AIGC工具平台-GPT-SoVITS-v4-TTS音频推理克隆
声音克隆与语音合成的结合,是近年来生成式AI在多模态方向上的重要落地场景之一。随着预训练模型能力的增强,结合语音识别、音素映射与TTS合成的端到端系统成为初学者可以上手实践的全流程方案。
围绕 GPT-SoVITS-v4-TTS 模块,介绍了其在整合包中的操作方式和各阶段工具使用流程。从前置数据处理、模型训练到最终的音频生成,逐步拆解系统内部逻辑与交互方式,为理解该类系统架构提供直观路径。
文章目录
- 操作使用
- 应用示例
- 前置数据集获取工具
- GPT-SoVITS-TTS
- TTS-for-GPT-soVITS
- 开发与应用
操作使用
进入软件后在 整合包 里可以直接搜索 GPT-SoVITS-v4-TTS 进入该模块。
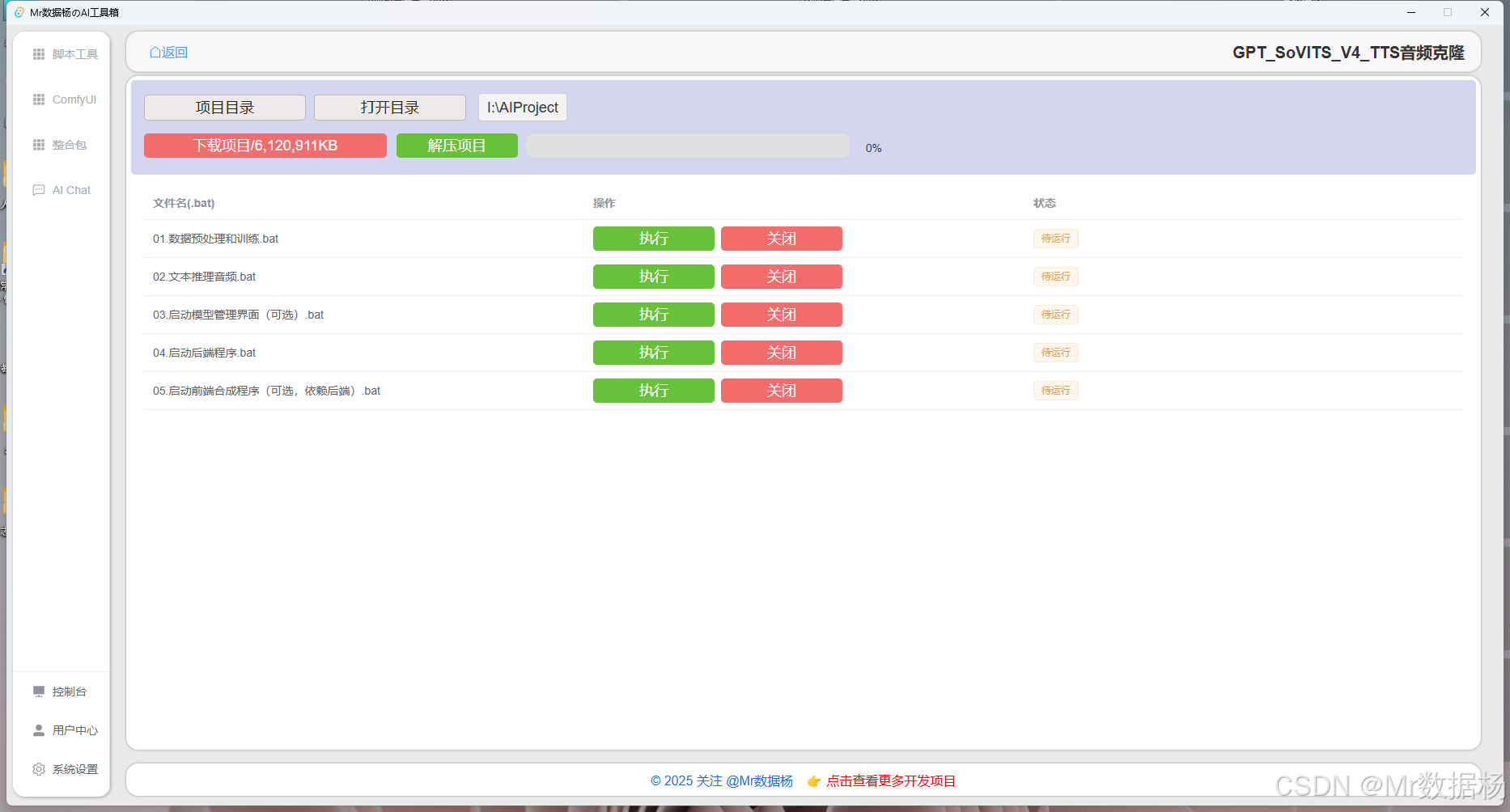
点击【下载选项卡】可获取完整项目整合包的下载地址,或直接使用下方链接下载。将文件保存至项目目录下后,点击解压按钮,等待解压完成即可开始使用。
| - | 说明 |
|---|---|
| 源码使用教程 | 基于GPT-SoVITS-v4-TTS的音频文本推理,流式生成 |
| 整合包下载地址 | 基于GPT-SoVITS-v4-TTS的声音克隆项目整合包 |
项目脚本配置
这些脚本通过 Gradio 提供可视化界面,分别对应 GPT-SoVITS 项目从数据准备、预处理、训练到推理的各个阶段。使用者只需按需点击对应的 .bat 文件,即可启动相关功能模块,无需手动输入复杂命令,适合初学者快速上手和部署测试。
| 脚本名称 | 功能说明 |
|---|---|
