笔记︱数据科学领域因果推断案例集锦(第三弹)
之前的案例收集在了:
因果推断笔记——数据科学领域因果推断案例集锦(九)
笔记︱数据科学领域因果推断案例集锦(第二弹)
本篇为第三篇。
文章目录
- 1 因果推断在客户营销领域的挑战与应用
- 2 飞猪:因果推荐技术在营销和可解释性上的应用
- 2.1 保险红包推荐
- 2.2 贝叶斯网络
- 3 分布式因果推断在美团履约平台的探索与实践
- 4 阿里妈妈:CausalMMM:基于因果结构学习的营销组合建模
- 5 干货 | 携程火车票基于因果推断的业务实践
- 6 因果推断学习笔记 - 因果推断在搜推领域的应用
- 7 阿里妈妈:CausalMTA: 基于因果推断的无偏广告多触点归因技术
- 8 因果推断在腾讯视频增长业务的应用
- 9 基于因果推断的商家经营智能诊断实践
- 9.1 **混合因果网络发现新技术——HCM**
- 9.2 **基于因果的深度归因技术**
- 10 干货 | 贝叶斯结构模型在全量营销效果评估的应用
- 11 因果推断在转转推荐场景下的实践
1 因果推断在客户营销领域的挑战与应用
https://mp.weixin.qq.com/s/kEA6F8FT9staBev8jR9vuA
PSM 和业务系统的因果样本库
(1)PSM-PS 阶段
由于随机数据的稀缺性,我们在选取因果模型的训练数据时,必然要从已有的历史数据入手。我们使用倾向得分匹配(Propensity Score Matching)的方法,对历史数据计算倾向性得分,再对其进行匹配处理。倾向性得分是指一个具体的 x 个体被分配到实验组的概率 P(T=1|X=x)。
2)PSM-Matching 阶段
① 选择合适的样本对,对 PS 模型的分值进行分桶匹配。
② 设定合适的选取阈值以及选取数量。
③ 样本选取完成后,对数据分布,业务指标进行评估。
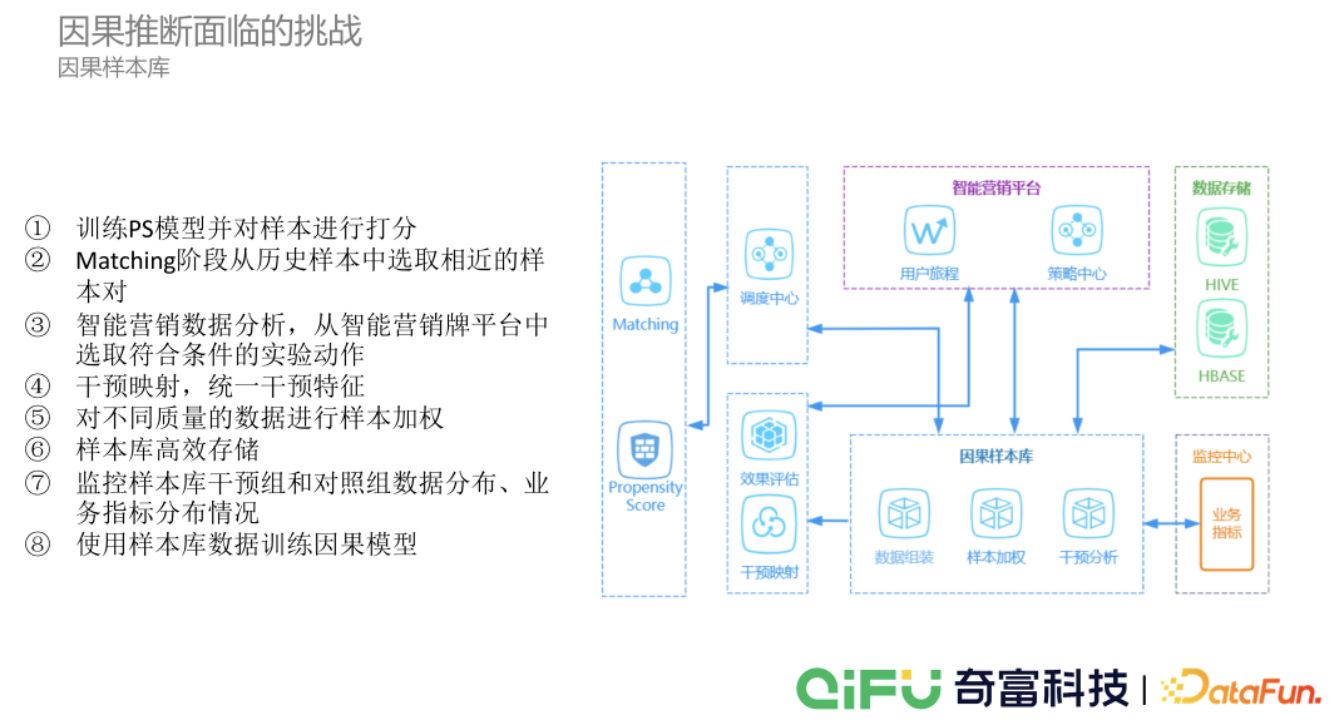
(3)建立因果样本库
① 训练 PS 模型并对样本进行打分。
② Matching 阶段从历史样本中选取相近的样本对。
