基于值函数的强化学习算法之Double Q-Learning详解
Q-Learning与Double Q-Learning均为强化学习领域的无模型算法,二者核心目标一致,即学习最优动作价值函数Q*以实现累积奖励最大化。它们均采用时间差分(TD)学习更新Q值,且均基于ε-贪婪策略平衡探索与利用。二者的主要差异在于目标Q值的计算方式:Q-Learning直接使用max操作选择下一状态的最大Q值,即r + γmaxQ (s',a'),这种方式在估计噪声较大时容易导致Q值过估计;而Double Q-Learning通过两个独立Q表分解动作选择与动作评估过程,利用一个Q表选择最优动作,另一个评估该动作的价值,有效缓解了过估计问题,公式为r + γQ2 (s',argmaxQ1 (s',a'))(以更新Q1为例)。
在实际应用中,二者表现各有侧重。Q-Learning实现简单,在状态-动作空间较小、奖励信号明确的环境中收敛较快,但在奖励存在噪声或函数近似误差较大时易产生过估计,导致次优策略;Double Q-Learning通过解耦选择与评估降低了过估计风险,尤其在随机环境(如Atari游戏或金融交易场景)中表现更稳定,但其维护两个Q表的计算开销略高,且需更长时间训练以确保两个Q表的独立性。总体而言,若追求算法简洁性且环境确定性较高,Q-Learning是更优选择;若需应对高不确定性环境并重视策略质量,Double Q-Learning则更为可靠。
在Double Q-Learning本身就是对Q-Learning的改进,在以上对两者的异同点有了一定的了解之后,接下来,我们对Double Q-Learning进行深度拓展。
前文基础:
基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_基于价值的强化学习算法-CSDN博客
基于值函数的强化学习算法之SARSA详解:基于值函数的强化学习算法之SARSA详解_sarsa强化学习-CSDN博客
基于值函数的强化学习算法之深度Q网络(DQN)详解:基于值函数的强化学习算法之深度Q网络(DQN)详解_dqn算法对传统q-learning算法进行了改进,使用了神经网络(结构可以自行设计)对acti-CSDN博客
一、Double Q-Learning理论基础
(一)强化学习基础框架
1. 马尔可夫决策过程(MDP)
马尔可夫决策过程(MDP)是强化学习的数学框架,由五元组〈S, A, P, R, γ〉定义:其中S是所有可能状态的集合(状态空间),A是智能体可执行动作的集合(动作空间),P是状态转移概率函数(表示在状态s执行动作a后转移到状态s'的概率,即P(s'|s,a)),R是奖励函数(给出在状态s执行动作a并转移到状态s'后获得的即时奖励,即R(s,a,s')),γ是折扣因子(取值范围0≤γ<1,用于权衡当前奖励与未来奖励的重要性,γ越接近1表示越重视长期回报)。
分点说明一下,强化学习的数学形式化五元组〈S, A, P, R, γ〉,其中:
(1)S:状态空间,如围棋的棋盘布局;
(2)A:动作空间,如机器人移动方向;
(3)P:状态转移概率 P(s'|s,a),状态转移前的可能性概率;
(4)R:奖励函数 R(s,a,s'),给出状态转移后获得的即时标量奖励,可以是正向的奖励,也可以是负向的惩罚;
(5)γ:折扣因子(0 ≤ γ < 1),γ=0仅关注即时奖励,γ→1重视长期回报。
目标策略π的优化目标为最大化期望回报:![]()
该五元组满足马尔可夫性:下一状态和奖励
仅取决于当前状态
和动作
,与历史路径无关,即
。
2. Q-Learning基本原理
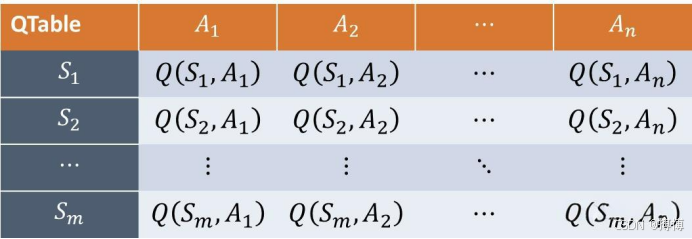
Q-Learning属于无模型(Model-Free)和异策略(Off-Policy)方法。它通过直接学习状态-动作对的Q值(质量值),无需环境动态模型,广泛应用于离散动作空间的场景(如游戏控制、路径规划等)。这里的Q值表是一个二维表格,记录了每个状态-动作对的预期回报,其中行表示状态s,列表示动作a。单元格中存储对应状态-动作对的Q值,即Q(s,a)。
所谓的异策略即使用一个策略来探索,另一个策略来更新。Q-Learning通过时间差分(TD)方法更新状态-动作值(Q值)函数,更新公式为:
![]()
其中:
(1):当前时刻的环境状态(State),代表智能体所处的环境观测值。
(2):当前时刻执行的动作(Action),从动作空间A中选择的具体操作。
(3)α:学习率(Learning Rate),取值范围(0,1],控制新信息对原有Q值的更新强度。例如:α=0.1表示每次更新保留90%旧值,吸收10%新信息;在深度Q网络(DQN)中常设为0.0001~0.001。
