核心机制:流量控制
搭配滑动窗口使用的
窗口大小
窗口越大,传输速度就越快,但是也不能无限大,太大了,对于可靠性会有影响
比如发生方以非常快的速度,发送,接收方的处理速度跟不上,也就会导致有效数据被接受方丢弃(又得重传)
流量控制,就是根据接收方的处理能力(如何衡量?),干预到发送方的发送速度(调整滑动窗口的大小)
应用程序调用 read 之类的操作(scanner.next)
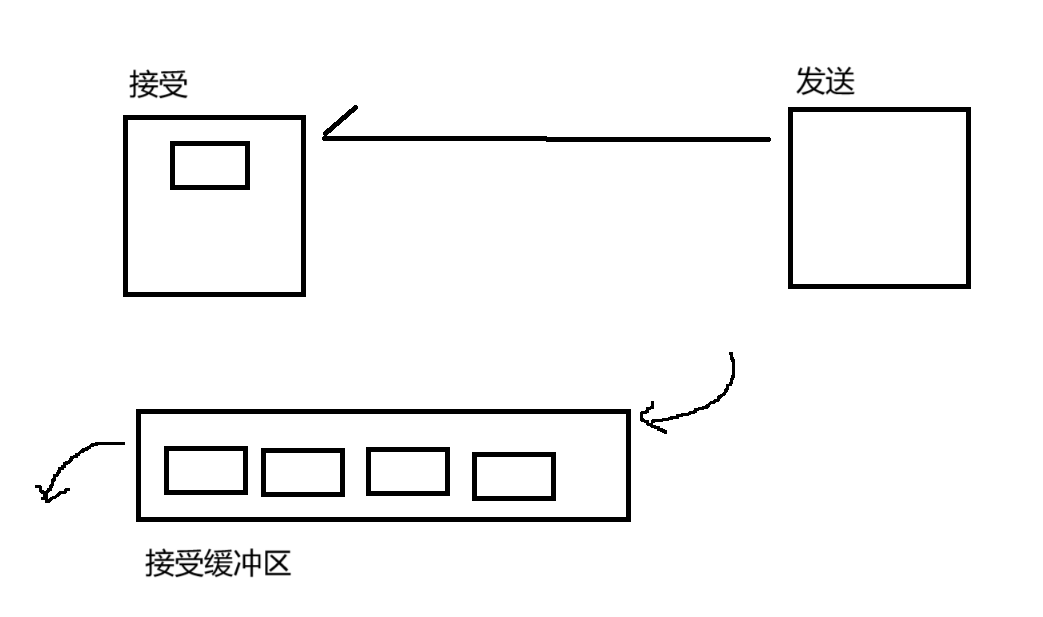
想象成"阻塞队列",如果队列里面没有数据,应用程序在 read 就会阻塞
生产者消费者模型
发送者是生产者,接受方是消费者,通过 TCP 的接受缓冲区,作为中转场地
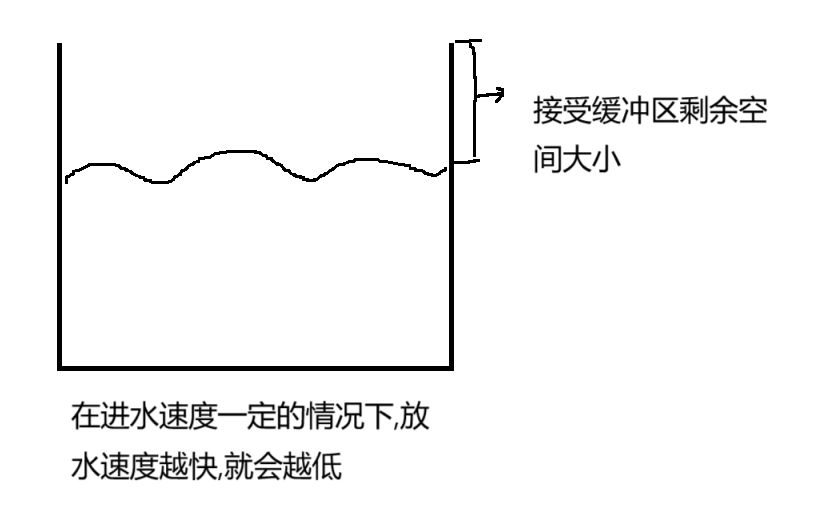
所谓的"接收方的处理能力"就是接收方应用程序调用 read 的速度(调用 read 有多快,每次 read 多少) 调用 read 的速度和应用程序,代码咋写的 是直接相关的,想要直接衡量 read,还不太容易得
read 到的数据,一定是有序的数据
使用另一个指标来衡量 read 的速度.直接看接受缓冲区的剩余空间的大小
接收 receive, 接受accept
连接 connection 链接 link
TCP 是"有连接" 不是 "有链接"
如果发现水位比较低,就可以认为放水的速度比较快(应用程序 read 的速度比较快)
接受缓冲区的剩余空间大小:以这个指标反向制约发送方的发送速度
