深入理解 Linux 进程控制
文章目录
- 1. 进程创建
- 🍑 fork 函数初识
- 🍑 fork 函数返回值
- 🍎 如何理解 fork 函数有两个返回值问题?
- 🍎 为什么给父进程返回子进程 PID,给子进程返回 0?
- 🍎 如何理解同一个 id 值,怎么可能会保存两个不同的值?
- 🍑 写时拷贝
- 🍑 fork 常规用法
- 🍑 fork 调用失败的原因
- 2. 进程终止
- 🍑 进程退出场景
- 🍑 进程常见退出方法
- 🍑 return 退出
- 🍑 _exit 函数
- 🍑 exit 函数
- 3. 进程等待
- 🍑 进程等待必要性
- 🍑 进程等待的方法
- 🍎 wait 方法
- 🍎 waitpid 方法
- 🍎 获取子进程status
- 🍎 总结
- 🍑 阻塞等待 与 非阻塞等待
- 🍎 进程的阻塞等待方式
- 🍎 进程的非阻塞等待方式
- 🍎 总结
- 4. 进程程序替换
- 🍑 替换原理
- 🍑 图解分析
- 🍑 替换函数
- 🍑 函数解释
- 🍑 命名理解
- 🍎 execl
- 🍎 execlp
- 🍎 execv
- 🍎 execvp
- 🍎 用 test.c 去调用 mybin.c
- 🍎 execle
- 🍎 execve
- 🍎 总结
- 5. 手动实现一个简易的 Shell
- 🍑 函数和进程之间的相似性
1. 进程创建
🍑 fork 函数初识
在 Linux 中 fork 函数是一个非常重要的函数,它从已存在进程中创建一个新进程,此时新进程为子进程,而原进程为父进程。
#include <unistd.h>pid_t fork(void);返回值:子进程中返回0,父进程返回子进程id,出错返回-1
进程调用 fork 函数以后,当控制转移到内核中的 fork 代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork 返回,开始调度器调度
如下图所示:
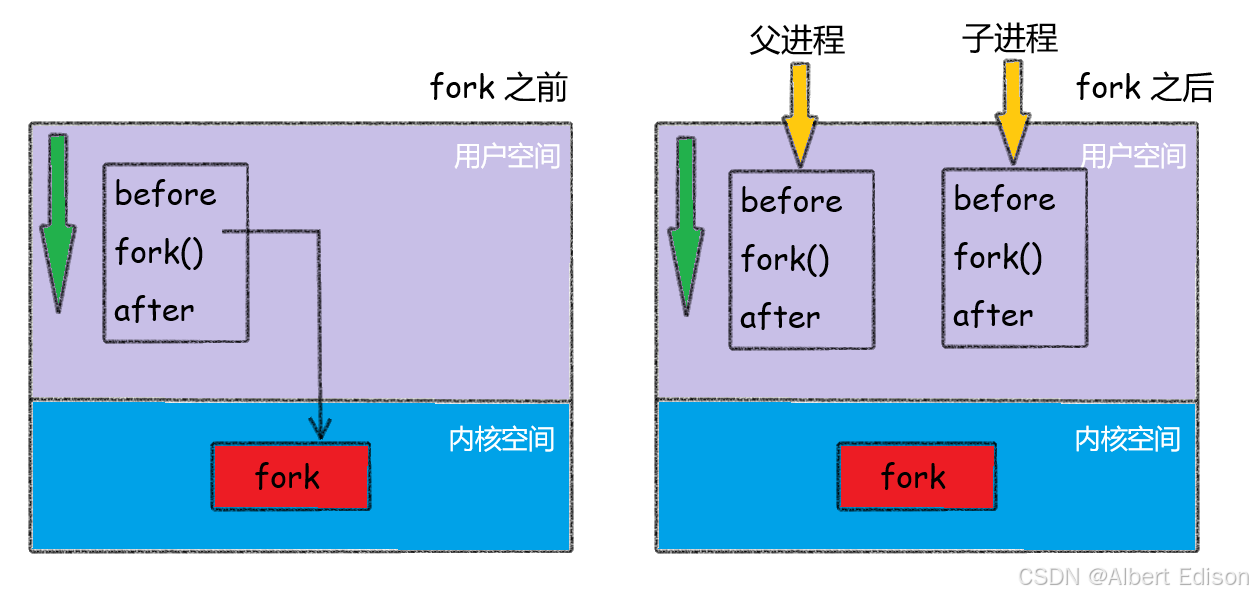
当一个进程调用 fork 之后,就有两个二进制代码相同的进程,而且它们都运行到相同的地方,但每个进程都将可以开始它们自己的旅程。
代码示例
int main()
{pid_t id;printf("Before: pid is %d\n", getpid());id = fork();if (id == -1){perror("fork()");exit(1);}printf("After: pid is %d, fork return %d\n", getpid(), id);sleep(1);return 0;
}
运行结果:
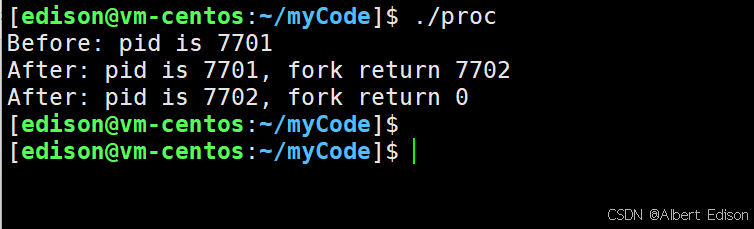
这里看到了三行输出,一行 Before,两行 After。进程 7701 先打印 Before 消息,然后它又打印 After,另一个 After 消息有 7702 打印的。
注意到进程 7702 没有打印 Before,为什么呢?如下图所示
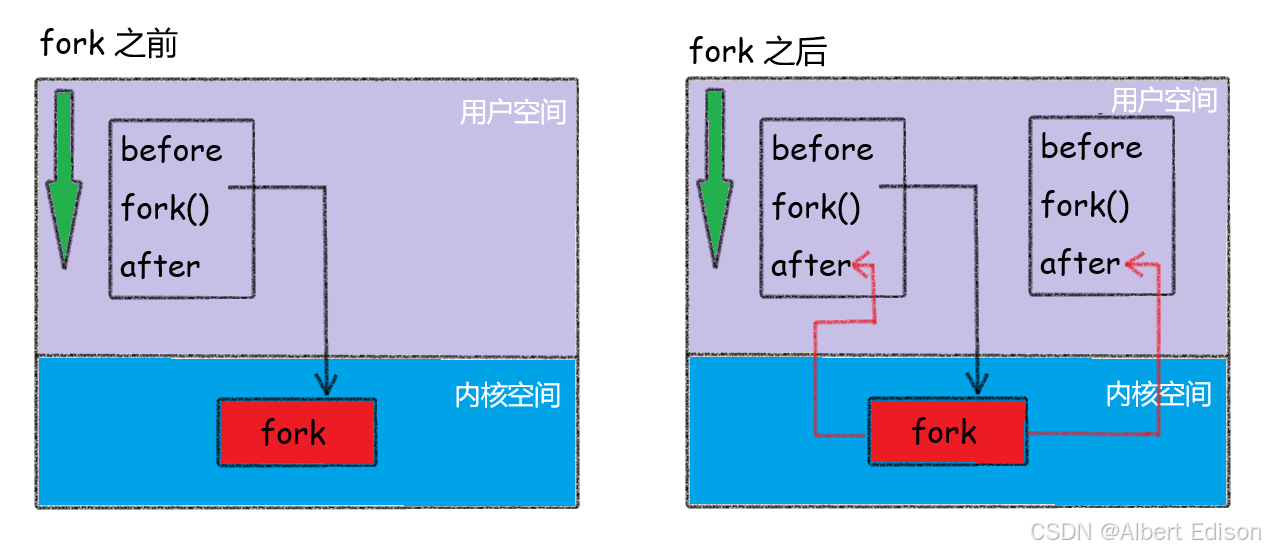
所以,fork 之前父进程独立执行,fork 之后,父子两个执行流分别执行。注意,fork 之后,谁先执行完全由调度器决定。
🍑 fork 函数返回值
我们再来看一段代码:
int main()
{pid_t id = fork();if (id > 0) {// father printf("我是父进程, pid: %d, ppid: %d\n", getpid(), getppid());}else if (id == 0) {// child printf("我是子进程, pid: %d, ppid: %d\n", getpid(), getppid());}else {printf("fork error\n");return 1;}sleep(1);return 0;
}
运行结果:
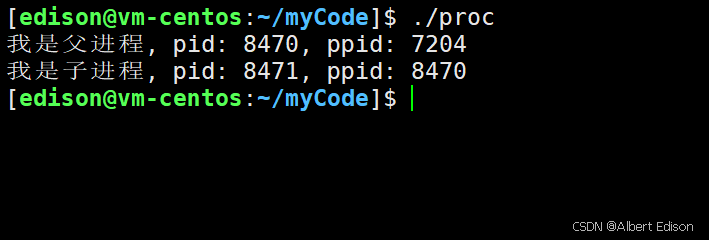
当我们使用 fork 创建进程以后,思考下面这些问题?
🍎 如何理解 fork 函数有两个返回值问题?
fork() 被调用一次,但会返回两次:
- 在父进程中,返回子进程的 PID(正整数)
- 在子进程中,返回 0
- 失败时返回 - 1
原理:fork() 通过复制当前进程(父进程)创建一个新进程(子进程)。复制完成后,两个进程从 fork() 调用的下一行开始继续执行。由于每个进程都有自己的执行上下文,fork() 在父进程和子进程中返回不同的值。
🍎 为什么给父进程返回子进程 PID,给子进程返回 0?
父进程需要子进程的 PID 来管理子进程(如等待子进程结束、发送信号等)。
子进程可以通过 getpid() 获取自己的 PID,通过 getppid() 获取父进程的 PID,因此不需要额外返回父进程的 PID。返回 0 是为了让子进程能够区分自己的身份。
🍎 如何理解同一个 id 值,怎么可能会保存两个不同的值?
换句话说,也就是如何让 if 和 else if 同时去执行各自的代码?
fork() 执行后,父进程和子进程拥有独立的内存空间。虽然代码看起来是同一个变量 id,但实际上:
- 父进程中的 id 存储子进程的 PID
- 子进程中的 id 存储 0
执行流程:
- 父进程调用
fork() - 系统创建子进程,复制父进程的内存(包括变量 id )
- 父进程继续执行,id 保存子进程 PID
- 子进程开始执行,id 保存 0
因此,if 和 else if 并非在同一个进程中同时执行,而是分别在父进程和子进程中执行。
我们修改代码,重新验证:
int main()
{printf("Before fork: pid=%d\n", getpid());pid_t id = fork();if (id > 0) {// 父进程执行此分支printf("父进程: pid=%d, ppid=%d, 子进程pid=%d\n", getpid(), getppid(), id);}else if (id == 0) {// 子进程执行此分支printf("子进程: pid=%d, ppid=%d, fork返回值=%d\n", getpid(), getppid(), id);}else {perror("fork失败");return 1;}// 父子进程都会执行这里printf("pid=%d 即将退出\n", getpid());return 0;
}
运行结果:
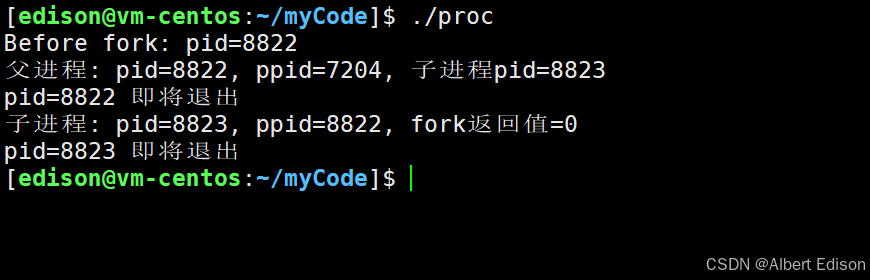
总结:fork() 通过复制进程创建两个独立的执行上下文,每个上下文有自己的变量副本,从而实现不同的返回值。这是 Linux 多进程编程的基础机制。
🍑 写时拷贝
通常,父子代码共享,父子不再写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
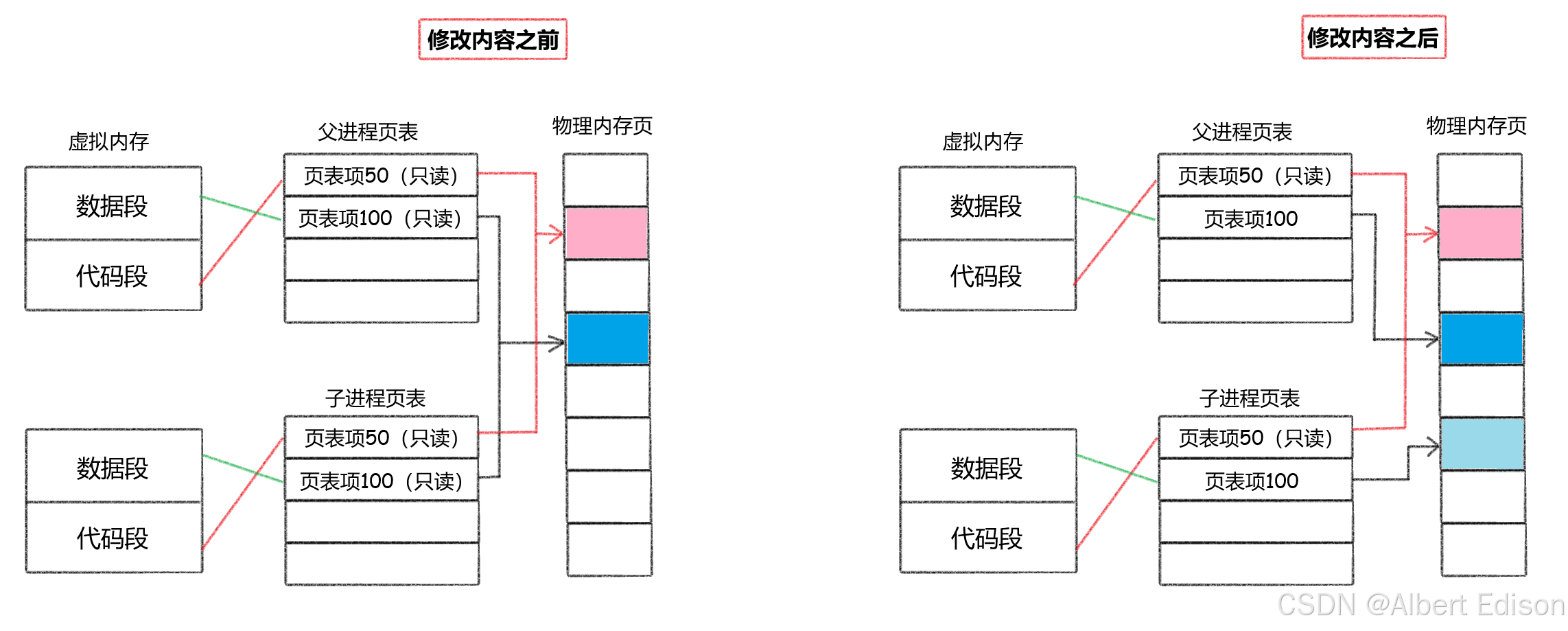
🍑 fork 常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从 fork 返回后,调用 exec 函数。
🍑 fork 调用失败的原因
- 系统中有太多的进程。
- 实际用户的进程数超过了限制。
2. 进程终止
🍑 进程退出场景
进程退出的情况主要分为三种:
- 代码跑完了,结果正确 —>
return 0 - 代码跑完了,结果不正确 -->
return !0 - 代码没跑完,程序异常了,退出码无意义
🍑 进程常见退出方法
正常终止(可以通过 echo $? 查看进程退出码):
- 从 main 函数返回
- 调用
exit _exit
异常退出:
- ctrl + c,信号终止
🍑 return 退出
main 函数中的 return 0 是什么意思?这个 0 返回给谁的呢?为什么要写 0 呢?