③ 智能营销数据分析,从智能营销平台中选取符合条件的实验动作。
④ 干预映射,统一干预特征。
⑤ 对不同质量的数据进行样本加权。
⑥ 样本库高效存储。
⑦ 监控样本库干预组和对照组数据分布、业务指标分布情况。
⑧ 使用样本库数据训练因果模型。
因果推断业务实践
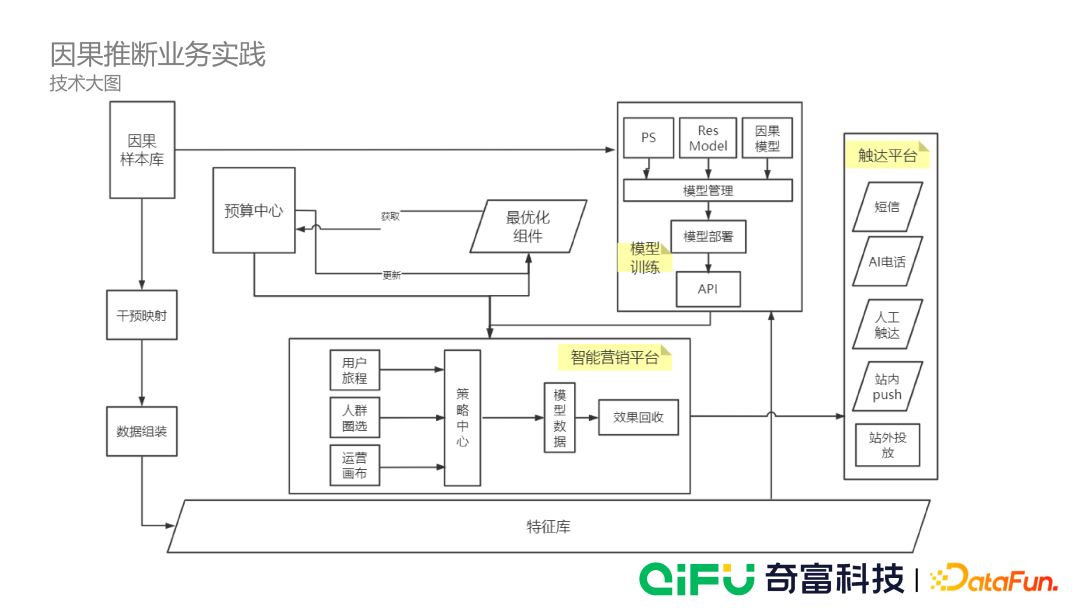
我们根据不同业务场景下的预算和构建的最优化组件,从智能营销平台中选取合适的训练样本,并对其进行干预映射与数据组装,形成可供机器学习模型使用的特征库,然后结合最优化组件与因果模型,再通过智能营销平台到不同的触达平台,从而把整个系统串联起来,完成 uplift 模型的实验与落地。
2 飞猪:因果推荐技术在营销和可解释性上的应用
https://mp.weixin.qq.com/s/M9RSzYiDvJ8L2Ux2VmFFRw
2.1 保险红包推荐
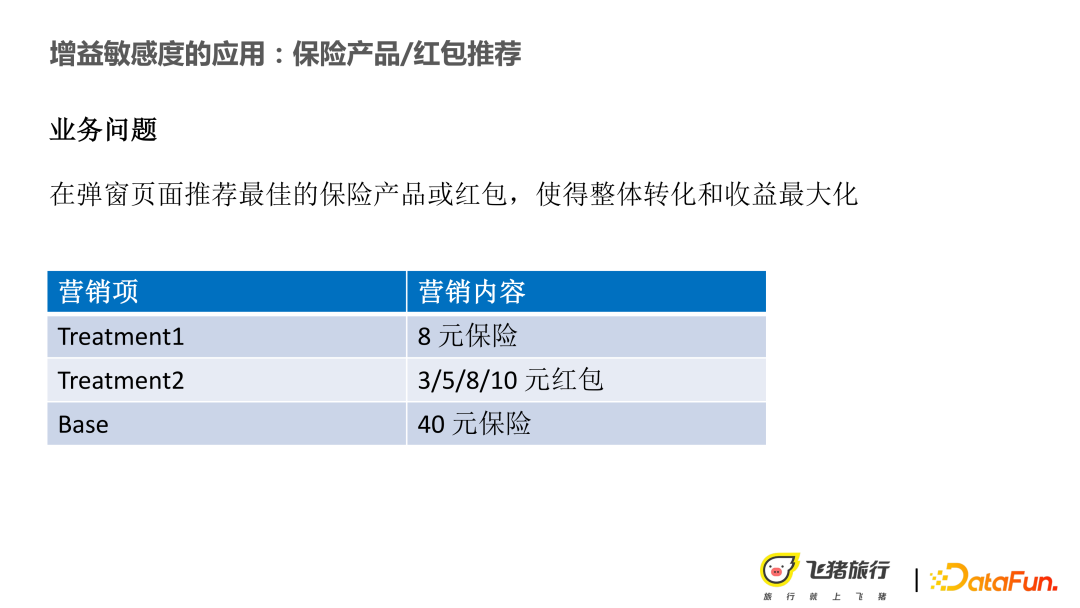
- AB 实验:A 是按原来的策略去投放,可能是 40 块钱的保险,也可能是运营来进行保险的定价,或者原始模型的一个定价。B 桶,低价保险投放。
- Label :用户是否转化成交。
- 模型:T/S/X-learner 以及各类的这种 Meta 模型。
- 样本特征:用户基础特征 + 历史购买商品的相对价格 + 红包使用频率 + 上下文价格相关特征等
模型对比:

表现最好的模型是 LR+T-Learner,其实不太符合原始的预期。后来思考了这个问题,也许问题出在用户对保险相关的价格特征的构建上,并不太足够去刻画。因为我们也去做了一些用户调研,比如用户的性格,对保险的敏感程度,这种 APP 域内的一些用户画像数据,能看到用户对一个无实物商品的感兴趣程度。但最终,还是基于这样的分数,去划定人群做投放,线上的 base 桶相对提升 5.8%。
其他两个案例:

2.2 贝叶斯网络
贝叶斯因果网络主要是表征事务间因果关系,有向五环图的结构。先简单介绍一下为什么要使用贝叶斯网络。在不同的推荐文案下,我们想知道用户为什么对文案感兴趣,或者说为什么能转化,其背后到底有哪些隐藏的变量。
