【opencv】基础知识到进阶(更新中)
安装:pip install opencv-python
入门案例¶
读取图片¶
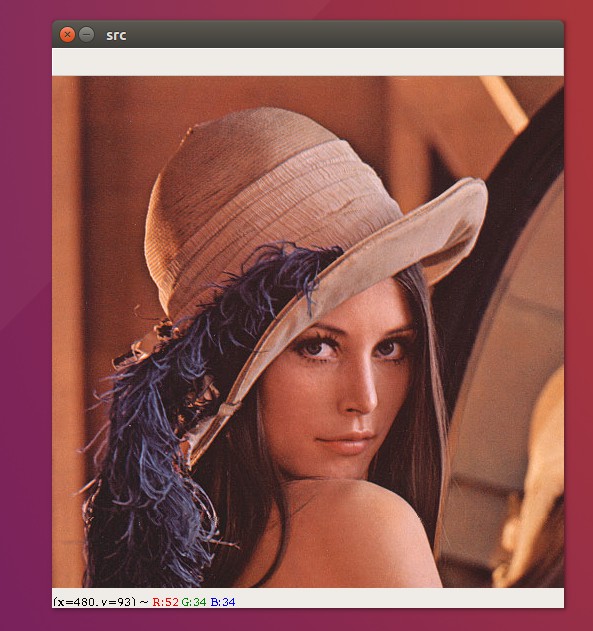
本节我们将来学习,如何使用opencv显示一张图片出来,我们首先需要掌握一条图片读取的api
cv.imread("图片路径","读取的方式")
# 图片路径: 需要在工程目录中,或者一个文件的绝对路径
# 读取方式: 分别有如下三种:
cv.IMREAD_COLOR : 以彩图的方式加载,会忽略透明度(默认方式)
cv.IMREAD_GRAYSCALE: 以灰色图片方式加载
cv.IMREAD_UNCHANGED: 直接加载,透明度会得到保留 import cv2 as cv# 读取图片 参数1:图片路径, 参数2:读取的方式
img = cv.imread("img/lena.png",cv.IMREAD_COLOR)
# 显示窗口 参数1:窗口名称, 参数2:图片数据
cv.imshow("src",img)# 让程序处于等待推出状态
cv.waitKey(0)
# 当程序推出时,释放所有窗口资源
cv.destroyAllWindows()写入文件¶
刚才我们知道,如何读取文件,接下来,我们来学习如何将内存中的图片数据写入到磁盘中!
暂时我们还没有学习,如何直接代码构建一张图片,为了演示,我们先读取一张图片,然后再将它写入到文件中,后面我们会学习如何直接内存中构建一张图片
import cv2 as cv
img = cv.imread("img/lena.png", cv.IMREAD_UNCHANGED)# 将图片写入到磁盘中,参数1: 图片写入路径,参数2: 图片数据
cv.imwrite("img/lena_copy.png",img)cv.waitKey(0)
cv.destroyAllWindows()理解像素¶
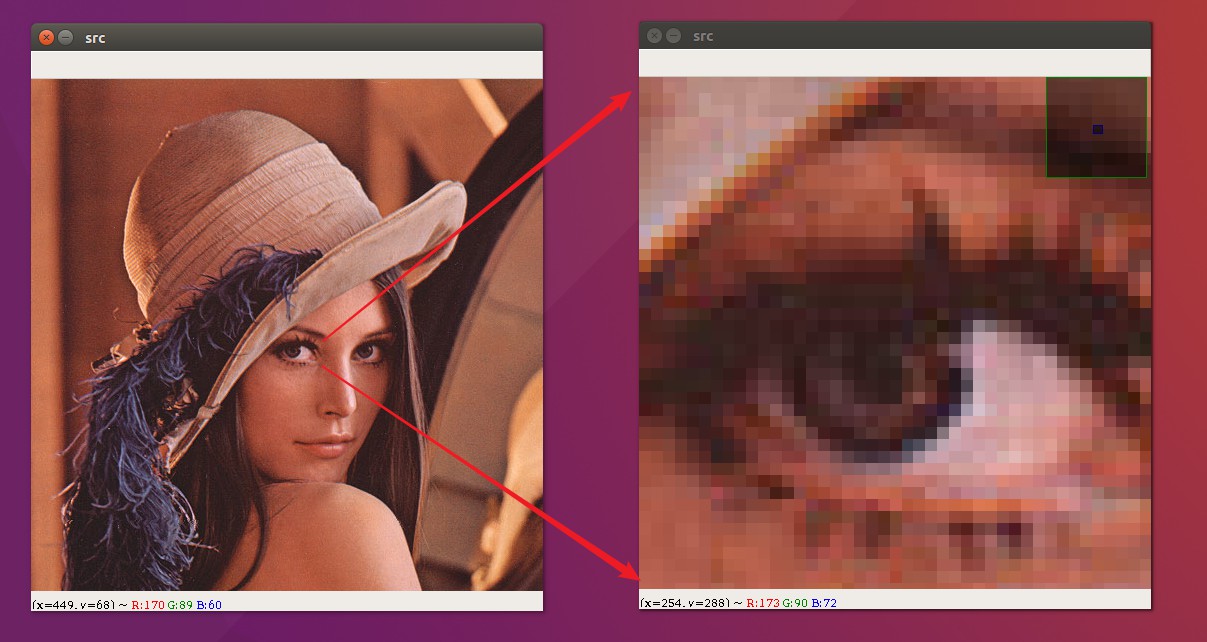
当我们将一张图片不断放大之后,我们就可以看到这张图片上一个个小方块,这里面的每一个小方块我们就可以称之为像素点! 任何一张图片,都是有若干个这样的像素所构成的!
操作像素¶
为了便于大家能够理解像素,我们现在手工来创建一张图片,例如我们使用np.zeros这样的函数可以创建一个30x40的矩阵,那个这个矩阵其实就可以表示一张图片,矩阵中每一个元素都是一个像素点,每个像素点又由BGR三部分组成,这里我们需要强调一下Opencv中,颜色空间默认是BGR不是RGB,所以我们想表示红色需要使用(0,0,255),想表示绿色需要(0,255,0)
下面我们就来操作图片,在图片的正中央增加一根红色的线!
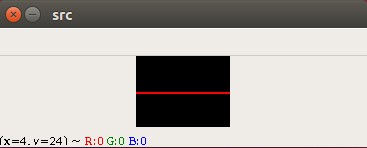
这里我直接给出示例代码,然后我们来看一下运行效果吧!
import cv2 as cv
import numpy as np# 构建一个空白的矩阵
img = np.zeros((30,40,3),np.uint8)# 将第15行所有像素点全都改成红色
for i in range(40):# 设置第15行颜色为红色img[15,i] = (0,0,255)# 显示图片
cv.imshow("src",img)cv.waitKey(0)
cv.destroyAllWindows()几何变换
123456789 10 11 | |
图片镜像处理¶
图片的镜像处理其实就是将图像围绕某一个轴进行翻转,形成一幅新的图像. 我们经常可以通过某个小水坑看到天空中的云, 只不过这个云是倒着的! 这个就是我们称为的图片的镜像!
下面我们来看这样一个示例吧!我们将lena这张图片沿着x轴进行了翻转

如果我们想在一个窗口中显示出两张图片,那么我们就需要知道图片的宽高信息啦!
如何获取呢? 看下面的示例代码:
imgInfo = img.shape
imgInfo[0] : 表示高度
imgInfo[1] : 表示宽度
imgInfo[2] : 表示每个像素点由几个颜色值构成 知道了上述信息之后,我们就可以按照如下步骤实现啦!
实现步骤:
- 创建一个两倍于原图的空白矩阵
- 将图像的数据按照从前向后,从后向前进行绘制
代码实现
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个两倍于原图大小的矩阵
dstImg = np.zeros((height*2,width,3),np.uint8)# 向目标矩阵中填值
for row in range(height):for col in range(width):# 上部分直接原样填充dstImg[row,col] = img[row,col]# 下半部分倒序填充dstImg[height*2-row-1,col] = img[row,col]# 显示图片出来
cv.imshow("dstImg",dstImg)cv.waitKey(0)
cv.destroyAllWindows()图片缩放¶
对于图片的操作,我们经常会用到,放大缩小,位移,还有旋转,在接下来的课程中,我们将来学习这些操作!
首先,我们来学习一下图片的缩放
关于图片的缩放,常用有两种:
- 等比例缩放
- 任意比例缩放
要进行按比例缩放,我们需要知道图片的相关信息,我们可以通过
图片缩放的常见算法:
- 最近领域插值
- 双线性插值
- 像素关系重采样
- 立方插值
默认使用的是双线性插值法,这里我们给出利用opencv提供的resize方法来进行图片的缩放
import cv2 as cv# 读取一张图片
img = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
# 获取图片信息
imgInfo = img.shape
print(imgInfo)
# 获取图片的高度
height = imgInfo[0]
# 获取图片的宽度
width = imgInfo[1]
# 获取图片的颜色模式,表示每个像素点由3个值组成
mode = imgInfo[2]# 定义缩放比例
newHeight = int(height*0.5)
newWidth = int(width*0.5)
# 使用api缩放
newImg = cv.resize(img, (newWidth, newHeight))
# 将图片展示出来
cv.imshow("result",newImg)cv.waitKey(0)
cv.destroyAllWindows()实现最近邻域插值法¶
从与计算位置最近的一个像素点获取颜色相关信息!
例如: 宽度和高度都放大2倍, 那么放大之后的图片坐标(2,4)这个点对应应该是原图(1,2)这个点的像素值
那放大之后的图片坐标(1,2)这个点应该对应原图(0.5,1)这个点的像素值.
但是没有0.5这样的角标呀! 那我们可以取这个点附近的颜色值,例如(0,1)这个点的像素值,这个其实就是最近邻域插值法
import cv2 as cv
import numpy as np
"""
最近邻域插值法原理
"""
img = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
# 获取当前图片信息
imgInfo = img.shape
# 获取图片的高度
height = imgInfo[0]
# 获取图片的宽度
width = imgInfo[1]
# 指定缩放比例,宽度高度都缩放一半
scale = 0.5
# 目标高度
dstHeight = int(height*scale)
# 目标宽度
dstWidth = int(width*scale)
# 创建空白矩阵模板
dstImg = np.zeros((dstHeight, dstWidth, 3), np.uint8)
# 使用最近邻域插值法填充内容
for row in range(dstHeight):for col in range(dstWidth):# 计算当前坐标与原图坐标的映射sourceRow = int(row/scale)sourceCol = int(col/scale)# 从原图中获取图片的像素值pixel = img[sourceRow,sourceCol]# 将获取到的像素值,填充到新的图片中dstImg[row,col] = pixel# 将目标图片显示出来
cv.imshow("scale",dstImg)cv.waitKey(0)图片操作原理¶
我们在前面描述过一张图片,在计算机程序中,其实是用矩阵来进行描述的,如果我们想对这张图片进行操作,其实就是要对矩阵进行运算.
矩阵的运算相信大家在前面课程的学习中,已经学会了,下面我们来给大家列出常见的几种变换矩阵

这里我给大家演示的是图片的位移操作,将一个矩阵的列和行看成坐标系中的x和y我们就可以轻易的按照前面我们所学过的内容来操作矩阵啦!
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,3),np.uint8)for row in range(height):for col in range(width):# 补成齐次坐标sourceMatrix = np.array([col,row,1])# 水平方向平移50像素,垂直方向平移100像素matrixB = np.array([[1,0,50],[0,1,100]])# 矩阵相乘dstMatrix = matrixB.dot(sourceMatrix.T) # 得到目标图像的像素坐标# 从原图中获取数据dstCol = int(dstMatrix[0])dstRow = int(dstMatrix[1])# 防止角标越界if dstCol < width and dstRow < height:dstImg[dstRow,dstCol] = img[row,col]# 显示图片出来
cv.imwrite("temp.jpg",dstImg)图片移位¶
刚才我们采用的是纯手工的方式来操作图片,其实我们完全没必要那样做,opencv中已经帮我们提供好了相关的计算操作,我们只需提供变换矩阵就好啦!
cv.warpAffine(原始图像,变换矩阵,(高度,宽度))
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 定义位移矩阵
matrixShift = np.float32([[1,0,50],[0,1,100]])
# 调用api
dstImg = cv.warpAffine(img,matrixShift,(width,height))cv.imshow("dst",dstImg)
cv.waitKey(0)图片旋转¶
图片的旋转其实也是很简单的,只不过默认是以图片的左上角为旋转中心

import cv2 as cvimg = cv.imread("img/itheima.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 定义仿射矩阵: 参数1:中心点, 参数2:旋转角度,参数3:缩放系数
matrixAffine = cv.getRotationMatrix2D((width * 0.5, height * 0.5), 45, 0.5)
# 进行仿射变换
dstImg = cv.warpAffine(img, matrixAffine, (width, height))cv.imshow("dstImg",dstImg)
cv.waitKey(0)图片仿射变换¶
仿射变换是在几何上定义为两个向量空间之间的一个仿射变换或者仿射映射(来自拉丁语,affine,“和…相关”)由一个非奇异的线性变换(运用一次函数进行的变换)接上一个平移变换组成。