| 01.获取和处理训练数据.bat | 启动数据预处理模块,包括语音采样整理、标注转换等 |
| 02.文字转音素预处理.bat | 启动文本转音素工具,用于生成训练所需的音素数据 |
| 03.启动预训练管理器(可选).bat | 启动预训练参数管理界面,可查看或加载预训练模型(非必选) |
| 04.启动训练任务.bat | 启动训练控制台,执行模型训练流程 |
| 05.启动推理功能模块(TTS、克隆音频).bat | 启动推理服务,提供基于 Gradio 的 TTS 与音频克隆在线体验界面 |
应用示例
前置数据集获取工具
在正式开始音频克隆前,需要先准备一系列工具来获取和处理数据。
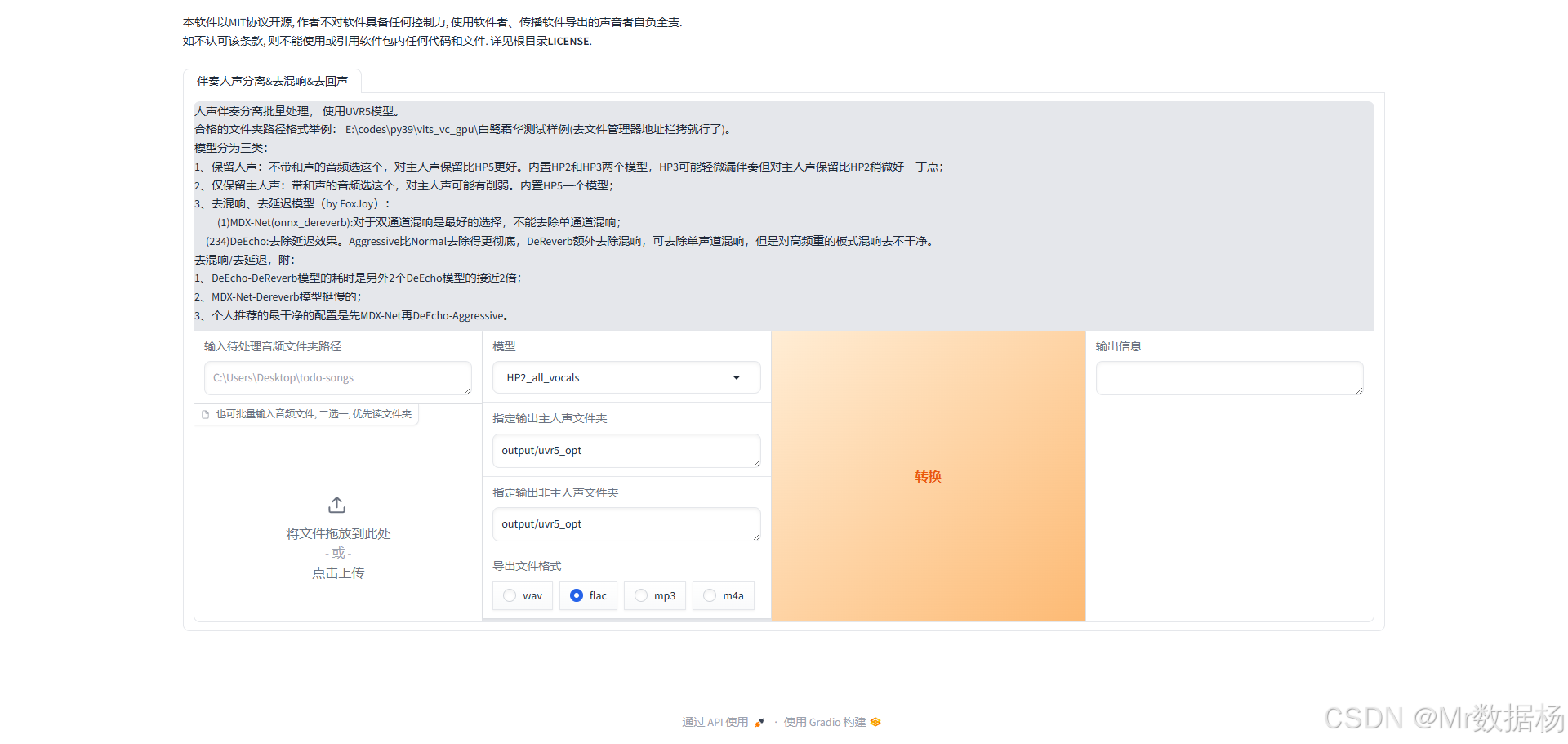
原生和背景分离 UVR5