如何建模,把网络里的节点和边构建成如下的几种:
① 用户节点,将年龄、性别这种用户画像的基础信息作为一个离散变量,成为一个节点。
② 事件节点,因为保险场景对事件的敏感性要高于很多其他的商品推荐,比如在天气或者节日下,用户可能会对延误险,或者某些有特定属性的保险比较敏感。
③ 创意节点,比如温馨类引导性文案、动态数字文案等都会有不同的效果。基于以上三大类节点,做条件概率计算,完成图的构建。
3 分布式因果推断在美团履约平台的探索与实践
https://mp.weixin.qq.com/s/ZS8ADvC_c3yxUuSLJkRFgA
我们不仅需要知道当前优惠券金额下,订单数是多少(预测问题),还要知道在改变金额的情况下,订单数会发生怎样的变化(反事实问题)。
工业界主流的分布式机器学习架构有AllReduce、ParameterServer、MapReduce三种,其中AllReduce性能最高(ParameterServer架构也可以和AllReduce结合,为了方便讨论,这里不再细究)。
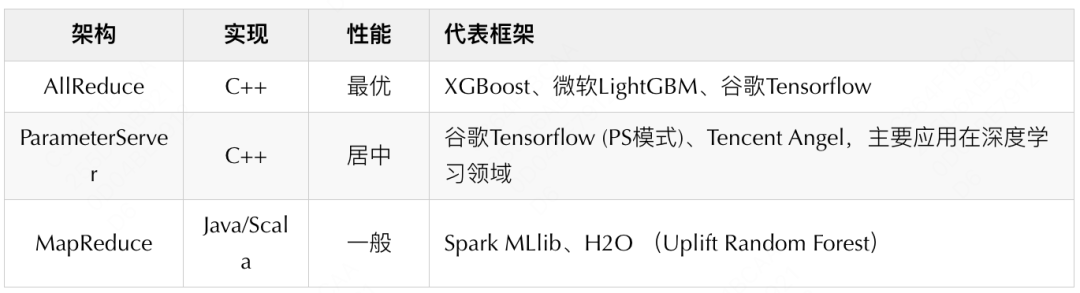
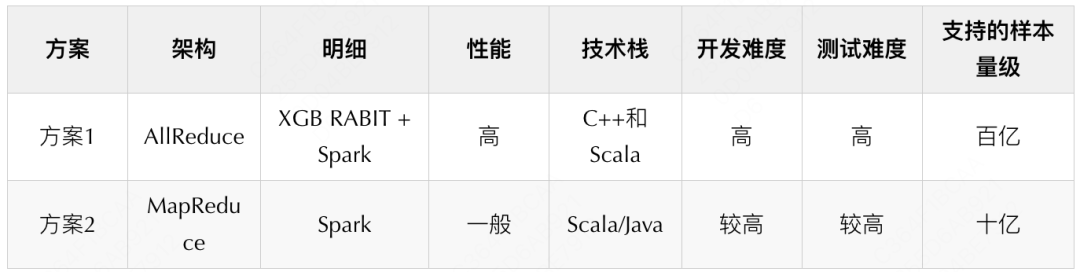
因为XGBoost内建了一个AllReduce框架RABIT可以直接复用,因此我们迅速拟定了两个调研方向——复用XGBoost的AllReduce高性能实现和Spark MapReduce实现。
4 阿里妈妈:CausalMMM:基于因果结构学习的营销组合建模
https://mp.weixin.qq.com/s/_Ln0Up5dukwXPWYQdLwMSQ
现有MMM工作大多可以分为两类:基于回归的方法、基于因果的方法。前者[1]基于不同渠道的消耗对GMV做回归,以回归系数解释各渠道重要性程度,但忽视了渠道之间的相互影响,影响模型的解释能力;
后者[2]大多从先验知识出发预先定义因果结构,但忽略了不同商铺之间因果结构的异质性,难以用于实际场景中指导决策。