import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义图片 左上角,左下角 右上角的坐标
matrixSrc = np.float32([[0,0],[0,height-1],[width-1,0]])
# 将原来的点映射到新的点
matrixDst = np.float32([[50,100],[300,height-200],[width-300,100]])
# 将两个矩阵组合在一起,仿射变换矩阵
matrixAffine = cv.getAffineTransform(matrixSrc,matrixDst)dstImg = cv.warpAffine(img,matrixAffine,(width,height))cv.imwrite("datimg.jpg", dstImg)图像金字塔¶
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
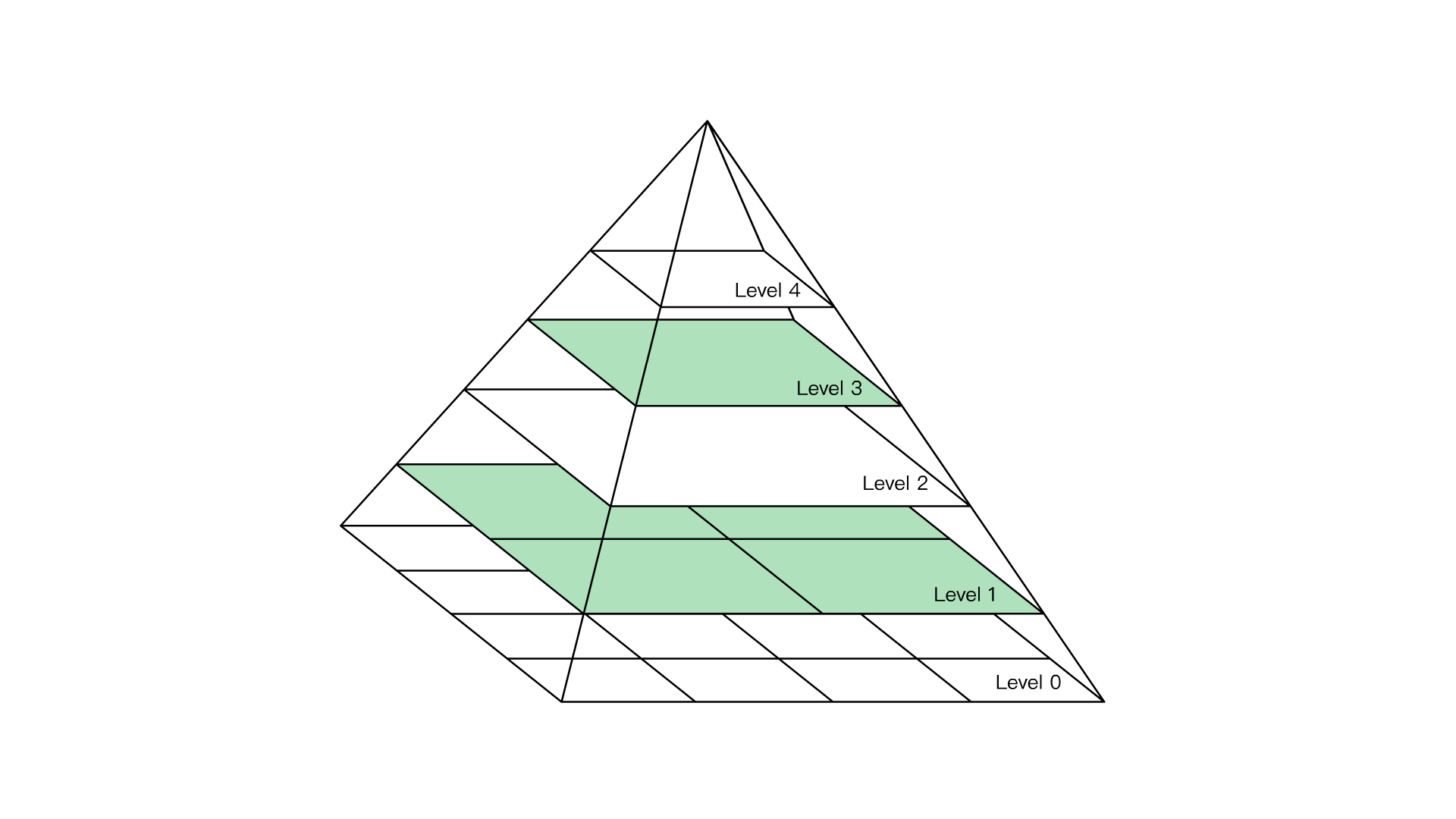
降低图像的分辨率,我们可以称为下采样
提高图像的分辨率,我们可以称为上采样
下面我们来测试一下采用这种采样操作进行缩放和我们直接进行resize操作他们之间有什么差别!
我们可以看到,当我们对图片进行下采样操作的时候,即使图片变得非常小,我们任然能够看到它的轮廓,这对后面我们进行机器学习是非常重要的一步操作
,而当我们直接使用resize进行操作的时候,我们发现图片似乎不能完全表示它原有的轮廓,出现了很多的小方块!
import cv2 as cv;src_img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR);
imgInfo = src_img.shape
height = imgInfo[0]
width = imgInfo[1]pry_down1 = cv.pyrDown(src_img)
cv.imshow("down1",pry_down1)
pry_down2 = cv.pyrDown(pry_down1)
cv.imshow("down2",pry_down2)
pry_down3 = cv.pyrDown(pry_down2)
cv.imshow("down3",pry_down3)
pry_down4 = cv.pyrDown(pry_down3)
cv.imshow("down4",pry_down4)pyr_up1 = cv.pyrUp(pry_down1)
cv.imshow("up1",pyr_up1)
pyr_up2 = cv.pyrUp(pry_down2)
cv.imshow("up2",pyr_up2)
pyr_up3 = cv.pyrUp(pry_down3)
cv.imshow("up3",pyr_up3)
pyr_up4 = cv.pyrUp(pry_down4)
cv.imshow("up4",pyr_up4)# 对比resize
img2 = cv.resize(src_img,(int(height/2),int(width/2)))
cv.imshow("img1/2",img2)img4 = cv.resize(src_img,(int(height/4),int(width/4)))
cv.imshow("img1/4",img4)img8 = cv.resize(src_img,(int(height/8),int(width/8)))
cv.imshow("img1/8",img8)img16 = cv.resize(src_img,(int(height/16),int(width/16)))
cv.imshow("img1/16",img16)cv.waitKey(0)
cv.destroyAllWindows()图像处理
灰度处理
一张彩色图片通常是由BGR三个通道叠加而成,为了便于图像特征识别,我们通常会将一张彩色图片转成灰度图片来进行分析,当我们转成灰色图片之后,图片中边缘,轮廓特征仍然是能够清晰看到的,况且在这种情况下我们仅需要对单一通道进行分析,会简化很多操作!
import cv2 as cv# 方式一 : 直接以灰度图像的形式读取
# img = cv.imread("img/itheima.jpg", cv.IMREAD_GRAYSCALE)
# cv.imshow("dstImg",img)
# cv.waitKey(0)# 方式二: 以彩图的方式读取
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
# 将原图的所有颜色转成灰色
dstImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("dstImg",dstImg)cv.waitKey(0)原理演示
方式一: gray = (B+G+R)/3
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义一个与原图同样大小的矩阵,
dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据
for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度gray = np.uint8((int(b)+int(g)+int(r))/3)# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)
cv.waitKey(0)方式二: 利用著名的彩色转灰色心理学公式: Gray = R*0.299 + G*0.587 + B*0.114
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义一个与原图同样大小的矩阵
dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据
for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度# gray = np.uint8((int(b)+int(g)+int(r))/3)# 采用心理学公式计算gray = b*0.114 + g*0.587 + r*0.299# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)
cv.waitKey(0)颜色反转¶
灰图反转¶
例如在一张灰度图片中,某个像素点的灰度值为100, 然后我们进行颜色反转之后,灰度值变为255-100 = 155 , 从下图我们可以看出,进行颜色反转之后,整张图片看起来非常像我们小时候所看到的胶卷底片!
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("img",img)
# 获取原图信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,1),np.uint8)for row in range(height):for col in range(width):# 获取原图中的灰度值gray = img[row,col]# 反转newColor = 255 - gray# 填充dstImg[row,col]=newColorcv.imshow("dstimg",dstImg)
cv.waitKey(0)彩图反转¶
学会了前面灰度图片的反转,下面我们进一步来学习彩色图片的反转. 相对于灰度图片,彩色图片其实只是由3个灰度图片叠加而成,如果让彩色图片进行颜色反转,我们其实只需要让每个通道的灰度值进行反转即可!
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)
# 获取原图信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,3),np.uint8)for row in range(height):for col in range(width):# 获取原图中的灰度值(b,g,r) = img[row,col]# 反转new_b = 255-bnew_g = 255-gnew_r = 255-r# 填充dstImg[row,col]=(new_b,new_g,new_r)cv.imshow("dstimg",dstImg)
cv.waitKey(0)马赛克效果¶
马赛克指现行广为使用的一种图像(视频)处理手段,此手段将影像特定区域的色阶细节劣化并造成色块打乱的效果,因为这种模糊看上去有一个个的小格子组成,便形象的称这种画面为马赛克。其目的通常是使之无法辨认。
下面,我们来介绍一下实现马赛克的思路!
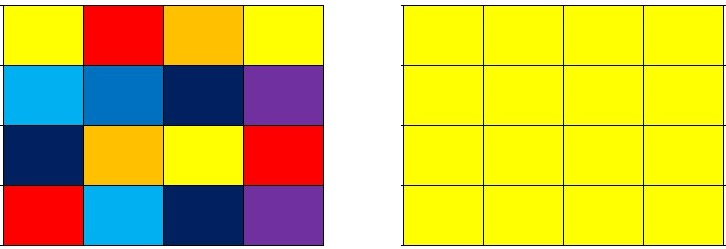
假设我们将要打马赛克的区域按照4x4进行划分,我们就会得到如下左图的样子!
接下来我们要干的就是让这个4x4块内的所有像素点的颜色值都和第一个像素点的值一样.
经过运算之后,我们整个4x4块内的所有像素点就都成了黄色! 从而掩盖掉了原来的像素内容!
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)# 获取原图信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 遍历要打马赛克的区域 int(height/2)-50,int(width/2)-50
for row in range(int(height/2)-100,int(height/2)+100):for col in range(int(width/2)-100,int(width/2)+100):# 每10×10的区域将像素点颜色改成一致if row%10==0 and col%10==0:# 获取当前颜色值(b,g,r) = img[row,col]# 将10×10区域内的颜色值改成一致for i in range(10):for j in range(10):img[row+i,col+j]= (b,g,r)# 显示效果图
cv.imwrite("img/mosaic.jpg",img)图片浮雕效果¶
梯度¶
前面我们做过一个毛玻璃效果的图片, 其实原理很简单对吧,我们只需要让当前像素点的颜色和附近像素点的颜色一致就可以了! 这样带来的效果其实是图片变得模糊.
那么模糊图片和清晰图片之间的差异是什么呢? 从视觉角度来讲, 图像模糊是因为图像中物体的边缘轮廓不明显,就好比一个近视的同学,摘下眼镜看东西,整个世界的轮廓都是模糊的. 再进一步理解就是物体边缘灰度变化不强烈,层次感不强造成的! 那么反过来, 如果物体轮廓边缘灰度变化明显些, 层次感强些图像不就是清晰一些了吗?
这种灰度变化明不明显强不强烈该如何定义呢 ? 我们学过微积分, 微分就是求函数的变化率,即导数(梯度). 其实梯度我们可以把它理解为颜色变化的强度, 更直白一点说梯度相当于是2个相邻像素之间的差值!

我们先看第一行数据, 在X轴方向上,颜色值都为100,我们并没有看到任何的边缘
但是在Y轴方向上, 我们可以看到100和50之间有明显的边缘,其实这个就是梯度
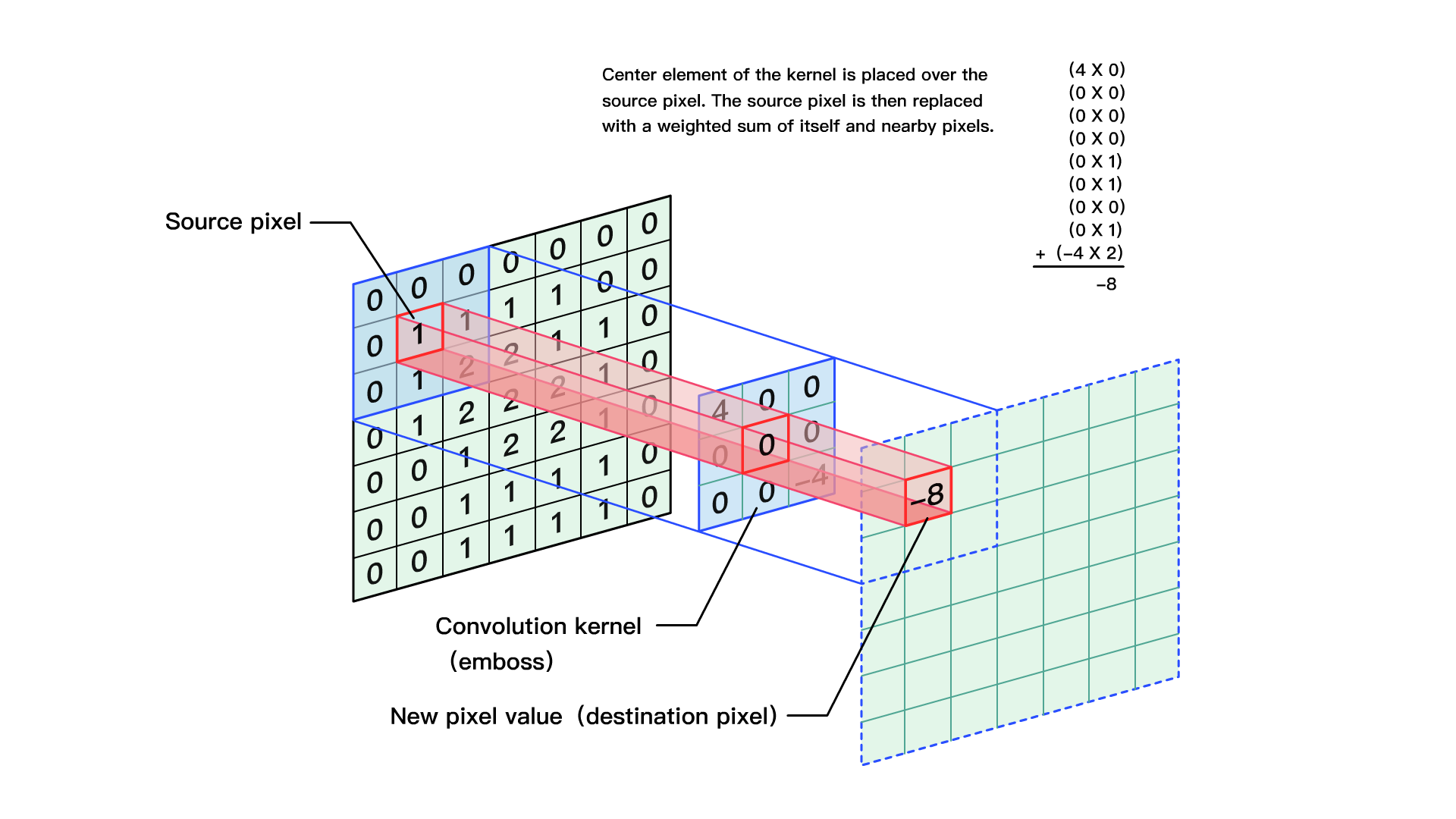
浮雕效果相信大家都有比较熟悉,在opencv中我们想要实现浮雕效果,只需套用如下公式即可:
1 | |
其中,相邻像素值之差可以体现边缘的突变或者称为梯度
末尾加上120只是为了增加像素值的灰度.
当然,在这个运算的过程中,我们还需要注意计算结果有可能小于0或者大于255
import cv2 as cv
import numpy as np
import random# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 创建一张与原图相同大小的空白矩阵
dstImg = np.zeros((height,width,1),np.uint8)# 向空白图片中填充内容
for row in range(height):for col in range(width-1):# 获取当前像素值gray0 = grayImg[row,col]# 获取相邻一个像素点灰度gray1 = grayImg[row,col+1]# 计算新的灰度值gray = int(gray0)-int(gray1)+120# 校验gray是否越界gray = gray if gray<255 else 255gray = gray if gray>0 else 0# 将值填充到空白的矩阵中dstImg[row,col] = gray# 显示图片
cv.imshow("dstimg",dstImg)
cv.waitKey(0)绘制图形¶
在这之前,我们学过的所有操作,其实都是在原图的基础上进行修改! 现在假设我们想在原图上绘制一些标记或者轮廓,那么我们就需要来学习一下opencv给我们提供的相应API,在这些API中,常见的有绘制直线,绘制圆,绘制矩形
# 绘制线段 参数2:起始点 参数3:结束点 参数4:颜色 参数5:线条宽度 cv.line(图片矩阵,起始点,结束点,颜色值,线条的宽度,线条的类型) # 绘制一个矩形 参数2: 左上角 参数3:右下角 参数4:颜色 参数5:线条宽度,若为负数,则填充整个矩形 cv.rectangle(dstImg,(250,90),(470,180),(0,255,0),-1) # 绘制圆形 参数2:圆心 参数3:半径 参数4:颜色 参数5:线条宽度 cv.circle(dstImg,(450,280),90,(0,0,255),5)
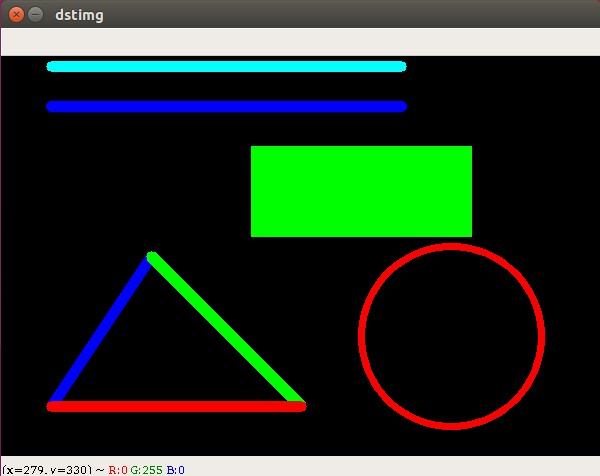
import cv2 as cv
import numpy as np
import random# 创建一个空白的矩阵
dstImg = np.zeros((400,600,3),np.uint8)# 绘制线段 参数2:起始点 参数3:结束点 参数4:颜色 参数5:线条宽度
cv.line(dstImg,(50,10),(400,10),(255,255,0),10)
# 扛锯齿
cv.line(dstImg,(50,50),(400,50),(255,0,0),10,cv.LINE_AA)# 绘制一个三角形
cv.line(dstImg,(50,350),(150,200),(255,0,0),10)
cv.line(dstImg,(150,200),(300,350),(0,255,0),10)
cv.line(dstImg,(300,350),(50,350),(0,0,255),10)# 绘制一个矩形 参数2: 左上角 参数3:右下角 参数4:颜色 参数5:线条宽度,若为负数,则填充整个矩形
cv.rectangle(dstImg,(250,90),(470,180),(0,255,0),-1)# 绘制圆形 参数2:圆心 参数3:半径 参数4:颜色 参数5:线条宽度
cv.circle(dstImg,(450,280),90,(0,0,255),5)# 显示图片
cv.imshow("dstimg",dstImg)
cv.waitKey(0)文字图片绘制¶
在图片上绘制文本,我们需要用到
# 绘制文字 font = cv.FONT_HERSHEY_SIMPLEX # 参数2:文本 参数3:显示位置 参数4:字体 参数5:大小 参数6:颜色 参数7:粗细 参数8:线条类型 cv.putText(img,'www.itheima.com',(395,138),font,1,(0,0,255),2,cv.LINE_AA)
# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 在图片上绘制矩形
cv.rectangle(img,(380,150),(666,236),(0,255,0),5)# 绘制图片
lenaImg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
# 获取图片信息
imgInfo = lenaImg.shape
# 计算缩放图片宽高
scale = 0.3
height = int(imgInfo[0]*scale)
width = int(imgInfo[1]*scale)
# 缩放图片
newLenaImg = cv.resize(lenaImg,(height,width))
# 遍历
for row in range(height):for col in range(width):img[50+row,100+col]=newLenaImg[row,col]cv.imshow('dstimg',img)
cv.waitKey(0)注意: opencv不支持中文显示,若想显示中文,需要额外安装中文字体库
图片美化¶
亮度增强¶
亮度增强,其实就是将每个颜色值增大一点点 例如: color = color + 50 即可调亮图片 color = color - 50 即可调暗图片
import cv2 as cvdef checkColor(value):value = value if value < 256 else 255value = value if value > 0 else 0return value# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow('img',img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义颜色改变的值
count=35# 遍历每一个像素点
for row in range(height):for col in range(width):# 获取每个像素点的颜色值(b,g,r) = img[row,col]# 增大当前颜色值newb = b + countnewg = g + countnewr = r + count# 校验每个像素值不能越界newb = checkColor(newb)newg = checkColor(newg)newr = checkColor(newr)img[row,col] = (newb,newg,newr)
# 显示改变之后的图像
cv.imshow('newimg',img)
cv.waitKey(0)灰度图片¶
直方图¶
统计每个灰度值出现的概率
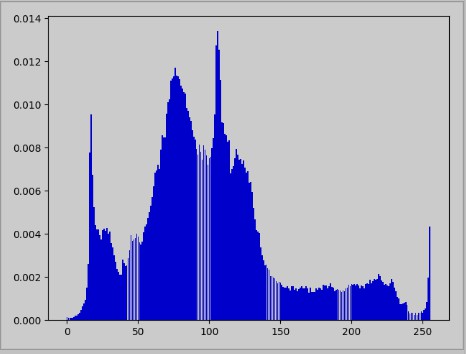
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt# 将图片数据读取进来
img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 定义一个向量,用于记录每个灰度出现的次数
count = np.zeros(256,np.float32)# 统计每一个灰度出现的次数
for row in range(height):for col in range(width):# 获取每个像素的灰度值gray = int(grayImg[row,col])# 统计count[gray]=count[gray]+1# 统计出现的概率
# 定义一个向量,用于记录每个灰度出现的次数
ratios = np.zeros(256,np.float32)
for i in range(256):# 将次数转成概率ratios[i] = count[i]/(height*width)x = np.linspace(0,255,256)
y = ratiosplt.bar(x,y,0.9,color='gray')
plt.show()cv.waitKey(0)api实现
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("gray",grayImg)# 计算直方图 , 注意这里需要用数组的方式传值
hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])
plt.plot(hist,color="green")
plt.show()cv.waitKey(0)
cv.destroyAllWindows()画图方式
方式一:# 使用api将直方图数据计算好 图片 通道 掩膜 数量 值的范围hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])# 调用plot函数显示plt.plot(hist,color="green")plt.show()
方式二:# 1.使用Img.ravel()将多行的矩阵转成单行的矩阵# 2. 然后调用matplot的hist函数自动计算直方图,bins表示像素区间数量plt.hist(grayImg.ravel(),color="red",bins=256)plt.show()直方图均衡化是将原图象的直方图通过变换函数修正为均匀的直方图,然后按均衡直方图修正原图象。图象均衡化处理后,图象的直方图是平直的,即各灰度级具有相同的出现频数,那么由于灰度级具有均匀的概率分布,图象看起来就更清晰了。
经过直方图均衡化处理之后,我们整个图像的颜色变化就是一种平滑变化的状态
原始直方图 -- 均衡化直方图的 变换函数 : 累积概率图
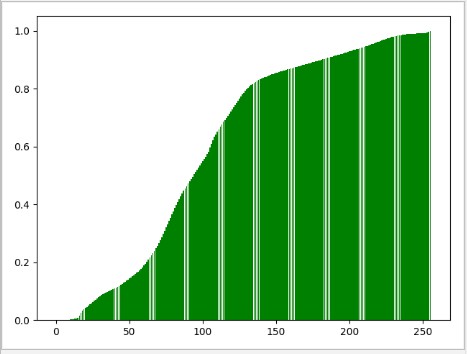
下面我们来看一下灰色图片经过直方图均衡化处理之后的对比