使用UVR5工具对音频进行人声和背景音乐分离,确保后续处理的音频质量。操作界面非常直观,初学者只需导入原始音频文件,选择对应模型,点击开始即可分离出干净的人声文件。
语音切分工具
将分离后的人声音频进一步切分为适合处理的小段。
将分离后的人声音频进一步切分为适合处理的小段。输入路径选择UVR5处理后的音频文件夹,输出路径按照角色建立子文件夹,例如:output/角色名/slicer_opt。
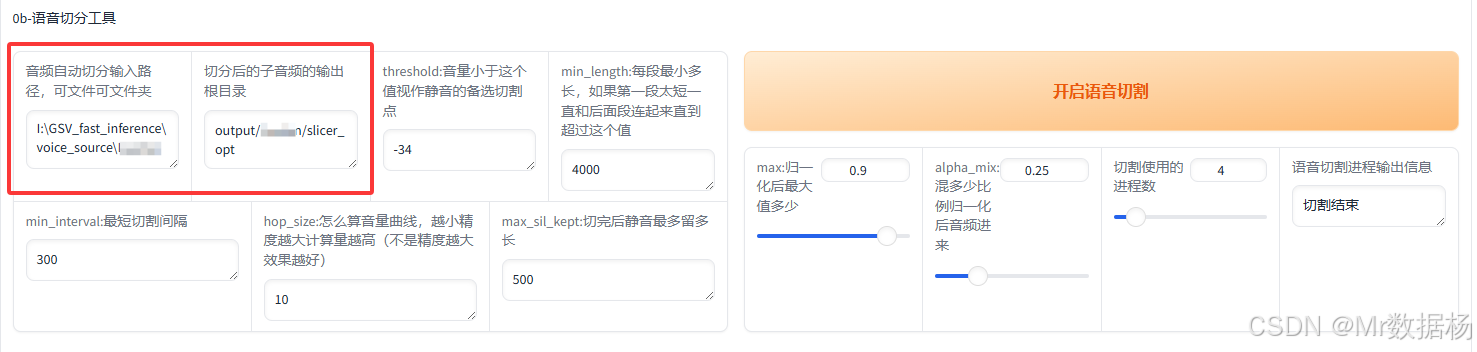
切分工具会自动按语音停顿和静默间隔切分,降低后续处理难度。
语音降噪工具
切分后的语音片段可能存在背景噪声,降噪工具可有效提升音质。输入路径为切分后的文件夹路径(如output/角色名/slicer_opt),输出路径建议新建子文件夹(如output/角色名/denoise_opt)。

