【Block总结】EBlock,快速傅里叶变换(FFT)增强输入图像的幅度|即插即用|CVPR2025
论文信息
标题: DarkIR: Robust Low-Light Image Restoration
作者: Daniel Feijoo, Juan C. Benito, Alvaro Garcia, Marcos Conde
论文链接:https://arxiv.org/pdf/2412.13443
GitHub链接:https://github.com/cidautai/DarkIR

创新点
DarkIR提出了一种新的卷积神经网络(CNN)框架,旨在同时处理低光图像增强和去模糊任务。与现有方法通常分开处理这两项任务不同,DarkIR通过多任务学习的方式,利用图像退化之间的相关性来提高恢复效果。该模型在参数和计算量上均优于之前的方法,且在多个标准数据集(如LOLBlur、LOLv2和Real-LOLBlur)上取得了新的最先进结果。
方法
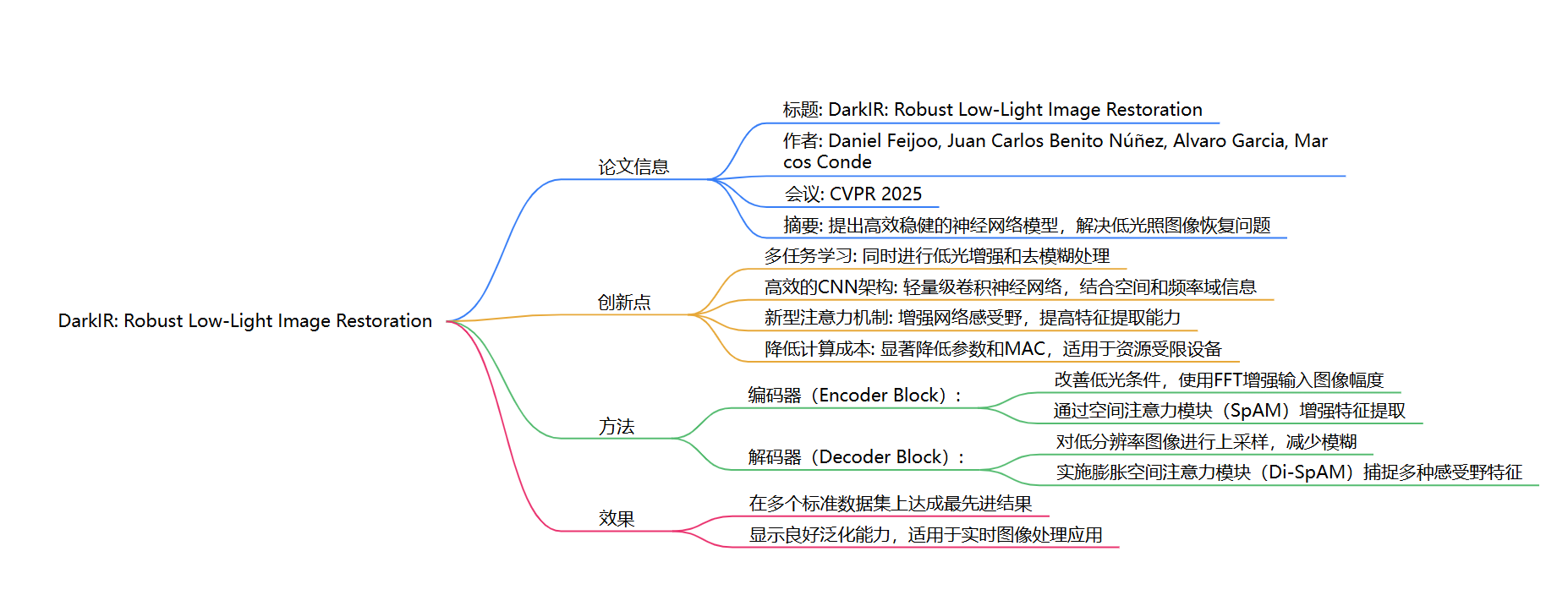
DarkIR的架构采用了编码器-解码器设计,主要包括以下几个部分:
- 编码器块(EBlock): 主要在频域中改善低光条件,使用快速傅里叶变换(FFT)增强输入图像的幅度。 通过空间注意模块(SpAM)增强特征提取,确保网络能够关注重要的空间信息。
- 解码器块(DBlock): 负责上采样编码器的低分辨率输出并减少模糊。 实现了膨胀空间注意模块(Di-SpAM),通过不同膨胀率的深度卷积捕捉多种感受野的特征。
该方法结合了频域技术和创新的注意力机制,优化了低光图像的恢复过程。
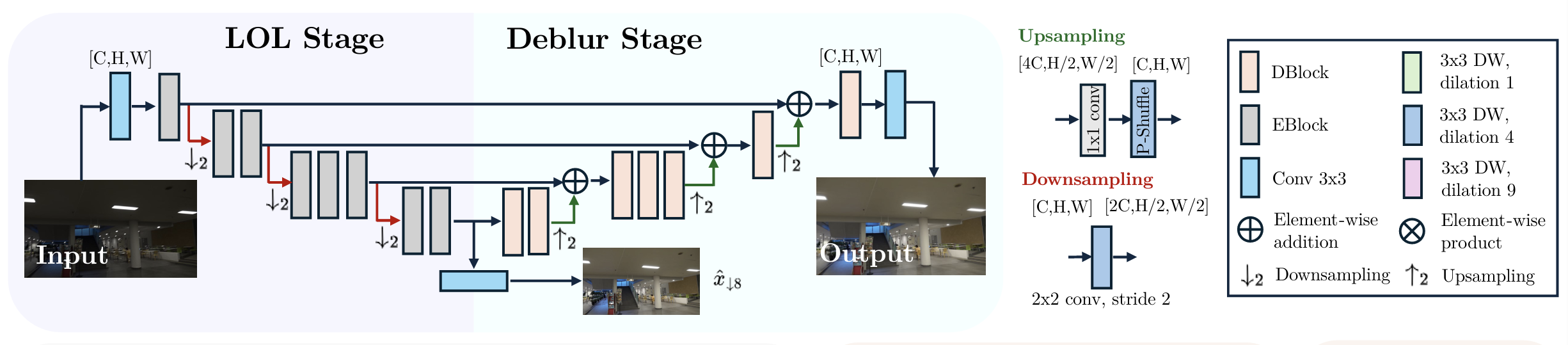
EBlock模块详解
EBlock(编码器块) 是DarkIR模型中的关键组成部分,专注于在低光照条件下进行图像增强。其设计旨在利用频域信息来改善图像质量,具体实现如下:
1. 结构组成
EBlock主要由以下几个部分构成:
- 空间注意力模块(SpAM): 该模块用于提取重要的空间特征,帮助网络聚焦于图像中的关键区域。SpAM的设计灵感来源于NAFBlock,采用了简化的通道注意力机制,以便在频域增强过程中提取有意义的空间信息。
- 频域前馈网络(FreMLP): 该模块在频域内操作,通过快速傅里叶变换(FFT)增强输入图像的幅度信息。增强后的幅度信息再通过逆快速傅里叶变换(IFFT)转换回空间域。
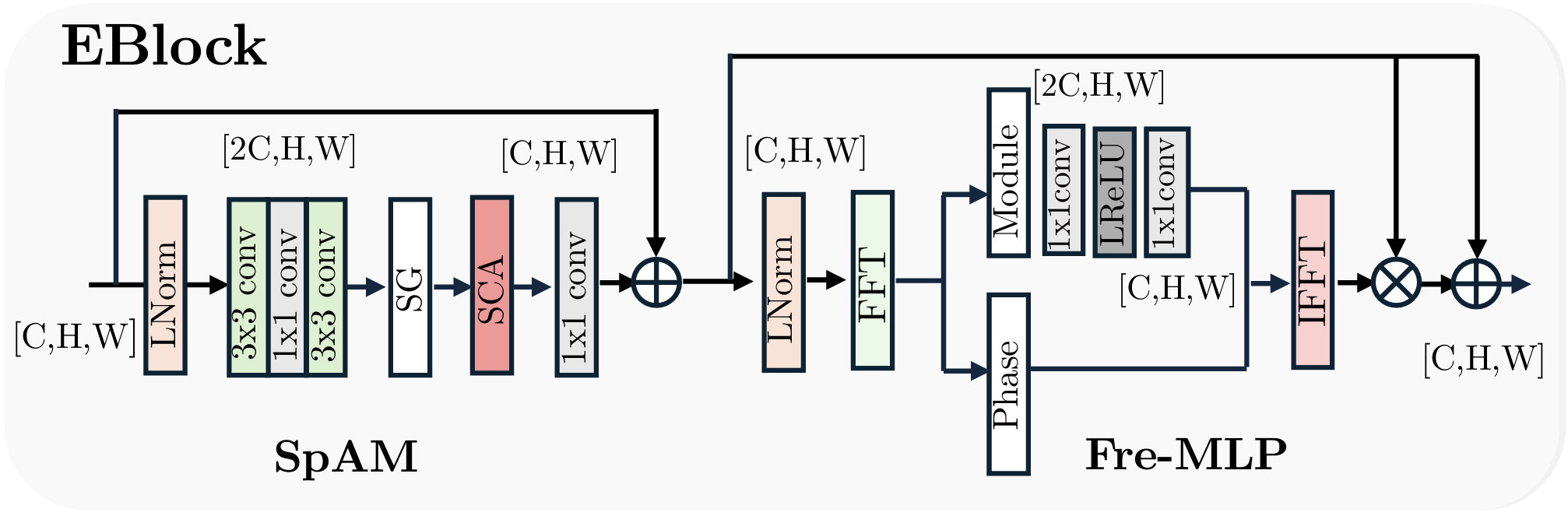
2. 工作原理
EBlock的工作流程如下:
-
输入处理: 输入图像首先经过Layer Normalization进行标准化,以提高训练的稳定性。
-
空间特征提取:通过SpAM模块提取空间特征,确保网络能够关注到图像中的重要区域。结合多个分支的输出,利用门控机制(SimpleGate)进行特征融合。
-
频域增强:使用FFT对输入图像进行频域转换,主要操作幅度信息。通过FreMLP模块进一步处理频域数据,以增强低光条件下的图像特征。
-
输出生成: 最终的输出通过1x1卷积层恢复到原始通道数,并与输入进行残差连接,以保持信息的完整性。
效果
DarkIR在真实世界的夜间和暗光图像中表现出色,能够有效地减少噪声和模糊,同时保持高保真度。其在多个数据集上的表现超越了现有的最先进技术,展示了其在计算摄影、智能手机等资源受限设备上的应用潜力。

完整代码
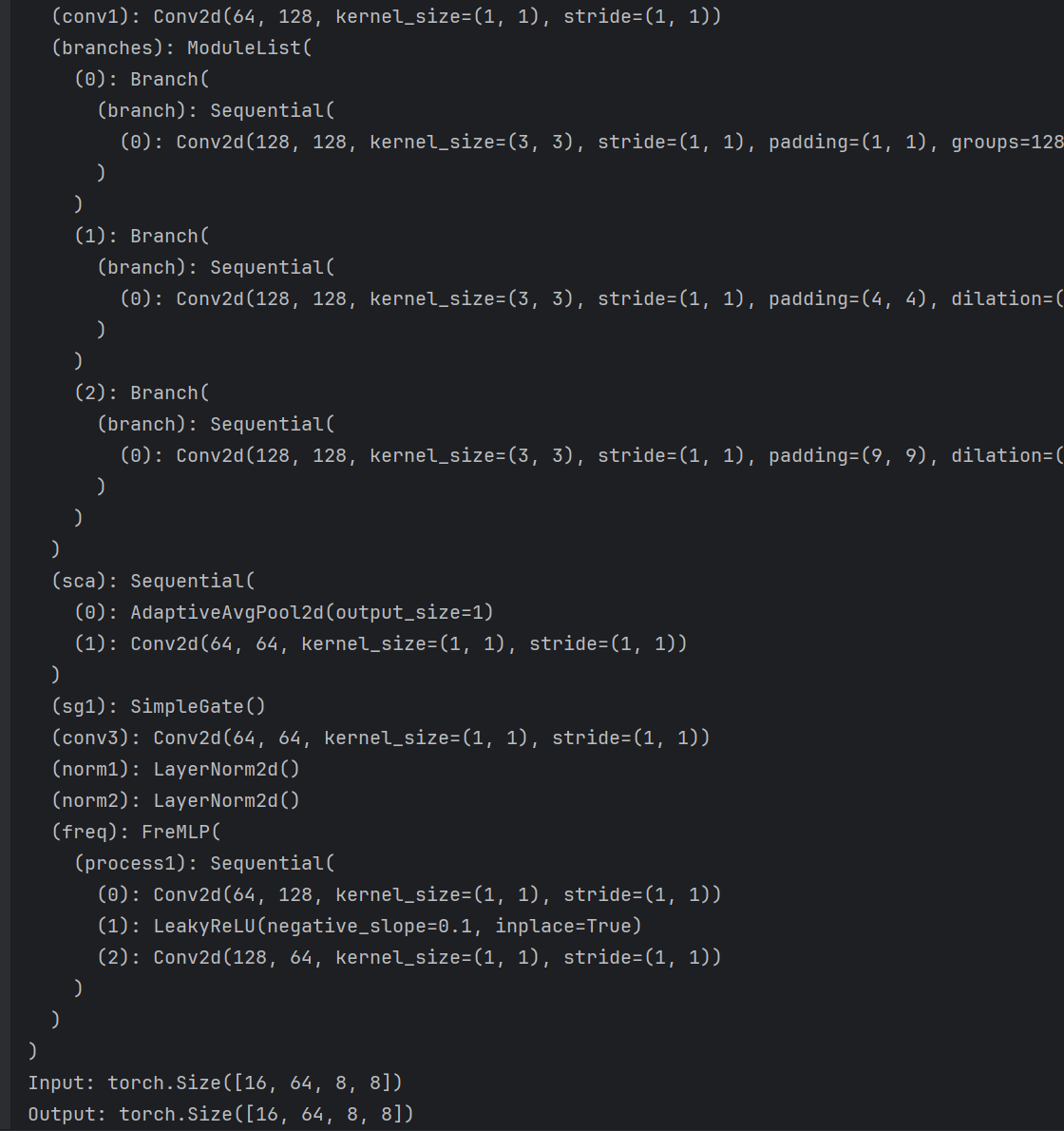
import torch