这里是均衡化前后图像直方图的对比
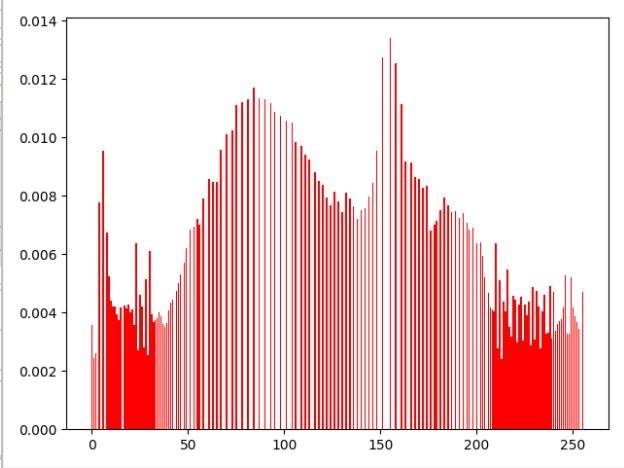
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt# 将图片数据读取进来
img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 显示灰度图片
cv.imshow('grayimg',grayImg)
# 定义一个向量,用于记录每个灰度出现的次数
count = np.zeros(256,np.float32)# 统计每一个灰度出现的次数
for row in range(height):for col in range(width):# 获取每个像素的灰度值gray = int(grayImg[row,col])# 统计count[gray]=count[gray]+1# 统计出现的概率
# 定义一个向量,用于记录每个灰度出现的次数
ratios = np.zeros(256,np.float32)
for i in range(256):# 将次数转成概率ratios[i] = count[i]/(height*width)x = np.linspace(0,255,256)
y = ratiosplt.bar(x,y,0.9,color='gray')
plt.show()# --------均衡化 -------------------# 定义累计概率初值
sum1 = 0.0
# 定义用于记录累计概率的数组
sumRatios = np.zeros(256,np.float32)
# 计算每个灰度的累计概率
for i in range(256):sum1 = sum1 + ratios[i]sumRatios[i]=sum1x = np.linspace(0,255,256)
y = sumRatios# 显示均衡化之后的直方图
plt.bar(x,y,0.9,color='green')
plt.show()# 遍历原灰图
for row in range(height):for col in range(width):# 取出原灰度gray = grayImg[row,col]# 取出当前灰度的累计概率ratio = sumRatios[gray]# 计算新的灰度,并赋值grayImg[row,col]=np.uint8(255*ratio)cv.imshow('new gray img',grayImg)# 会自己去统计直方图
plt.hist(grayImg.ravel(),color="red",bins=256)
plt.show()cv.waitKey(0)api
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("gray",grayImg)# 计算直方图 , 注意这里需要用数组的方式传值
hist = cv.calcHist([grayImg],[0],None,[256],[0.0,255.0])
plt.plot(hist,color="green")
plt.show()# 直方图均衡化
# equalize_img = np.zeros(grayImg.shape,np.uint8)
equalize_img = cv.equalizeHist(grayImg)
cv.imshow("equalize img",equalize_img)# 会自己统计直方图,但是需要将多行数据转成单行数据
plt.hist(equalize_img.ravel(),bins=256)
plt.show()cv.waitKey(0)
cv.destroyAllWindows()彩色图片¶
直方图¶
在前面,我们计算灰度图片的直方图时,我们只需要统计灰色值出现的概率就可以了,现在我们要处理的是彩色图片,所以我们需要将(B,G,R)三种颜色值取出来,单独计算每种颜色的直方图
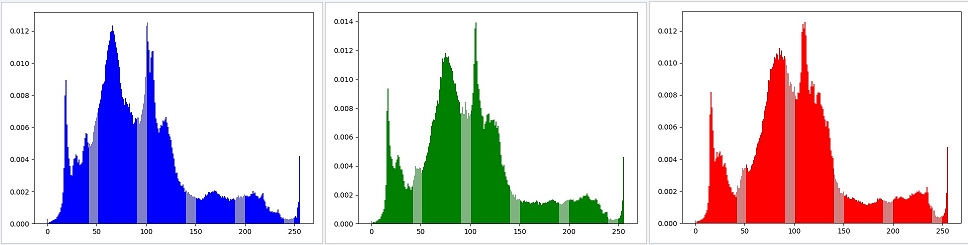
import cv2 as cv
import matplotlib.pyplot as pltimg = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)colors = ["blue","green","red"]
img_split = cv.split(img)
for i,channel in enumerate(img_split):plt.hist(channel.ravel(),bins=256,color=colors[i])plt.show()cv.waitKey(0)
cv.destroyAllWindows()直方图均衡化
import cv2 as cvimg = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)b,g,r = cv.split(img)b_dst = cv.equalizeHist(b)
g_dst = cv.equalizeHist(g)
r_dst = cv.equalizeHist(r)ret = cv.merge([b_dst,g_dst,r_dst])# 显示均衡化之后的图片
cv.imshow("src",img)
cv.imshow("equalize_img",ret)cv.waitKey(0)
cv.destroyAllWindows()视频处理¶
视频分解图片¶
在后面我们要学习的机器学习中,我们需要大量的图片训练样本,这些图片训练样本如果我们全都使用相机拍照的方式去获取的话,工作量会非常巨大, 通常的做法是我们通过录制视频,然后提取视频中的每一帧即可!
接下来,我们就来学习如何从视频中获取信息
ubuntu下摄像头终端可以安装: sudo apt-get install cheese 然后输入cheese即可打开摄像头
实现步骤:
- 加载视频
- 获取视频信息
- 解析视频
import cv2 as cvvideo = cv.VideoCapture("img/twotiger.avi")
# 判断视频是否打开成功
isOpened = video.isOpened()
print("视频是否打开成功:",isOpened)
# 获取图片的信息:帧率
fps = video.get(cv.CAP_PROP_FPS)
# 获取每帧宽度
width = video.get(cv.CAP_PROP_FRAME_WIDTH)
# 获取每帧的高度
height = video.get(cv.CAP_PROP_FRAME_HEIGHT)
print("帧率:{},宽度:{},高度:{}".format(fps,width,height))# 从视频中读取8帧信息
count=0while count<8:count = count + 1# 读取成功or失败, 当前帧数据flag,frame = video.read()# 将图片信息写入到文件中if flag: # 保存图片的质量 cv.imwrite("img/tiger%d.jpg"%count,frame,[cv.IMWRITE_JPEG_QUALITY,100])print("图片截取完成啦!")图片合成视频¶
在执行视频合成之前,最好先安装ffmpeg
sudo apt-get update
sudo apt-get install ffmpeg
# 安装完成之后,查看版本
ffmpeg -versionimport cv2 as cv# 读取一张图片
img1 = cv.imread("img/tiger1.jpg",cv.IMREAD_COLOR)
# 获取图片信息
imgInfo = img1.shape
# 定义宽高
size = (imgInfo[1],imgInfo[0])
# 定义视频写入 编码格式
fourcc = cv.VideoWriter_fourcc(*'XVID')
# 输出视频名称 编码格式对象 帧率 大小
videoWrite = cv.VideoWriter("img/tiger_copy2.avi",fourcc,4,size)for i in range(1,8):img = cv.imread("img/tiger%d.jpg"%i)videoWrite.write(img)# 养成良好习惯,释放资源
videoWrite.release()
cv.destroyAllWindows()print("生成视频结束!")人脸识别¶
在Opencv中人脸识别是基于Haar特征+Adaboost级联分类器来实现人脸识别的!
要理解这节内容,我们首先要明白什么是特征?
特征其实就是某个区域的像素点经过运算之后得到的结果! 例如haar特征其实就是用下图列出的模板在图像中滑动,计算白色区域覆盖的像素之和减去黑色区域覆盖的像素之和,运算出来的结果就是haar特征值!
Haar特征一般和Adaboost分类器结合在一起进行目标识别!
这里需要运动机器学习的知识! 不过值得庆幸的是Opencv已经为我们训练好了数据,并且已经提取出了人脸的特征,在opencv的源码中有相应的xml特征文件. 并且我们只需要调用opencv提供好的API即可快速完成人脸识别的功能!
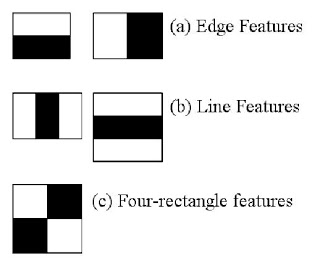

核心api为:
# 加载已经训练好的特征文件
faces_xml = cv.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
# 根据特征文件去查找人脸
faces_xml.detectMultiScale(图像, 缩放系数, 至少检验次数)实现步骤:
- 加载特征xml文件
- 加载图片
- 灰度处理
- 判决
- 绘制出检测出来的人脸