降噪完成后,语音文件清晰度和质量显著提高,便于后续ASR语音识别。
中文批量离线ASR工具
通过中文批量ASR工具自动识别音频对应的文本内容。输入路径选择降噪后的音频文件夹(如output/角色名/denoise_opt),输出路径指定为新子文件夹(如output/角色名/asr_opt)。
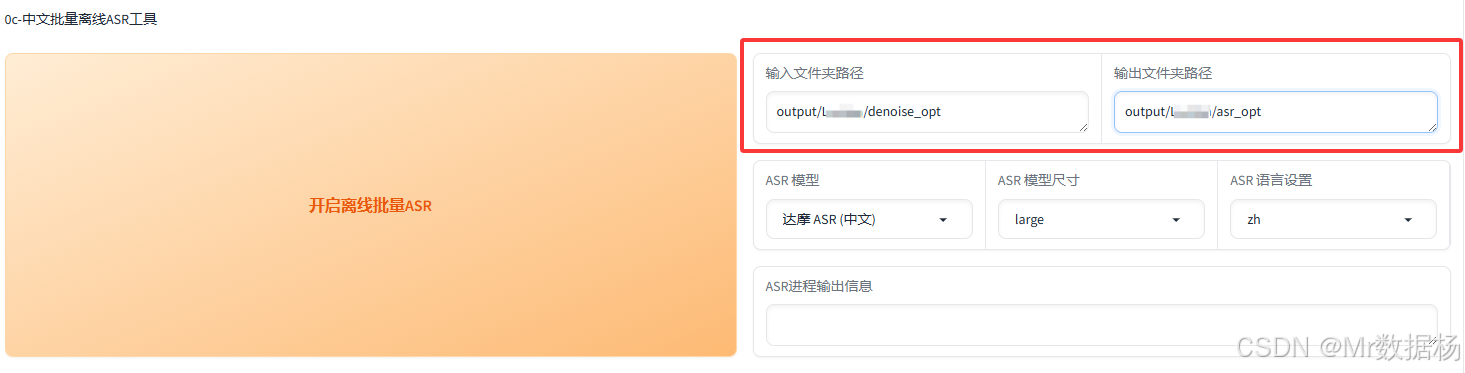
工具会自动生成音频片段对应的文本识别结果,并生成一个slicer_opt.list文件,便于后续文本校对。
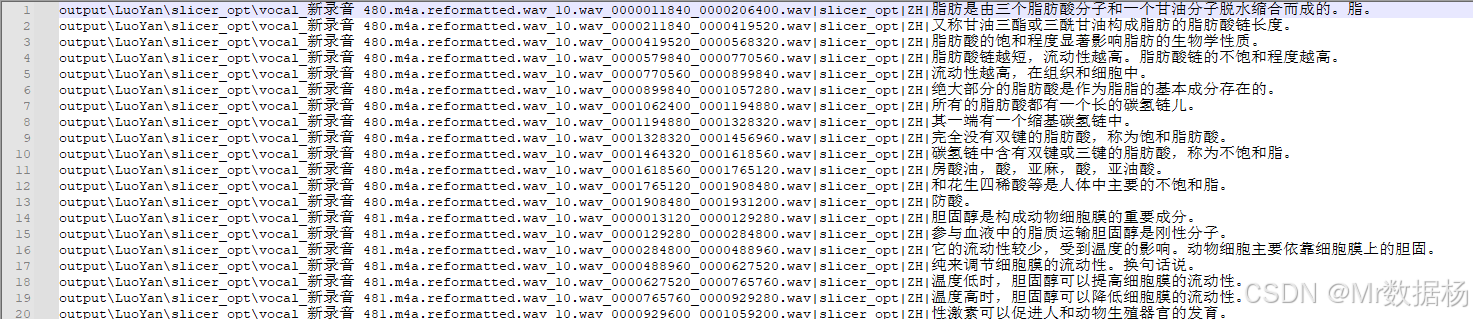
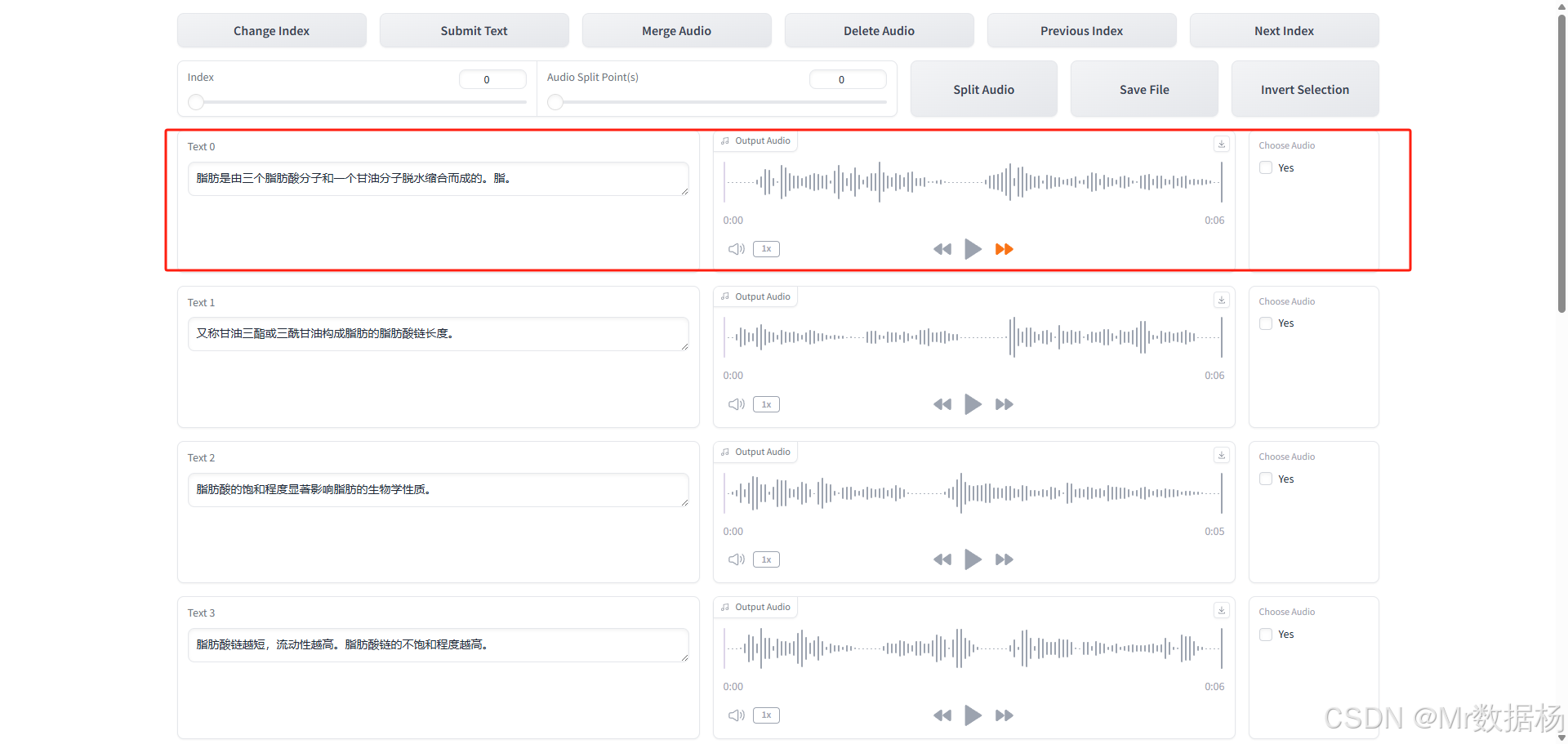
语音文本校对标注工具