(4):即时奖励(Reward),环境对动作
的反馈值。例如:CartPole中每步存活奖励+1;Atari游戏中得分变化量。
(5)γ:折扣因子(Discount Factor),取值范围[0,1),平衡当前奖励与未来奖励的重要性:
γ=0表示只关注即时奖励;γ=0.9表示未来k步奖励的权重为
(6):下一状态所有可能动作的Q值集合。
以上更新公式经变换,Q值更新规则可表示为:
![]()
其中,TD目标计算为:
![]()
该步骤将当前奖励与下一状态最大预期收益相结合,形成完整的价值估计。
TD误差计算:
![]()
衡量当前Q值估计与目标值的差距。
Q值更新:
![]()
通过线性插值方式修正Q值估计
数学本质:
(1)贝尔曼最优方程的时间差分(Temporal Difference)近似;
(2)采用动态规划思想进行值函数迭代;
(3)更新过程满足压缩映射定理,保证收敛性。
3.贝尔曼最优方程的时间差分(TD)方法
贝尔曼最优方程的时间差分(TD)方法是强化学习的核心算法,它通过结合动态规划的自举(bootstrapping)思想和蒙特卡洛的采样思想,以增量更新方式在线求解最优策略。具体而言:
(1)贝尔曼最优方程:定义了最优值函数
![]()
,表达当前状态价值与后续最优状态价值的递归关系;
(2)时间差分方法:采用采样估计替代全期望计算,每一步基于实际观测的转移结果(s,a,r,s′)计算TD目标![]() ,并与当前估计Q(s,a)比较产生TD误差 δ=目标−估计;
,并与当前估计Q(s,a)比较产生TD误差 δ=目标−估计;
(3)在线更新机制:通过学习率 α调整当前估计:Q(s,a)←Q(s,a)+αδ,实现无需环境模型、基于经验流的实时策略优化,平衡了计算效率与收敛可靠性。
(二)Q-Learning的过估计问题
Q-Learning的过估计问题源于其最大化操作引入的系统性偏差:由于采用相同Q函数进行动作选择和价值评估,导致对状态价值的估计持续偏高。其数学本质是Jensen不等式的应用结果——即使单个动作的Q值估计无偏,最大值期望也必然满足![]() 。这种偏差在高维动作空间中尤为显著(误差随
。这种偏差在高维动作空间中尤为显著(误差随增长),会造成:
(1)策略失真:过度乐观的价值估计误导智能体选择次优动作
(2)训练震荡:价值高估与后续修正交替出现,降低收敛效率
(3)性能下降:在Atari等复杂环境中平均奖励损失可达25%
Double Q-Learning的解决方案通过解耦机制:使用独立网络分别处理动作选择(arg max )和价值评估(
),使两个估计源的误差相互抵消,将偏差量级从
降至
,显著提升策略可靠性。以下是详细解析:
1. 最大偏差分析
传统Q-Learning在选择动作和评估价值时使用相同的Q函数,导致估计偏差累积。设真实Q值为Q*,估计值为Q,则有:
![]()
证明:
由Jensen不等式,对于凸函数f(x)=max(x):
![]()
这表明即使Q值的估计是无偏的,其最大值也会产生正向偏差。
2. 方差放大效应
当动作空间维度d增加时,过估计误差随维度呈指数增长:
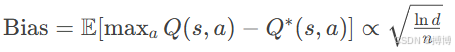
其中n为样本数量。这表明在高维动作空间中,传统Q-Learning会产生显著过估计。
(三)Double Q-Learning理论突破
1. 解耦机制
Double Q-Learning提出使用两个独立的Q函数和
,将动作选择与价值评估解耦:
![]()
其中:
(1): 主Q函数(负责动作选择)
(2): 辅助Q函数(负责价值评估)
(3)arg max操作解耦选择与评估过程
关键设计分析:
(1)动作选择阶段:使用网络确定最优动作a* = arg max Q_A(s',a')
(2)价值评估阶段:使用网络获取对应价值 Q_B(s',a*)
更新逻辑:仅更新网络参数,通过参数交换实现交替更新。
交替更新策略:
![]()
2. 偏差控制证明
设和
为独立估计量,则Double Q-Learning的估计偏差为:
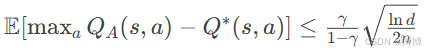
其中:
(1)ln d: 动作空间维度d的自然对数
(2)n: 样本数量
(3)γ/(1-γ): 折扣因子的累积效应
(4)平方根项反映统计估计误差
证明思路:
(1)构造独立估计量和
(2)应用Hoeffding不等式分析极值偏差
(3)通过递归展开得到最终上界