因此,从传统MMM出发引入因果发现方法,动态挖掘不同店铺的因果结构,显得尤为重要。
在MMM任务中动态挖掘因果结构并非易事,存在以下挑战:
- 挑战一:因果异质性(Causal Heterogeneity)不同店铺特点和不同时期,渠道的因果结构和动态会有所不同。
- 挑战二:营销响应模式(Marketing Response Patterns)在前人的研究[3]中,已经验证了广告效果随投入发生响应的几种重要模式,如溢出效应和饱和效应。如图2(b)所示,广告投入的影响会随时间衰减,并随着投入的增加而饱和。
CausalMMM是一种基于图变分自编码器的方法,由两个关键模块组成:因果关系编码器(Causal Relational Encoder)和营销响应解码器(Marketing Response Decoder)。
在因果关系编码器中,我们对店铺的历史数据进行编码,以Gumbel softmax采样生成特定的因果结构。
基于因果结构,营销响应解码器被设计为满足营销响应模式的先验条件,并实现良好的预测性能。解码器中集成了顺序模型和S曲线转换,分别捕获了溢出和饱和效应。
5 干货 | 携程火车票基于因果推断的业务实践
https://mp.weixin.qq.com/s/SqLv9G_MDqStM-aLxqaIhg
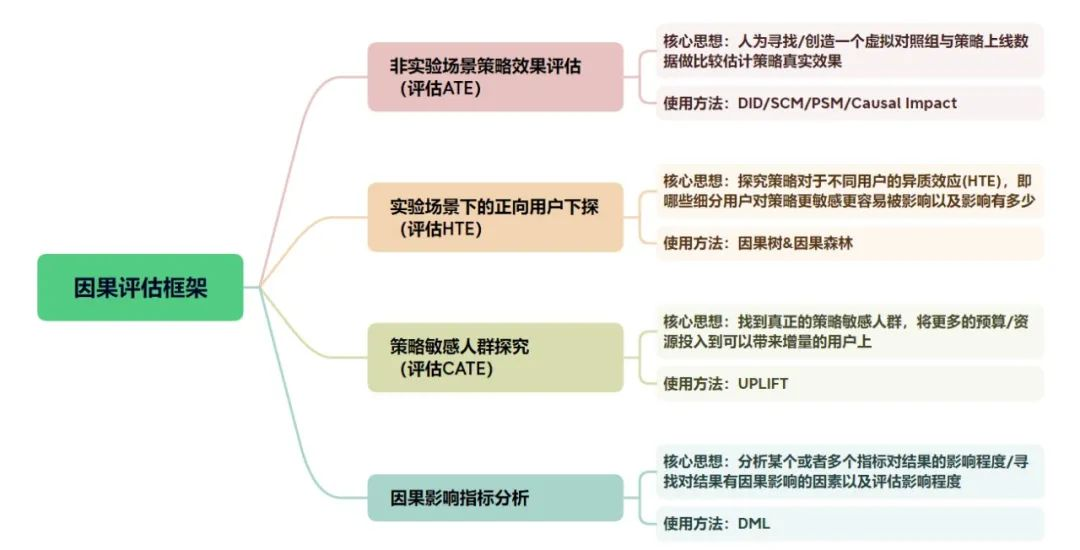
实践总结,因果推断方法常见的使用场景有以下四种(如图4-1):
场景一:非实验场景策略效果评估问题判别:评估计算的是群体效应(ATE)、无法进行 AB 实验。
- 核心思想:人为创造一个虚拟对照组与策略上线数据做比较估计策略真实效果。
- 使用方法:PSM\SCM\Casual Impact\DID。
- 常见场景:
- a. 北京市新建立了一个机场,对我们的订单的影响。
- b. 微信公众号突然更改提醒方式,对我们用户触达转化率的影响。
- c. 研究政策影响方面:例如某地区通过法律将最低工资每小时 4.25 美元提高到 5.05 美元,相邻的某地区保持不变,是否会提高就业人数。