ASR识别结果可能存在错误,若对精度要求较高,则可手动使用该工具进行逐条文本校对和修正,提升克隆语音的准确性。
GPT-SoVITS-TTS
完成数据准备后,进入模型训练和语音合成阶段。
项目设置
在GPT-SoVITS工具界面设置模型训练项目的名称,便于后续区分和管理。

选择前面已经ASR识别并校对好的文本标记文件,作为训练数据的基础。

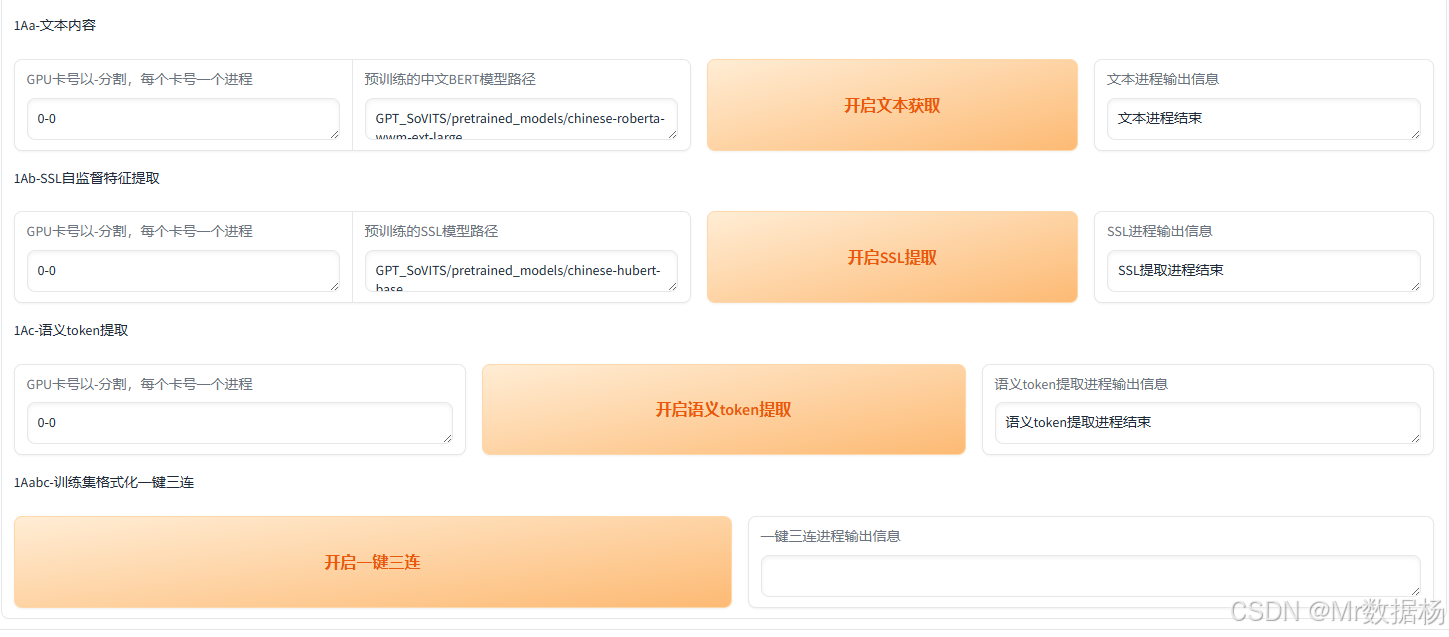
数据格式化
在项目设置完成后,依次执行数据格式化操作,可以直接使用工具中的“一键三连”功能快速完成,包括数据的预处理、格式检查和必要的文件生成。该过程通常比较稳定,不易出现问题。
微调训练
启动SoVITS模型训练,过程中实时观察训练日志。训练完成后,模型文件会自动存放在GPT_weights目录下,后续用于生成音频。
