计算机视觉---深度学习框架(Backbone、Neck、Head)
一、主干(Backbone):视觉特征的“根基”
1. 核心定位与功能
- 定义:
作为网络的底层基础,主干负责从输入图像中提取多层次、多尺度的视觉特征,其输出的特征图(Feature Map)需兼顾空间细节(低层级)和语义信息(高层级),为后续任务提供丰富的表征。 - 关键设计目标:
- 特征表达能力:通过深层网络捕捉复杂语义(如“汽车”“行人”)。
- 计算效率:平衡参数量与精度,适配不同硬件(如GPU/CPU/边缘设备)。
- 多尺度感知:支持不同大小目标的特征提取(如检测中的小目标)。
- 迁移通用性:通过预训练(如ImageNet分类)学习通用视觉特征,便于迁移到下游任务。
2. 经典结构与技术演进
(1) CNN类主干
-
早期架构(2012-2015):
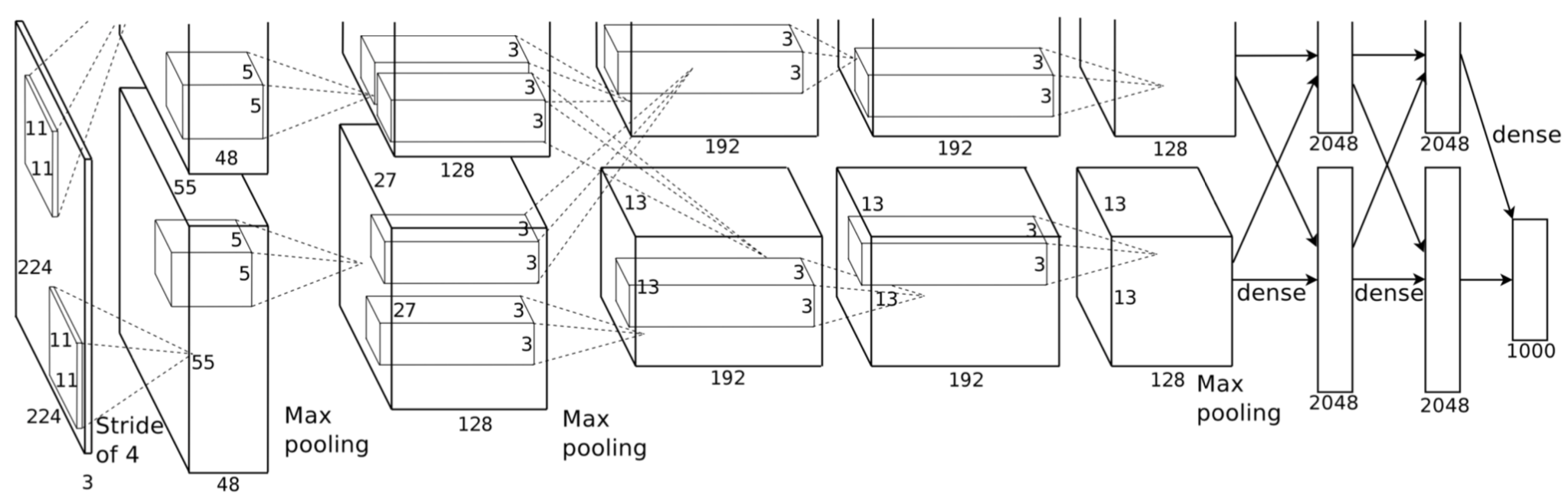
- AlexNet:首次使用深度卷积层(5层)+ReLU+Dropout,开启CNN时代。
- VGGNet:通过堆叠3×3小卷积核和池化层,验证“深度”对性能的提升(如VGG16/19)。
-
现代架构(2015年后):
-
ResNet(残差网络):引入残差连接(Residual Connection)解决深层网络梯度消失问题,衍生出ResNet-18/34/50/101/152等变体。
-
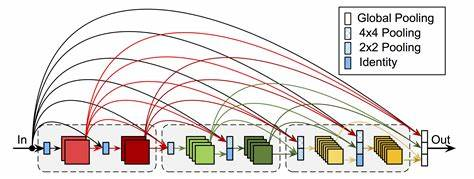
DenseNet:密集连接(Dense Connection)增强特征复用,减少参数量(如DenseNet121)。
-
轻量化架构:
- MobileNet系列:采用Depthwise Separable Convolution(深度可分离卷积),降低计算量(如MobileNetV1-V3)。
- ShuffleNet系列:通过通道混洗(Channel Shuffle)和分组卷积优化轻量化性能(如ShuffleNetV2)。
- EfficientNet:基于神经架构搜索(NAS)联合优化网络宽度、深度和分辨率,实现SOTA精度-效率平衡。
-
-
多尺度特征提取:
- 空洞卷积(Atrous Convolution):在ResNet基础上引入膨胀率,扩大感受野且不损失分辨率(如DeepLab系列用于分割)。
- 特征金字塔(Implicit Neck):部分主干(如ResNet)直接输出多阶段特征图(C2-C5),供颈部进一步处理。
(2) Transformer类主干
-
核心思想:用自注意力机制(Self-Attention)替代卷积,捕捉全局上下文依赖。
-
经典模型:
- ViT(Vision Transformer):将图像分块(Patch)后输入Transformer编码器,在大规模数据集(如JFT-300M)上预训练后性能超越CNN。
- Swin Transformer:引入分层窗口注意力(Hierarchical Window Attention),支持多尺度特征输出,适配检测、分割任务(如Swin-T/S/B/L)。
- DeiT(Data-Efficient Image Transformer):通过知识蒸馏优化Transformer训练,减少对超大规模数据的依赖。

-
混合架构:
- ConViT:在Transformer中融入卷积归纳偏置(如局部注意力),提升小数据下的泛化能力。
- LeViT:结合卷积和Transformer,通过渐进式Token减少降低计算量。
3. 关键技术细节
- 输入分辨率与步长:
- 主干通常以固定分辨率(如224×224)输入,通过stride=2的卷积/池化层逐步下采样(如ResNet下采样4次,输出1/32分辨率特征图)。
- 预训练策略:
- 监督预训练:在ImageNet等分类数据集上预训练,初始化主干权重。
- 自监督预训练:通过对比学习(如MoCo、SimCLR)或掩码建模(如BEiT)在无标签数据上学习通用特征。
- 特征图输出:
- 多阶段输出:如ResNet输出{C2, C3, C4, C5}(分辨率依次为1/4, 1/8, 1/16, 1/32),对应不同层级的语义强度。
二、颈部(Neck):特征融合的“枢纽”
1. 核心定位与功能
