NER实践总结,记录一下自己实践遇到的各种问题。
更。
没卡,跑个模型休息好几天,又闲又急。
一开始直接套用了别人的代码进行实体识别,结果很差,原因是他的词表没有我需要的东西,我是用的医学文本。代码直接在github找了改的,用的是BERT的Chinese版本。
然后想了解决办法就是使用自己创建词表的方法先处理一下整个文本数据,将高频词合并(1000个)。前一千个我自己去筛选。结果效果很差,很多没包含的,很多不是词也和一起了,非常烂(相当蠢的一个办法还浪费了很长时间大家别尝试了)。

然后想了新的解决办法是在网上找那种公开的医学书的目录,作为词表,比如某一章节讲高血压,就可以作为词表。因此去找了中华药典等之类的书,放入词表进行训练。效果还可以,但还是有很多错误。
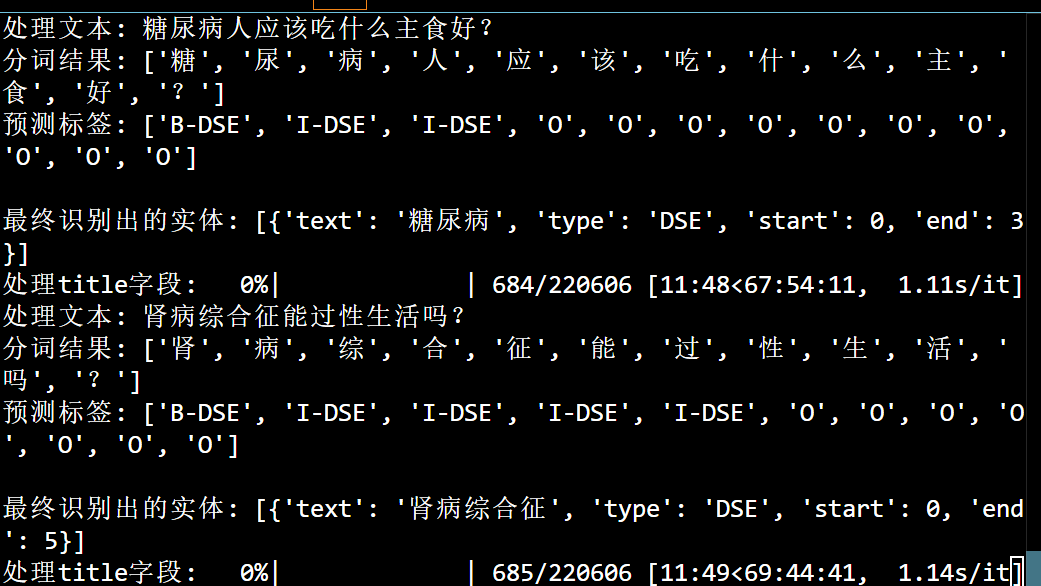
最后发现是因为没有提前删标点之类的东西,导致句子太长。因此使用re包重新处理了数据,再跑,效果相当不错。感人。
需要北美求职的小伙伴,可以私我哦,硅谷大厂大佬亲自求职陪跑!保证拿到实习offer~
此外还开发了一些小工具:
ai求职——Jobnova powered by Liba Space - Get the most timely job recommendations
ai面试——Jobnova powered by Liba Space - Get the most timely job recommendations
欢迎参与尝试。