这个 0 叫做进程退出时,它所对应的退出码,它能标定进程执行的结果是否正确。
代码示例:
int addToTarget(int from, int to)
{ int sum = 0; for (int i = from; i < to; i++) sum += i; return sum;
} int main()
{ int num = addToTarget(1, 100); if (num == 5050) return 0; else // num不等于5050, 执行else语句return 1;
}
运行结果:
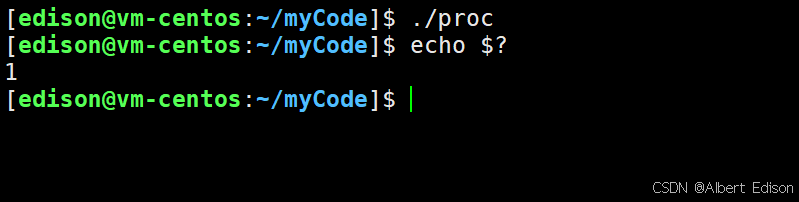
其中 echo $? 永远记录最近一个进程在命令行中执行完毕时对应的退出码。
那么以后如何设定 main 函数的返回值呢?很简单,如果不关心进程退出码,直接 return 0 即可。
如果未来我们是要关心进程退出码的时候,要返回特定的数据表明特定的错误,其中退出码的意思如下:
- 0:按照惯例,0 表示程序成功执行并正常退出,没有发生任何未处理的错误。
- 非零值 (例如 1,-1,255 等):通常表示程序在执行过程中遇到了某种错误或异常情况,导致非正常退出。具体哪个非零值代表什么错误,可以由程序员自行定义,但也有一些通用的约定(例如,1 通常表示一个通用错误)。
那怎么把退出码转换成对应的文字描述呢?我们需要用到库函数 strerror
strerror()函数返回一个指向字符串的指针,该字符串描述了通过参数errnum传入的错误代码
我们可以打印出每个退出码的意思:
int main()
{for (int i = 0; i < 100; i++){printf("%d: %s\n", i, strerror(i));}
}
运行结果:
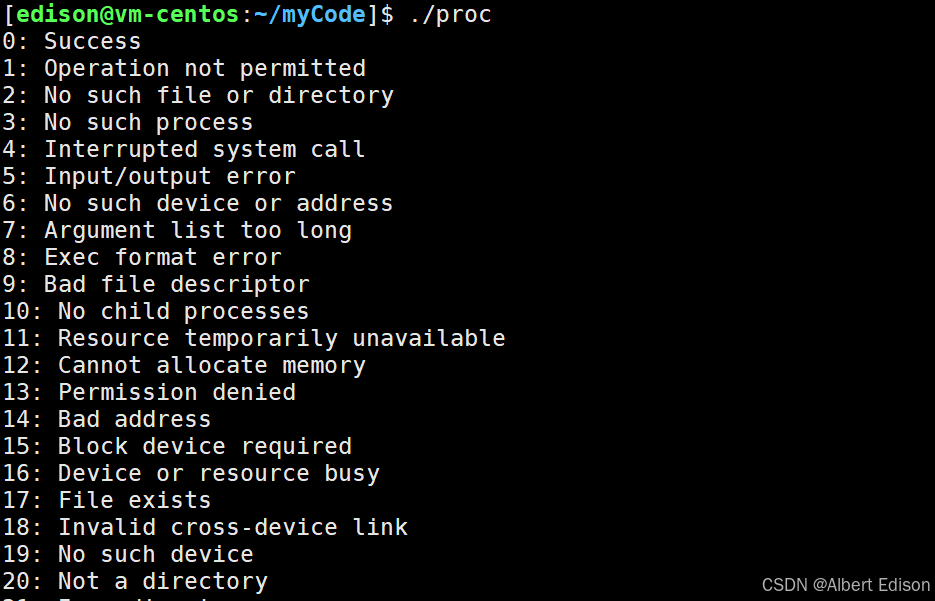
同样,我们也可以验证一下:
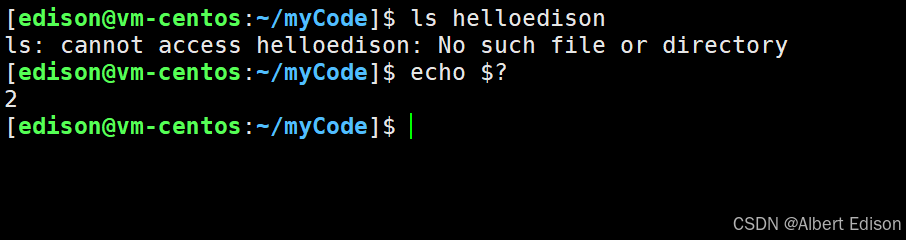
总结:return 是一种更常见的退出进程方法,执行 return n 等同于执行 exit(n),因为调用 main 的运行时函数会将 main 的返回值当做 exit 的参数。
🍑 _exit 函数
_exit() 是系统调用,会直接终止进程,不进行任何用户空间的清理工作(如刷新缓冲区)。
#include <unistd.h>void _exit(int status);
其中:
- 参数 status 定义了进程的终止状态,父进程通过 wait 来获取该值。
代码示例:
可以看到此时什么也没有打印:
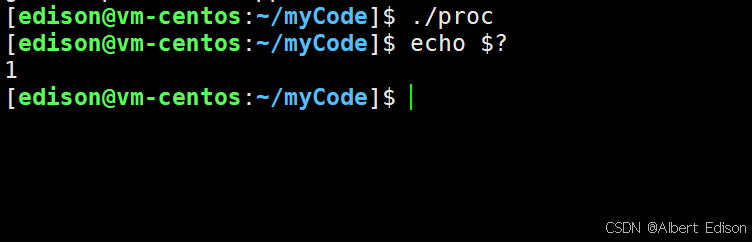
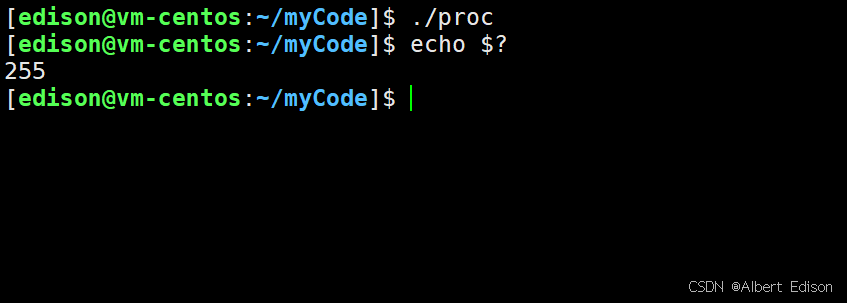
虽然 status 是 int,但是仅有低 8 位可以被父进程所用,所以 _exit(-1) 时,在终端执行 $? 发现返回值是 255。
🍑 exit 函数
exit() 是 C 库函数,会执行清理操作,包括刷新 stdio 缓冲区,然后调用 _exit (或类似的系统调用) 来终止进程。
#include <stdlib.h>void exit(int status);
其中:
exit()函数会导致进程正常终止,并将状态值与 0377 进行按位与运算的结果返回给父进程,并且函数本身不会返回任何值。
代码示例:
int main()
{printf("hello edison\n");exit(12);while (1)sleep(1);
}
运行结果:
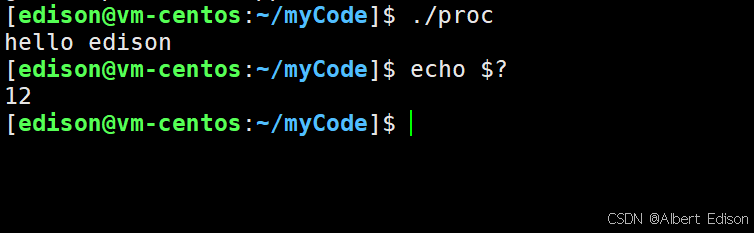
再对代码进行修改:
int main()
{printf("hello edison");sleep(2);exit(1);
}
运行结果:
为什么前 2 秒钟 hello eidson 没有显示出来呢?很简单,因为此时数据还在缓冲区!
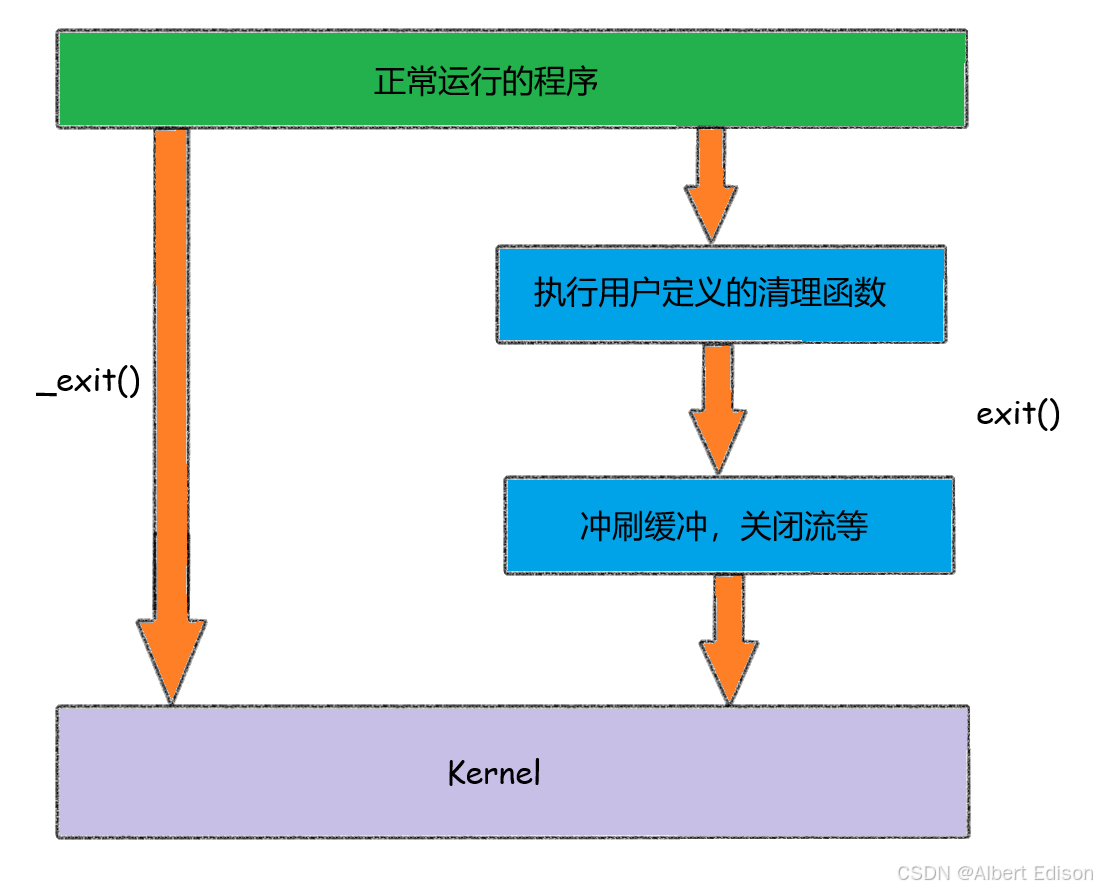
exit() 最后也会调用 _exit(),但在调用 exit() 之前,还做了其他工作:
- 执行用户通过
atexit或on_exit定义的清理函数。 - 关闭所有打开的流,所有的缓存数据均被写入。
- 调用
_exit()。
如下图所示:
3. 进程等待
🍑 进程等待必要性
之前提到过,若子进程退出时父进程未做处理,会导致 僵尸进程 问题,进而造成内存泄漏。
僵尸进程处于一种特殊状态,此时即便使用 kill -9 也无法终止它,毕竟无法杀死一个已经结束运行的进程。
父进程创建子进程通常是为了执行特定任务,那么如何知晓子进程的任务完成情况呢?