- 定义:
颈部位于主干和头部之间,负责对主干输出的多尺度特征进行融合、增强和重校准,解决不同层级特征的“语义鸿沟”(如深层强语义、浅层强细节),生成更适合头部任务的特征表示。 - 关键设计目标:
- 跨层特征交互:融合浅层细节(如边缘)和深层语义(如类别)。
- 多尺度表达:生成多分辨率特征图,适配不同大小的目标(如检测中的小目标需要高分辨率特征)。
- 轻量化与高效性:在有限计算成本内实现特征优化。
2. 经典结构与技术分类
(1) 特征金字塔网络(FPN-like)
- 自顶向下(Top-Down)融合:
- FPN(Feature Pyramid Network,2017):
- 结构:通过上采样(最近邻插值)将深层低分辨率、强语义特征图放大,与浅层高分辨率、弱语义特征图逐元素相加(横向连接),输出{P2-P5}(分辨率同主干的{C2-C5})。
- 应用:Faster R-CNN、YOLOv3等。
- Path Aggregation Network(PANet,2018):
- 在FPN基础上增加自底向上(Bottom-Up)路径,通过下采样传递浅层细节,增强特征传播(如YOLOv5的颈部)。
- FPN(Feature Pyramid Network,2017):
- 轻量化改进:
- BiFPN(Bidirectional Feature Pyramid Network,2020):
- 引入跨尺度连接(如同一层级特征图重复融合)和权重机制(Fast normalized fusion),动态调整不同路径的贡献(如EfficientDet)。
- NAS-FPN(2019):通过神经架构搜索自动设计最优特征融合路径。
- BiFPN(Bidirectional Feature Pyramid Network,2020):
(2) 注意力机制增强
- 通道注意力(Channel Attention):
- SE-Net(Squeeze-and-Excitation Network):通过全局平均池化和全连接层学习通道权重,增强关键语义通道(如ResNet+SE模块)。
- ECA-Net(Efficient Channel Attention):轻量化通道注意力,通过一维卷积捕获跨通道交互。
- 空间注意力(Spatial Attention):
- CBAM(Convolutional Block Attention Module):同时应用通道和空间注意力,在特征图空间维度上抑制无关区域。
- Non-local Network:通过自注意力机制捕获长距离空间依赖,适用于分割等需要全局信息的任务。
(3) 其他变体
- ASFF(Adaptive Spatial Feature Fusion,2019):
- 对不同尺度特征图进行动态加权融合,每个像素的融合权重由特征本身决定,提升小目标检测性能。
- SFAM(Spatial Feature Attention Module,2019):
- 在颈部中引入空间注意力,增强特征图中目标区域的响应。
- 无颈部设计:
- 部分轻量级模型(如YOLOv3-tiny、YOLOv7-E6E)省略颈部,直接使用主干的多阶段特征图输入头部,减少计算开销。
3. 关键技术细节
- 上采样方法:
- 插值法:最近邻插值、双线性插值(保留细节但无学习参数)。
- 转置卷积(Transposed Convolution):可学习的上采样,可能引入棋盘效应(Checkerboard Artifacts)。
- 下采样方法:
- 步长=2的卷积或池化(如3×3卷积+stride=2),减少分辨率并扩大感受野。
- 特征图对齐:
- 融合前需确保特征图尺寸一致,通常通过裁剪或插值调整(如FPN中浅层特征图裁剪至与深层上采样后的尺寸相同)。
三、头部(Head):任务导向的“决策层”
1. 核心定位与功能
- 定义:
头部是网络的末端,直接根据颈部输出的特征图完成具体任务的预测,如目标检测中的坐标回归和类别分类、语义分割中的像素级标签预测等。 - 关键设计目标:
- 任务特异性:针对不同任务设计定制化结构(如检测需要边界框回归,分割需要密集预测)。
- 正负样本分配:定义有效样本(如检测中Anchor与GT的匹配策略)。