对应需要加载文件下载地址:放到对应目录即可opencv/data/haarcascades at master · opencv/opencv · GitHub
import cv2 as cv
# 第1步:加载xml文件
faces_xml = cv.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
eyes_xml = cv.CascadeClassifier("assets/haarcascade_eye.xml")# 第2步:加载图片
img = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)# 第3步:将图片转成灰色图片
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 第4步:使用api进行人脸识别 参数2:缩放系数 参数3:至少要检测几次才算正确
faces = faces_xml.detectMultiScale(gray, 1.3, 5)
print("找到人脸的数量:",len(faces))# 在人脸上绘制矩形
for (x,y,w,h) in faces:# 在找到人脸上画矩形cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),5)# 从灰色图片中找到人脸grayFace = gray[y:y+h,x:x+w]colorFace = img[y:y+h,x:x+w]# 在当前人脸上找到眼睛的位置eyes = eyes_xml.detectMultiScale(grayFace,1.3,5)print("当前人脸上眼睛数量:",len(eyes))# 在眼睛上绘制矩形for (e_x,e_y,e_w,e_h) in eyes:cv.rectangle(colorFace,(e_x,e_y),(e_x+e_w,e_y+e_h),(0,0,255),3)cv.imshow('result',img)
cv.waitKey(0)
cv.destroyAllWindows()HSV颜色模型¶
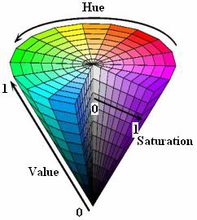
HSV(Hue, Saturation, Value)是根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)。
这个模型中颜色的参数分别是:色调(H),饱和度(S),明度(V)
色调H¶
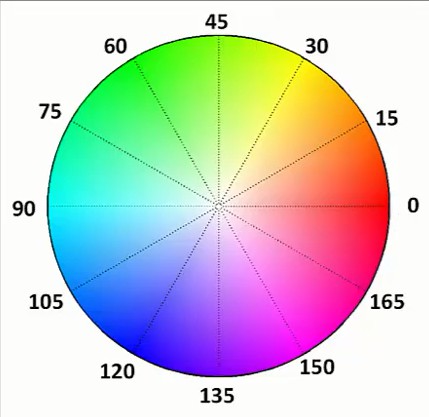
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;
饱和度S¶
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V¶
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
结论:
-
当S=1 V=1时,H所代表的任何颜色被称为纯色;
-
当S=0时,即饱和度为0,颜色最浅,最浅被描述为灰色(灰色也有亮度,黑色和白色也属于灰色),灰色的亮度由V决定,此时H无意义;
-
当V=0时,颜色最暗,最暗被描述为黑色,因此此时H(无论什么颜色最暗都为黑色)和S(无论什么深浅的颜色最暗都为黑色)均无意义。
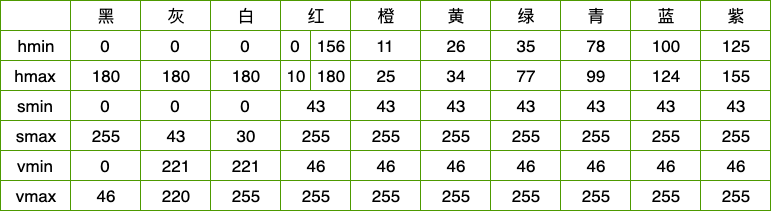
注意: 在opencv中,H、S、V值范围分别是[0,180],[0,255],[0,255],而非[0,360],[0,1],[0,1];
这里我们列出部分hsv空间的颜色值, 表中将部分紫色归为红色
判断当前是白天还是晚上¶
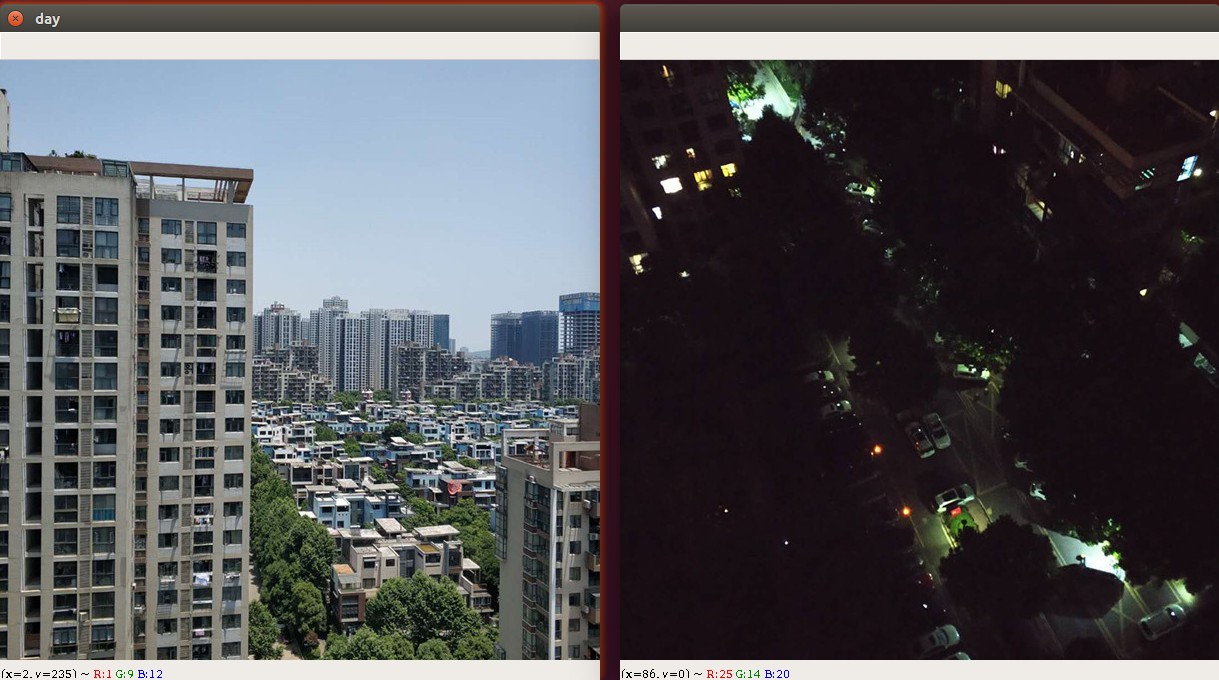
实现步骤¶
- 将图片从BGR颜色空间,转变成HSV颜色空间
- 获取图片的宽高信息
- 统计每个颜色点的亮度
- 计算整张图片的亮度平均值
注意,这仅仅只能做一个比较粗糙的判定,按照我们人的正常思维,在傍晚临界点我们也无法判定当前是属于晚上还是白天!
import cv2 as cv
import numpy as npdef average_brightness(img):"""封装一个计算图片平均亮度的函数"""imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]hsv_img = cv.cvtColor(img, cv.COLOR_BGR2HSV)# 提取出v通道信息v_day = cv.split(hsv_img)[2]# 计算亮度之和result = np.sum(v_day)# 返回亮度的平均值return result/(height*width)# 计算白天的亮度平均值
day_img = cv.imread("assets/day.jpg", cv.IMREAD_COLOR)
brightness1 = average_brightness(day_img)
print("day brightness1:",brightness1);# 计算晚上的亮度平均值
night_img = cv.imread("assets/night.jpg", cv.IMREAD_COLOR)
brightness2 = average_brightness(night_img)
print("night brightness2:",brightness2)cv.waitKey(0)
cv.destroyAllWindows()颜色过滤¶
在一张图片中,如果某个物体的颜色为纯色,那么我们就可以使用颜色过滤inRange的方式很方便的来提取这个物体.
下面我们有一张网球的图片,并且网球的颜色为一定范围内的绿色,在这张图片中我们找不到其它颜色也为绿色的图片,所以我们可以考虑使用绿色来提取它!
图片的颜色空间默认为BGR颜色空间,如果我们想找到提取纯绿色的话,我们可能需要写(0,255,0)这样的内容,假设我们想表示一定范围的绿色就会很麻烦!
所以我们考虑将它转成HSV颜色空间,绿色的色调H的范围我们很容易知道,剩下的就是框定颜色的饱和度H和亮度V就可以啦!
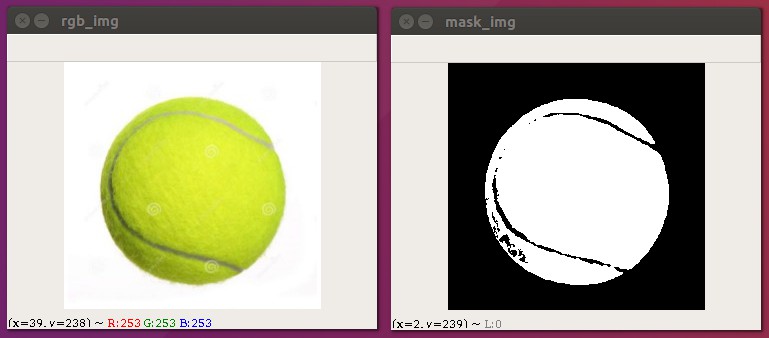
实现步骤:
- 读取一张彩色图片
- 将RGB转成HSV图片
- 定义颜色的范围,下限位(30,120,130),上限为(60,255,255)
- 根据颜色的范围创建一个mask
import cv2 as cv
# 读取图片
rgb_img = cv.imread("assets/tenis1.jpg", cv.IMREAD_COLOR)
cv.imshow("rgb_img",rgb_img)
# 将BGR颜色空间转成HSV空间
hsv_img = cv.cvtColor(rgb_img, cv.COLOR_BGR2HSV)# 定义范围 网球颜色范围
lower_color = (30,120,130)
upper_color = (60,255,255)# 查找颜色
mask_img = cv.inRange(hsv_img, lower_color, upper_color)
# 在颜色范围内的内容是白色, 其它为黑色
cv.imshow("mask_img",mask_img)cv.waitKey(0)
cv.destroyAllWindows()图像的二值化¶
图像二值化( Image Binarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
在数字图像处理中,二值图像占有非常重要的地位,图像的二值化使图像中数据量大为减少,从而能凸显出目标的轮廓。
1 | |

| THRESH_BINARY | 高于阈值改为255,低于阈值改为0 |
|---|---|
| THRESH_BINARY_INV | 高于阈值改为0,低于阈值改为255 |
| THRESH_TRUNC | 截断,高于阈值改为阈值,最大值失效 |
| THRESH_TOZERO | 高于阈值不改变,低于阈值改为0 |
| THRESH_TOZERO_INV | 高于阈值该为0,低于阈值不改变 |
简单阈值¶
import cv2 as cv# 读取图像
img = cv.imread("assets/car.jpg",cv.IMREAD_GRAYSCALE)
# 显示图片
cv.imshow("gray",img)
# 获取图片信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义阈值
thresh = 60for row in range(height):for col in range(width):# 获取当前灰度值grayValue = img[row,col]if grayValue>thresh:img[row,col]=255else:img[row,col]=0# 直接调用api处理 返回值1:使用的阈值, 返回值2:处理之后的图像
# ret,thresh_img = cv.threshold(img, thresh, 255, cv.THRESH_BINARY)# 显示修改之后的图片
cv.imshow("thresh",img);cv.waitKey(0)
cv.destroyAllWindows()自适应阈值¶
我们使用一个全局值作为阈值。但是在所有情况下这可能都不太好,例如,如果图像在不同区域具有不同的照明条件。在这种情况下,自适应阈值阈值可以帮助。这里,算法基于其周围的小区域确定像素的阈值。因此,我们为同一图像的不同区域获得不同的阈值,这为具有不同照明的图像提供了更好的结果。
除上述参数外,方法cv.adaptiveThreshold还有三个输入参数:
该adaptiveMethod决定阈值是如何计算的:
- cv.ADAPTIVE_THRESH_MEAN_C:该阈值是该附近区域减去恒定的平均Ç。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值减去常数C的高斯加权和。
该BLOCKSIZE确定附近区域的大小和Ç是从平均值或附近的像素的加权和中减去一个常数
import cv2 as cv# 读取图像
img = cv.imread("assets/thresh1.jpg",cv.IMREAD_GRAYSCALE)
# 显示图片
cv.imshow("gray",img)
# 获取图片信息
imgInfo = img.shape# 直接调用api处理 参数1:图像数据 参数2:最大值 参数3:计算阈值的方法, 参数4:阈值类型 参数5:处理块大小 参数6:算法需要的常量C
thresh_img = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,11,5)# 显示修改之后的图片
cv.imshow("thresh",thresh_img);cv.waitKey(0)
cv.destroyAllWindows()THRESH_OTSU¶
采用日本人大津提出的算法,又称作最大类间方差法,被认为是图像分割中阈值选取的最佳算法,采用这种算法的好处是执行效率高!