场景二:实验场景下的正向用户下探
- 问题判别:探究干预(策略)对于不同用户的异质效应(又叫 HTE),指的是哪些细分用户对策略更敏感更容易被影响以及影响有多少,更好的归因和理解不同的用户群,传统做法是多维分析,效率低,容易犯错。
- 核心思想:对某个干预敏感度最大的一批人。
- 使用方法:因果树/因果森林。
- 常见场景:通常情况下,是结合实验来做分析的。
场景三:策略敏感人群探究
- 问题判别:找到真正的干预(策略)敏感人群,将预算/资源投入到这批人群。
- 核心思想:对期望结果(如下单转化等)进行归因,寻找由于某个干预而引发期望结果的人群。
- 使用方法:Uplift Model。
- 常见场景:用户营销场景,节省成本、提升 ROI。
a. 现在公司有一批预算,可以给用户发送优惠券提升用户购买率,应该发给平台的哪些用户。
场景四:因果影响指标分析
- 问题判别:分析某个或者多个指标对结果的影响程度或者寻找对结果有因果影响的因素以及评估影响程度。
- 核心思想:基于历史观测数据进行因果建模,解决多重共线性问题和自变量和因变量的非线性问题。因果推断经常会遇到混淆变量的问题,比如我们想要去分析直播推荐多样性(指标 D)对用户活跃度(指标Y)的影响,但此时存在很多变量 X 既与 D 相关又与 Y 相关。
6 因果推断学习笔记 - 因果推断在搜推领域的应用
https://mp.weixin.qq.com/s/Zu-cWFqx8yAZGyrasbzPVw
搜索推荐系统的系统性bias有很多,部分列举如下:
- selection bias:一个用户必然只能给一小部分最感兴趣物品打分,类似于投入优惠券但用户可以有选择的领券,这就造成如豆瓣网上部分动画番剧特别小众但评分巨高的现象。
- conformity bias:用户存在从众效应,这点在娱乐方向非常明显:一首歌爆红与否不一定取决于本身的质量好坏,如果大量视频采用其作为配乐,自然就会变得火起来。