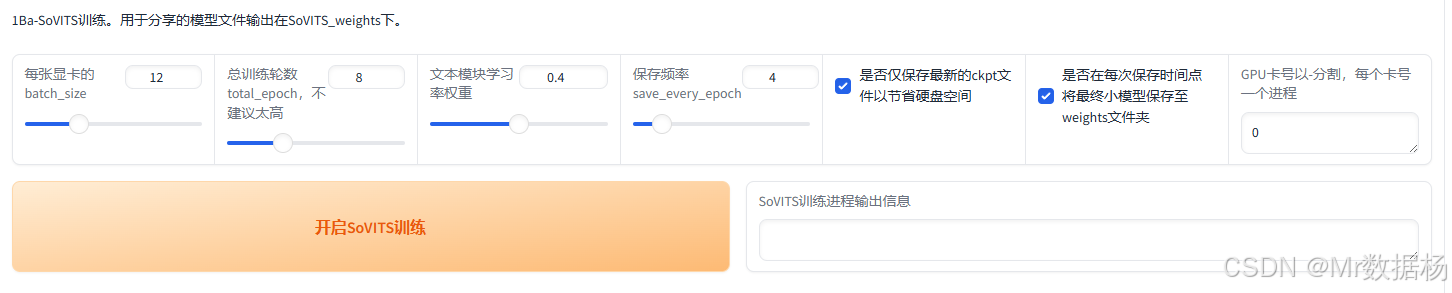
启动GPT模型训练,同样实时观察训练进度。训练成功后,生成的GPT模型文件也会位于GPT_weights目录。

这两个步骤的完成对最终克隆效果非常关键,确保两者训练充分后再进行推理测试。
TTS-for-GPT-soVITS
模型管理
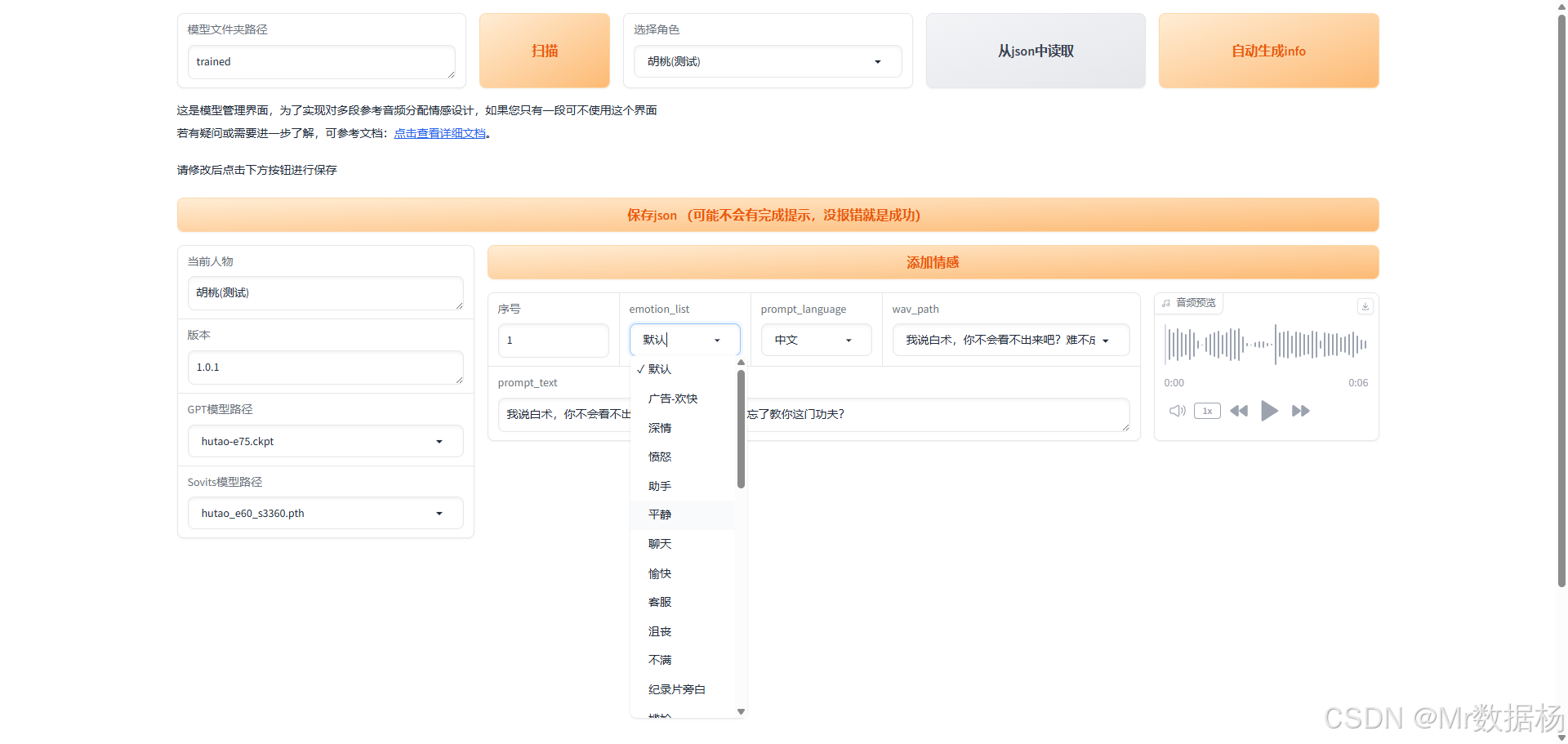
在TTS-for-GPT-soVITS目录中运行启动模型管理界面.bat文件,进入界面后点击"扫描"按钮,系统将显示当前用于生成音频的模型及其相关配置信息。
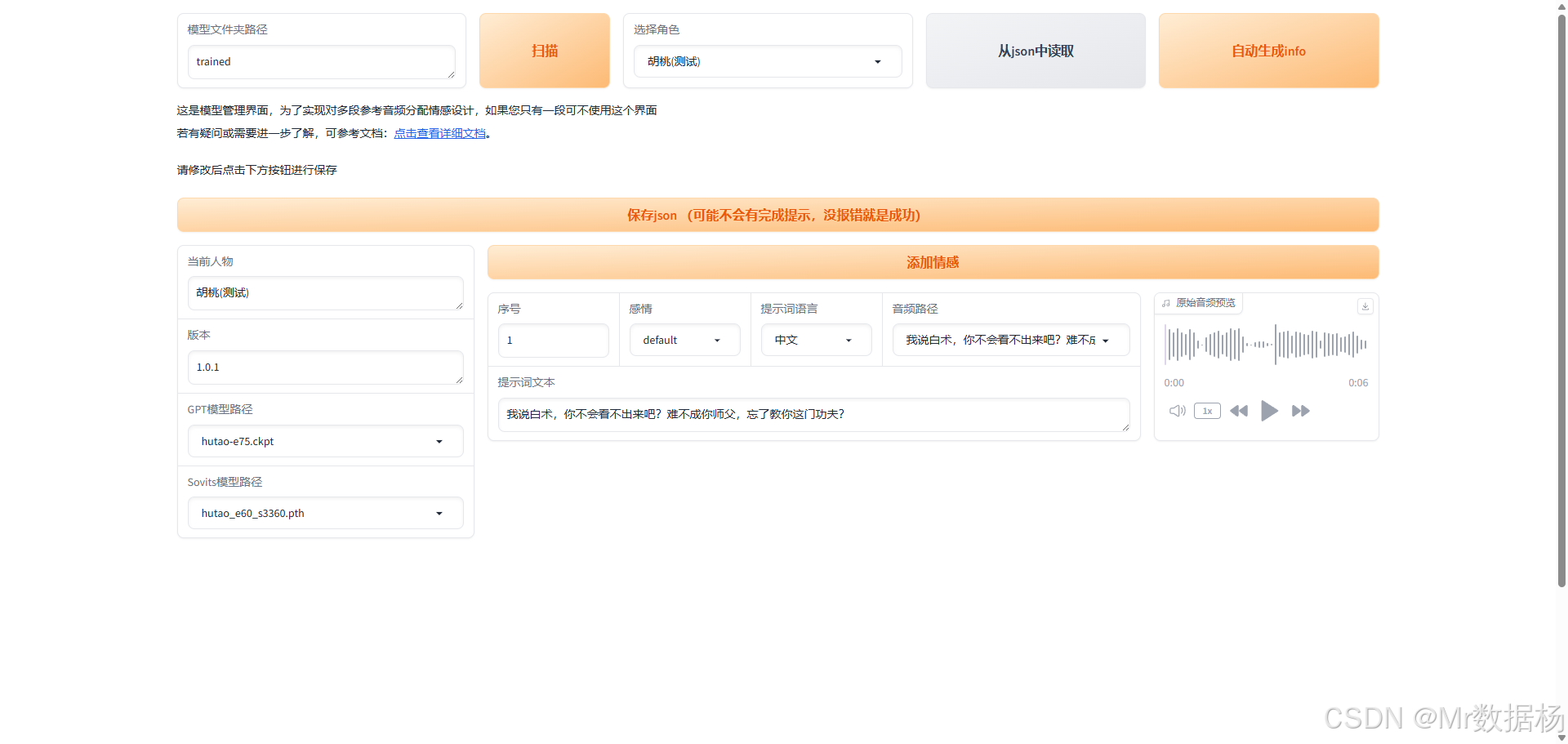
项目的角色配置文件位于根目录下的 trained/character_info.json,您可以在其中添加下拉菜单的角色名称选项,其中 default 字段用于指定默认选中的模型。