import cv2 as cv# 读取图像
img = cv.imread("assets/otsu_test.png",cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)ret,thresh_img = cv.threshold(img, 225, 255, cv.THRESH_BINARY_INV)
cv.imshow("normal", thresh_img);gaussian_img = cv.GaussianBlur(img,(5,5),0)
cv.imshow("g",gaussian_img)ret,thresh_img = cv.threshold(gaussian_img, 0, 255, cv.THRESH_BINARY|cv.THRESH_OTSU)
cv.imshow("otsu", thresh_img);print("阈值:",ret)
cv.waitKey(0)
cv.destroyAllWindows()图像的噪声¶
如果我们把图像看作信号,那么噪声就是干扰信号。我们在采集图像时可能因为各种各样的干扰而引入图像噪声。在计算机中,图像就是一个矩阵, 给原始图像增加噪声, 我们只需要让像素点加上一定灰度即可. f(x, y) = I(x, y) + noise
常见的噪声有椒盐噪声(salt and pepper noise),为什么叫椒盐噪声?因为图像的像素点由于噪声影响随机变成了黑点(dark spot)或白点(white spot)。这里的“椒”不是我们常见的红辣椒或青辣椒,而是外国的“胡椒”(香料的一种)。我们知道,胡椒是黑色的,盐是白色的,所以才取了这么个形象的名字.
接下来我们来生成10%的椒噪声和盐噪声:
# 创建和原图同大小随机矩阵 胡椒噪声
pepper_noise = np.random.randint(0,256,(height,width))
# 创建和原图同大小随机矩阵 盐噪声
salt_noise = np.random.randint(0,256,(height,width))
# 定义10%的噪声 256×10%=25.6
ratio = 0.1
# 若值小于25.6 则置为-255,否则为0
pepper_noise = np.where(pepper_noise < ratio*256,-255,0)
# 若值大于25.6 则置为255,否则为0
salt_noise = np.where(salt_noise < ratio*256,255,0)我们还要注意,opencv的图像矩阵类型是uint8,低于0和高于255的值并不截断,而是使用了模操作。即200+60=260 % 256 = 4。所以我们需要先将原始图像矩阵和噪声图像矩阵都转成浮点数类型进行相加操作,然后再转回来。
# 将uint8类型转成浮点类型
img.astype("float")
pepper_noise.astype("float")
salt_noise.astype("float")# 将 胡椒噪声 添加到原图中
dst_img = img + pepper_noise
# 校验越界问题
dst_img = np.where(dst_img > 255,255,dst_img)
dst_img = np.where(dst_img < 0,0,dst_img)cv.imshow("pepper img",dst_img.astype("uint8"))# 将 盐噪声 添加到原图中
dst_img = img + salt_noise
# 校验越界问题
dst_img = np.where(dst_img > 255,255,dst_img)
dst_img = np.where(dst_img < 0,0,dst_img)cv.imshow("salt img",dst_img.astype("uint8"))# 将 椒盐噪声 添加到原图中
dst_img = img + pepper_noise + salt_noise
# 校验越界问题
dst_img = np.where(dst_img > 255,255,dst_img)
dst_img = np.where(dst_img < 0,0,dst_img)cv.imshow("pepper salt img",dst_img.astype("uint8"))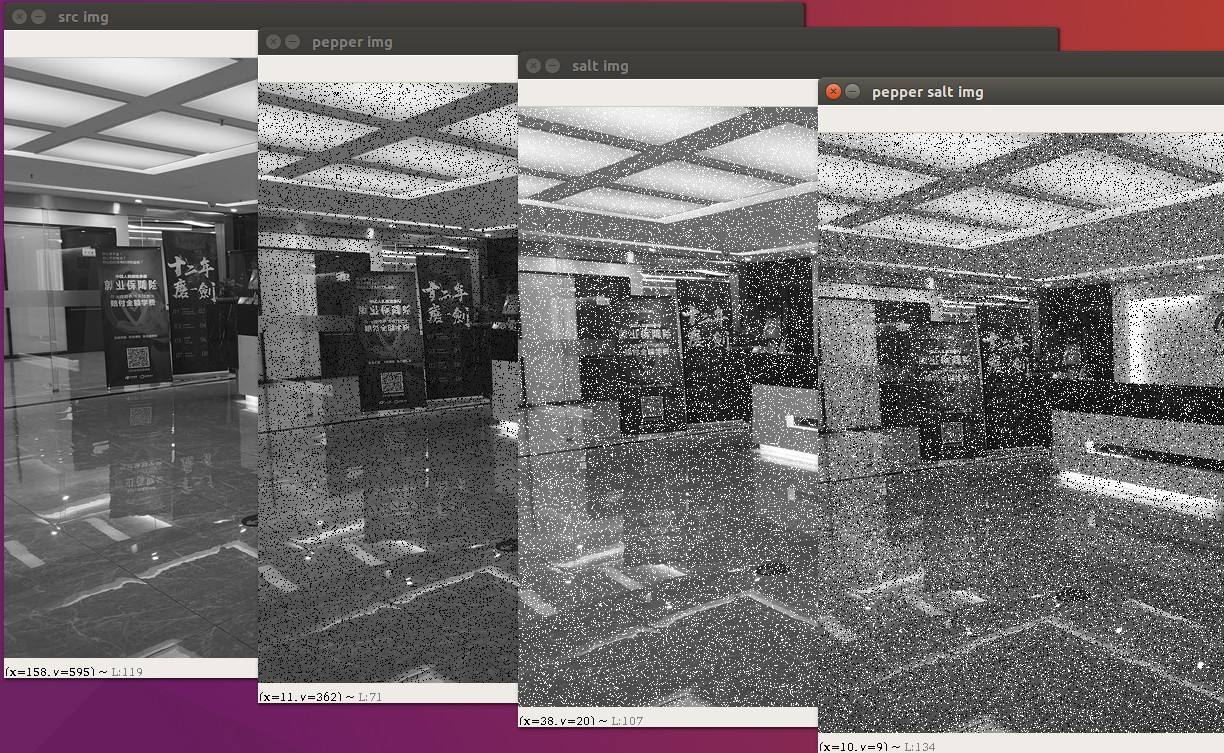
直方图匹配¶
直方图匹配又称为直方图规定化,是指将一幅图像的直方图变成规定形状的直方图而进行的图像增强方法。 即将某幅影像或某一区域的直方图匹配到另一幅影像上。使两幅影像的色调保持一致。可以在单波段影像直方图之间进行匹配,也可以对多波段影像进行同时匹配。两幅图像比对前,通常要使其直方图形式一致。
直方图规定化,也叫做直方图匹配,用于将图像变换为某一特定的灰度分布,也就是其目的的灰度直方图是已知的。这其实和均衡化很类似,均衡化后的灰度直方图也是已知的,是一个均匀分布的直方图;而规定化后的直方图可以随意的指定,也就是在执行规定化操作时,首先要知道变换后的灰度直方图,这样才能确定变换函数。规定化操作能够有目的的增强某个灰度区间,相比于,均衡化操作,规定化多了一个输入,但是其变换后的结果也更灵活。
直方图规定化的实现步骤如下:
- 计算原图像的累积直方图
- 计算规定直方图的累积直方图
- 计算两累积直方图的差值的绝对值
- 根据累积直方图最小差值建立灰度级的映射
| 灰度值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 原图累计概率 | 0.19 | 0.44 | 0.65 | 0.81 | 0.89 | 0.95 | 0.98 | 1.00 |
| 目标图累计概率 | 0 | 0 | 0 | 0.15 | 0.35 | 0.65 | 0.85 | 1.00 |
| 映射差值最小 | 0->3 | 1->4 | 2->5 | 3->6 | 4->6 | 5->7 | 6->7 | 7->7 |
import cv2 as cv
import matplotlib.pyplot as plt;
import numpy as np"""
直方图匹配: 让一张图参考另一张图, 让他们的色调保持一致步骤:计算原图累计直方图计算参考图的累计直方图计算两个累计直方图的差异生成原图和参考图之间的颜色映射
"""
# 计算单通道图像 累计概率
def getAccumulateRatios(img):height = img.shape[0]width = img.shape[1]# 1.计算直方图hist = cv.calcHist([img],[0],None,[256],[0,255])# print(hist)# plt.plot(hist)# plt.show()# 2.计算每个灰度值出现的概率ratios = hist/(height*width);# 3. 计算累计概率sumRatios = np.zeros(256,np.float32)sum1=0;for i,r in enumerate(ratios):sum1 = sum1 + r;sumRatios[i] = sum1;# 4. 绘制累计概率直方图# x = np.linspace(0,255,256);# plt.bar(x,sumRatios)# plt.show()return sumRatios;"""传入进来的数据仍然上单通道数据1. 计算累计直方图的差异找到最小的差异2. 获取颜色映射
"""
def map_color(src_channel,refer_channel):# src 单通道累计直方图src_sumRatios = getAccumulateRatios(src_channel);# refer 单通道累计直方图refer_sumRatios = getAccumulateRatios(refer_channel);colorMaps = np.zeros(256,np.uint8);# 遍历原图每一个灰度的累计概率for i,srcRatio in enumerate(src_sumRatios):# 得到 i: 灰度值 ratio :累计概率 0 0.19min = 100;referColor = 0;for j,referRatio in enumerate(refer_sumRatios):# j: 表示参考图的灰度值, referRatio累计概率diff = np.abs(srcRatio - referRatio)if diff < min:# 更新最小值min = diff;referColor = j;# 0 ---> referColorcolorMaps[i] = referColor;# print(colorMaps)return colorMaps;""" 完成单通道直方图匹配 """
def oneChannelMatch(src_channel,refer_channel):# 单通道颜色值映射colorMaps = map_color(src_channel, refer_channel);# 绘制原图直方图# cv.imshow("src",src_channel)# plt.hist(src_channel.ravel(),bins=256,color="blue")# plt.show()# 绘制参考图直方图# cv.imshow("refer", refer_channel)# plt.hist(refer_channel.ravel(), bins=256,color="green")# plt.show()one_channel = src_channelheight = one_channel.shape[0]width = one_channel.shape[1]for row in range(height):for col in range(width):# 获取原来的灰度值gray = one_channel[row, col];# 去颜色映射表中查找新的颜色值referColor = colorMaps[gray];# 替换为新的颜色值one_channel[row, col] = referColor;# 绘制生成之后的直方图# cv.imshow("dst", one_channel)# plt.hist(refer_channel.ravel(), bins=256, color="red")# plt.show()return one_channelif __name__ == '__main__':src = cv.imread("./img/lena.jpg",cv.IMREAD_COLOR)cv.imshow("src",src)refer = cv.imread("./img/image.png",cv.IMREAD_COLOR)cv.imshow("refer",refer)# 先计算src的累计直方图 , 计算单通道src_channels = cv.split(src)# 先计算refer的累计直方图 , 计算单通道refer_channels = cv.split(refer)dst_channel0 = oneChannelMatch(src_channels[0],refer_channels[0])dst_channel1 = oneChannelMatch(src_channels[1],refer_channels[1])dst_channel2 = oneChannelMatch(src_channels[2],refer_channels[2])dst = cv.merge([dst_channel0,dst_channel1,dst_channel2])cv.imshow("dst",dst)cv.waitKey(0)cv.destroyAllWindows()图片卷积¶
图像滤波是尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,是图像预处理中不可缺少的操作,其处理效果的好坏将直接影响到后续图像处理和分析的有效性和可靠性。
线性滤波是图像处理最基本的方法,它允许我们对图像进行处理,产生很多不同的效果。首先,我们需要一个二维的滤波器矩阵(卷积核)和一个要处理的二维图像。然后,对于图像的每一个像素点,计算它的邻域像素和滤波器矩阵的对应元素的乘积,然后加起来,作为该像素位置的值。这样就完成了滤波过程。
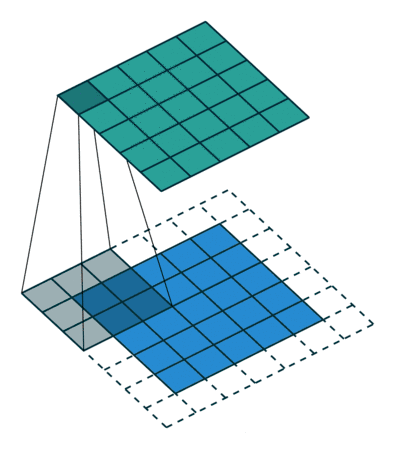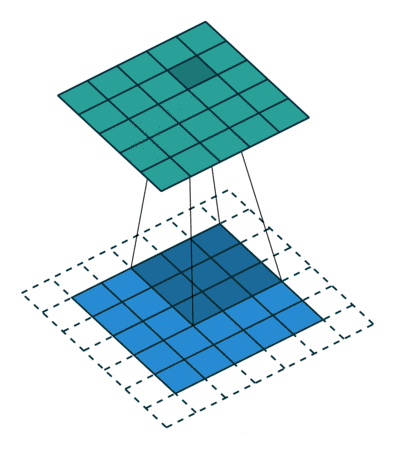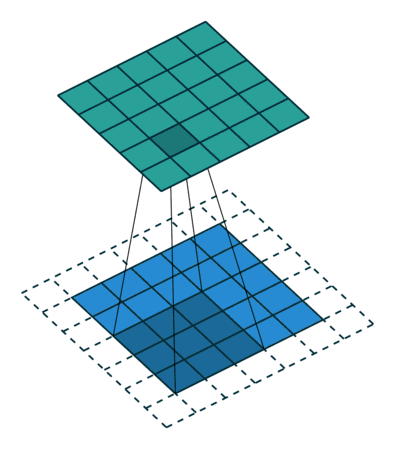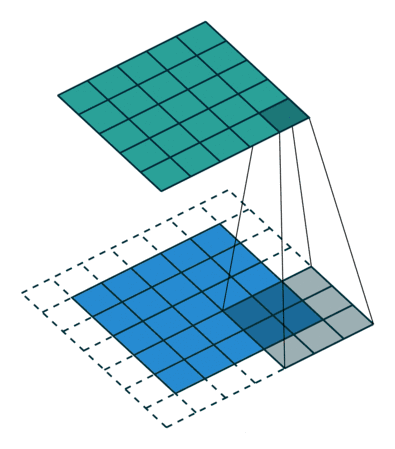
对图像和滤波矩阵进行逐个元素相乘再求和的操作就相当于将一个二维的函数移动到另一个二维函数的所有位置,这个操作就叫卷积
卷积需要4个嵌套循环,所以它并不快,除非我们使用很小的卷积核。这里一般使用3x3或者5x5。而且,对于滤波器/卷积核,也有一定的规则要求:
- 滤波器的大小应该是奇数,这样它才有一个中心,例如3x3,5x5或者7x7。有中心了,也有了半径的称呼,例如5x5大小的核的半径就是2
- 滤波器矩阵所有的元素之和应该要等于1,这是为了保证滤波前后图像的亮度保持不变。当然了,这不是硬性要求了。
- 如果滤波器矩阵所有元素之和大于1,那么滤波后的图像就会比原图像更亮,反之,如果小于1,那么得到的图像就会变暗。如果和为0,图像不会变黑,但也会非常暗。
- 对于滤波后的结构,可能会出现负数或者大于255的数值。对这种情况,我们将他们直接截断到0和255之间即可。对于负数,也可以取绝对值。
均值滤波¶
将卷积核内的所有灰度值加起来,然后计算出平均值,用这个平均值填充卷积核正中间的值,这样做可以降低图像的噪声,同时也会导致图像变得模糊
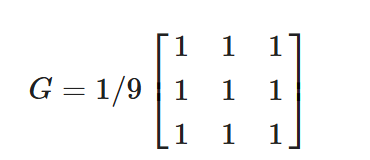
import cv2 as cvimg = cv.imread("./assets/itheima.jpg", cv.IMREAD_COLOR)
cv.imshow("src",img)dst = cv.blur(img, (3,3))
cv.imshow("dst",dst)cv.waitKey(0)
cv.destroyAllWindows()高斯模糊¶
采用均值滤波降噪会导致图像模糊的非常厉害,有没有一种方式既能保留像素点真实值又能降低图片噪声呢?那就是加权平均的方式. 离中心点越近权值越高,越远权值越低.
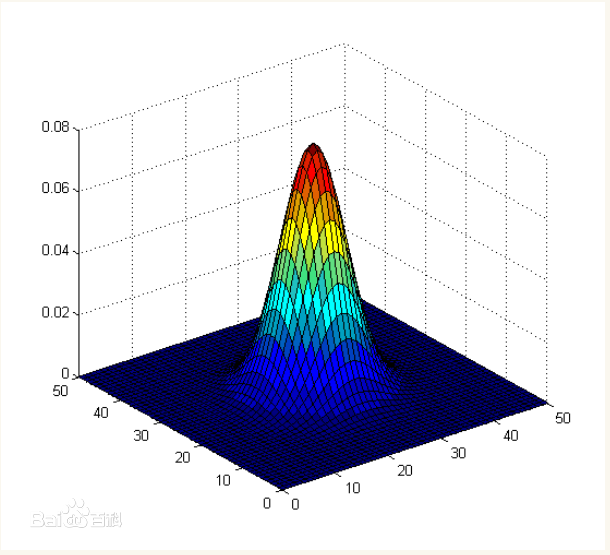
但是权重的大小设置非常麻烦,那么有没有一种方式能够自动生成呢? 这个就是需要用到高斯函数
高斯函数呈现出的特征就是中间高,两边低的钟形
高斯模糊通常被用来减少图像噪声以及降低细节层次。
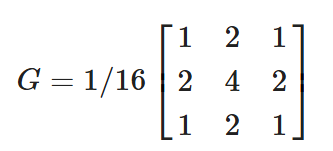
import cv2 as cv# 回调函数
def updateSigma(val):# 高斯模糊 参数1:图像 参数2:卷积核大小, 参数3:标准差越大,去除高斯噪声能力越强,图像越模糊gaussian_blur = cv.GaussianBlur(img, (5,5), val)cv.imshow("gaussian",gaussian_blur)img = cv.imread("assets/itheima.jpg", cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)
# 创建一个窗口
cv.namedWindow("gaussian",cv.WINDOW_AUTOSIZE)
# 创建一个窗口进度条: 参数1:名称 参数2:窗口名称 参数3: 起始值 参数4: 最大值, 参数5:回调函数
cv.createTrackbar("sigma","gaussian",0,255,updateSigma)updateSigma(0)cv.waitKey(0)
cv.destroyAllWindows()中值滤波¶
对邻近的像素点进行灰度排序,然后取中间值,它能有效去除图像中的椒盐噪声
操作原理: 卷积域内的像素值从小到大排序 取中间值作为卷积输出
import cv2 as cv
img = cv.imread("./assets/itheima_salt.jpg", cv.IMREAD_COLOR)
cv.imshow("src",img)dst = cv.medianBlur(img, 3)
cv.imshow("dst",dst)cv.waitKey(0)
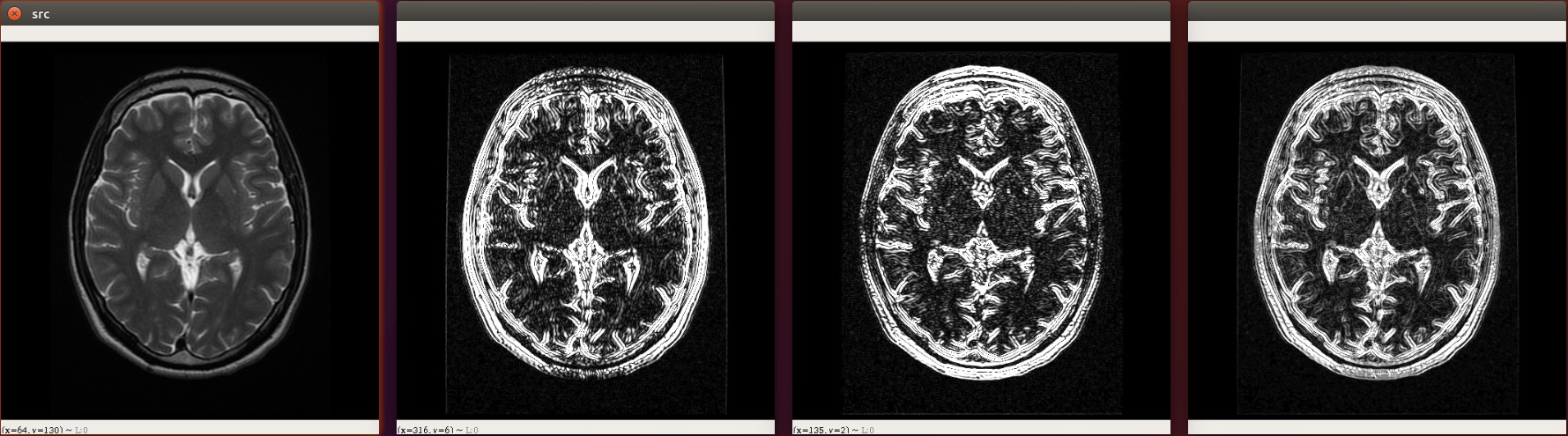
cv.destroyAllWindows()Sobel算子¶
Sobel算子是像素图像边缘检测中最重要的算子之一,在机器学习、数字媒体、计算机视觉等信息科技领域起着举足轻重的作用。在技术上,它是一个离散的一阶差分算子,用来计算图像亮度函数的一阶梯度之近似值。在图像的任何一点使用此算子,将会产生该点对应的梯度矢量
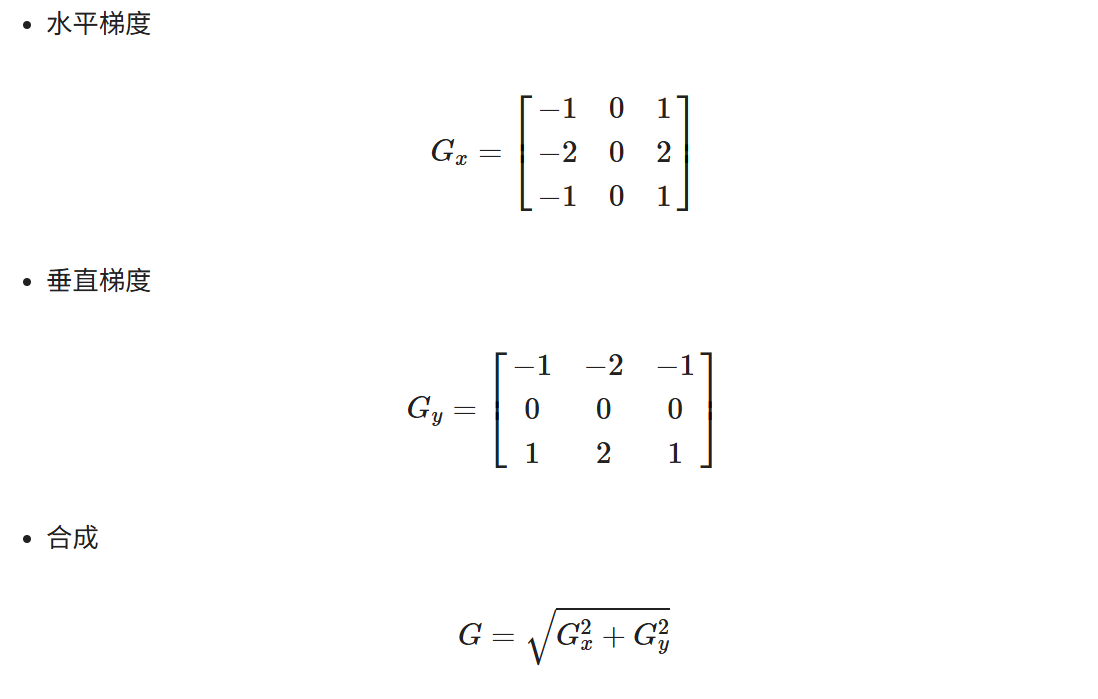
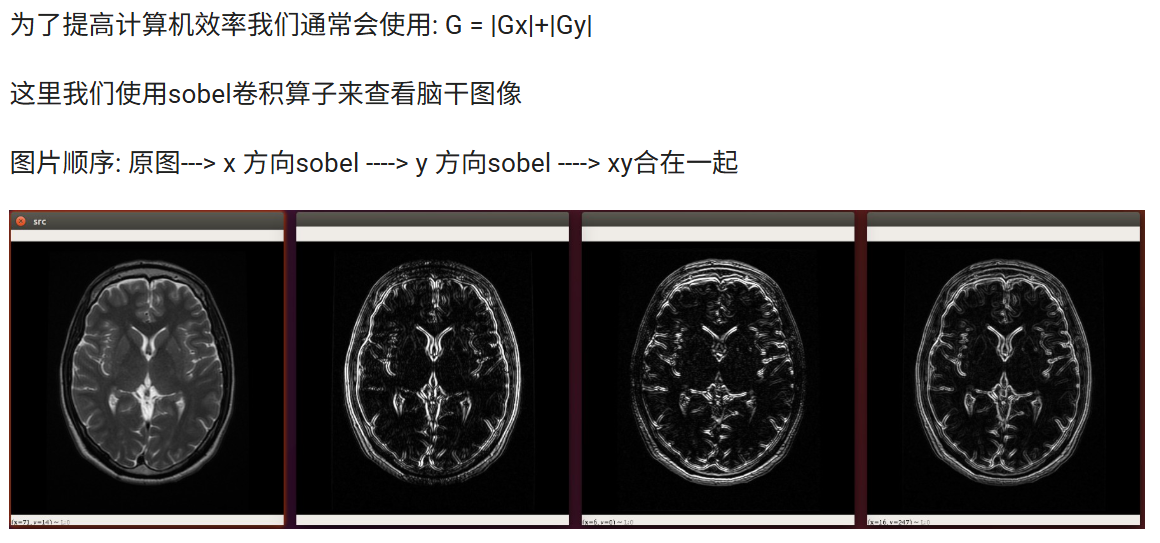
import cv2 as cvimg = cv.imread("./assets/brain.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)# sobel算子 参数1:图像, 参数2:图像的深度 -1表示和原图相同, 参数3: x方向求导的阶数 参数4: y方向求导的阶数
x_sobel = cv.Sobel(img, cv.CV_32F, 1, 0)
# 将图像转成8位int
x_sobel = cv.convertScaleAbs(x_sobel)cv.imshow("x sobel",x_sobel)# sobel算子
y_sobel = cv.Sobel(img, cv.CV_16S, 0, 1)
# 将图像转成8位int
y_sobel = cv.convertScaleAbs(y_sobel)
cv.imshow("y_sobel",y_sobel)# 将x,y方向的内容叠加起来
x_y_sobel = cv.addWeighted(x_sobel, 0.5, y_sobel, 0.5,0)
cv.imshow("x,y sobel",x_y_sobel)cv.waitKey(0)
cv.destroyAllWindows()由于使用Sobel算子计算的时候有一些偏差, 所以opencv提供了sobel的升级版Scharr函数,计算比sobel更加精细.
下面是使用Scharr计算出来的边缘图像
import cv2 as cvimg = cv.imread("./assets/brain.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)# sobel算子
x_scharr = cv.Scharr(img, cv.CV_32F, 1, 0)
# 将图像转成8位int
x_scharr = cv.convertScaleAbs(x_scharr)
cv.imshow("x scharr",x_scharr)# # sobel算子
y_scharr = cv.Scharr(img, cv.CV_16S, 0, 1)
# 将图像转成8位int
y_scharr = cv.convertScaleAbs(y_scharr)
cv.imshow("y scharr",y_scharr)# 将x,y方向的内容叠加起来
xy_scharr = cv.addWeighted(x_scharr, 0.5, y_scharr, 0.5,0)
cv.imshow("x,y scharr",xy_scharr)cv.waitKey(0)
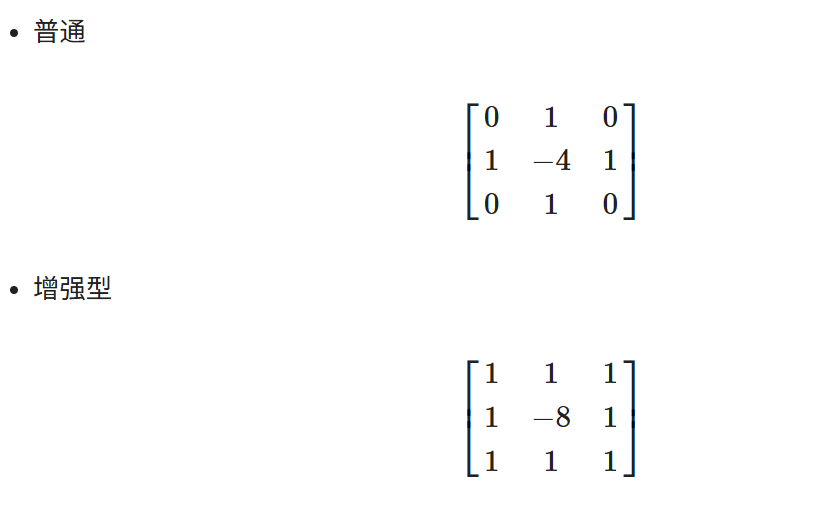
cv.destroyAllWindows()拉普拉斯算子¶
通过拉普拉斯变换后增强了图像中灰度突变处的对比度,使图像中小的细节部分得到增强,使图像的细节比原始图像更加清晰。
import cv2 as cvimg = cv.imread("./assets/grbq.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)# 使用拉普拉斯算子
dst = cv.Laplacian(img,cv.CV_32F)
# 取绝对值,将数据转到uint8类型
dst = cv.convertScaleAbs(dst)cv.imshow("dst",dst)cv.waitKey(0)
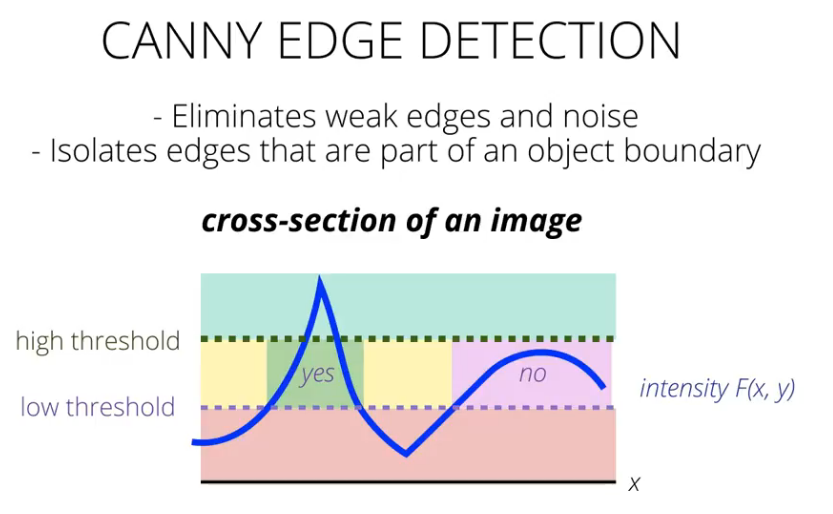
cv.destroyAllWindows();canny边缘检测算法¶
Canny算法由John F.Canny于1986年开发,是很常用的边缘检测算法。
它是一种多阶段算法,内部过程共4个阶段:
- 噪声抑制(通过Gaussianblur高斯模糊降噪):使用5x5高斯滤波器去除图像中的噪声
- 查找边缘的强度及方向(通过Sobel滤波器)
- 应用非最大信号抑制(Non-maximum Suppression): 完成图像的全扫描以去除可能不构成边缘的任何不需要的像素
- 高低阈值分离出二值图像(Hysteresis Thresholding)
- 高低阈值比例为T2:T1 = 3:1 / 2:1
- T2为高阈值,T1为低阈值

