 0.012% | 2.56 KMac | 0.000% | Linear (in_features = 512, out_features = 5, bias = True) |
计算量排名最高的残差块(layer3 - BasicBlock)各层信息
| 层名称 | 参数量(Params) | 参数量占比 | 计算量(MACs) | 计算量占比 | 层类型及参数 |
|---|---|---|---|---|---|
| layer3 - 0 - conv1 | 294.91 k | 1.385% | 57.8 MMac | 1.571% | Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) |
| layer3 - 0 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 0 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 0 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 0 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 0 - downsample - 0 | 32.77 k | 0.154% | 6.42 MMac | 0.175% | Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) |
| layer3 - 0 - downsample - 1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 1 - conv1 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 1 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 1 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 1 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 1 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 2 - conv1 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 2 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 2 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 2 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 2 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 3 - conv1 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 3 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 3 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 3 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 3 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 4 - conv1 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 4 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 4 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 4 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 4 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 5 - conv1 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 5 - bn1 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
| layer3 - 5 - relu | 0 | 0.000% | 100.35 KMac | 0.003% | ReLU() |
| layer3 - 5 - conv2 | 589.82 k | 2.771% | 115.61 MMac | 3.142% | Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer3 - 5 - bn2 | 512 | 0.002% | 100.35 KMac | 0.003% | BatchNorm2d(256, eps = 1e - 05, momentum = 0.1, affine = True, track_running_stats = True) |
参数量排名最高的残差块(layer4 - BasicBlock)各层信息
| 层名称 | 参数量(Params) | 参数量占比 | 计算量(MACs) | 计算量占比 | 层类型及参数 |
|---|---|---|---|---|---|
| layer4 - 0 - conv1 | 1.18 M | 5.542% | 57.8 MMac | 1.571% | Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) |
| layer4 - 0 - bn1 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 0 - relu | 0 | 0.000% | 50.18 KMac | 0.001% | ReLU() |
| layer4 - 0 - conv2 | 2.36 M | 11.083% | 115.61 MMac | 3.142% | Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer4 - 0 - bn2 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 0 - downsample - 0 | 131.07 k | 0.616% | 6.42 MMac | 0.175% | Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) |
| layer4 - 0 - downsample - 1 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 1 - conv1 | 2.36 M | 11.083% | 115.61 MMac | 3.142% | Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer4 - 1 - bn1 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 1 - relu | 0 | 0.000% | 50.18 KMac | 0.001% | ReLU() |
| layer4 - 1 - conv2 | 2.36 M | 11.083% | 115.61 MMac | 3.142% | Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer4 - 1 - bn2 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 2 - conv1 | 2.36 M | 11.083% | 115.61 MMac | 3.142% | Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer4 - 2 - bn1 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
| layer4 - 2 - relu | 0 | 0.000% | 50.18 KMac | 0.001% | ReLU() |
| layer4 - 2 - conv2 | 2.36 M | 11.083% | 115.61 MMac | 3.142% | Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) |
| layer4 - 2 - bn2 | 1.02 k | 0.005% | 50.18 KMac | 0.001% | BatchNorm2d(512, eps=1e - 05, momentum=0.1, affine=True, track_running_stats=True) |
全局统计信息:
| 指标 | 数值 |
|---|---|
| 总参数量(Params) | 21.29 M |
| 总计算量(MACs) | 3.68 GMac |
小结
- 学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
- 利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。