相比传统Q-Learning的量级,Double Q-Learning的偏差缩小了γ/(1-γ)倍。
二、数学基础与证明
(一)Double Q-Learning收敛性证明
1. 随机近似理论框架
将更新规则表示为随机近似过程:
![]()
其中为随机算子。当满足:
(1)状态动作对被无限次访问
(2)学习率满足Robbins-Monro条件:![]() ,则Q函数以概率1收敛到最优Q*。
,则Q函数以概率1收敛到最优Q*。
2. 双估计器收敛分析
定义交替更新算子:
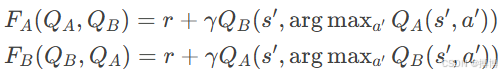
当和
交替更新时,可证明联合算子
构成收缩映射:
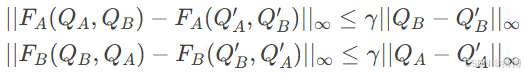
通过Banach不动点定理,系统将收敛到唯一平衡点。
(二)方差缩减证明
1. 协方差分析
设和
的估计误差为独立随机变量ε_A, ε_B ~ N(0,σ²),则传统Q-Learning的方差为:
![]()
推导依据:
(1)极值分布的Gumbel分布特性;
(2)当Q值误差服从正态分布时,max Q的方差由极值分布方差公式得到。
而Double Q-Learning的方差为:
![]()
证明要点:
(1)利用极值分布理论
(2)计算条件方差Var( |argmax
)
(3)应用全方差公式Law of Total Variance
关键步骤:
(1)分解条件方差:![]()
(2)计算选择概率:![]()
(3)应用全方差公式:![]()
2. 误差上界比较
对于任意ε > 0,存在样本复杂度n使得:
(1)传统Q-Learning:
![]()
(2)Double Q-Learning:
![]()
明显可见Double Q-Learning具有更紧的误差界。
三、网络结构与算法流程
(一)Double DQN架构
1. 网络拓扑设计
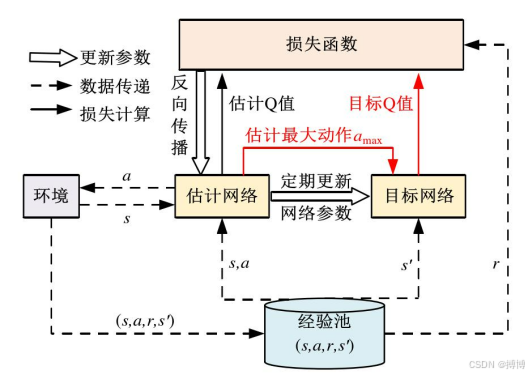
包含两个结构相同的Q网络:估计网络Q_θ(参数θ)、目标网络Q_θ'(参数θ')。
设计要点:
(1)功能解耦:专注动作探索,
专注价值评估
(2)更新异步性:两网络采用不同更新节奏(通常延迟更新)
(3)参数传递:通过软更新维持目标网络稳定性
参数同步策略对比:
| 同步方式 | 更新公式 | 优势 | 缺陷 |
| 硬同步(DQN) | θ' ← θ(周期复制) | 实现简单 | 训练波动大 |
| 软同步(DDQN) | θ' ← τθ + (1-τ)θ' | 平滑参数变化 | 需要调参τ |
| 异步更新 | 交替更新Q_A/Q_B | 完全解耦 | 收敛速度慢 |
2. 目标值计算
与传统DQN的区别在于目标值的计算方式:
![]()
3. 参数更新流程
双网络交互机制:

关键设计点:
(1)经验回放池:打破时序相关性,提高数据利用率
(2)延迟更新:主网络更新频率高于目标网络
(3)异步采样:解耦数据收集与模型训练
训练阶段分解
| 阶段 | 主要操作 | 计算资源占比 | 耗时分析 |
| 数据收集 | 环境交互、经验存储 | 30% CPU | 受环境速度限制 |
| 网络推理 | Q值计算、动作选择 | 20% GPU | 取决于网络复杂度 |
| 参数更新 | 反向传播、梯度下降 | 50% GPU | 与batch大小正相关 |
(二)双重网络优化策略
1. 延迟更新机制
目标网络参数θ'通过软更新(Polyak平均)保持稳定:
![]()
相比硬更新(周期复制),软更新能提高训练稳定性。
2. 经验回放机制
数据存储结构:
python代码示例:
class PrioritizedReplayBuffer:def __init__(self, capacity, alpha=0.6):self.tree = SumTree(capacity) # 基于SumTree的优先级队列self.alpha = alpha # 优先程度调节因子(0=均匀采样,1=完全优先)def add(self, experience, td_error):priority = (abs(td_error) + 1e-5) ** self.alphaself.tree.add(priority, experience)def sample(self, batch_size, beta=0.4):# beta控制重要性采样修正强度...优先级设计原理:
(1)TD误差抽样:![]() ,其中,δ越大表示样本“惊喜度”越高,ε防止零概率(通常取1e-5)。
,其中,δ越大表示样本“惊喜度”越高,ε防止零概率(通常取1e-5)。