import cv2 as cv
import numpy as np
import random# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)# 1. 将图片转成灰度图片
grayImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 2. canny算法
dstImg = cv.Canny(grayImg,50,180)# 显示效果图
cv.imshow('dstimg',dstImg)
cv.waitKey(0)双边滤波¶
双边滤波其综合了高斯滤波器和α-截尾均值滤波器的特点,同时考虑了空间域与值域的差别,而Gaussian Filter和α均值滤波分别只考虑了空间域和值域差别。高斯滤波器只考虑像素间的欧式距离,其使用的模板系数随着和窗口中心的距离增大而减小;α-截尾均值滤波器则只考虑了像素灰度值之间的差值,去掉α%的最小值和最大值后再计算均值。
在opencv中,双边滤波的api已经提供好啦!
cv.bilateralFilter(输入图像, d, sigmaColor, sigmaSpace)src: 输入图像
d: 表示在过滤过程中每个像素邻域的直径范围。如果这个值是非正数,则函数会从sigmaSpace计算该值。
sigmaColor: 颜色空间过滤器的sigma值,这个参数的值越大,表明该像素邻域内有越宽广的颜色会被混合到一起,产生较大的半相等颜色区域。
sigmaSpace: 坐标空间中滤波器的sigma值,如果该值较大,则意味着越远的像素将相互影响,从而使更大的区域中足够相似的颜色获取相同的颜色.import cv2 as cv
# 将图片数据读取进来
img = cv.imread("img/timg.jpg",cv.IMREAD_COLOR)
cv.imshow('img',img)
# 双边滤波
dstImg = cv.bilateralFilter(img, 10, 50, 50)
# 显示改变之后的图像
cv.imshow('newimg',dstImg)
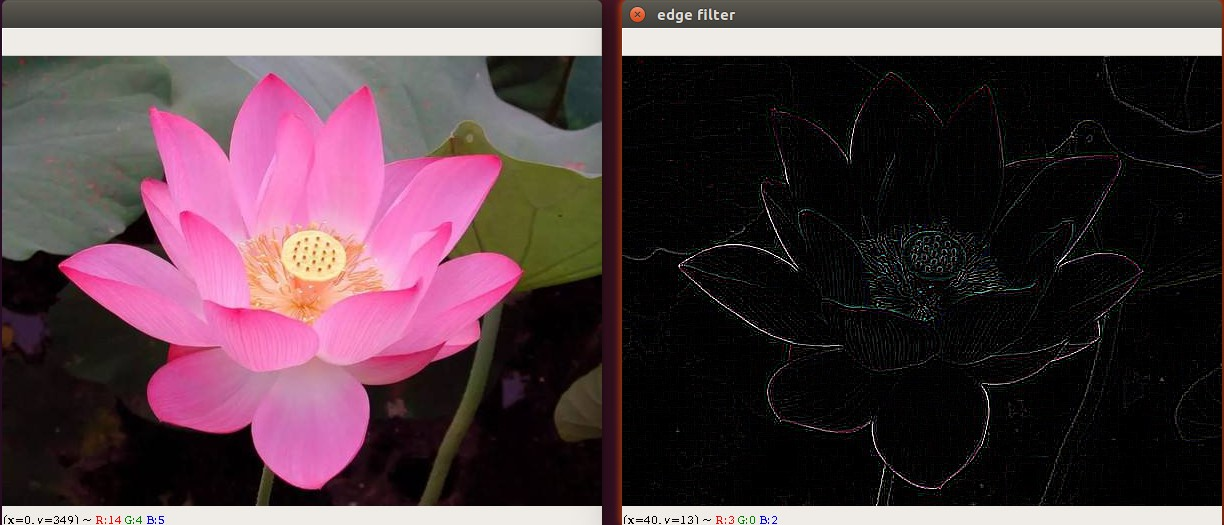
cv.waitKey(0)锐化滤波¶