这就需要通过进程等待机制,父进程不仅能回收子进程占用的资源,还能获取子进程的退出状态,从而判断任务执行是否成功、子进程是否正常退出。
回顾一下僵尸进程危害:
- 僵尸进程会一直占用进程表项。
- 若大量僵尸进程存在,可能导致系统无法创建新进程。
进程等待实现方式:
- 使用
wait()阻塞等待任意子进程退出 - 使用
waitpid()可指定等待某个子进程 - 通过
WEXITSTATUS等宏解析退出状态(了解即可,不必深究)
🍑 进程等待的方法
🍎 wait 方法
功能:父进程调用 wait() 会阻塞,直到任意一个子进程结束。
#include <sys/types.h>
#include <sys/wait.h>pid_t wait(int *status);
返回值:
- 成功:返回结束的子进程的 PID。
- 失败:返回 -1(如无子进程)。
参数 status:
- 指向一个整数变量,用于存储子进程的退出状态码。
- 若不关心退出状态,可传入 NULL。
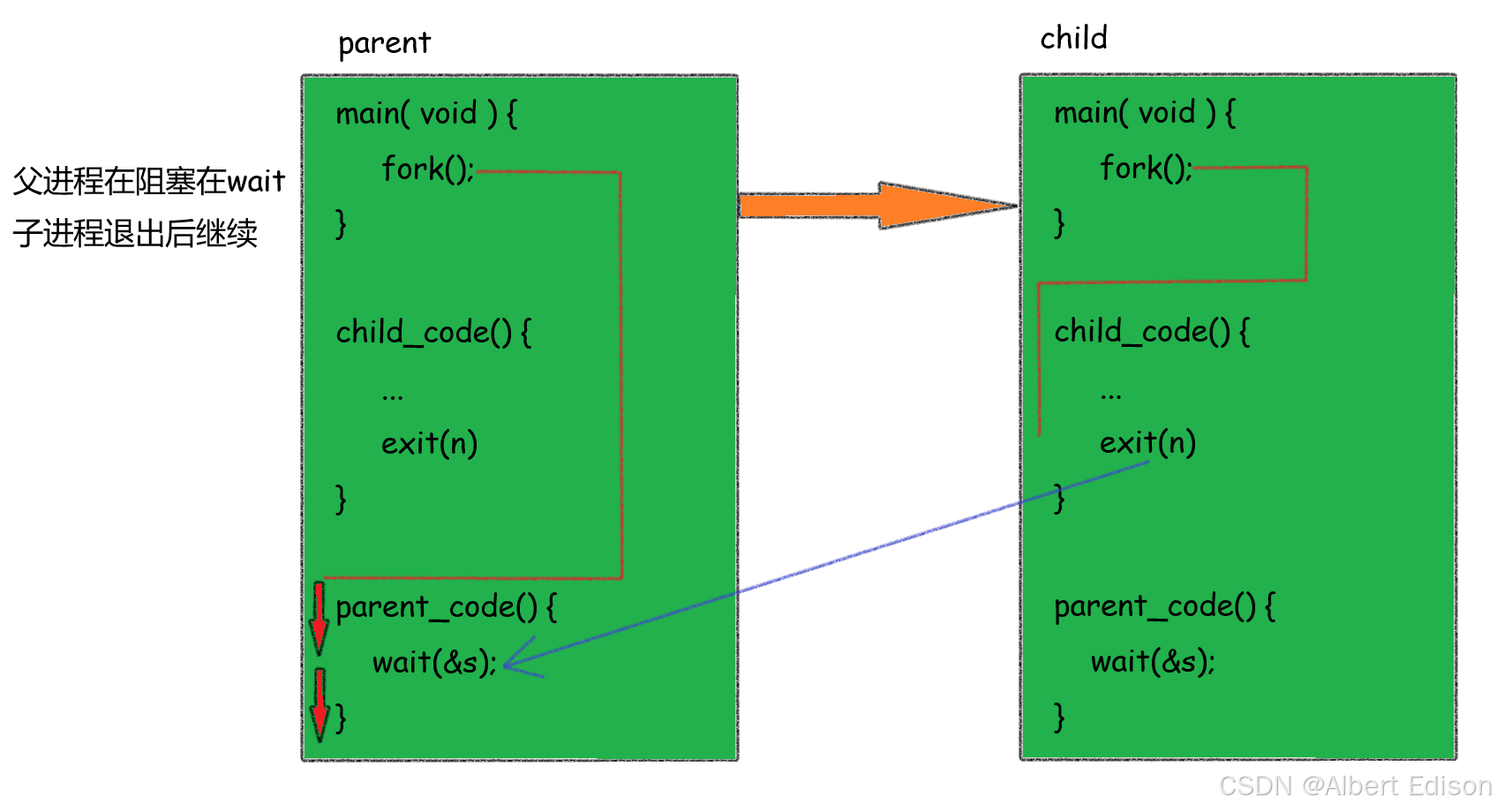
我们可以假设这样一个场景:当父进程休眠 15 秒时,子进程会在运行 10 秒后退出。由于父进程尚未执行 wait() 操作,子进程会进入僵尸状态(Z 状态)并持续约 5 秒。直到父进程休眠结束调用 wait(),僵尸进程的资源才会被回收,状态标记从 Z 变为终止。
代码示例:
int main()
{pid_t id = fork();if (id == 0){// childint cnt = 10;while (cnt){printf("我是子进程: %d, 父进程: %d, cnt: %d\n", getpid(), getppid(), cnt--);sleep(1);}exit(0); // 进程退出}// 父进程sleep(15);pid_t ret = wait(NULL);if (id > 0){printf("wait success: %d\n", ret);}sleep(5);return 0;
}
我们写一个监控脚本来看看运行结果:
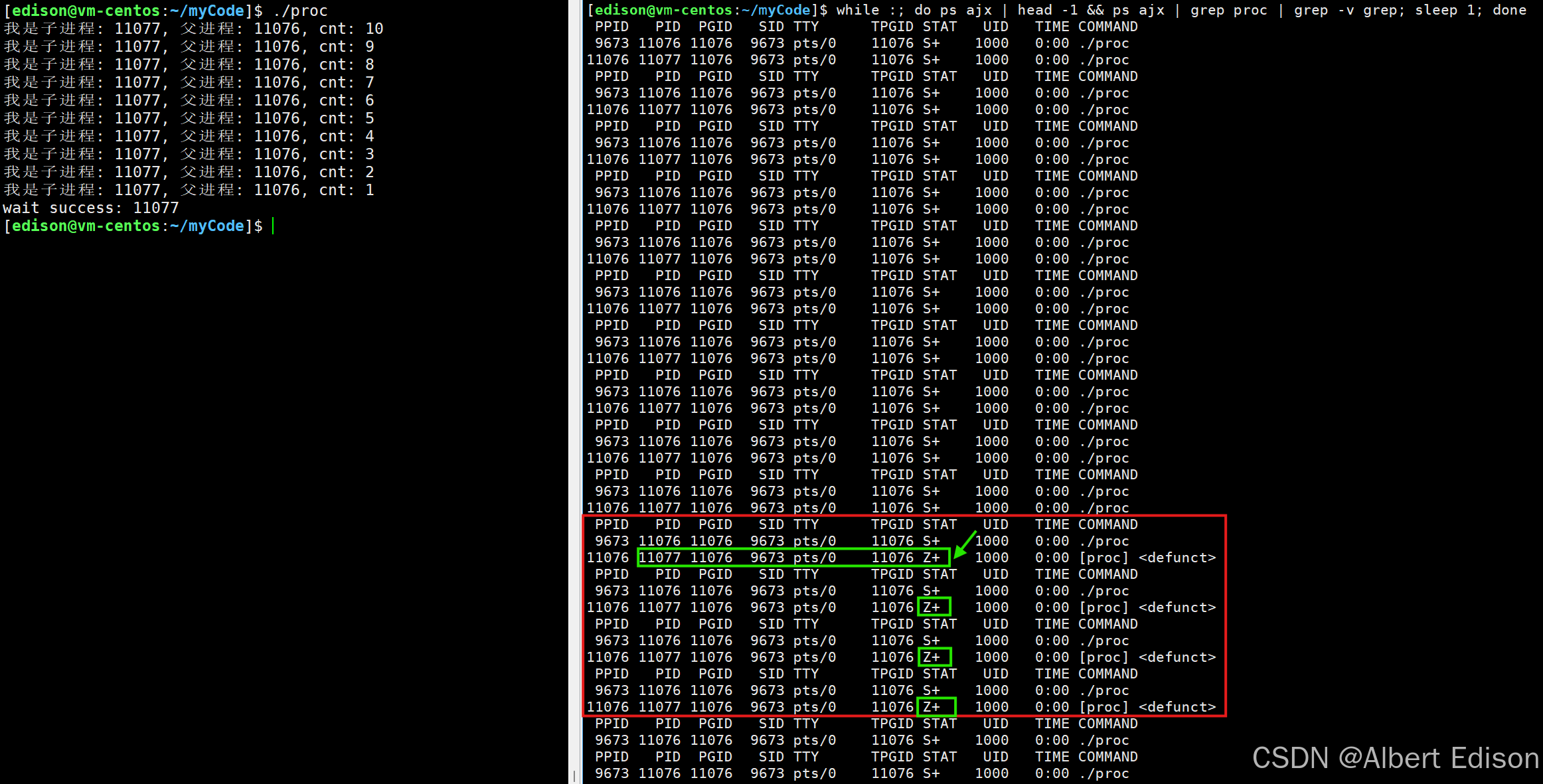
子进程行为:
- 子进程循环 10 秒(cnt 从 10 递减到 1),每秒打印一次信息。
- 10 秒后子进程调用
exit(0)退出,此时子进程变成僵尸进程(Z 状态),等待父进程回收。
父进程行为:
- 父进程休眠 15 秒,期间未调用
wait()。 - 在子进程退出后的前 5 秒(第 11~15 秒),子进程处于僵尸状态(可通过脚本观察到
Z+标记)。 - 父进程休眠 15 秒结束后,调用
wait(NULL)回收子进程,僵尸状态消失。 - 父进程再休眠 5 秒后退出。
🍎 waitpid 方法
功能:父进程调用 waitpid() 等待指定子进程或任意子进程结束,并获取其退出状态。
#include <sys/types.h>
#include <sys/wait.h>pid_t waitpid(pid_t pid, int *status, int options);
返回值:
- 成功:返回结束的子进程的 PID。
- 失败:返回 -1(如无子进程、参数错误等)。
参数:
pid:指定要等待的子进程:pid > 0:等待 PID 等于 pid 的子进程。pid == -1:等待任意子进程(等同于wait())。pid == 0:等待同进程组的所有子进程。pid < -1:等待进程组 ID 等于 |pid| 的所有子进程。
status:指向整数变量,用于存储子进程的退出状态(若不关心可传 NULL)。
options:控制等待行为的标志位,常用:
- WNOHANG:非阻塞模式,若子进程未结束立即返回 0。
- WUNTRACED:追踪暂停的子进程(用于调试)。
- WCONTINUED:追踪恢复执行的子进程。
代码示例 1:
int main()
{pid_t id = fork();if (id == 0){// childint cnt = 5;while (cnt){printf("我是子进程: %d, 父进程: %d, cnt: %d\n", getpid(), getppid(), cnt--);sleep(1);}exit(10); // 进程退出}// 父进程int status = 0;pid_t ret = waitpid(id, &status, 0); // 设置为0表示阻塞时等待if (id > 0){printf("wait success: %d, ret: %d\n", ret, status); }sleep(5);return 0;
}
运行结果:
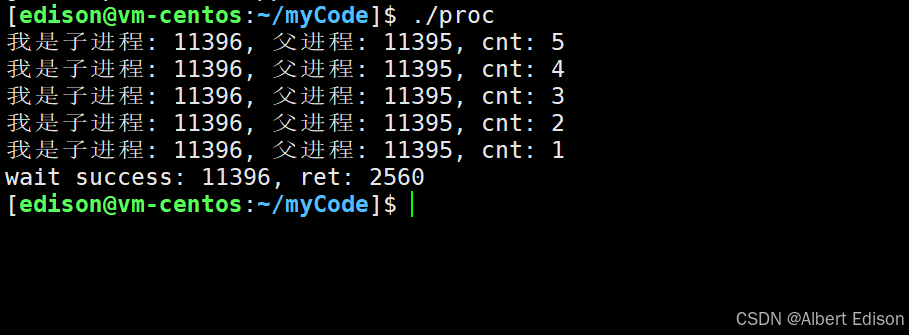
为什么 status 的值是 2560 呢?这是由于对 waitpid 返回的状态码的解读方式不正确导致。
🍎 获取子进程status
wait 和 waitpid,都有一个 status 参数,该参数是一个输出型参数,由操作系统填充。
如果传递 NULL,表示不关心子进程的退出状态信息;否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
waitpid 的 status参数并非直接返回子进程的退出码,而是一个32 位整数,包含多个状态标志位,也就是说不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究 status 低 16 比特位):
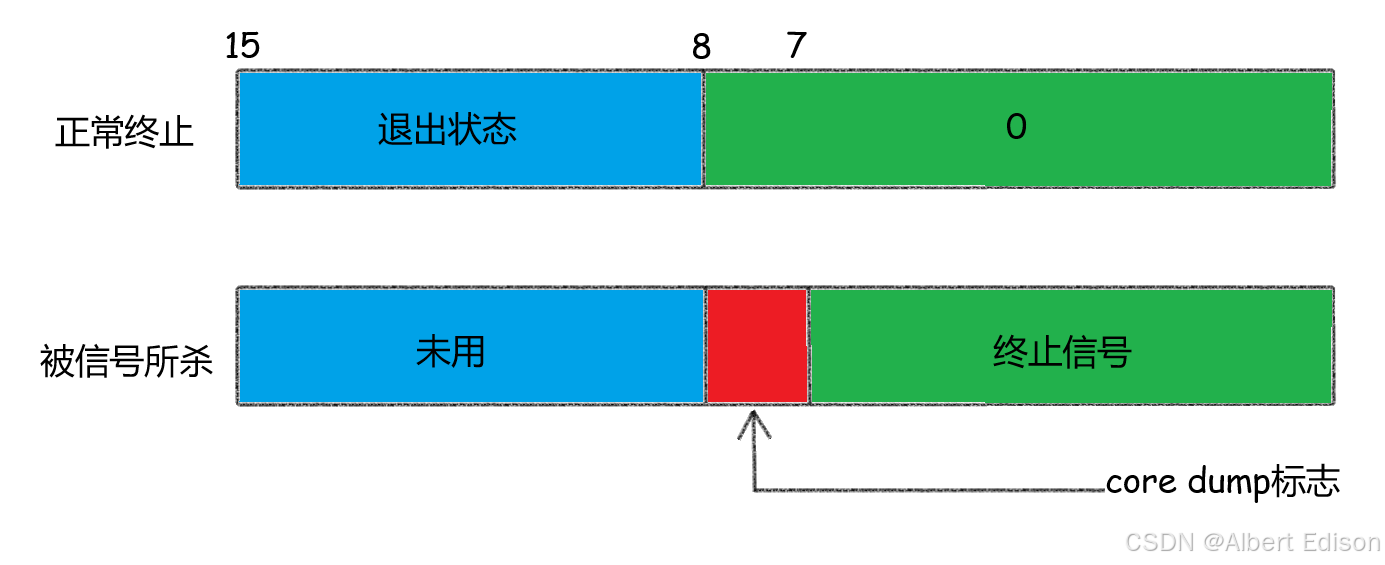
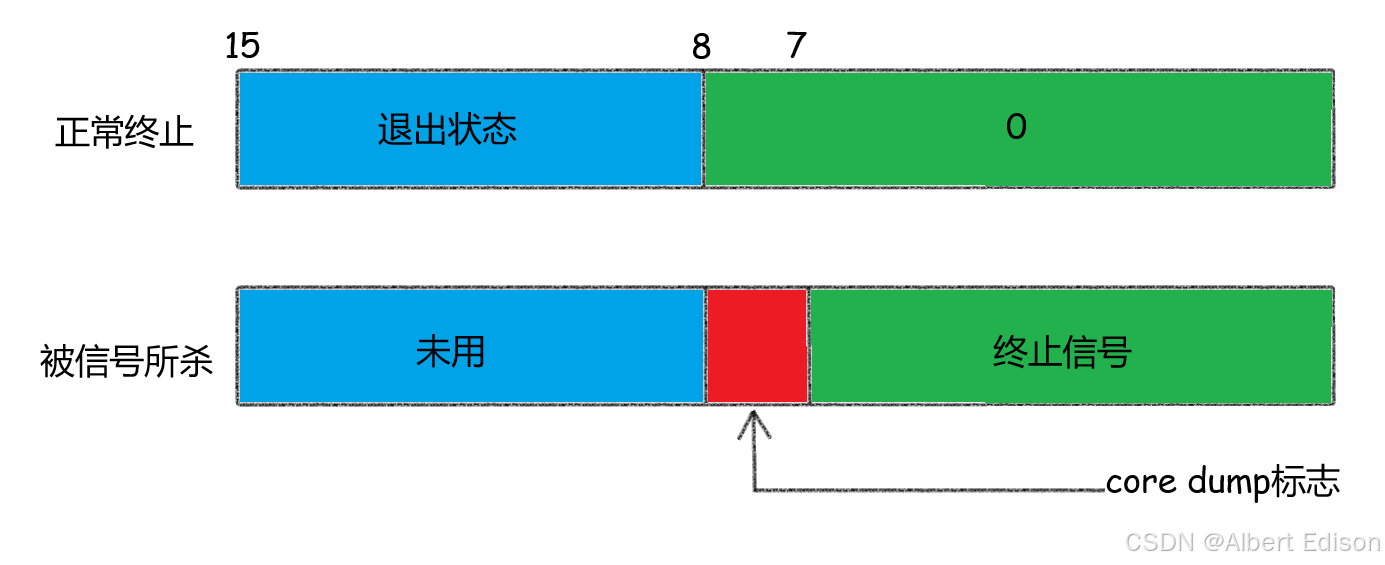
其中:
- 低 8 位:表示终止子进程的信号编号(如果子进程被信号终止)。
- 8-15 位:存储子进程的退出码(即
exit(10)中的 10)。 - 其他位:存储更多状态信息(如进程是否暂停、是否继续执行等)。
而在上面的例子中:
- 子进程调用
exit(10),退出码为 10。 - 10 的二进制表示为 00001010。
- 当这个值被存储在 status 的 8-15 位时,实际数值为
10 << 8 = 2560(十进制)。
所以我们重新对代码进行修改。
代码示例 2:
int main()