import torch.nn as nnclass LayerNormFunction(torch.autograd.Function):@staticmethoddef forward(ctx, x, weight, bias, eps):ctx.eps = epsN, C, H, W = x.size()mu = x.mean(1, keepdim=True)var = (x - mu).pow(2).mean(1, keepdim=True)y = (x - mu) / (var + eps).sqrt()ctx.save_for_backward(y, var, weight)y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)return y@staticmethoddef backward(ctx, grad_output):eps = ctx.epsN, C, H, W = grad_output.size()y, var, weight = ctx.saved_variablesg = grad_output * weight.view(1, C, 1, 1)mean_g = g.mean(dim=1, keepdim=True)mean_gy = (g * y).mean(dim=1, keepdim=True)gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(dim=0), Noneclass LayerNorm2d(nn.Module):def __init__(self, channels, eps=1e-6):super(LayerNorm2d, self).__init__()self.register_parameter('weight', nn.Parameter(torch.ones(channels)))self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))self.eps = epsdef forward(self, x):return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)class SimpleGate(nn.Module):def forward(self, x):x1, x2 = x.chunk(2, dim=1)return x1 * x2class Adapter(nn.Module):def __init__(self, c, ffn_channel=None):super().__init__()if ffn_channel:ffn_channel = 2else:ffn_channel = cself.conv1 = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=1, padding=0, stride=1, groups=1,bias=True)self.conv2 = nn.Conv2d(in_channels=ffn_channel, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1,bias=True)self.depthwise = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=3, padding=1, stride=1,groups=c, bias=True, dilation=1)def forward(self, input):x = self.conv1(input) + self.depthwise(input)x = self.conv2(x)return xclass FreMLP(nn.Module):def __init__(self, nc, expand=2):super(FreMLP, self).