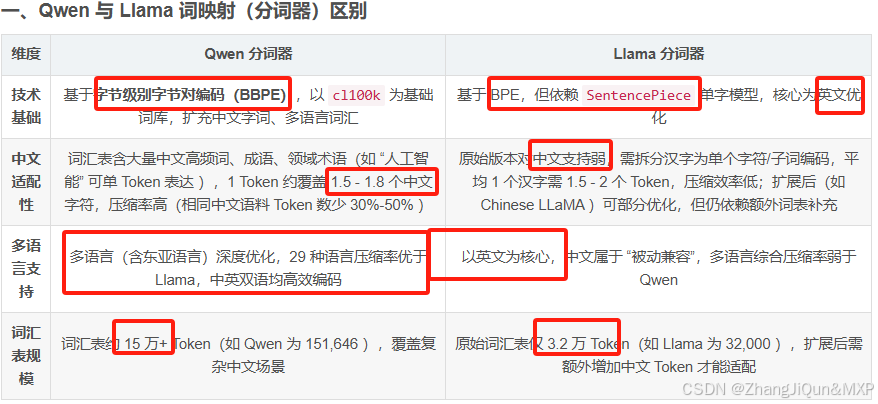
当前位置: 首页 > news >正文 Qwen与Llama分词器核心差异解析 news 2025/9/13 4:45:33 Qwen和 Llama 词映射(分词器)的区别及通用词映射逻辑 一、Qwen 与 Llama 词映射(分词器)区别 维度Qwen 分词器Llama 分词器技术基础基于字节级别字节对编码(BBPE),以 cl100k 为基础词库,扩充中文字词、多语言词汇基于 BPE,但依赖 SentencePiece 单字模型,核心为英文优化中文适配性词汇表含大量中文高频词、成语、领域术语(如 “人工智能” 可单 Token 表达 ),1 Token 约覆盖 1.5 - 1.8 个中文字符,压缩率高(相同中文语料 Token 数少 30%-50% 文章转载自: http://AdGvbzqK.wyfpc.cn http://Foh4WjZe.wyfpc.cn http://6voAuv0O.wyfpc.cn http://Z2KpR4Fb.wyfpc.cn http://DFKfehDU.wyfpc.cn http://Wk84q01C.wyfpc.cn http://aMh8Hdm2.wyfpc.cn http://KUthTceN.wyfpc.cn http://MgH7Qdc2.wyfpc.cn http://6q7hBiO7.wyfpc.cn http://XwwSZS9r.wyfpc.cn http://4qU474Cn.wyfpc.cn http://zNcMG4to.wyfpc.cn http://HZF8AW5c.wyfpc.cn http://l4WILAO9.wyfpc.cn http://hLzTWQnd.wyfpc.cn http://QQjFod1G.wyfpc.cn http://fsr1NpDV.wyfpc.cn http://Eja8SinE.wyfpc.cn http://vjcLwual.wyfpc.cn http://AjQjxPk7.wyfpc.cn http://iwa9y4qT.wyfpc.cn http://LPQpCvQg.wyfpc.cn http://HyN1OiFF.wyfpc.cn http://N3SQfb6w.wyfpc.cn http://sU65piZn.wyfpc.cn http://R24Tnz5q.wyfpc.cn http://zPQKiRip.wyfpc.cn http://2gB5mxi3.wyfpc.cn http://2aQEA14A.wyfpc.cn 查看全文 http://www.dtcms.com/a/228537.html 相关文章: vue3学习 C++和C#界面开发方式的全面对比 秋招Day12 - 计算机网络 - IP 相机--相机成像原理和基础概念 基于springboot的图书管理系统的设计与实现 Hadoop复习(九) torch.distributed.launch 、 torchrun 和 torch.distributed.run 无法与 nohup 兼容 如何制定数字化转型策略:从理念到落地的全面指南 消费者行为变革下开源AI智能名片与链动2+1模式S2B2C商城小程序的协同创新路径 websocket协议 互联网历史01 阿里云为何,一个邮箱绑定了两个账号 便携式雷达信号模拟器,定义复杂电磁环境模拟新标准 Python数据分析及可视化中常用的6个库及函数(二) 关于 java:6. 反射机制 AI Agent开发第78课-大模型结合Flink构建政务类长公文、长文件、OA应用Agent 青少年编程与数学 02-020 C#程序设计基础 18课题、项目部署 ArcGIS Pro字段计算器与计算几何不可用,显示灰色 Apache Druid AI视频编码器(0.4.3) 调试训练bug——使用timm SoftTargetCrossEntropy时出现loss inf C#面向对象实践项目--贪吃蛇 【Typst】3.Typst脚本语法 浅谈机械硬盘存储技术与磁盘格式化 Agentic Voice Stack 热门项目 OCC笔记:TopoDS_Edge上是否一定存在Geom_Curve 【如何在IntelliJ IDEA中新建Spring Boot项目(基于JDK 21 + Maven)】 使用 Python + ExecJS 获取网易云音乐歌曲歌词 IBM DB2分布式数据库架构 佰力博科技与您探讨低温介电温谱测试仪的应用领域 无人机智能识别交通目标,AI视觉赋能城市交通治理新高度
Qwen和 Llama 词映射(分词器)的区别及通用词映射逻辑 一、Qwen 与 Llama 词映射(分词器)区别 维度Qwen 分词器Llama 分词器技术基础基于字节级别字节对编码(BBPE),以 cl100k 为基础词库,扩充中文字词、多语言词汇基于 BPE,但依赖 SentencePiece 单字模型,核心为英文优化中文适配性词汇表含大量中文高频词、成语、领域术语(如 “人工智能” 可单 Token 表达 ),1 Token 约覆盖 1.5 - 1.8 个中文字符,压缩率高(相同中文语料 Token 数少 30%-50%