{pid_t id = fork();if (id == 0){// childint cnt = 5;while (cnt){printf("我是子进程: %d, 父进程: %d, cnt: %d\n", getpid(), getppid(), cnt--);sleep(1);}exit(10); // 进程退出}// 父进程int status = 0;pid_t ret = waitpid(id, &status, 0); // 设置为0表示阻塞时等待if (id > 0){printf("wait success: %d, sig number: %d, child exit code: %d\n", ret, (status & 0x7F), (status >> 8) & 0xFF); }sleep(5);return 0;
}
代码中的:printf(“wait success: %d, sig number: %d, child exit code: %d\n”, ret, (status & 0x7F), (status >> 8) & 0xFF);
运行结果:
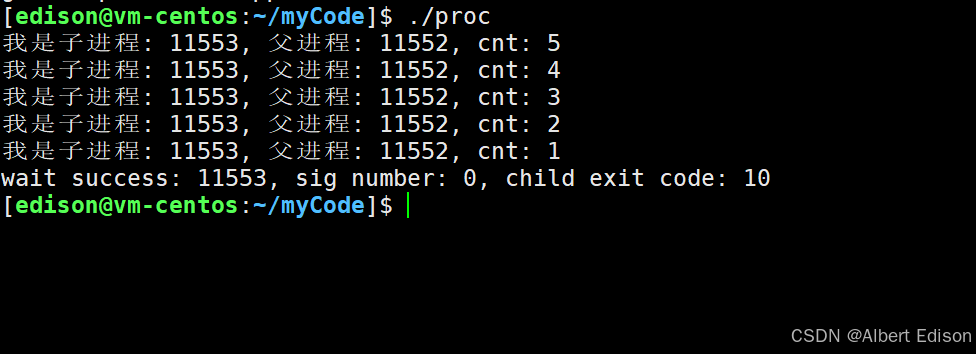
解释一下:
1、(status & 0x7F)
0x7F的二进制是0000 0000 0000 0000 0000 0000 0111 1111(低 7 位全为 1)。
status & 0x7F会屏蔽所有高位,只保留低 7 位,即信号编号。
示例:若子进程被 SIGTERM(信号 15)终止,status & 0x7F结果为 15。2、(status >> 8) & 0xFF
status >> 8将整个状态码右移 8 位,把退出码部分移到低 8 位。
0xFF的二进制是0000 0000 0000 0000 0000 0000 1111 1111(低 8 位全为 1)。
(status >> 8) & 0xFF会屏蔽右移后的高位,只保留低 8 位的退出码。
示例:若子进程exit(10),(status >> 8) & 0xFF结果为 10。3、假设子进程正常退出,退出码为 10:status的二进制表示:
0000 0000 0000 0000 0000 1010 0000 0000
(退出码 10 位于第 8-15 位,其余位为 0)3.1 计算信号编号status: 0000 0000 0000 0000 0000 1010 0000 0000
& 0x7F: 0000 0000 0000 0000 0000 0000 0111 1111
--------------------------------------------- 结果: 0000 0000 0000 0000 0000 0000 0000 0000 → 十进制值为0 结论:信号编号为 0,表示子进程未被信号终止(正常退出)。3.2 计算退出码
1. 右移8位: 0000 0000 0000 0000 0000 1010 0000 0000 >> 8 ↓ 0000 0000 0000 0000 0000 0000 0000 1010 2. 与0xFF: 0000 0000 0000 0000 0000 0000 0000 1010
& 0xFF: 0000 0000 0000 0000 0000 0000 1111 1111
--------------------------------------------- 结果: 0000 0000 0000 0000 0000 0000 0000 1010 → 十进制值为10
结论:退出码为 10,与子进程exit(10)一致。
信号除了为 0,还有其它的吗?当然有!
代码示例 3:
int main()
{pid_t id = fork();if (id == 0){// childint cnt = 5;while (cnt){printf("我是子进程: %d, 父进程: %d, cnt: %d\n", getpid(), getppid(), cnt--);sleep(1);// 新增bugint a = 10;a /= 0;}exit(10); // 进程退出}// 父进程int status = 0;pid_t ret = waitpid(id, &status, 0); // 设置为0表示阻塞时等待if (id > 0){printf("wait success: %d, sig number: %d, child exit code: %d\n", ret, (status & 0x7F), (status >> 8) & 0xFF); }sleep(5);return 0;
}
可以看到,此时 sig number 为 8,说明我们的进程运行期间出错了:
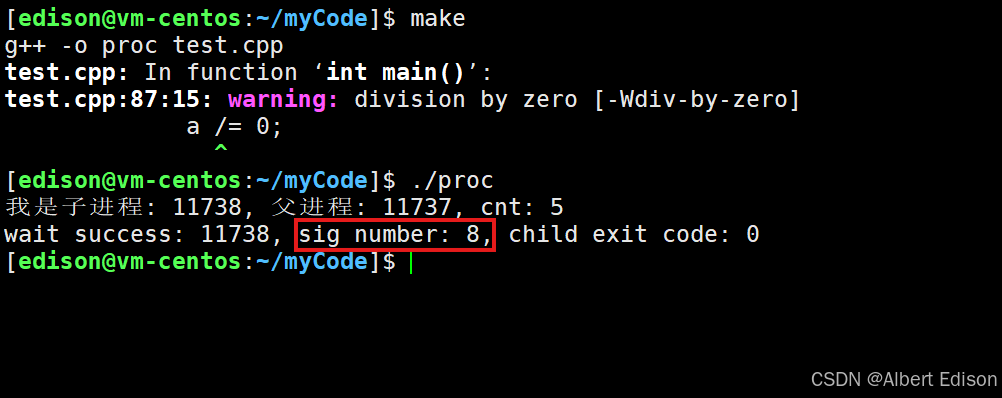
可以使用用 kill -l 可以看到 SIGFPE(信号编号 8) 代表浮点异常(Floating-Point Exception)
总结如下:
child exit code是子进程通过exit(n)或return n返回的退出状态值(即代码中的exit(10))。它反映了子进程执行的结果。- 0:表示子进程正常结束(成功执行完毕)。
- 非 0:通常表示子进程异常结束,非 0 值可用于指示具体错误类型(由程序自定义,如 1 表示参数错误,2 表示文件不存在等)。
sig number表示终止子进程的信号编号。如果子进程是被信号杀死的(而非正常退出),该值会指示具体是哪个信号。- 0:表示子进程正常退出(通过
exit()或return),未收到任何终止信号。 - 非 0:表示子进程被信号终止。例如:11 对应 SIGSEGV(段错误)。
- 0:表示子进程正常退出(通过
Linux 系统中 wait() 和 waitpid() 函数的三种核心行为模式,它们完全由子进程的当前状态决定:
- 如果子进程已经退出,调用
wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退出信息。 - 如果在任意时刻调用
wait/waitpid,子进程存在且正常运行,则进程可能阻塞。 - 如果不存在该子进程,则立即出错返回。
如下图所示:
🍎 总结
当我们讨论僵尸进程时,一个关键问题是:进程退出后,其状态信息究竟存储在哪里?