- exposure bias:推荐系统的召回-排序过滤了绝大部分物品,物品并不是以均等的概率曝光给用户,所以用户只能基于曝光的部分物品给推荐系统以反馈,然后得到反馈的推荐系统再基于这些有偏的数据给用户推荐下一批物品。
- position bias:不同物品曝光的时间和位置都是不同的,在很多场景下,位置本身带来的 bias 非常大,如果不考虑 position bias,那么 top1 物品很可能会得到最高的转化率并且永远保持在第一位。
在这些 bias 中,研究最透彻的是 position bias。
- 最简单的去除 position bias 的方法是在训练时把样本 position 作为特征输入模型,在预测时 position 填0。
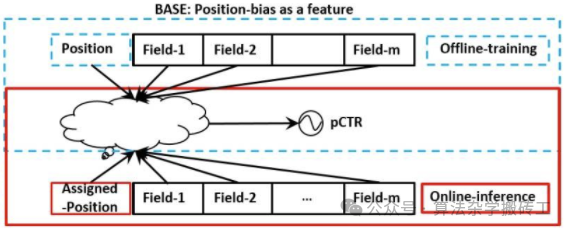
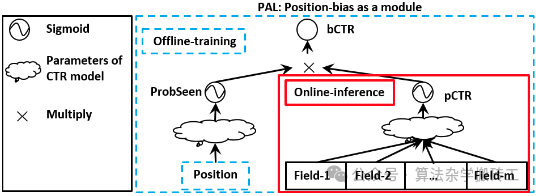
更为经典的方法是华为提出的 position-bias aware learning(PAL),如下图,左边网络得到 position bias,右边网络得到用户-物品无偏转化率,两者分别 sigmoid 后相乘得到 CTR。
7 阿里妈妈:CausalMTA: 基于因果推断的无偏广告多触点归因技术
https://mp.weixin.qq.com/s/KJnmfIUiwYZWU3WheRL_cA
基于因果推断技术的无偏广告多渠道归因模型 MTA,消除了用户静态与动态混淆偏差的影响,从而训练无偏的转化预测模型
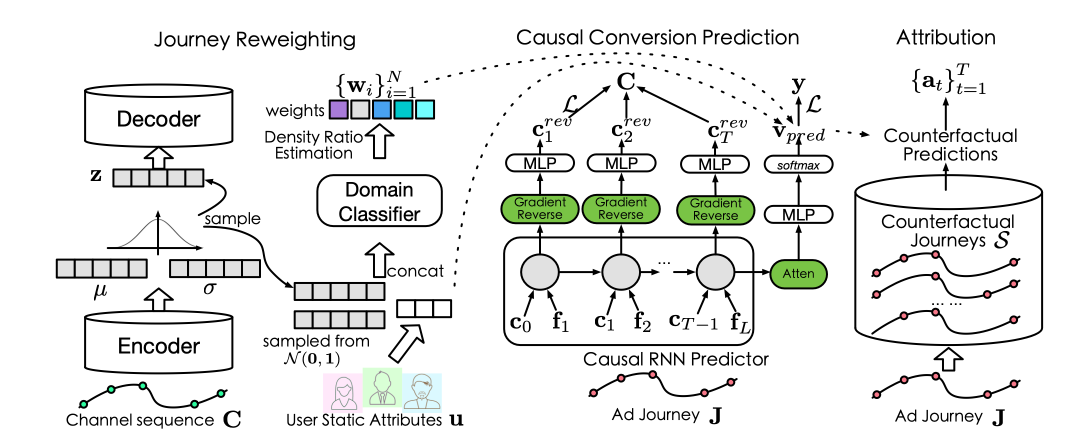
CausalMTA的model-agnostic框架,如图三。
该框架有两大关键模块:
- 用户浏览路径重加权(journey reweighting)
- 因果转化预测(causal conversion prediction)
两大模块分别消除静态与动态特征的影响。
在用户浏览路径重加权中,本文使用变分循环自编码器学习广告序列的生成概率,然后采用密度比估计方式计算每条样本的权重,基于IPTW的方式对观测数据集重加权得到消除静态混淆变量影响的数据分布。