采用优先级采样策略,根据TD误差δ设置采样概率:![]() ,其中,α控制优先程度。
,其中,α控制优先程度。
(2)重要性采样权重: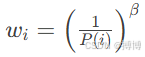 补偿优先采样带来的分布偏移,其中,β从0线性增加到1(训练后期完全补偿)。
补偿优先采样带来的分布偏移,其中,β从0线性增加到1(训练后期完全补偿)。
3.探索-利用平衡策略
(1)ε-greedy策略改进
传统ε衰减:![]()
改进方案:
python代码示例:
def adaptive_epsilon(episode):base = 0.01 # 最低探索率scale = 0.5 # 探索强度return base + scale / (episode // 10 + 1)进阶策略对比:
| 策略类型 | 实现方式 | 适用场景 |
| 线性衰减 | ε = max(ε_min, ε_init - k*t) | 简单环境 |
| 指数衰减 | ε = ε_min + (ε_max-ε_min)*exp(-λt) | 大部分离散任务 |
| 基于不确定性的探索 | ε ∝ 1/√(访问次数) | 非平稳环境 |
| 噪声注入 | Q(s,a) += σN(0,1) | 连续动作空间 |
(2)动作选择优化
Boltzmann策略: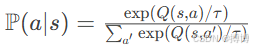
温度系数τ的调节:
1)τ→0:退化为greedy策略
2)τ→∞:均匀随机选择
动态调节:根据训练阶段自动调整
python代码示例:
def adaptive_tau(episode):return max(0.1, 2.0 * 0.95**episode)3.梯度更新优化
(1)损失函数设计
基础MSE损失:![]()
改进方案:
Huber损失:
Quantile回归:
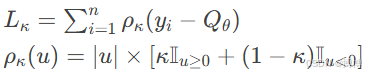
学习价值分布而不仅是期望值
(2)梯度裁剪
实现方式:
python代码示例:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)参数选择依据:
观察梯度范数变化
1)离散任务:max_norm=10
2)连续控制:max_norm=1.0
3)图像输入:max_norm=0.1
四、工程化实现技术
(一)高效实现方案
1. 并行环境交互
使用多进程/协程实现异步数据收集:
python代码示例:
from multiprocessing import Pooldef collect_experience(worker_id):env = make_env()while True:state = env.reset()done = Falsewhile not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)replay_buffer.add((state, action, reward, next_state, done))state = next_statepool = Pool(processes=4)pool.map(collect_experience, range(4))2. 混合精度训练
使用NVIDIA APEX库实现FP16训练:
python代码示例:
from apex import ampmodel, optimizer = amp.initialize(model, optimizer, opt_level="O2")with torch.cuda.amp.autocast():q_values = model(states)loss = F.mse_loss(q_values, targets)optimizer.zero_grad()amp.scale_loss(loss, optimizer).backward()optimizer.step()(二)分布式训练架构
1. 参数服务器设计
包含以下组件:
(1)Learner:中央学习节点,更新主网络参数
(2)Actor:多个环境交互节点,生成经验数据
(3)Replay Buffer:分布式经验存储
2. 通信优化
采用压缩通信协议:
(1)梯度量化:将32位浮点数量化为8位整数
(2)稀疏更新:仅传输变化超过阈值的参数
(3)异步通信:计算与通信流水线并行
一个基于python的完整的double Q-learning示例,包括环境准备、代码解析、超参数优化、与Q-learning效果对比、数据可视化等内容,将在另一篇文章中介绍。