实际上,进程变为僵尸状态时:
1)代码段和数据段 会被操作系统回收,因为进程已停止运行。
2)** 进程控制块(PCB)** 必须被保留,其中存储了两项关键信息:
- 退出状态码(exit code)
- 终止信号(if any)
这些信息被保存在 PCB 中,直到父进程通过 wait() 或 waitpid() 系统调用读取。具体流程是:
- 子程退出时,操作系统将退出状态写入其 PCB。
- 父进程调用
wait()获取该 PCB 中的状态信息(通过status参数)。 - 父进程解析状态后,子进程的 PCB 才会被彻底释放。
在应用层,子进程的退出情况可归纳为三类:
- 正常结束且结果正确(退出码通常为 0)
- 正常结束但结果错误(退出码为非零值,如 1、2 等)
- 异常终止(由信号触发,如 SIGSEGV、SIGFPE 等)
🍑 阻塞等待 与 非阻塞等待
再谈进程退出:
- 当进程退出时,会进入僵尸状态,此时进程虽然终止运行,但其
task_struct结构会保留,其中记录了进程的退出状态码等信息。 wait/waitpid作为系统调用,由操作系统内核执行。内核通过这两个接口可以访问并读取子进程的task_struct数据。
因此,父进程调用 wait/waitpid 获取的子进程退出信息,实际上是内核从子进程的 task_struct 中提取并返回的。
进程退出搞明白了,那么阻塞等待和非阻塞等待又是啥呢?别急,我们先来看两个小故事。
故事一:
你给李四打电话,可李四好一会儿才接听。你便对他说:“你先别挂电话呀”。说完,你就自顾自地看起书来,把电话放在了旁边。就这样,你一边看着书,一边等着李四,并且时不时的问李四收拾好了没有。
过了大概 30 分钟,电话那头传来李四的声音:“张三,走吧,我已经到楼下了,都能看到你了呢”。听到这话,你赶忙挂了电话,也清楚了李四现在的状态,知道他已经下楼了。想到马上就能见到李四,你心里很高兴,随后便和李四开开心心地去吃饭了。
其中,你不挂电话是为了检测李四的状态,那么这种就叫做:阻塞等待。
故事二:
我给你打电话,然后问道:“你现在状态好了没呀?” 你回复说还没好呢,那我就说:“那咱们先把电话挂了吧,你先好好收拾,我就在楼下等你。” 李四听了,回了句 “行”,于是双方就这么约定好了。
之后,张三又给李四打了个电话,再次问李四:“你现在好了没?” 李四回答说还没好呢,张三便挂了电话。挂了电话后,张三就在楼底下待着,一会儿看看书,一会儿玩玩手机,偶尔还会和几个半生不熟的朋友打打招呼。
又等了一两分钟,张三实在等不及了,就又给李四打电话问:“好了没呀?” 李四还是说还没好,让张三再等等,张三无奈地回了句 “好吧”,接着就把电话挂了,继续在楼下耐心等候。
就这样,前前后后张三给李四打了十几通电话呢。大概过了二三十分钟,李四终于回复说:“我好了啊,我已经看到你了,我已经到楼下了。”随后,两人开开心心地去吃饭了。
张三给李四打电话的本质是进行状态检测:若李四处于未就绪状态,张三会直接挂断电话,这一单次行为属于非阻塞操作;而张三反复多次进行这种非阻塞尝试的过程,即构成了轮询机制。
我们可以把打电话的过程类比为系统调用 wait/waitpid:
- 张三 → 父进程
- 李四 → 子进程
当父进程调用 wait/waitpid 等待子进程时,若采用传统的阻塞式方式:
- 若子进程未退出,父进程会被阻塞在
wait/waitpid调用处 - 直到子进程退出后,
wait/waitpid才会返回结果
这就是第一种情况:阻塞式等待
而非阻塞等待的机制则不同:
- 父进程调用
wait/waitpid检测子进程状态时 - 若子进程未退出,系统会立即返回结果(不会阻塞父进程)
- 父进程可以继续执行其他任务
这种每次检测后立即返回的方式,就是非阻塞等待。
🍎 进程的阻塞等待方式
代码示例:
int main()
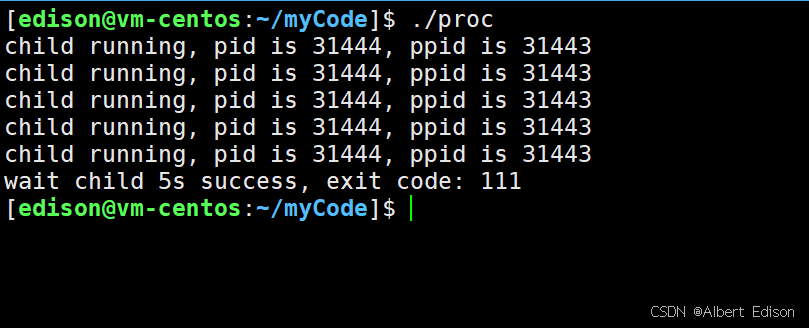
{pid_t id = fork();assert(-1 != id);if (0 == id){// childint cnt = 5;while (cnt){printf("child running, pid is %d, ppid is %d\n", getpid(), getppid());cnt --;sleep(1);}exit(111); }// parent// 1. 让OS释放子进程的Z状态// 2. 获取子进程的退出结果// 在等待期间, 子进程没有退出的时候, 父进程只能阻塞等待int status = 0; // child的退出信息int ret = waitpid(id, &status, 0); //waitpid的第三个参数options为0,表示默认使用阻塞模式if (ret > 0) // 等待成功{ // 判断是否正常退出if (WIFEXITED(status)) // 正常退出为真{// 判断子进程运行结果是否OKprintf("wait child 5s success, exit code: %d\n", WEXITSTATUS(status));}else {// printf("child exit not normal!\n");}}return 0;
}
运行结果:
🍎 进程的非阻塞等待方式
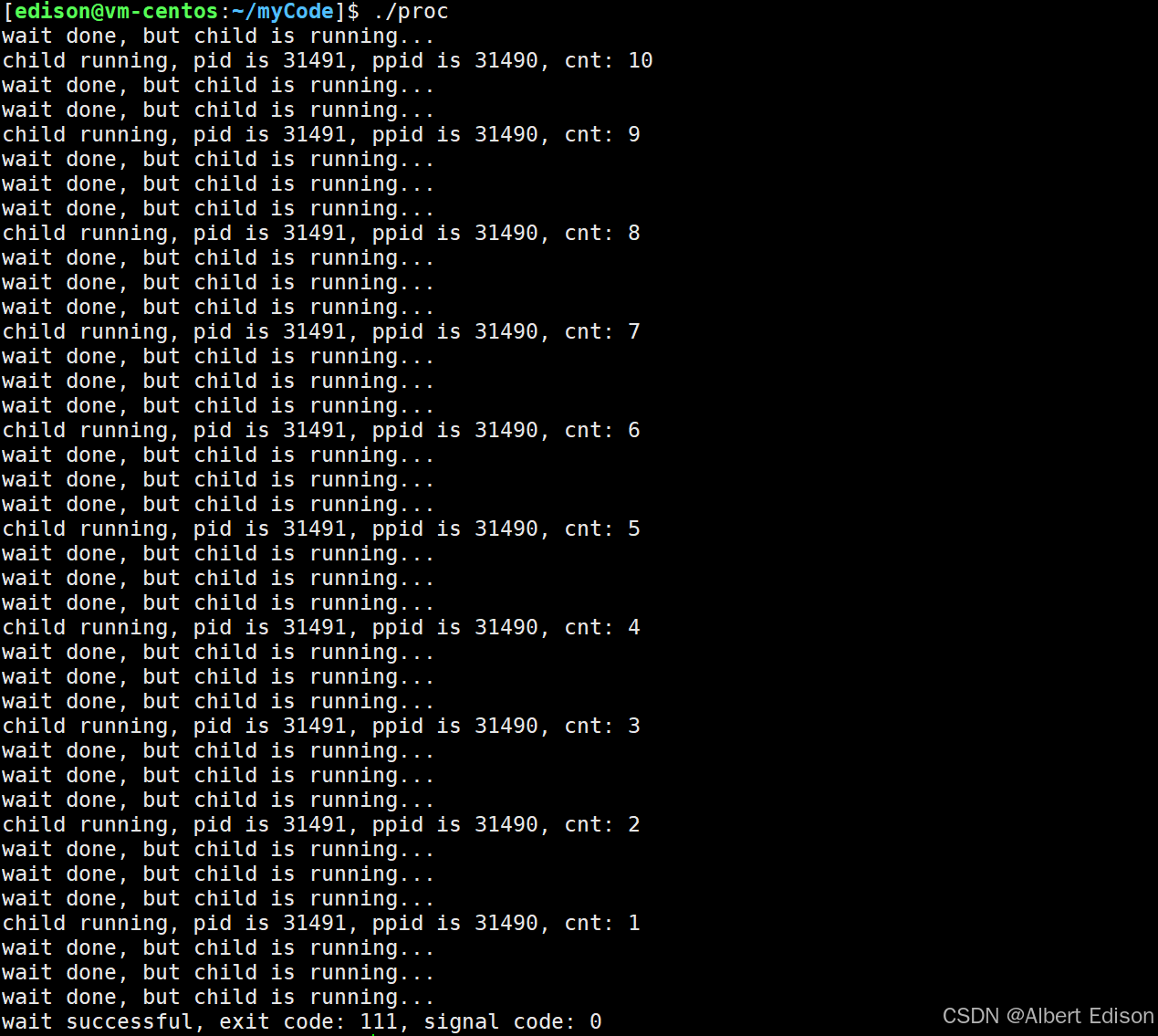
在下面这段代码里,子进程每三秒会打印一次信息,并且会持续运行十秒。父进程则以每秒一次的频率对其进行非阻塞检查,一旦子进程结束运行,父进程就能马上获取到它的退出状态。
int main()
{pid_t id = fork();assert(-1 != id);if (0 == id){// childint cnt = 10;while (cnt){printf("child running, pid is %d, ppid is %d, cnt: %d\n", getpid(), getppid(), cnt);cnt --;sleep(3);}exit(111); }// parentint status = 0;while (1){pid_t ret = waitpid(id, &status, WNOHANG); // WNOHANG: 非阻塞 --> 子进程没有退出, 父进程检测之后, 立即返回if (ret == 0){// waitpid调用成功 && 子进程没有退出// 子进程没有退出, 我的waitpid没有等待失败, 仅仅是检测到了子进程没退出.printf("wait done, but child is running...\n");}else if (ret > 0){// 1. 等待成功 --> waitpid调用成功, 并且子进程退出了printf("wait successful, exit code: %d, signal code: %d\n", (status >> 8)&0xFF, status & 0x7F);break;}else {// waitpid调用失败printf("waitpid call failed\n");break;}sleep(1);}return 0;
}
运行结果:
非阻塞等待:waitpid(id, &status, WNOHANG) 以非阻塞模式检查子进程状态:
ret == 0:子进程仍在运行。ret > 0:子进程已退出,返回值为子进程 PID。ret < 0:等待失败(如子进程不存在)。
解析退出状态:
(status >> 8) & 0xFF:提取子进程的退出状态码(exit(111)中的 111)。status & 0x7F:提取终止子进程的信号编号(正常退出时为 0)。- 轮询间隔:父进程每次检查后 sleep(1),避免 CPU 资源浪费。
执行流程:
- 父进程创建子进程后进入循环,每秒检查一次子进程状态。
- 子进程运行 10 秒,期间父进程每次检查都会输出 “wait done, but child is running…”。
- 子进程退出后,父进程捕获到退出状态,打印退出码(111)和信号码(0),然后结束。
关键点
- 非阻塞等待:父进程无需挂起,可以继续执行其他任务(这里是每秒检查一次)。
- 资源回收:通过
waitpid确保子进程不会变成僵尸进程(Zombie Process)。 - 状态解析:status 参数包含子进程的退出状态和终止信号信息,通过位运算提取。
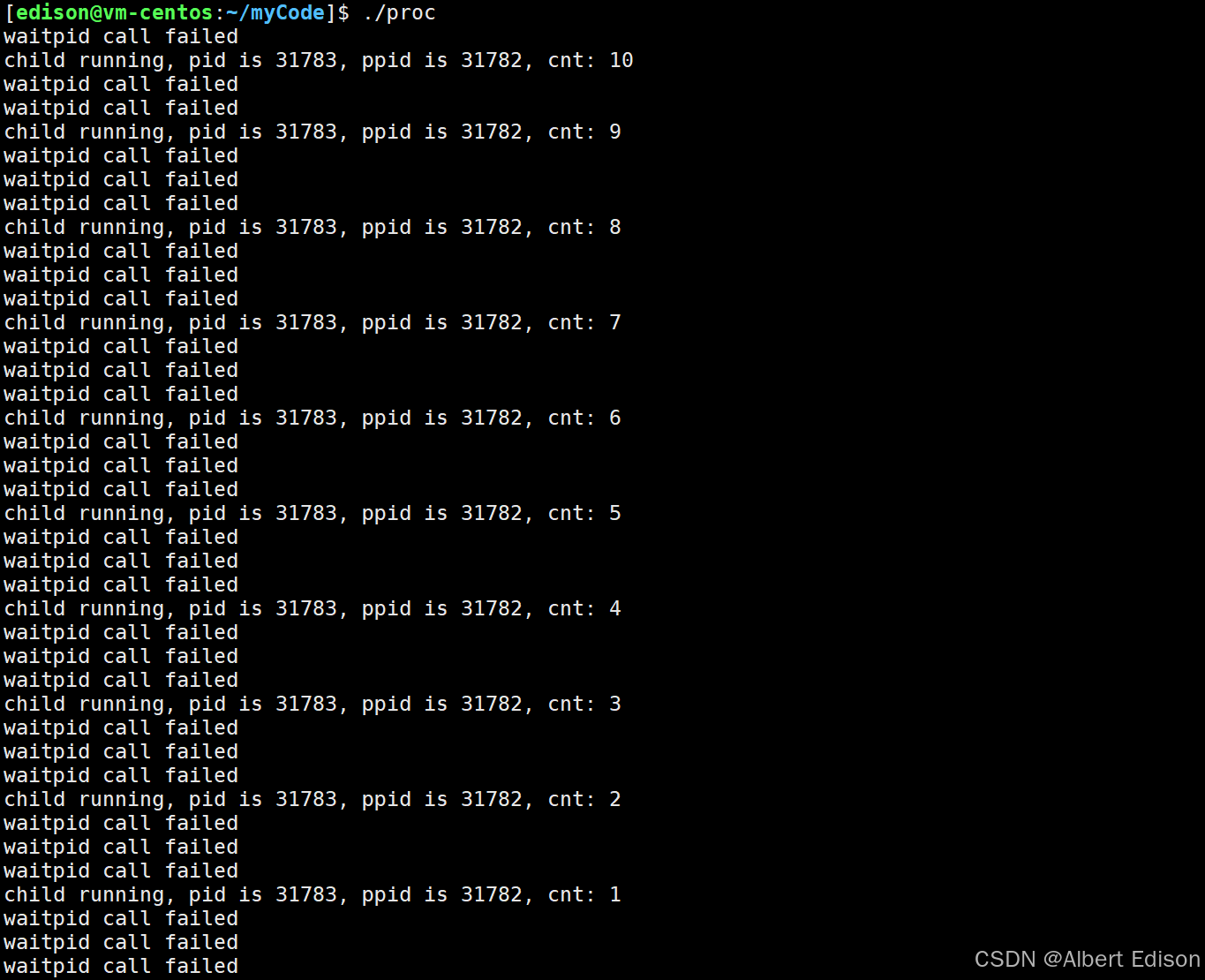
现在我故意把这个子进程的 PID 写错了,此时这个父进程要等的这个子进程不是它的,可以看到这里的父进程它一直打的就是调用失败:
我们为什么需要非阻塞等待?它的优势体现在哪里?