__init__()self.process1 = nn.Sequential(nn.Conv2d(nc, expand * nc, 1, 1, 0),nn.LeakyReLU(0.1, inplace=True),nn.Conv2d(expand * nc, nc, 1, 1, 0))def forward(self, x):_, _, H, W = x.shapex_freq = torch.fft.rfft2(x, norm='backward')mag = torch.abs(x_freq)pha = torch.angle(x_freq)mag = self.process1(mag)real = mag * torch.cos(pha)imag = mag * torch.sin(pha)x_out = torch.complex(real, imag)x_out = torch.fft.irfft2(x_out, s=(H, W), norm='backward')return x_outclass Branch(nn.Module):'''Branch that lasts lonly the dilated convolutions'''def __init__(self, c, DW_Expand, dilation=1):super().__init__()self.dw_channel = DW_Expand * cself.branch = nn.Sequential(nn.Conv2d(in_channels=self.dw_channel, out_channels=self.dw_channel, kernel_size=3, padding=dilation,stride=1, groups=self.dw_channel,bias=True, dilation=dilation) # the dconv)def forward(self, input):return self.branch(input)class DBlock(nn.Module):'''Change this block using Branch'''def __init__(self, c, DW_Expand=2, FFN_Expand=2, dilations=[1], extra_depth_wise=False):super().__init__()# we define the 2 branchesself.dw_channel = DW_Expand * cself.conv1 = nn.Conv2d(in_channels=c, out_channels=self.dw_channel, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation=1)self.extra_conv = nn.Conv2d(self.dw_channel, self.dw_channel, kernel_size=3, padding=1, stride=1, groups=c,bias=True, dilation=1) if extra_depth_wise else nn.Identity() # optional extra dwself.branches = nn.ModuleList()for dilation in dilations:self.branches.append(Branch(self.dw_channel, DW_Expand=1, dilation=dilation))assert