- 损失函数设计:平衡不同任务分支的损失(如分类损失+回归损失)。
2. 按任务分类的头部结构
(1) 目标检测头部
- 双阶段检测头(Two-Stage):
- 代表模型:Faster R-CNN、Mask R-CNN。
- 结构:
- 区域建议网络(RPN):通过滑动窗口(Anchor)生成候选区域(Proposals),属于“粗筛”阶段。
- R-CNN头部:对ROI(Region of Interest)特征图进行池化(如RoIAlign),通过全连接层完成分类和回归(“精调”阶段)。
- 单阶段检测头(One-Stage):
- Anchor-based:
- YOLO系列:将图像划分为网格(Grid),每个网格预测多个Anchor的类别和坐标(如YOLOv3的3个尺度头部)。
- RetinaNet:通过Focal Loss解决正负样本失衡问题,头部包含独立的分类分支和回归分支。
- Anchor-free:
- CenterNet:直接预测目标中心点坐标、尺寸和类别,无需Anchor(如Heatmap+Offset+Size)。
- FCOS(Fully Convolutional One-Stage):将每个像素视为潜在中心点,根据位置到目标边界的距离进行回归(如L2-L5层级对应不同大小目标)。
- Anchor-based:
- 关键技术:
- 正负样本匹配:
- Anchor-based:基于IoU阈值(如IoU>0.7为正,<0.3为负)。
- Anchor-free:基于中心点范围或特征层级分配(如FCOS的中心采样策略)。
- 损失函数:
- 分类:CrossEntropy Loss、Focal Loss。
- 回归:Smooth L1 Loss、CIoU Loss、DIoU Loss(考虑预测框与真实框的重叠和位置关系)。
- 正负样本匹配:
(2) 语义分割头部
- 编码器-解码器(Encoder-Decoder):
- U-Net:解码器通过上采样和跳跃连接(Skip Connection)恢复分辨率,结合浅层细节和深层语义(如医学图像分割)。
- DeepLab系列:
- ASPP(Atrous Spatial Pyramid Pooling):通过不同膨胀率的空洞卷积并行提取多尺度上下文,增强语义一致性。
- PSPNet:
- PPM(Pyramid Pooling Module):通过不同尺度的池化核捕获全局上下文(如1×1、3×3、6×6、全局池化)。
- 轻量级分割头:
- ENet:采用非对称卷积和下采样策略,解码器简化为少数几层,适配实时分割。
- Fast-SCNN:引入全局特征提取模块(GPM)和局部特征 refinement 模块(LRM),平衡速度与精度。
(3) 实例分割头部
- Mask R-CNN:
- 在Faster R-CNN基础上增加掩码分支,对每个ROI预测二进制掩码(通过全卷积网络,如FCN),实现实例级分割。
- YOLACT:
- 单阶段实例分割,头部生成原型掩码(Prototype Masks)和掩码系数(Mask Coefficients),通过线性组合得到每个实例的掩码。
(4) 其他任务头部
- 姿态估计:
- Top-Down:如Hourglass Network,头部通过热图(Heatmap)预测关键点位置。
- Bottom-Up:如OpenPose,头部检测关节点并关联成人体骨架。
- 图像生成:
- GAN的生成器:可视为特殊头部,将潜在向量(Latent Vector)映射为图像像素(如StyleGAN的渐进式上采样结构)。
3. 关键技术细节
- 多任务头部:
- 共享主干和颈部,不同任务分支独立(如检测+分割,或检测+属性分类)。
- 输出维度设计:
- 检测头:每个Anchor/网格输出维度为
[类别数+坐标参数数+置信度](如YOLOv3的每个Anchor输出85维)。 - 分割头:输出维度为
[类别数, H, W],通过Softmax生成像素级类别概率。
- 检测头:每个Anchor/网格输出维度为
- 后处理算法:
- 检测:非极大值抑制(NMS)、Soft-NMS、DIoU-NMS,用于过滤冗余框。
- 分割:CRF(条件随机场)后处理,优化掩码边缘细节。
四、跨模块交互与系统优化
1. 主干-颈部接口设计
- 特征图选择:
- 颈部通常选取主干的中间层(如ResNet的C2-C5)作为输入,C2(1/4分辨率)保留更多细节,C5(1/32分辨率)语义最强。
- 通道数匹配:
- 主干输出的通道数(如ResNet的256/512/1024/2048)可能通过1×1卷积压缩(如FPN中压缩至256通道),减少颈部计算量。
2. 颈部-头部适配
- 特征图分辨率:
- 检测头通常需要多尺度特征图(如P3-P5,分辨率1/8-1/32),小目标对应高分辨率特征图(P3),大目标对应低分辨率(P5)。
- 感受野匹配:
- 头部的预测范围需与颈部特征图的感受野对齐(如大目标对应深层高感受野特征)。
3. 硬件与部署优化
- 主干轻量化:
- 边缘设备采用MobileNet、ShuffleNet等轻量主干,或通过模型剪枝、量化压缩大型主干(如ResNet)。
- 颈部计算优化:
- 减少颈部层级(如YOLOv3无颈部)或使用深度可分离卷积(如BiFPN中的轻量化操作)。
- 头部合并策略:
- 多任务头部共享部分层(如检测和分类共享前几个卷积层),减少参数冗余。
五、最新进展与未来趋势
1. 主干:Transformer的统治与混合架构
- 纯Transformer主干:如MAE(Masked Autoencoders)通过掩码重建预训练,在分割、检测中超越CNN主干。
- 卷积-Transformer混合:如Swin Transformer结合局部窗口注意力和层级特征,成为主流检测/分割主干。
2. 颈部:动态化与自适应
- 动态特征融合:如Conditional BiFPN,根据输入图像内容动态生成融合权重(EfficientDet-D7x)。
- 无颈部设计:如YOLOv7-E6E直接使用主干多阶段特征,通过重参数化(Reparametrization)提升效率。
3. 头部:Anchor-free与统一化
- 全卷积检测头:如YOLOv5/YOLOv8的Headless设计,直接通过卷积层输出预测,摒弃全连接层。
- 多任务统一头部:如YOLOX-Nano通过单一头部同时支持检测和姿态估计,通过注意力机制动态切换任务分支。
4. 跨模块联合优化
- 端到端可微分架构:如DETR(Detection Transformer)通过Transformer编码器-解码器直接预测目标,消除颈部和NMS后处理,实现“全网络可微分”。
- 神经架构搜索(NAS):自动化设计主干-颈部-头部的组合(如AutoFPN、DetNAS)。
六、经典模型结构拆解表
| 模型 | 主干 | 颈部 | 头部 | 任务 |
|---|---|---|---|---|
| Faster R-CNN | ResNet50/101 | FPN | RPN+R-CNN(双阶段检测) | 目标检测 |
| YOLOv5 | CSPDarknet | FPN+PAN | 三尺度Anchor-based检测头 | 目标检测 |
| Mask R-CNN | ResNet-FPN | (同主干颈部) | R-CNN+掩码分支 | 实例分割 |
| EfficientDet | EfficientNet-B0-B7 | BiFPN | 单阶段Anchor-free检测头 | 目标检测 |
| U-Net | 卷积层(编码器) | 跳跃连接 | 转置卷积解码器 | 语义分割 |
| Swin Transformer | Swin Transformer | (直接输出多阶段特征) | 分割头/检测头(如Faster R-CNN) | 检测/分割 |
七、总结:模块化设计的本质与价值
主干、颈部、头部的划分本质是功能解耦与抽象分层,其核心价值在于:
- 复用性:主干(如ResNet)、颈部(如FPN)、头部(如YOLO检测头)可独立替换,加速模型迭代。
- 可解释性:清晰的模块边界便于分析性能瓶颈(如检测精度低可能源于颈部特征融合不足)。
- 技术分工:研究者可专注单一模块优化(如主干的Transformer化、颈部的注意力机制、头部的Anchor-free设计),推动领域整体进步。
随着深度学习向通用视觉模型(如Segment Anything Model, SAM)发展,模块边界可能逐渐模糊(如主干与颈部集成、头部支持动态任务),但功能解耦的思想仍将是模型设计的基石。