回到之前的例子:张三给李四打电话后,如果李四尚未就绪,张三不会一直干等着。他可以在楼下自由活动,比如:看看手机消息、与旁人闲聊几句,甚至掏出《C和指针》研读一番。这种处理方式在计算机领域被称为非阻塞等待。
非阻塞等待的核心优势在于:它不会让父进程陷入 “停滞” 状态。父进程在等待子进程的过程中,完全可以并行处理其他任务。这种 “一心多用” 的能力,使得系统资源得到更高效的利用。
这种模式在需要同时处理多个任务的程序中尤为重要。例如,服务器程序可以在等待子进程处理特定请求的同时,继续响应其他客户端的连接请求,从而显著提升系统的并发处理能力。
那么我们可以通过函数指针数组和非阻塞等待,展示如何在 Linux C 中实现轻量级的任务调度系统,代码如下:
#define NUM 10typedef void (*func_t)(); // func_t 是一个函数指针类型,指向「无参数、返回值为 void 的函数」。func_t handlerTask[NUM];// 任务1
void task1()
{printf("handle task 1\n");
}// 任务2
void task2()
{printf("handle task 2\n");
}// 任务3
void task3()
{printf("handle task 3\n");
}// 任务4
void task4()
{printf("handle task 4\n");
}void loadTask()
{memset(handlerTask, 0, sizeof(handlerTask));handlerTask[0] = task1;handlerTask[1] = task2;handlerTask[2] = task3;
}int main()
{pid_t id = fork();assert(-1 != id);if (0 == id){// childint cnt = 10;while (cnt){printf("child running, pid is %d, ppid is %d, cnt: %d\n", getpid(), getppid(), cnt--);sleep(1);}exit(111); }loadTask();// parentint status = 0;while (1){pid_t ret = waitpid(id, &status, WNOHANG); // WNOHANG: 非阻塞 --> 子进程没有退出, 父进程检测之后, 立即返回if (ret == 0){// waitpid调用成功 && 子进程没有退出// 子进程没有退出, 我的waitpid没有等待失败, 仅仅是检测到了子进程没退出.printf("wait done, but child is running...parent running other things\n");for (int i = 0; handlerTask[i] != NULL; ++ i){handlerTask[i](); // 采用回调的方式, 让父进程在空闲的时候执行其它任务}}else if (ret > 0){// 1. 等待成功 --> waitpid调用成功, 并且子进程退出了printf("wait successful, exit code: %d, signal code: %d\n", (status >> 8)&0xFF, status & 0x7F);break;}else {// waitpid调用失败printf("waitpid call failed\n");break;}sleep(1);}return 0;
}
运行结果:
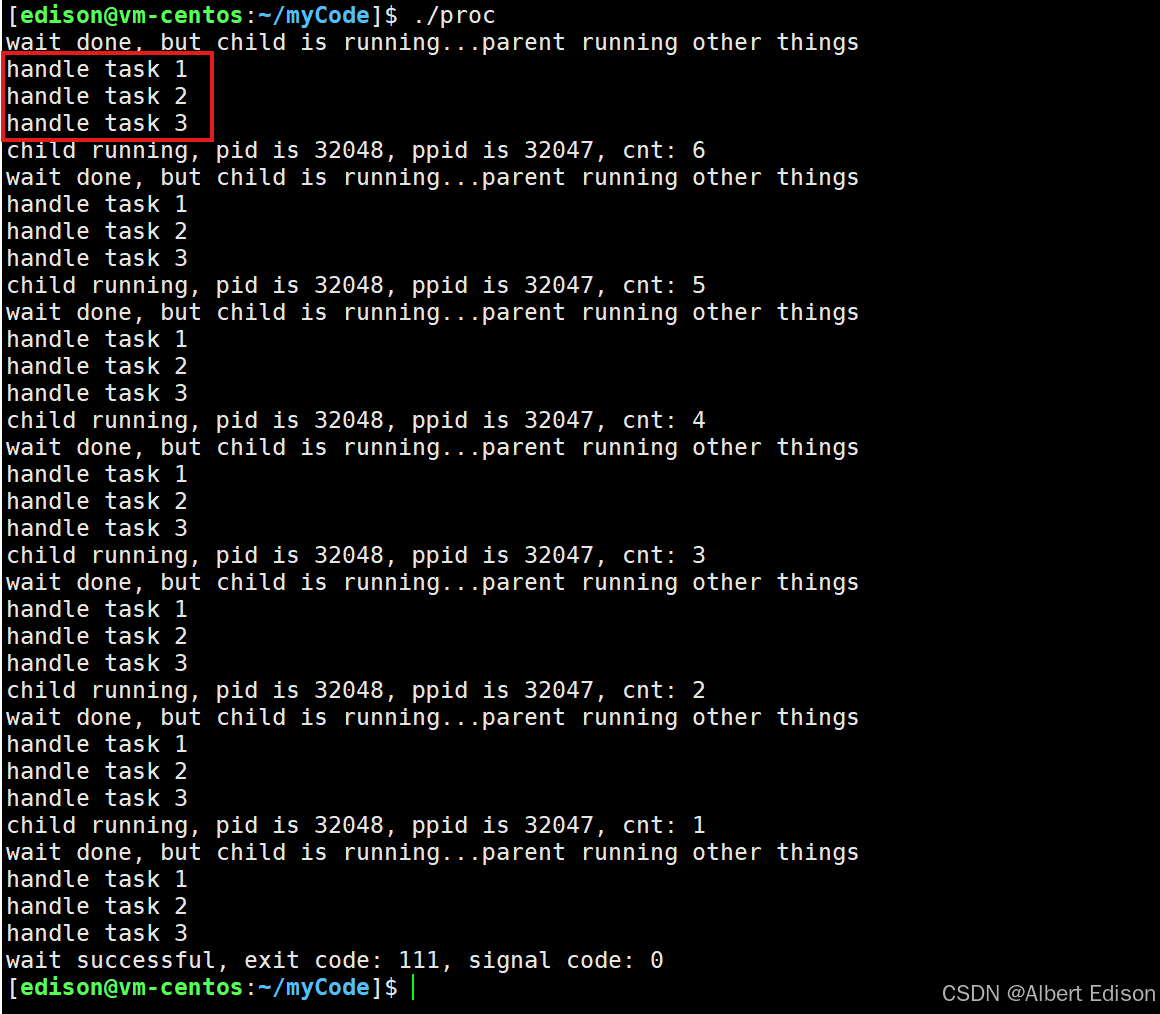
这种设计模式在服务器编程中很常见,可以在等待 IO 操作的同时继续处理其他任务,提高系统并发能力。
🍎 总结
定义:
- 进程等待是操作系统提供的一种同步机制,通过
wait/waitpid等系统调用,允许父进程获取子进程的运行状态并回收其资源。
核心目的:
- 资源回收:释放子进程结束后残留的僵尸进程(Zombie Process)
- 状态获取:获取子进程的退出状态码(exit status)或终止信号(termination signal)
实现方式:
// 阻塞式等待:父进程暂停直到子进程退出
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, 0);// 非阻塞式等待:立即返回并继续执行父进程
pid_t waitpid(pid_t pid, int *status, WNOHANG);
- 阻塞模式:父进程挂起直到子进程状态变更
- 非阻塞模式:通过轮询机制周期性检查子进程状态
- 状态解析:使用
WIFEXITED/WEXITSTATUS等宏解析返回值
典型应用场景:
- 多进程服务器程序的子进程管理
- 任务调度系统中的异步任务监控
- 需要精确控制子进程生命周期的应用
4. 进程程序替换
🍑 替换原理
创建子进程的目的是什么呢?
- 其一,是希望子进程执行父进程对应的磁盘代码中的一部分,也就是执行父进程代码的一部分。
- 其二,是想让子进程加载磁盘上指定的程序,执行新程序的代码和数据,这其实就是所谓的进程的程序替换,相当于让子进程去执行一个全新的程序。
故原理如下:
用 fork 创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种
exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。
需要注意的是,调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。
🍑 图解分析
程序正常运行时,进程会经历 CPU 调度并持续执行,期间会访问自身的数据和代码。而当调用 exec 系列函数时,系统会执行程序替换操作。具体来说,就是将指定可执行程序的代码和数据加载到物理内存中,覆盖当前进程原本映射在内存中的代码和数据。必要情况下,系统还会重新修改页表,以确保地址映射的准确性。
这种将磁盘中的程序数据加载到物理内存指定位置,并替换掉原有内容的操作,就是程序替换的本质。这里的 “指定位置”,指的是当前进程在内存中原本存放代码和数据的区域。
由此我们可以思考一个问题:进程替换过程中是否创建了新的进程?答案是否定的。
程序替换只是用新程序的代码和数据取代了当前进程的原有内容,整个过程中进程的 PID 保持不变,并没有创建新的进程实体。新程序依然在原进程的上下文中运行,只是执行的代码和操作的数据发生了改变。
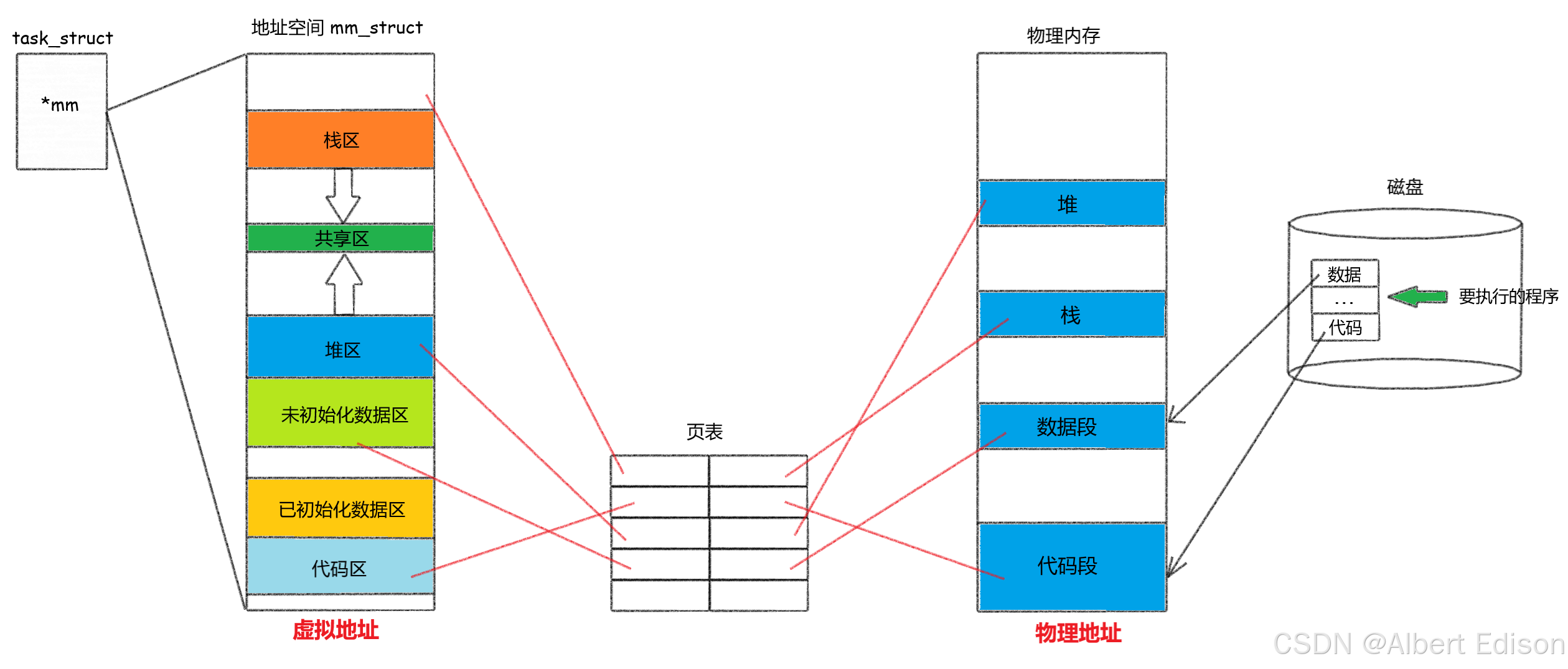
🍑 替换函数
其实有六种以 exec 开头的函数,统称为 exec 函数:
#include <unistd.h>int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
🍑 函数解释
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回;如果调用出错则返回 -1。
所以 exec 函数只有出错的返回值而没有成功的返回值。
🍑 命名理解
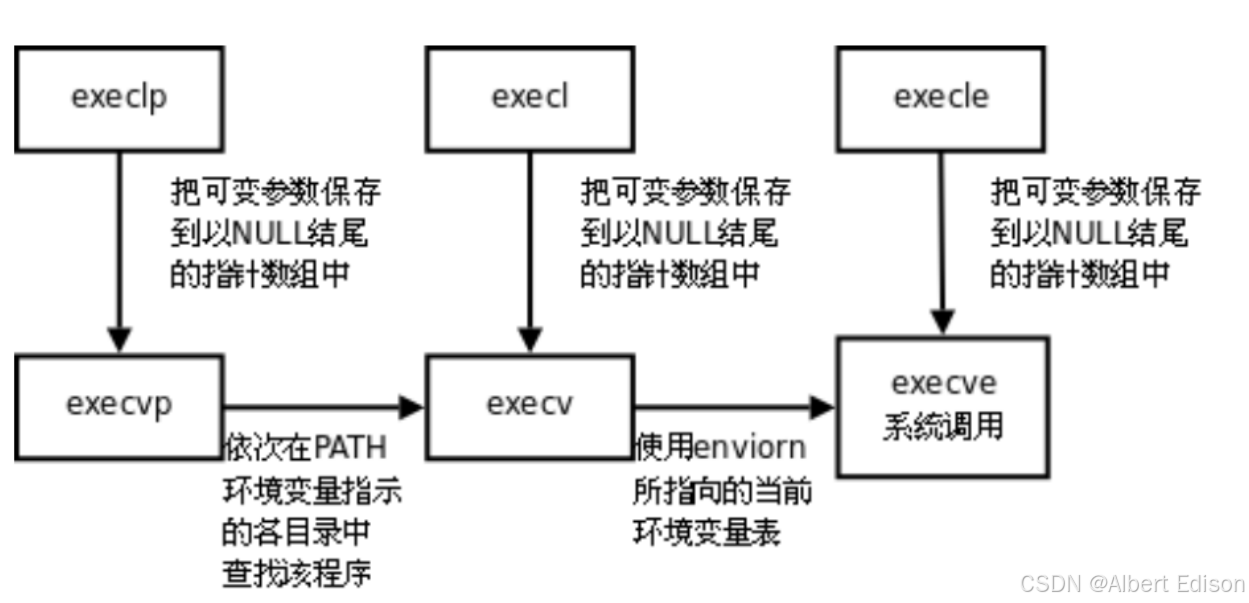
这些函数原型看起来很容易混,但只要掌握了规律就很好记:
- l(list):表示参数采用列表
- v(vector):参数用数组
- p(path):有 p 自动搜索环境变量 PATH
- e(env):表示自己维护环境变量
如下:
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 不是 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 不是 | 不是,须自己组装环境变量 |
| execv | 数组 | 不是 | 是 |
| execvp | 数组 | 是 | 是 |
| execve | 数组 | 不是 | 不是,须自己组装环境变量 |
下面我们分别来使用一下这些接口。
🍎 execl
函数原型
int execl(const char *path, const char *arg, ...);
参数说明
path:要执行的程序的绝对路径或相对路径(相对于当前工作目录)。例如:"/usr/bin/ls"。arg:传递给新程序的第一个参数,通常是程序名本身(与 argv[0] 对应)。例如:"ls"。...:可变参数列表,后续参数为传递给新程序的命令行参数(以 NULL 结尾)。例如:"-l", "-a", NULL。
返回值
- 成功:不返回(原进程的代码段、数据段等被新程序完全替换)。
- 失败:返回 -1,并设置 errno(如文件不存在、权限不足等)。
代码示例:
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// child// 类比: 命令行怎么写, 这里就怎么传execl("/usr/bin/ls", "ls", "-a", "-l", "--color=auto", NULL);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
使用进程替换来执行 ls 命令,此时父进程等待成功就得到了退出结果,运行之后可以看到退出码和推出信号也是没问题的。
注意这个退出结果是子进程执行 ls 的执行结果。(执行成功,所以它是 0)
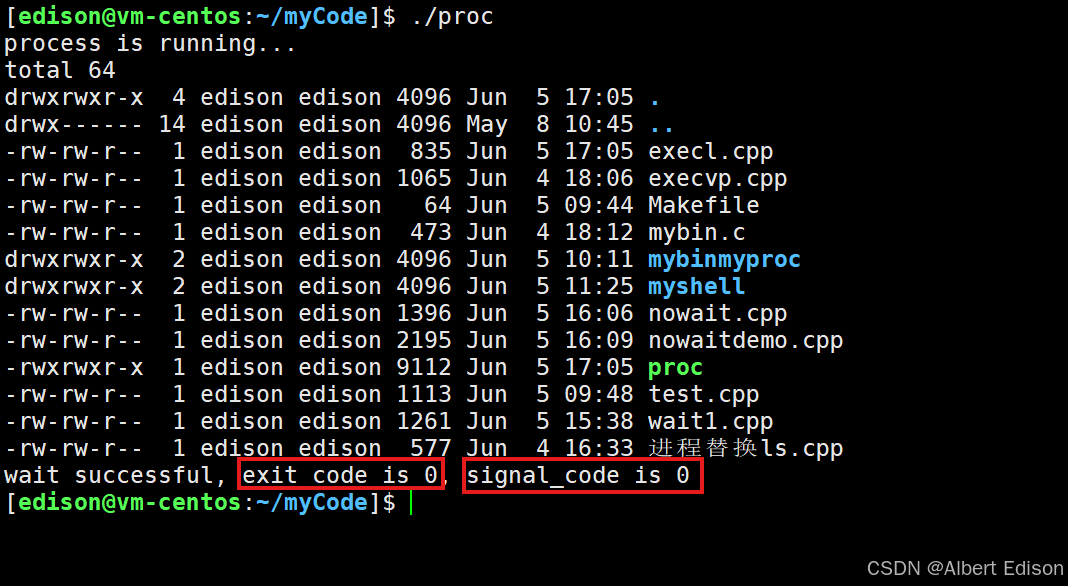
再对代码进行修改:
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// child// 类比: 命令行怎么写, 这里就怎么传execl("/usr/bin/lsedison", "ls", "-a", "-l", "--color=auto", NULL);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
运行以后可以看到此时退出码就为 1 了,exec 执行成功是没有返回值的,因为成功了就和接下来的代码无关了,那么返回值也就毫无意义,故 exec 只要是有返回值了,那么一定是代码出错了!