图像的锐化和边缘检测很像,首先找到边缘,然后把边缘加到原来的图像上面,这样就强化了图像的边缘,使图像看起来更加锐利了

import cv2 as cv
import numpy as npimg = cv.imread("./assets/hehua.jpg",cv.IMREAD_COLOR)
cv.imshow("src",img)kernel = np.array([[-1,-1,-1],[-1,9,-1],[-1,-1,-1]])dst = cv.filter2D(img,-1,kernel)cv.imshow("sharpness filter",dst)cv.waitKey(0)
cv.destroyAllWindows()霍夫直线变换¶
霍夫直线变换(Hough Line Transform)用来做直线检测
OpenCV(十八)霍夫变换(直线、线段与圆检测)_霍夫直线检测函数-CSDN博客

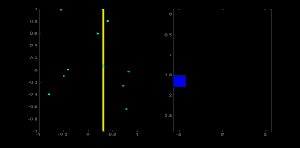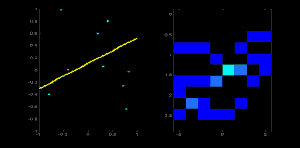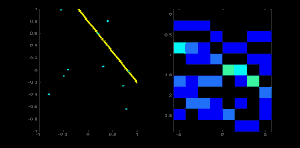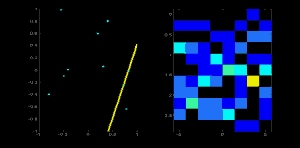
为了加升大家对霍夫直线的理解,我在左图左上角大了一个点,然后在右图中绘制出来经过这点可能的所有直线
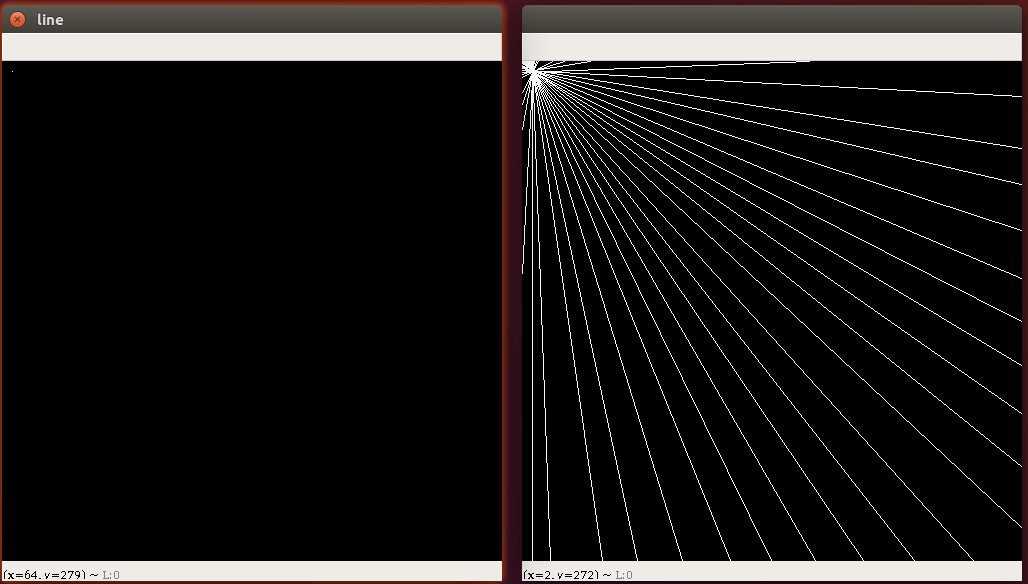
绘制经过某点的所有直线的示例代码如下,这个代码可以直接拷贝运行
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as npdef draw_line():# 绘制一张黑图img = np.zeros((500, 500, 1), np.uint8)# 绘制一个点cv.line(img, (10, 10), (10, 10), (255), 1)cv.imshow("line",img)return imgdef hough_lines(img):rho = 1;theta = np.pi/180threshold=0lines = cv.HoughLines(img,rho, theta, threshold)dst_img = img.copy()for line in lines[:,0]:rho,theta = linea = np.cos(theta)b = np.sin(theta)x = a*rhoy=b*rhox1 = int(np.round(x + 1000*(-b)))y1 = int(np.round(y + 1000*a))x2 = int(np.round(x - 1000*(-b)))y2 = int(np.round(y - 1000*a))cv.line(dst_img,(x1,y1),(x2,y2),(255,0,0),1)cv.imshow("li",dst_img)img = draw_line()
hough_lines(img)cv.waitKey(0)
cv.destroyAllWindows()练习:寻找棋盘中的直线¶
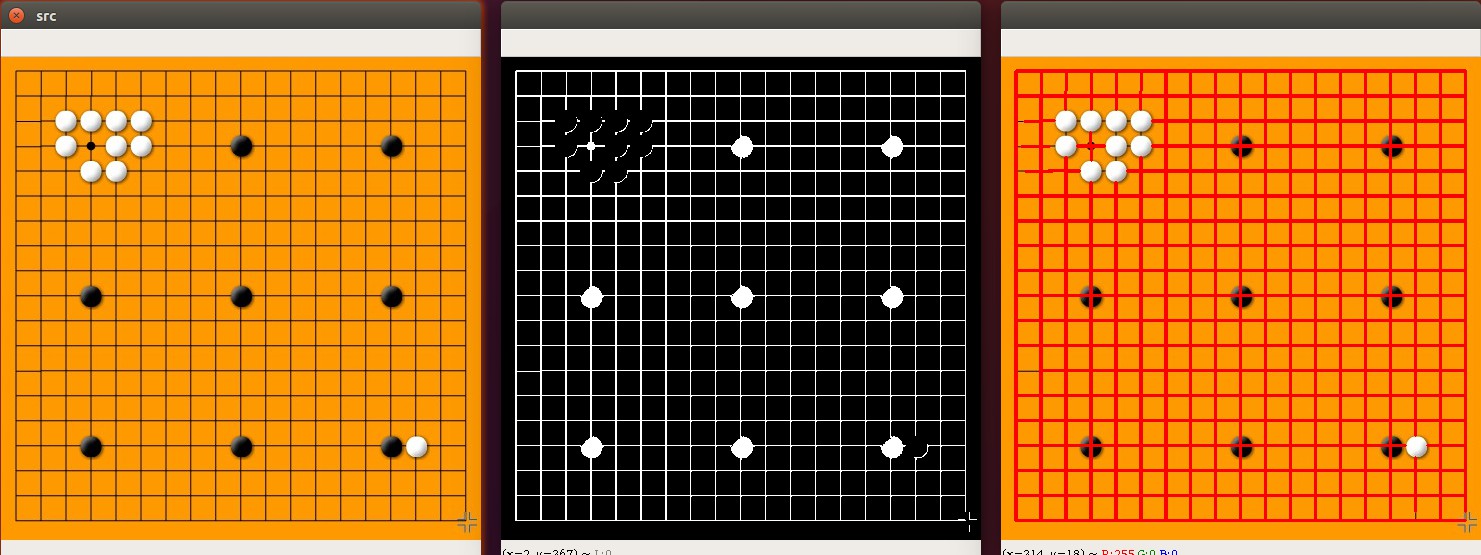
示例代码如下:
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np# 1. 将图片以灰度的方式读取进来
img = cv.imread("img/image.png", cv.IMREAD_COLOR)
cv.imshow("src",img)gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
# cv.imshow("gray",gray_img)
#
flag,thresh_img = cv.threshold(gray_img,100,255,cv.THRESH_BINARY_INV)
cv.imshow("thresh_img",thresh_img)# 3. 霍夫变换
# 线段以像素为单位的距离精度,double类型的,推荐用1.0
rho = 1
# 线段以弧度为单位的角度精度,推荐用numpy.pi/180
theta = np.pi/180
# 累加平面的阈值参数,int类型,超过设定阈值才被检测出线段,值越大,基本上意味着检出的线段越长,检出的线段个数越少。
threshold=10
# 线段以像素为单位的最小长度
min_line_length=25
# 同一方向上两条线段判定为一条线段的最大允许间隔(断裂),超过了设定值,则把两条线段当成一条线段,值越大,允许线段上的断裂越大,越有可能检出潜在的直线段
max_line_gap = 3lines = cv.HoughLinesP(thresh_img,rho,theta,threshold,minLineLength=min_line_length,maxLineGap=max_line_gap)dst_img = img.copy()for line in lines:x1,y1,x2,y2 = line[0]cv.line(dst_img,(x1,y1),(x2,y2),(0,0,255),2)cv.imshow("dst img",dst_img)cv.waitKey(0)
cv.destroyAllWindows()霍夫圆¶
一个圆可以由以下公式表示

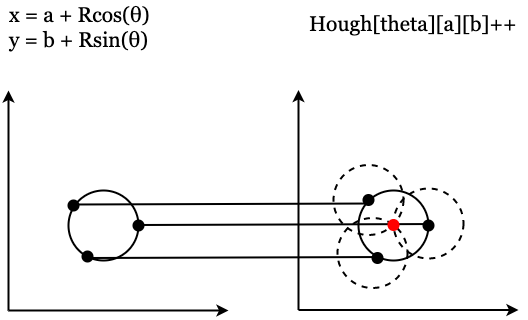
OpenCV的Logo检测结果:

- 参数及代码
def hough_circle(img):img_copy = img.copy()# 中值滤波降噪img_copy = cv2.GaussianBlur(img_copy, (3,3), 0)img_copy = cv2.medianBlur(img_copy, 5)gray = cv2.cvtColor(img_copy, cv2.COLOR_BGR2GRAY)cv2.imshow("gray", gray)"""@param 8-bit 单通道图片@param method 检测方法, 当前只有cv2.HOUGH_GRADIENT@param dp 累加器分辨率和图像分辨率的反比例, 例如:如果 dp=1 累加器和输入图像分辨率相同. 如果 dp=2 累加器宽高各为输入图像宽高的一半相同. @param minDist 检测到圆的圆心之间的最小距离。如果参数太小,除了真实的一个之外,可能错误地检测到多个相邻的圆圈。如果参数太大,可能会遗漏一些圆@param param1 参数1。它是两个传递给Canny边缘检测器的较高阈值(较低的阈值是此值的一半)@param param2 参数2, 它是检测阶段圆心的累加器阈值。它越小,会检测到更多的假圆圈。较大累加器值对应的圆圈将首先返回。@param minRadius 最小圆半径.@param maxRadius 最大圆半径. 如果<=0, 会使用图片最大像素值如果< 0, 直接返回圆心, 不计算半径"""# ../images/coins.jpgcircles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT,dp = 1,minDist = 50,param1=160,param2=50,minRadius=0,maxRadius=100)circles = np.uint16(np.around(circles))for i in circles[0, :]:# draw the outer circlecv2.circle(img_copy, (i[0], i[1]), i[2], (0, 255, 0), 2)# draw the center of the circlecv2.circle(img_copy, (i[0], i[1]), 2, (0, 0, 255), 3)cv2.imshow("detected circles", img_copy)寻找棋盘中的棋子¶
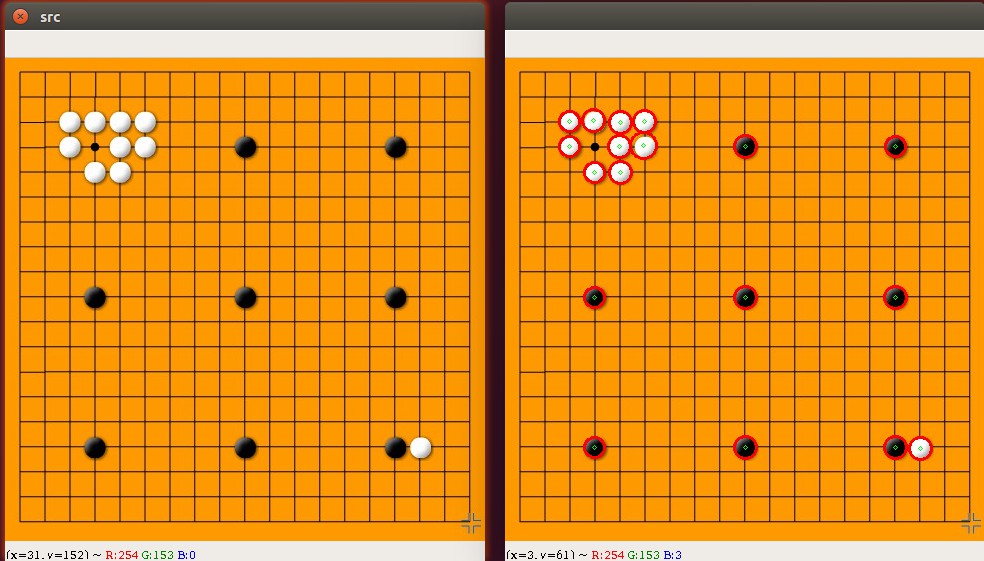
import cv2 as cv
import numpy as npimg = cv.imread("image.png", cv.IMREAD_COLOR)
cv.imshow("src",img)
# 将图片转成灰色图片
gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)# 霍夫圆形检测
def hough_circle(gray_img):# 定义检测图像中圆的方法。目前唯一实现的方法是cv2.HOUGH_GRADIENTmethod = cv.HOUGH_GRADIENT# 累加器分辨率与图像分辨率的反比。例如,如果dp = 1,则累加器具有与输入图像相同的分辨率。如果dp = 2,则累加器的宽度和高度都是一半。dp = 1# 检测到的圆的圆心之间最小距离。如果minDist太小,则可能导致检测到多个相邻的圆。如果minDist太大,则可能导致很多圆检测不到。minDist = 20# param1 Canny算法阈值上线# param2 cv2.HOUGH_GRADIENT方法的累加器阈值。阈值越小,检测到的圈子越多。# minRadius : 最小的半径,如果不确定,则不指定# maxRadius : 最大的半径,若不确定,则不指定circles = cv.HoughCircles(gray_img,method,dp,minDist=minDist,param1=70,param2=30,minRadius=0,maxRadius=20)for circle in circles[0,:]:# 圆心坐标,半径x,y,r = circlex,y,r = int(x),int(y),int(r)# 绘制圆心cv.circle(img,(x,y),2,(0,255,0),1)# 绘制圆形cv.circle(img,(x,y),r,(0,0,255),2)cv.imshow("result",img)# 调用函数,寻找霍夫圆
hough_circle(gray_img)cv.waitKey(0)
cv.destroyAllWindows()边缘与轮廓¶
- 基于图像边缘提取或二值化的基础寻找对象轮廓
- 边缘提取的阈值会最终影响轮廓发现的结果
- 主要API有以下两个
findContours发现轮廓drawContours绘制轮廓
查找轮廓¶
1 2 3 | |
- 轮廓检索模式
| RETR_EXTERNAL | 只检测最外层轮廓 |
|---|---|
| RETR_LIST | 提取所有轮廓,并放置在list中,检测的轮廓不建立等级关系 |
| RETR_CCOMP | 提取所有轮廓,并将轮廓组织成双层结构(two-level hierarchy),顶层为连通域的外围边界,次层位内层边界 |
| RETR_TREE | 提取所有轮廓并重新建立网状轮廓结构 |
- 轮廓检索算法
| CHAIN_APPROX_NONE | 获取每个轮廓的每个像素,相邻的两个点的像素位置差不超过1 |
|---|---|
| CHAIN_APPROX_SIMPLE | 压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的重点坐标,如果一个矩形轮廓只需4个点来保存轮廓信息 |
| CHAIN_APPROX_TC89_L1 | Teh-Chinl链逼近算法 |
| CHAIN_APPROX_TC89_KCOS | Teh-Chinl链逼近算法 |
绘制轮廓¶
1 | |