在因果转化预测中,本文采用RNN来建模用户路径的动态特征,并采用梯度反转层得到解耦动态特征与广告曝光的均衡表征。
从而得到无偏的转化预估模型。经过两个模块消除静态与动态特征的偏差后,得到无偏的预测模型,最后采用Shapley Values的计算方式完成触点权重的分配。
8 因果推断在腾讯视频增长业务的应用
https://mp.weixin.qq.com/s/Dh5Fqy_KSJD3psUdFkWo7Q
因果推断工具Spark CausalML,目前较为常用的CausalML/DoWhy(PyWhy)/MatchIt等包仅限于单机性能,无法对百万级及以上的数据量级进行建模,因此我们开发了分布式PySpark版本,满足大样本因果推断需求。Spark CausalML是一个用来做因果的PySpark包,此包可以直接应用于对实验数据的推断,也可对观测数据进行匹配后再进行推断。
以下是不同包的功能对比:
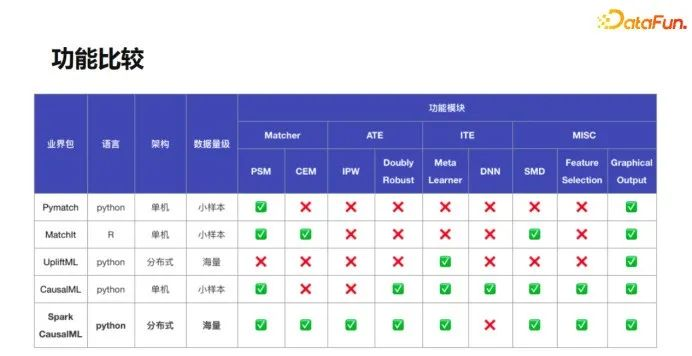
包的架构层面针对大样本数据进行了Spark脚本的重写,同时也包含了对于小样本数据推断操作的封装。Spark CausalML目前已在腾讯内部开源,增长侧的因果推断任务均使用此包例行调度,正积极推进外部开源中。
9 基于因果推断的商家经营智能诊断实践
https://mp.weixin.qq.com/s/3v5K_t0OfypaqJbmLO30Hg
9.1 混合因果网络发现新技术——HCM
因果网络发现,在具体的实践中主要面临两个挑战:
- 如何在混合数据类型上进行因果发现:现实数据场景中一般的数据变量都是混合型的变量,既有的方法一般假设数据类型单一,少数方法考虑混合变量上因果关系发现,但会假设关系线性或规模化受限;
- 大规模因果网络发现:样本规模大,变量维度高。
混合因果网络新模型

9.2 基于因果的深度归因技术
深度归因模型,其算法框架主要分为四部分:
- 第一,基于异常检测算法识别目标、因子显著波动;
- 第二,利用因果网络技术识别正确的因果Order;