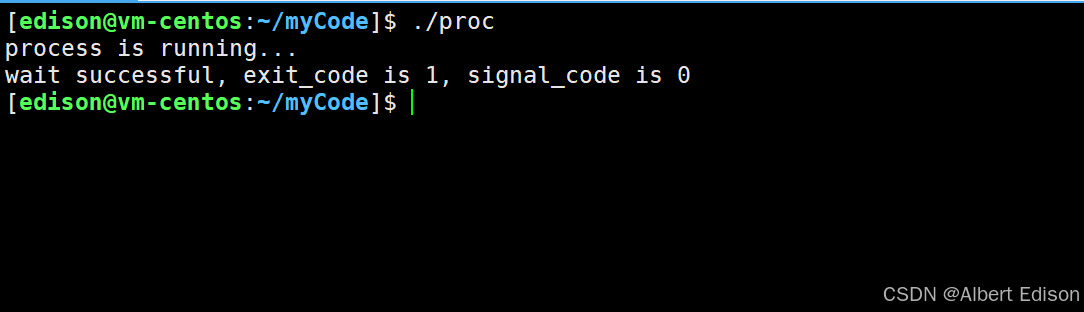
思考一下:子进程里面的程序替换会影响父进程吗?答案是不会!因为进程具有独立性!
那么它如何保证独立性呢?它是怎么做到替换的时候不影响父进程呢?
此时进入到原理二,如下图所示:
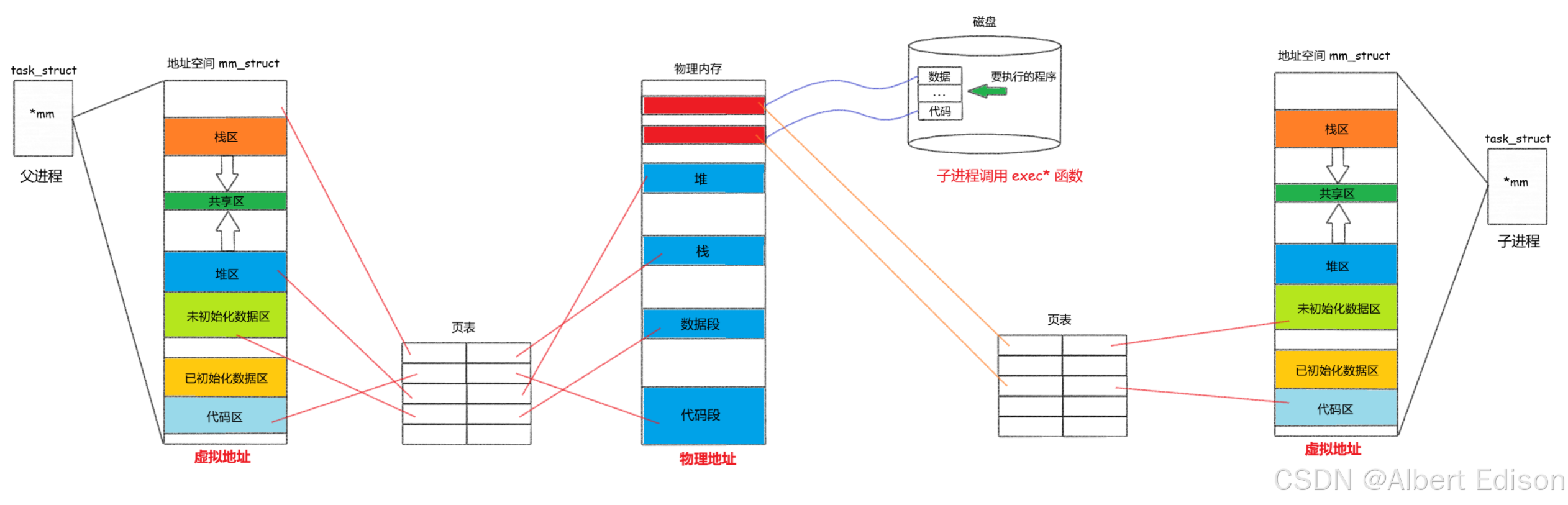
父进程在运行期间会执行自己的代码。当子进程调用exec系列函数进行程序替换时,本应将新程序的代码和数据覆盖到内存中。但由于进程具有独立性,子进程不能直接修改父进程的数据段。
当操作系统检测到子进程要执行程序替换时,会进行写时拷贝操作:在物理内存中为子进程分配新的空间,将待执行程序的代码和数据加载到这块新空间,并重新建立页表映射。这样一来,子进程运行的是全新的程序,而父进程的代码和数据不受影响。
进程的独立性由虚拟地址空间和页表机制共同保障。当某个执行流(如子进程)试图替换代码或数据时,系统会触发写时拷贝。过去我们常说数据会发生写时拷贝,实际上代码也可能发生写时拷贝——程序替换就是典型场景。
举个例子,子进程原本可能执行父进程代码中的 else 分支。但当它调用 exec 进行程序替换后,就会彻底脱离父进程的代码逻辑,转而执行全新的程序。整个替换过程中,子进程的 PID 保持不变,但执行的内容已完全更新。
🍎 execlp
函数原型
int execlp(const char *file, const char *arg, ...);
参数说明
file:要执行的程序名(无需完整路径)。例如:"ls"。- 注意:系统会自动在 PATH 环境变量指定的目录中搜索该程序。
arg:传递给新程序的第一个参数,通常是程序名本身(对应 argv[0])。例如:"ls"。...:可变参数列表,后续参数为传递给新程序的命令行参数(以 NULL 结尾)。例如:"-l", "-a", NULL。
代码实现
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// child execlp("ls", "ls", "-a", "-l", "--color=auto", NULL);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
运行结果:
🍎 execv
函数原型
int execv(const char *path, char *const argv[]);
参数说明
path:要执行的程序的绝对路径或相对路径(相对于当前工作目录)。例如:"/bin/ls"。argv:传递给新程序的参数数组,类型为char *const [],必须以NULL指针结尾。数组的第一个元素argv[0]通常是程序名本身(与命令行调用方式一致)。
代码实现
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// childchar *const argv[] = { "ls", "-a", "-l", "--color=auto", NULL };execv("/usr/bin/ls", argv);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
运行结果:
🍎 execvp
函数原型
int execvp(const char *file, char *const argv[]);
参数说明
file:要执行的程序名(无需完整路径)。例如:"ls"。- 注意:系统会自动在 PATH 环境变量指定的目录中搜索该程序。
argv:传递给新程序的参数数组,类型为char *const [],必须以NULL指针结尾。- 数组的第一个元素
argv[0]通常是程序名本身(与命令行调用方式一致)。
- 数组的第一个元素
代码实现
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// childchar *const argv[] = { "ls", "-a", "-l", "--color=auto", NULL };execvp("ls", argv);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
运行结果:
🍎 用 test.c 去调用 mybin.c
上面所有的话题都在执行系统命令,如果我想执行我自己写的程序呢?比如用 test.c 去调用 mybin.c?
其实也很简单,代码如下
// test.c
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// childexecl("./mybin", "mybin", NULL);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}// mybin.c
int main()
{printf("这是另一个 C 程序\n");return 0;
}
同时我们还要把 Makefile 修改一下:
.PHONY:all
all: mybin myproc mybin:mybin.cg++ -o $@ $^
myproc:test.cppg++ -o $@ $^
.PHONY:clean
clean:rm -f myproc mybin
运行结果:
同意,可以使用程序替换调用任何后端语言对应的可执行程序。
🍎 execle
函数原型
int execle(const char *path, const char *arg, ..., char * const envp[]);
参数说明
path:要执行的程序的绝对路径或相对路径(相对于当前工作目录)。例如:"/bin/ls"。arg:传递给新程序的第一个参数,通常是程序名本身(对应argv[0])。例如:"ls"。...:可变参数列表,后续参数为传递给新程序的命令行参数(以NULL结尾)。例如:"-l", "-a", NULL。envp:自定义环境变量数组,类型为char *const [],必须以NULL指针结尾。每个元素格式为"NAME=VALUE"(如"PATH=/usr/bin")。
test.c 代码如下:
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// childchar* const envp[] = { (char*)"MYENV=12345678", NULL }; execle("./mybin", "mybin", NULL, envp); // 自定义环境变量exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
mybin.c 代码如下:
int main()
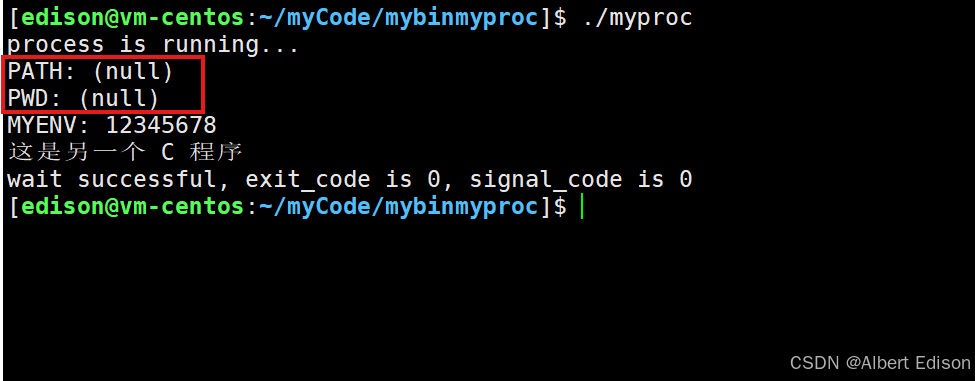
{printf("PATH: %s\n", getenv("PATH"));printf("PWD: %s\n", getenv("PWD"));printf("MYENV: %s\n", getenv("MYENV"));printf("这是另一个 C 程序\n"); return 0;
}
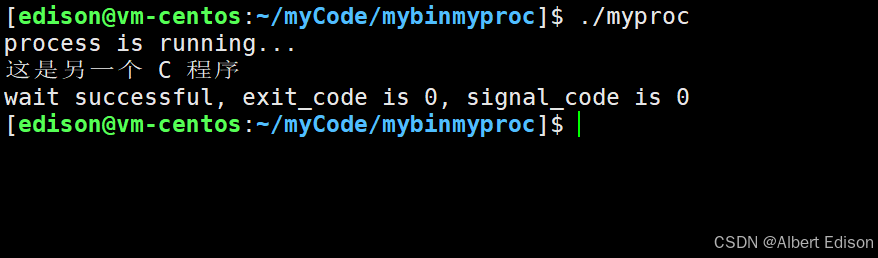
可以看到,当我们使用系统的环境变量的时候,会发现程序识别不到我们自定义的环境变量:
很简单,我们把设置一下系统的环境变量即可:
// 修改子进程中的部分代码
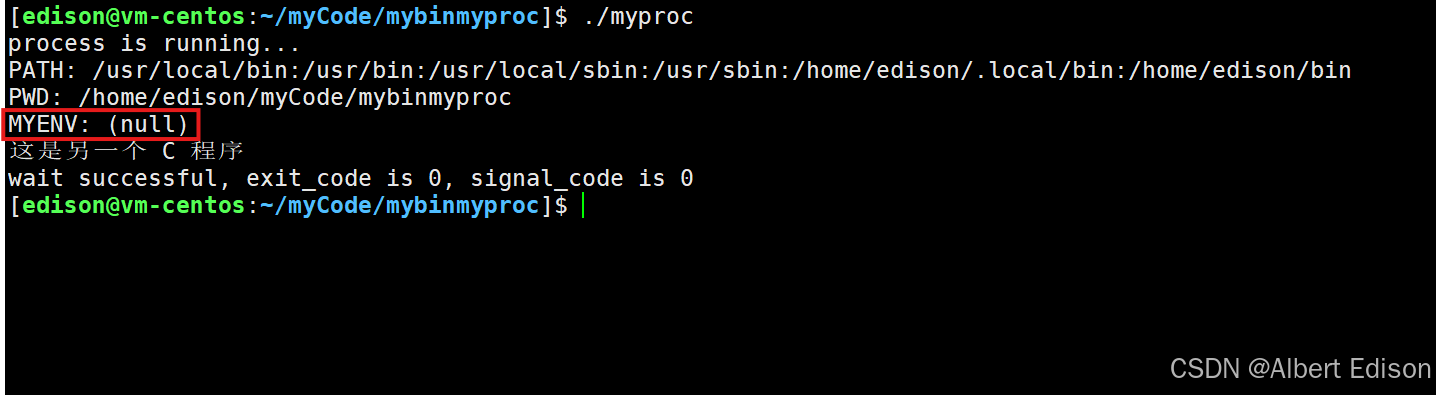
if (0 == id){sleep(1);// childextern char **environ;char* const envp[] = { (char*)"MYENV=12345678", NULL };execle("./mybin", "mybin", NULL, environ);exit(1); // exec一定出错了}
运行以后发现,自定义的环境变量又无法识别了:
那如果我既想要有系统的环境变量,又想把我自定义环境变量也导进去,如何实现呢?