len(dilations) == len(self.branches)self.dw_channel = DW_Expand * cself.sca = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=self.dw_channel // 2, kernel_size=1, padding=0,stride=1,groups=1, bias=True, dilation=1),)self.sg1 = SimpleGate()self.sg2 = SimpleGate()self.conv3 = nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation=1)ffn_channel = FFN_Expand * cself.conv4 = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=1, padding=0, stride=1, groups=1,bias=True)self.conv5 = nn.Conv2d(in_channels=ffn_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1,groups=1, bias=True)self.norm1 = LayerNorm2d(c)self.norm2 = LayerNorm2d(c)self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)def forward(self, inp):y = inpx = self.norm1(inp)# x = self.conv1(self.extra_conv(x))x = self.extra_conv(self.conv1(x))z = 0for branch in self.branches:z += branch(x)z = self.sg1(z)x = self.sca(z) * zx = self.conv3(x)y = inp + self.beta * x# second stepx = self.conv4(self.norm2(y)) # size [B, 2*C, H, W]x = self.sg2(x) # size [B, C, H, W]x = self.conv5(x) # size [B, C, H, W]x = y + x * self.gammareturn xclass EBlock(nn.Module):'''Change this block using Branch'''def __init__(self, c, DW_Expand=2, dilations = [1], extra_depth_wise=False):super().__init__()# we define the 2 branchesself.dw_channel = DW_Expand * cself.extra_conv = nn.Conv2d(c, c, kernel_size=3, padding=1, stride=1, groups=c, bias=True,dilation=1) if extra_depth_wise else nn.Identity() # optional extra dwself.conv1 = nn.Conv2d(in_channels=c, out_channels=self.dw_channel, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation=1)self.branches = nn.ModuleList()for dilation in dilations:self.branches.append(Branch(c, DW_Expand, dilation=dilation))assert len(dilations) == len(self.branches)self.dw_channel = DW_Expand * cself.sca = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=self.dw_channel // 2, kernel_size=1, padding=0,stride=1,groups=1, bias=True, dilation=1),)self.sg1 = SimpleGate()self.conv3 = nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation=1)# second stepself.norm1 = LayerNorm2d(c)self.norm2 = LayerNorm2d(c)self.freq = FreMLP(nc=c, expand=2)self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)# self.adapter = Adapter(c, ffn_channel=None)# self.use_adapters = False# def set_use_adapters(self, use_adapters):# self.use_adapters = use_adaptersdef forward(self, inp):y = inpx = self.norm1(inp)x = self.conv1(self.extra_conv(x))z = 0for branch in self.branches:z += branch(x)z = self.sg1(z)x = self.sca(z) * zx = self.conv3(x)y = inp + self.beta * x# second stepx_step2 = self.norm2(y) # size [B, 2*C, H, W]x_freq = self.freq(x_step2) # size [B, C, H, W]x = y * x_freqx = y + x * self.gamma# if self.use_adapters:# return self.adapter(x)# else:return xif __name__ == "__main__":# 定义输入张量大小(Batch、Channel、Height、Wight)B, C, H, W = 16, 64, 8, 8input_tensor = torch.randn(B,C,H,W) # 随机生成输入张量dim=C# 创建 DynamicTanh 实例block = EBlock(dim,dilations=[1, 4, 9])device = torch.device("cuda" if torch.cuda.is_available() else "cpu")block = block.to(device)print(block)input_tensor = input_tensor.to(device)# 执行前向传播output = block(input_tensor)# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")