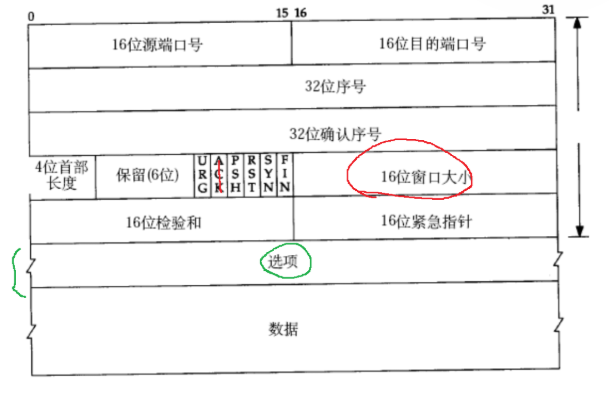
在接受方返回 ack 报文的时候,在 TCP 报头中把接受缓冲区剩余空间的大小 数值 ,放到 ack 的报头中,等发送方收到 ack 就知道接收方的处理速度了
发送方收到 ack 之后,就会根据窗口大小,重新设置下一轮 滑动窗口传输数据 窗口大小
16位 = > 64kb
是否意味着,TCP 的滑动窗口大小,最大只能是 64kb?? 并不是这样
TCP 在设计的时候,充分的吸取了以前 UDP 的教训,选项中有一个"窗口扩展因子"发送方收到 ack 之后,设置滑动窗口大小 16位窗口大小 << 窗口扩展因子,左移一位相当于 * 2,是指数增长的,这样的窗口大小的取值范围是非常非常大的
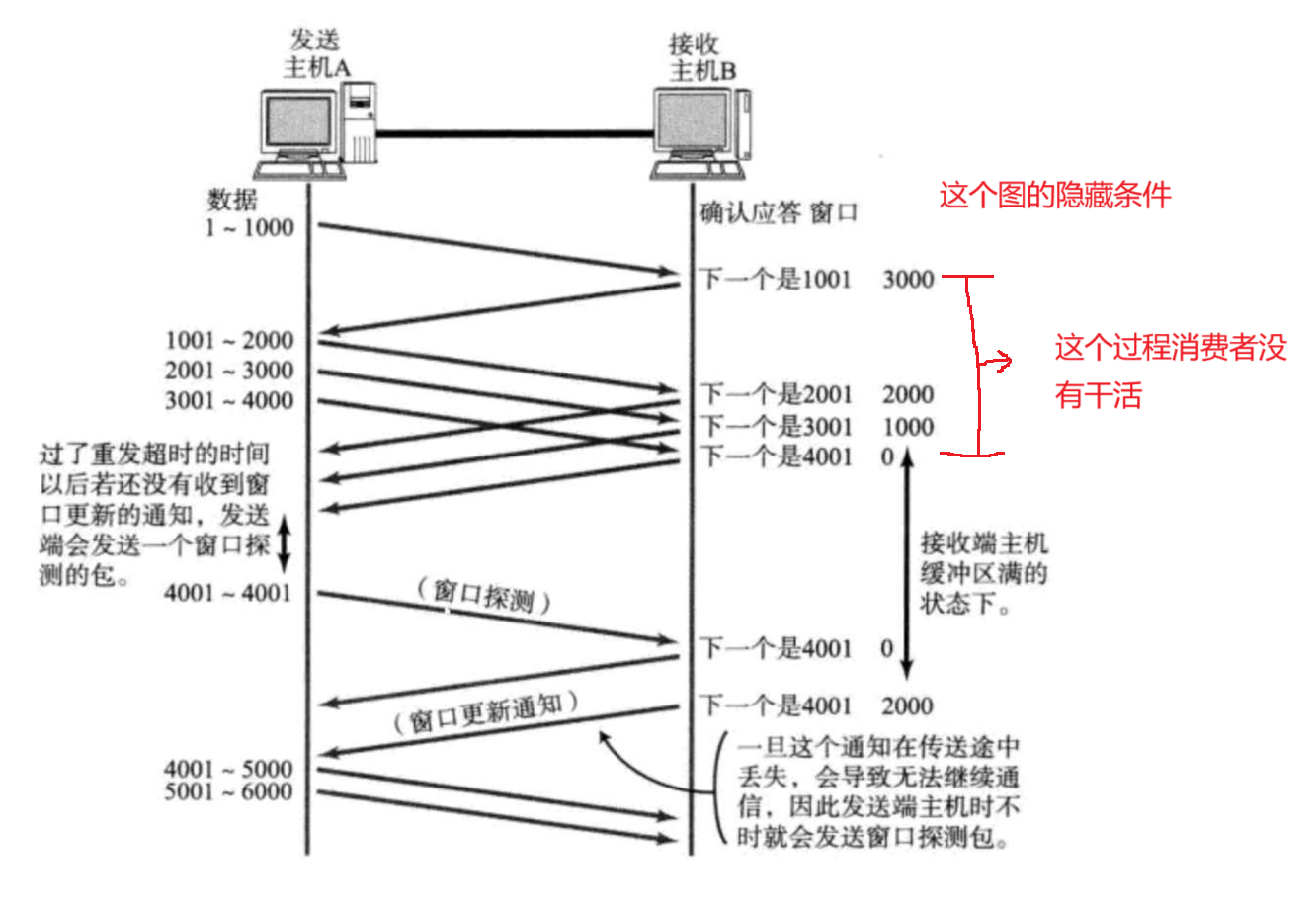
一般来说真实的情况是,大概率是一边收到数据,一边消耗数据
4001之后变成了 0 ,主机 A 这边就会暂停发送,队列满了,如果不暂停发送,接下来 A 数据就会被 B 丢掉,这个时候接受缓冲区更像是阻塞队列
A 不给 B 发数据,意味着 B 也就不给 A 返回 ack 了过了一会,主机 B 应用程序消耗了一部分数据
窗口探测包
当窗口大小为 0 的时候, A 只是不发送"业务数据"(TCP 载荷部分非空的数据,携带应用层数据包的数据) 但是 A 仍然会周期性的发送"窗口探测包"
另外 主机 B 也会在接受缓冲区不满的时候给 A 发一个"窗口更新包"