需要使用 putenv 函数,它的作用是,把你所传入的环境变量导到系统当中,说白了,导到系统当中就是把它添加到这个指针所指向的环境变量表里面。
代码实现
// 修改子进程中的部分代码
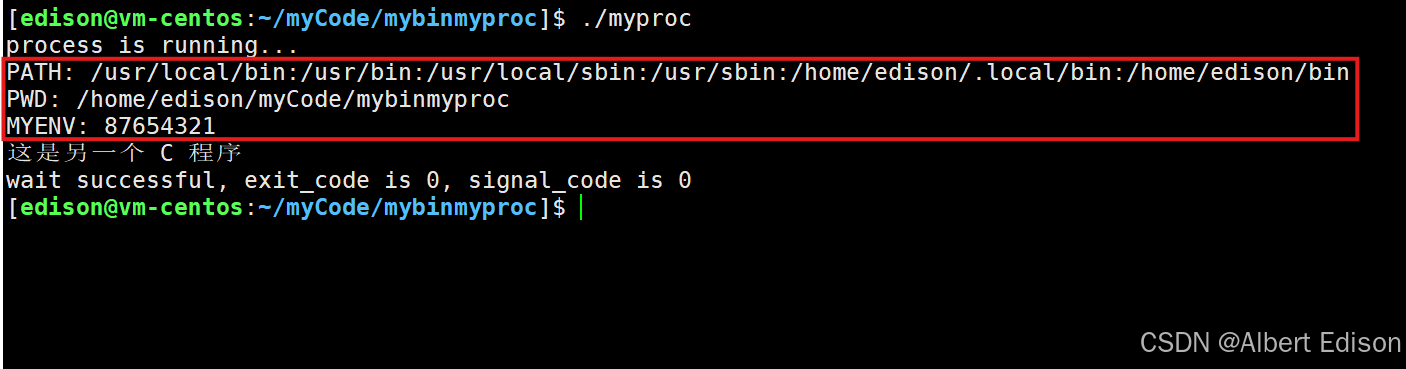
if (0 == id){sleep(1);// childextern char **environ;putenv((char*)"MYENV=87654321"); // 将指定环境变量导入到系统中environ指向的环境变量表中execle("./mybin", "mybin", NULL, environ);exit(1); // exec一定出错了}
可以看到此时都能够识别出来了:
🍎 execve
这个接口和前面所讲的 5 个接口不同,这才是真正的执行程序替换的系统调用接口,而上面那些接口都是基于系统调用(该接口)做的封装。
所以 execve 在 man 手册第 2 节,其它函数在 man 手册第 3 节。
int execve(const char *filename, char *const argv[], char *const envp[]);
代码实现
int main()
{printf("process is running...\n");pid_t id = fork();assert(id != -1);if (0 == id){sleep(1);// childchar *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};char *const argv[] = {"ps", "-ef", NULL};execve("/usr/bin/ps", argv, envp);exit(1); // exec一定出错了}// fatherint status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0) // 等待成功{printf("wait successful, exit_code is %d, signal_code is %d\n", (status >> 8)&0xFF, status & 0x7F);}
}
运行结果:
🍎 总结
如下图所示,是 exec 函数族的完整的例子:
5. 手动实现一个简易的 Shell
我们可以考虑下面这个与 shell 的互动场景:
用下图的时间轴来表示事件的发生次序。其中时间从左向右。shell 由标识为 sh 的方块代表,它随着时间的流逝从左向右移动。shell 从用户读入字符串 "ls"。shell建立一个新的进程,然后在那个进程中运行 ls 程序并等待那个进程结束。
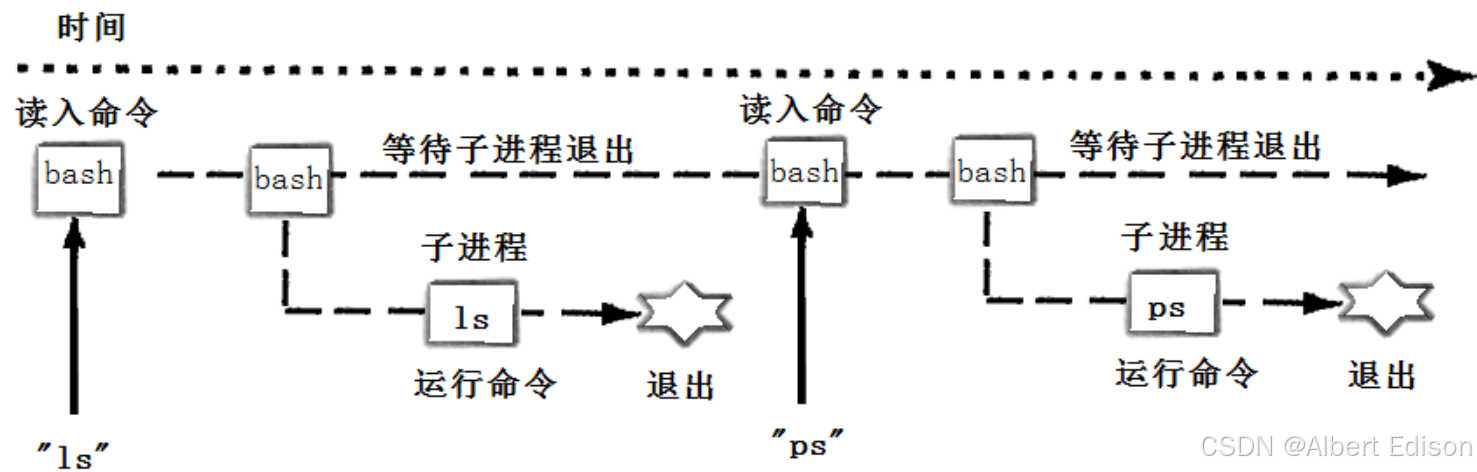
然后 shell 读取新的一行输入,建立一个新的进程,在这个进程中运行程序并等待这个进程结束。 所以要写一个 shell,需要循环以下过程:
- 获取命令行
- 解析命令行
- 建立一个子进程(fork)
- 替换子进程(execvp)
- 父进程等待子进程退出(wait)
根据这些思路,和我们前面的学的技术,就可以自己来实现一个 shell 了。
代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <string.h>#define NUM 1024
#define OPT_NUM 64char lineCommand[NUM];
char *myargv[OPT_NUM]; // 指针数组
int lastCode = 0;
int lastSignal = 0;int main()
{while (1){// 1. 输出提示符printf("[edison@vm-centos:~]# ");fflush(stdout); // 上面的printf没有加'\n', 所以要用fflush刷新缓冲区// 2. 获取用户输入(输入的时候,自己会按回车, 相当于输入了'\n') char *s = fgets(lineCommand, sizeof(lineCommand) - 1, stdin);assert(NULL != s);(void)s;// 清楚最后一个'\n'lineCommand[strlen(lineCommand) - 1] = 0; // 把最后一个元素'\n'赋值为0//printf("%s\n", lineCommand);// 3. 字符串切割myargv[0] = strtok(lineCommand, " ");int i = 1;if (myargv[0] != NULL && strcmp(myargv[0], "ls") == 0) // 给ls命令添加颜色{myargv[i++] = (char*)"--color=auto";}// 如果没有字串了, strtok会返回NULL, 也就是myargv[end] = NULL //int i = 1;while (myargv[i ++] = strtok(NULL, " ")){// 测试是否成功;}// 判定如果是cd命令, 则不需要创建子进程, 直接让shell自己执行对应的命令// 其实本质就是执行系统接口// 像这种不需要让我们的子进程来执行, 而是让shell自己执行的命令, 称之为: 内建/内置命令if (myargv[0] != NULL && strcmp(myargv[0], "cd") == 0){if (myargv[1] != NULL){chdir(myargv[1]);}continue;}// if (myargv[0] != NULL && myargv[1] != NULL && strcmp(myargv[0], "echo") == 0){if (strcmp(myargv[1], "$?") == 0){printf("ExitCode: %d, SignalCode: %d\n", lastCode, lastSignal);}else {printf("%s\n", myargv[1]);}continue;}// 测试是否成功(条件编译)
#ifdef DEBUG for (int i = 0; myargv[i]; i ++){printf("myargv[%d]: %s\n", i, myargv[i]);}
#endif// 4. 执行命令pid_t id = fork();assert(-1 != id);if (id == 0){// child --> 执行程序替换execvp(myargv[0], myargv);exit(111);}// parentint status = 0;pid_t ret = waitpid(id, &status, 0);assert(ret > 0);(void)ret;lastCode = (status >> 8) & 0xFF; // 退出码lastSignal = (status & 0x7F); // 退出信号}return 0;
}
运行以后可以看到基本的 Linux 命令已经完全实现了:
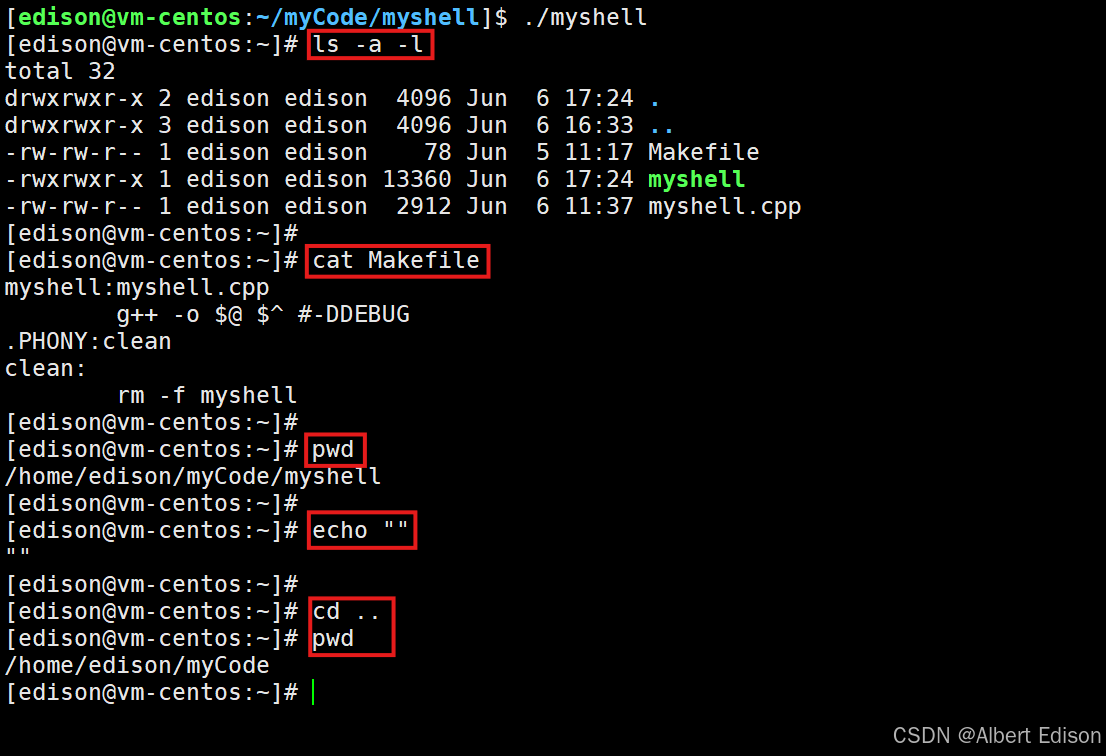
🍑 函数和进程之间的相似性
我们的 exec/exit 就像 call/return 一样,一个 C 程序有很多函数组成,而一个函数可以调用另外一个函数,同时传递给它一些参数。被调用的函数执行一定的操作,然后返回一个值,每个函数都有它的局部变量,不同的函数通过 call/return 系统进行通信。
这种通过参数和返回值,在拥有私有数据的函数间通信的模式,是结构化程序设计的基础。Linux 鼓励将这种应用于程序之内的模式扩展到程序之间。
如下图所示:
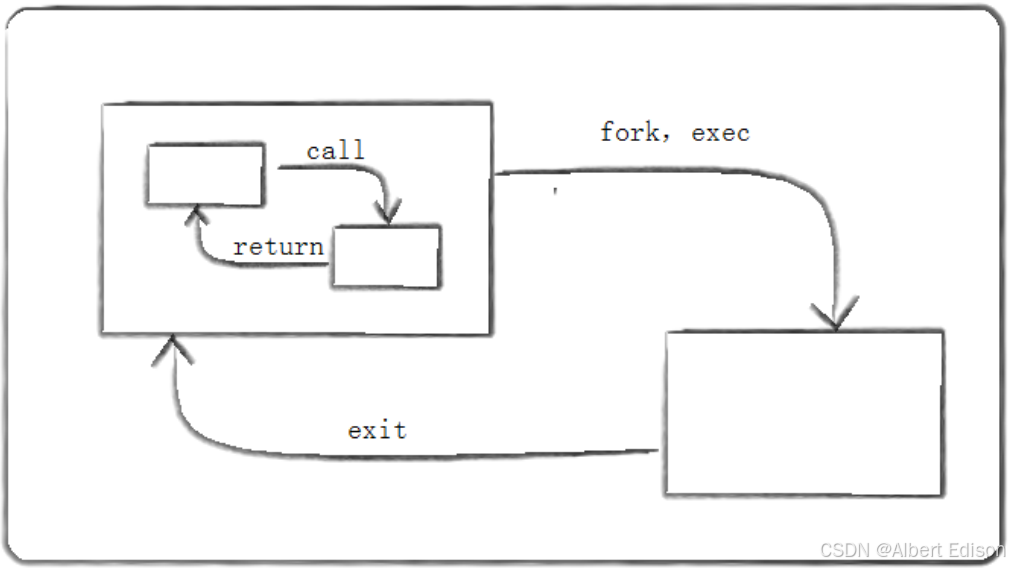
一个 C 程序可以 fork/exec 另一个程序,并传给它一些参数。这个被调用的程序执行一定的操作,然后通过 exit(n) 来返回值。调用它的进程可以通过 wait(&ret) 来获取 exit 的返回值。