- 第三,提出新的Multi-ATE估计技术,并基于因果Order估计干预变量的波动对目标的影响;
- 最后,基于各因子的Multi-ATE效果估计,计算其对目标波动的贡献度。

10 干货 | 贝叶斯结构模型在全量营销效果评估的应用
https://mp.weixin.qq.com/s/taCLo3jsfBEnOz30cT4PTw
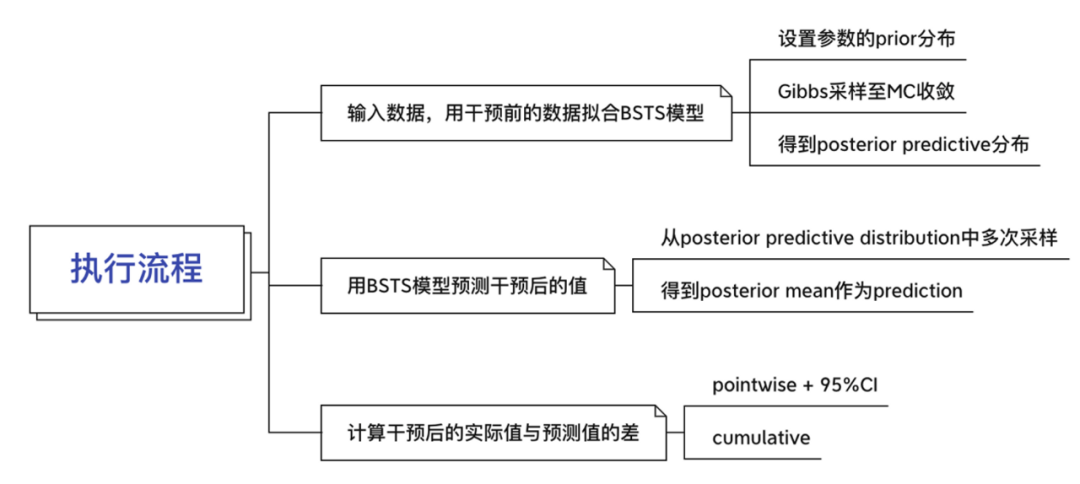
在对政策的效果评估上,我们核心想要的是观测对象“反事实值”,例如“如果没有这个广告投放,用户的浏览情况会怎样?”相较于传统的PSM或SCM方法,BSTS胜在其能够对于时间序列数据进行效果评估;
同时利用贝叶斯估计输出反事实值y的预测,并给出预测值的置信区间,能一定程度上降低反事实值预测的波动性,提升效应评估的准确性与稳定性。在实践应用上,可以通过谷歌开源的CausalImpact包来实现BSTS模型,在Python和R中均可调用,具体代码实现详见参考文献[7][8]。
11 因果推断在转转推荐场景下的实践
https://mp.weixin.qq.com/s/CJENHw6hn_Hy93aNe7uo-w
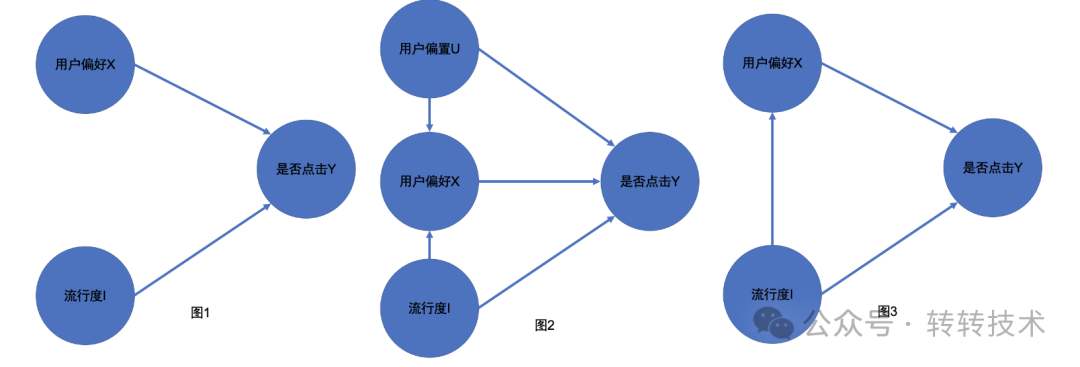
我们在首页默认tab进行了流行度偏差的debias实验,转转首页默认tab是一个多种物料共存的混合推荐场,其中商品维度上只有一个单独的点击率模型,便于我们观察实验效果。
一期方案我们的思路如因果图中的图一,商品的流行度不会对用户的偏好产生影响,这样流行度与用户的偏好对点击的影响就是线性的叠加。
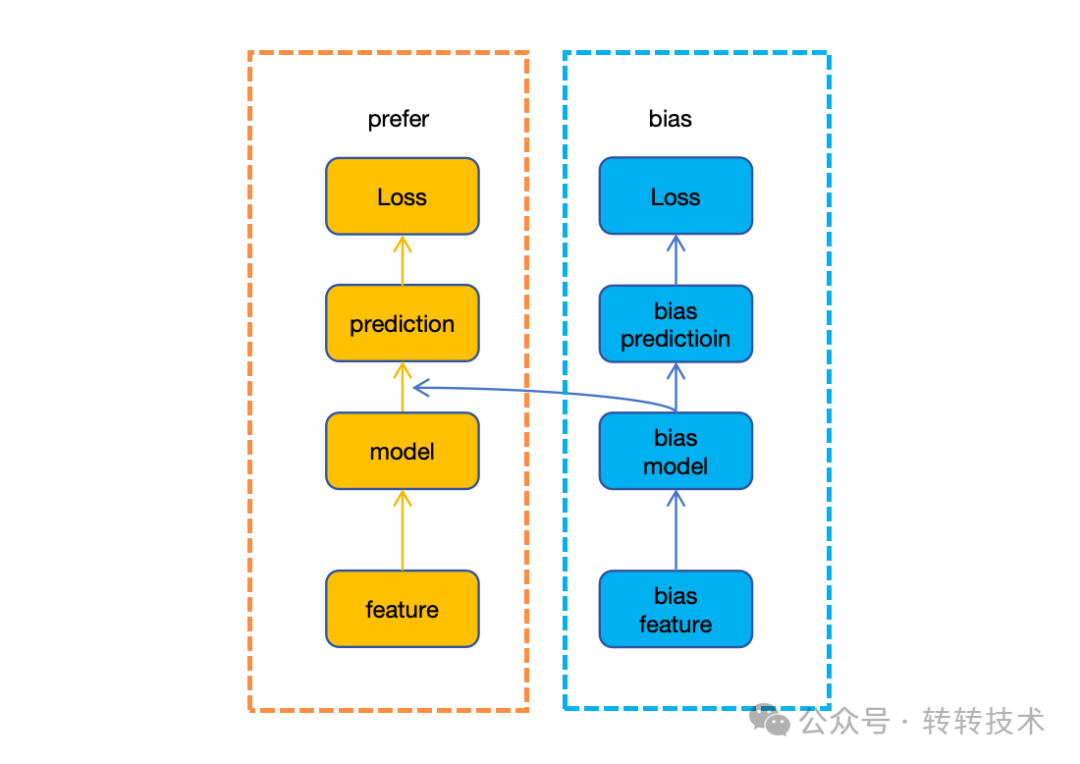
我们采用了两阶段的训练方法,从使用的特征中选取了部分商品的静态属性特征(商品的类目、质检项等)作为bias特征,全部特征作为prefer特征。可以看到特征和网络结构都是完全独立的。先训练bias部分,此时,收敛后再进行下一步,训练prefer部分时,两部分全联接层的输出相加再过sigmoid,即实验证明,该方案并无明显提升。