绘制外切圆¶
1 | |
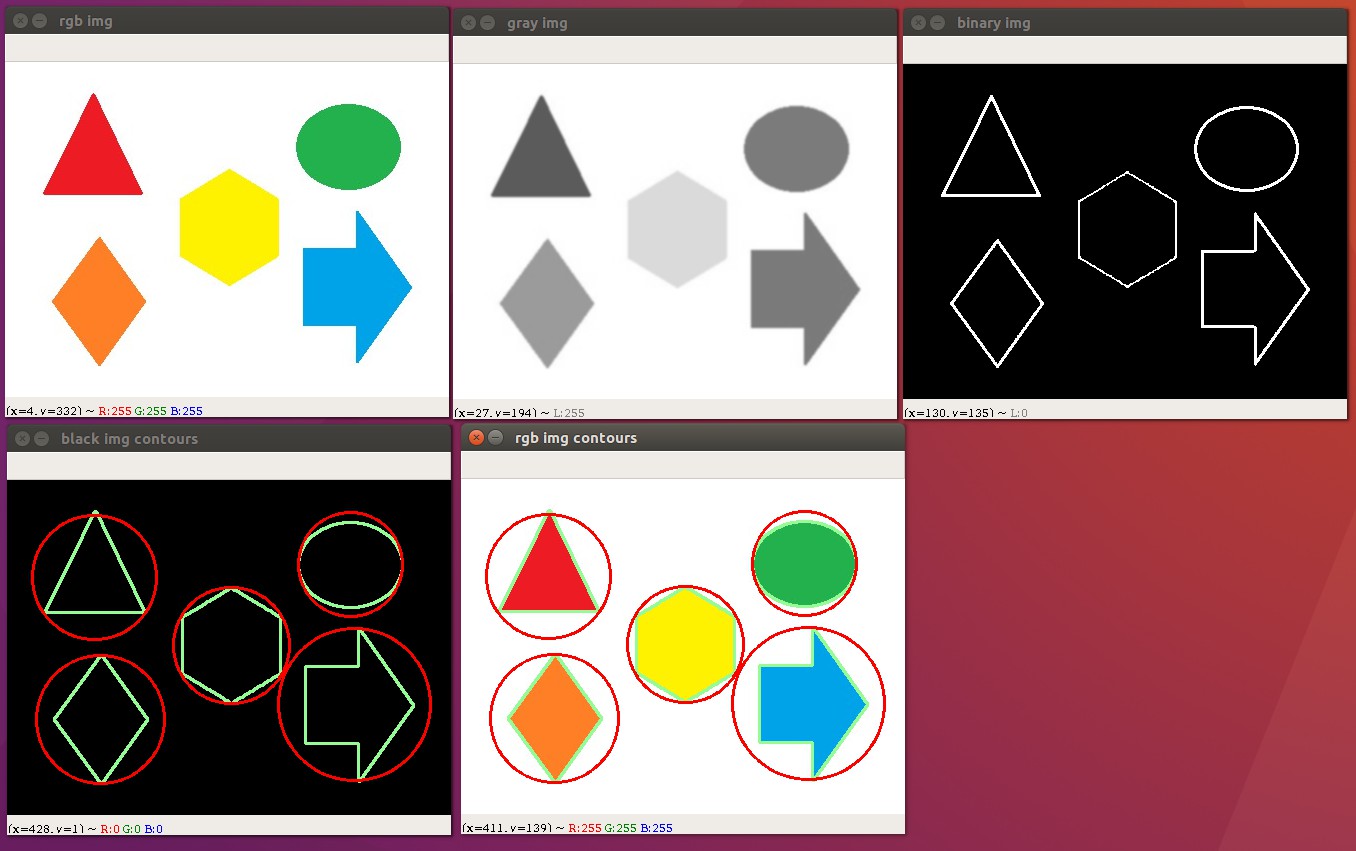
实现步骤:
- 读取图片
- 将图片转成一张灰色图片
- 对图片进行二值化处理
- 使用findContours查找轮廓
- 对轮廓进行处理
import cv2 as cvdef read_rgb_img(img_name):rgb_img = cv.imread(img_name,cv.IMREAD_COLOR)cv.imshow("rgb img",rgb_img)return rgb_imgdef convert_rgb2gray(img):gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)cv.imshow("gray img", gray_img)return gray_imgdef convert_gray2binary(img):binary_img = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,5,2)# _,binary_img = cv.threshold(img,50,255,cv.THRESH_BINARY_INV)cv.imshow("binary img", binary_img)return binary_imgdef getContours(img):_,contours,hierarchy = cv.findContours(img,cv.RETR_TREE,cv.CHAIN_APPROX_SIMPLE)print(contours,hierarchy)return contoursdef draw_contours(img,contours):index = -1 # 所有的轮廓thickness = 2 # 轮廓的宽度color = (255,125,125) # 轮廓的颜色cv.drawContours(img,contours,index,color,thickness)cv.imshow('draw contours',img)if __name__ == '__main__':img_name = "assets/shape0.jpg"rgb_img = read_rgb_img(img_name)gray_img = convert_rgb2gray(rgb_img)binary_imgage = convert_gray2binary(gray_img)contours = getContours(binary_imgage)draw_contours(rgb_img,contours)cv.waitKey(0)cv.destroyAllWindows()
形态学变换¶
膨胀与腐蚀¶
形态学变化是基于图像形状的一些简单操作。操作对象一般是二值图像,需要两个输入,一个是我们的原图,另一个是3x3的结构元素(内核),决定了膨胀操作的本质。常见的操作是图像的膨胀和腐蚀。以及他们的进阶操作注入Opening、Closing、Gradient等等。(参考)
结构元素的形状
| MORPH_RECT | 矩形 |
|---|---|
| MORPH_ELLIPSE | 椭圆形 |
| MORPH_CROSS | 十字型 |
膨胀Dilation¶
跟卷积操作非常类似.有图像A和3x3的结构元素,结构元素在A上进行滑动.计算结构元素在A上覆盖的最大像素值来替换当前结构元素对应的正中间的元素
膨胀的作用:
- 对象边缘增加一个像素
- 使对象边缘平滑
- 减少了对象与对象之间的距离

/*** 膨胀: 用内核中最大的值填充当前像素点的值*/
import cv2 as cvsrc = cv.imread("../img/morph-closing.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",src)kernel = cv.getStructuringElement(cv.MORPH_RECT,(5,5))dst = cv.dilate(src,kernel)
cv.imshow("dst",dst)
cv.waitKey()腐蚀Erosion

/*** 腐蚀: 用内核覆盖的最小像素值替换当前像素值*/
import cv2 as cvsrc = cv.imread("../img/morph-j.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",src)kernel = cv.getStructuringElement(cv.MORPH_RECT,(5,5))dst = cv.erode(src,kernel)
cv.imshow("dst",dst)
cv.waitKey()开操作Opening¶
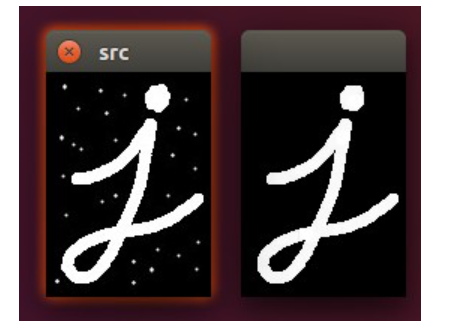
先腐蚀,后膨胀,主要应用在二值图像或灰度图像
先腐蚀: 让当前窗口中最小的颜色值替换当前颜色值
后膨胀: 让当前窗口中最大的颜色值替换当前颜色值
作用:
- 一般用于消除小的干扰或噪点(验证码图的干扰线)
- 可以通过此操作配合结构元素,提取图像的横线和竖线
示例代码
/*** 开操作: 先腐蚀,再膨胀*/
import cv2 as cvsrc = cv.imread("../img/morph-opening.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",src)kernel = cv.getStructuringElement(cv.MORPH_RECT,(5,5))dst = cv.morphologyEx(src,cv.MORPH_OPEN,kernel)
cv.imshow("dst",dst)
cv.waitKey()闭操作Closing¶
先膨胀,后侵蚀
一般用于填充内部缝隙

/*** 先膨胀再腐蚀*/
import cv2 as cvsrc = cv.imread("../img/morph-closing.jpg",cv.IMREAD_GRAYSCALE)
cv.imshow("src",src)kernel = cv.getStructuringElement(cv.MORPH_RECT,(5,5))dst = cv.morphologyEx(src,cv.MORPH_CLOSE,kernel)
cv.imshow("dst",dst)
cv.waitKey()小结¶
形态学变换中还有一些其它的变换,大家可以自行尝试查看执行效果
开运算先对图像腐蚀,再膨胀dst=open(src,element)=dilate(erode(src,element))闭运算先膨胀再腐蚀dst=close(src,element)=erode(dilate(src,element))形态梯度膨胀图和腐蚀图之差dst=morph_grad(src,element)=dilate(src,element)−erode(src,element)顶冒原图和开运算图之差dst=tophat(src,element)=src−open(src,element)黑冒闭运算结果和原图之差dst=blackhat(src,element)=close(src,element)−src模板匹配
模板匹配¶
模板匹配就是在整个图像区域发现与给定子图像匹配的小块区域。
在OpenCV中提供了6种匹配度量方法。
- 平方差匹配法CV_TM_SQDIFF
- 归一化平方差匹配法CV_TM_SQDIFF_NORMED
- 相关匹配法CV_TM_CCORR
- 归一化相关匹配法CV_TM_CCORR_NORMED
- 系数匹配法CV_TM_CCOEFF
- 化相关系数匹配法CV_TMCCOEFF_NORMED
通常来讲,随着从简单测量方法(平方差)到更复杂的测量方法(相关系数法),我们可以获得越来越准确的匹配。然而这同时也会以越来越大的计算量为代价。对于选取何种方法,针对不同的匹配情况进行对此分析比较,选取更适合自己应用场景同时兼顾速度和精度的最佳方案。 注意 :对于方法SQDIFF和SQDIFF_NORMED两种方法来讲,越小的值就有着更高的匹配结果,而其余的方法则是数值越大匹配效果越好。

import cv2 as cv# 加载原图
src = cv.imread("../img/zhaonimei.jpg")
cv.imshow("src",src)# 加载模板
temp = cv.imread("../img/mei.jpg")
cv.imshow("template",temp)result = cv.matchTemplate(src,temp,cv.TM_SQDIFF)# 将结果进行归一化处理
cv.normalize(result,result,0,1,cv.NORM_MINMAX)print(result)# 求最大值最小值
min,max,minLoc,maxLoc = cv.minMaxLoc(result)print(minLoc,maxLoc,min,max)cv.rectangle(src,(minLoc[0],minLoc[1]),(minLoc[0] + temp.shape[1],minLoc[1] + temp.shape[0]),(0,0,255),2)cv.imshow("dst",src)
cv.waitKey()车道线检测¶
本节我们使用opencv来完成一个车道线检测的案例,下图为案例最终处理的结果
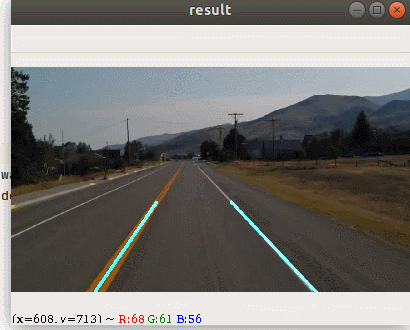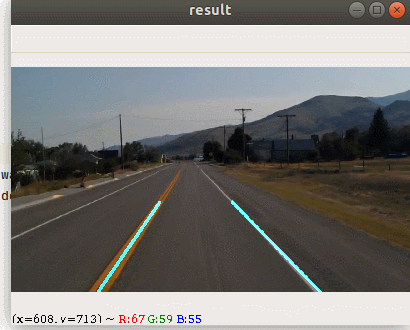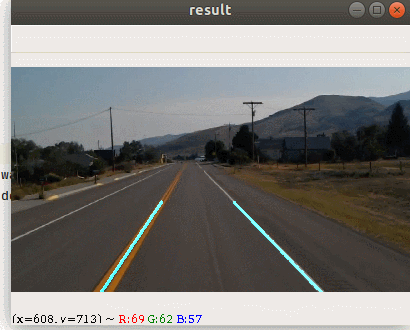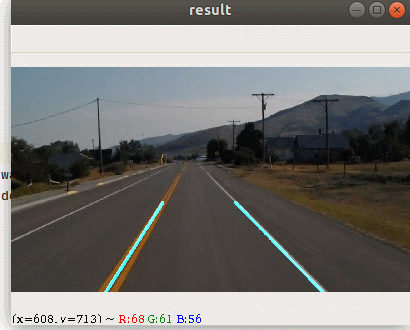
完成这样的案例我们需要经历哪些步骤呢 ? 我们先来思考一下解决问题的思路.当前情况下,摄像头拍出了很多的东西,例如路边的杂草远方的山.但是在我们自动驾驶的过程中,我们并不需要这么多东西,所以我们要考虑提取感兴趣的区域.有了感兴趣的区域之后,我们接下来就需要来识别道路.大家可能会想道路可能会有弯道,但是在小范围内,它还是直线,所以我们可以使用前面我们学过的霍夫直线来进行检测
这张摄像头拍摄到的照片

这张是我们使用canny边缘检测算法得到的图片

然后使用多边形截去不感兴趣的区域

通过以上三个步骤之后,下面我们就可以使用霍夫直线的方式,提取到车辆直线啦!
import cv2 as cv
import numpy as np
import matplotlib.pyplot as pltdef canny(image):gray = cv.cvtColor(image,cv.COLOR_BGR2GRAY);blur = cv.GaussianBlur(gray,(5,5),0)canny= cv.Canny(blur,50,100)return cannydef roi(image):height = image.shape[0]polygons = np.array([[(200,height),(1100,height),(550,250)]])mask = np.zeros_like(image);cv.fillPoly(mask,polygons,255)masked_image = cv.bitwise_and(image,mask)return masked_imagedef display_lines(image,lines):line_image = np.zeros_like(image);for line in lines:x1,y1,x2,y2 = line.reshape(4)cv.line(line_image,(x1,y1),(x2,y2),(255,255,0),10);return line_imagedef make_coordinates(image,parameters):slope = parameters[0]intercept = parameters[1]y1 = image.shape[0]y2 = int(y1*0.6)x1 = int((y1 - intercept)/slope)x2 = int((y2 - intercept)/slope)return np.array([x1,y1,x2,y2])def average_slop_intercept(image,lines):left_fit = []right_fit = []print(lines)for line in lines:x1, y1, x2, y2 = line.reshape(4)print(x1,y1,x2,y2)parameters = np.polyfit((x1,x2),(y1,y2),1)print(parameters)slope = parameters[0]intercept = parameters[1]if slope > 0 :left_fit.append((slope,intercept))else:right_fit.append((slope,intercept))#yongresult_lines = []if len(left_fit):left_fit_average = np.average(left_fit, axis=0)left_line = make_coordinates(image,left_fit_average)result_lines.append(left_line)if len(right_fit)>0:right_fit_average = np.average(right_fit, axis=0)right_line = make_coordinates(image,right_fit_average)result_lines.append(right_line)return result_linescv.namedWindow("result",cv.WINDOW_NORMAL)capture = cv.VideoCapture()
capture.open("test2.mp4")if capture.isOpened():flag = Truewhile flag:flag,image = capture.read();if not flag: break# image = cv.imread("test_image.jpg")lane_image = image # np.copy(image);print(lane_image.shape)canny_image = canny(lane_image)cropped_image = roi(canny_image)lines = cv.HoughLinesP(cropped_image,2,np.pi/180,100,minLineLength=40,maxLineGap=5)average_lines = average_slop_intercept(image,lines)lines_image = display_lines(lane_image,average_lines)combo_image = cv.addWeighted(lane_image,0.8,lines_image,1,1)cv.imshow("result",combo_image)cv.waitKey(10)cv.waitKey(0)
cv.destroyAllWindows()原文:直方图匹配 - 黑马机器人—OpenCV机器视觉:让机器看见世界!