<论文>(微软)WINA:用于加速大语言模型推理的权重感知神经元激活
一、摘要
本文介绍2025年5月由微软牵头发表的论文《WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference》。

摘要:
大型语言模型(LLM)不断增长的计算需求,使得高效推理和激活策略变得愈发关键。虽然诸如专家混合(MoE)等近期方法利用了选择性激活,但需要专门的训练,而免训练的稀疏激活方法通过即插即用的设计,具备更广泛的适用性和卓越的资源效率。然而,许多现有方法仅依赖隐藏状态的大小来确定激活,这导致了较高的近似误差和不理想的推理准确性。为解决这些局限性,我们提出了WINA(权重感知神经元激活),这是一种新颖、简单且免训练的稀疏激活框架,它同时考虑隐藏状态的大小和权重矩阵的列方向ℓ2范数。我们证明,这会产生一种稀疏化策略,该策略能获得最优的近似误差界,且理论保证比现有技术更严格。在实证方面,在相同的稀疏度水平下,WINA在多种LLM架构和数据集上的平均性能比最先进的方法(如TEAL)高出2.94%。这些结果使WINA成为LLM推理中免训练稀疏激活的新性能前沿,推动了免训练稀疏激活方法的发展,并为高效推理设定了坚实的基线。
二、核心创新点
作者指出,大模型不断增大的规模和复杂性使得控制计算成本的挑战也不断变大,如何在不降低输出质量的前提下降低推理成本成为了核心问题。一种策略是在推理过程中,使用MoE混合专家架构仅激活完整模型中的一个子网络,但这种策略依赖大量的训练。另一种策略是无需训练的稀疏激活,它保留原始的稠密模型,但在推理时选择性地忽略权重或者神经元,通过利用权重重要性、隐藏状态变化范围等标准来确定停用模型的哪些部分,从而加快推理,但这种方式忽略了权重矩阵对误差传播的影响,即未能考虑前向传播过程中输入元素与权重矩阵之间的相互作用如何影响模型输出,从而导致在稀疏激活中累积近似误差。
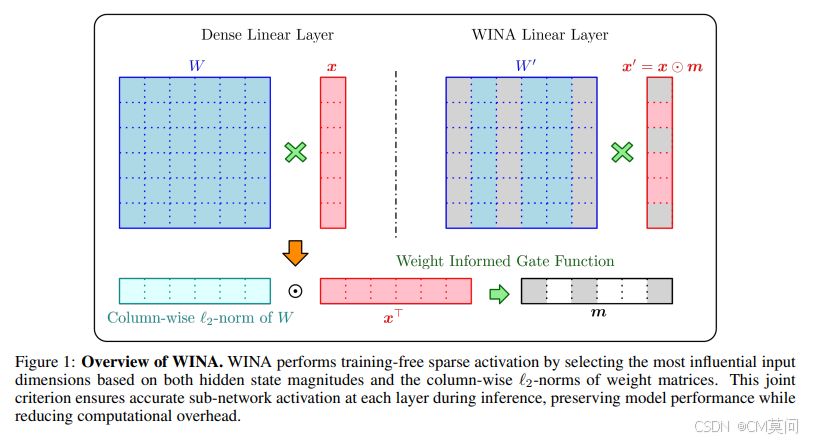
由此,作者提出了无需训练的WINA框架,这个框架基于隐藏状态的幅度和权重矩阵的列项L2范数执行稀疏激活(每一层输入中的非必要成分将被置为 0 )。通过将激活强度和权重重要性相结合,使得阈值能够直接反映每个激活对下一层的影响程度,由此实现了对稀疏性的更精细的控制,并对最终的近似误差设置了更严格的界限。
2.1 问题陈述
考虑一个由L层组成的深度神经网络M。对于,将第
层的权重矩阵表示为
,相应的输入表示为任意张量
,其代表完整的信息内容。作者的目标是确定一组二进制激活门
,其中每个
,使得模型的原始输出与门控输出之间的偏差最小化:
由于获取完整的可能输入集X通常是不可行的,作者改用一个采样子集来近似它。激活门控在输入向量空间中运行,以减少输出偏差。基于这一观察,可以重新将原始问题表述为每层的版本——给定一个权重矩阵
和一个采样输入向量
,标准线性变换为
。作者的目标就变成了确定一个激活门或者掩码
,使得掩码输出
通过求解下式来逼近原始输出:
2.2 权重感知门控机制
目前许多稀疏激活方法都通过一种由隐藏状态绝对值控制的top-K门控机制运行。这种方法忽略了权重矩阵的关键作用,而在WINA中,作者根据特定的标准选择top-K个分量来构造二元激活门:
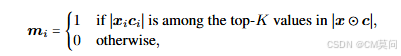
其中表示W的按列L2范数,
表示哈达玛积或者逐元素乘积。K的选择可以根据不同的用例进行调整,范围从一种粗粒度的通用标准(即对所有层应用相同的K)到一种细粒度的特定层策略(即单独分配K以更好地最小化近似误差)。
2.3 应用
作者依赖于相关权重矩阵列正交的假设在论文中展开了理论分析,即当时,但在实际中,大模型可能会违反列正交的条件。为了保持理论误差界限,作者提出了一种张量变换框架(tensor transformation framework),该框架在模型的相关权重矩阵中强制实现列正交性。
给定一个权重矩阵W,可以通过在W的右侧乘以一个正交矩阵Q来强制实现列正交性,使得乘积WQ具有正交列。具体来说,对W进行奇异值分解:
其中,U和V是正交矩阵,而是一个对角矩阵,包含W的奇异值。为了实现列正交性,设Q=V,并按如下方式变换W:
这种变换保证了所得矩阵满足列正交性:
为了确保模型在这种变换后最终输出保持不变,作者利用计算不变性来补偿其影响。即通过基于奇异值分解的变换,对自注意力层中的键投影矩阵和多层感知机(MLP)层中的门投影矩阵
施加列正交约束。然后,将这些变换传播到相邻层,并相应地调整残差连接,以保持计算不变性。在推理过程中,对这些经过变换的列正交矩阵采用所提出的激活准测,而对于其余矩阵则采用稀疏建模中常见的策略,即使用传统的基于输入的激活准则。