{"deflaut_character": "胡桃(测试)","characters_and_emotions": {"胡桃(测试)": ["default"],"xxxxx": ["default"],}
}
需要确保 key 值与当前目录下的文件夹名称完全匹配。
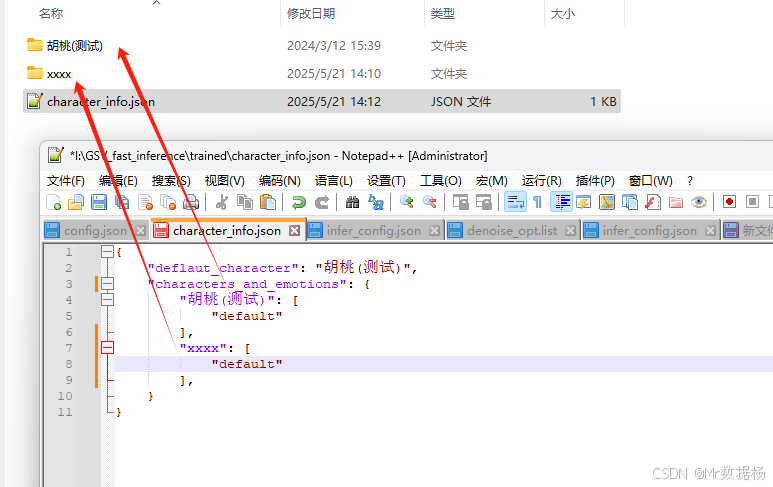
请将 GPT_weights 和 SoVITS_weights 的模型文件加载至此处。
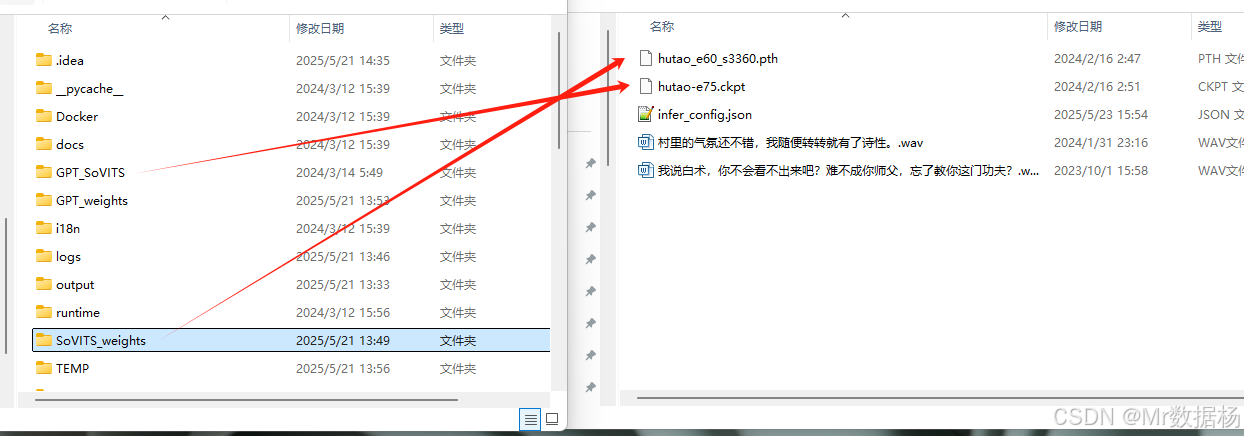
复制两份切片样本音频文件至当前目录,以音频文字内容作为文件名。随后打开 infer_config.json 文件,参照示例配置模型参数及样本文件路径。
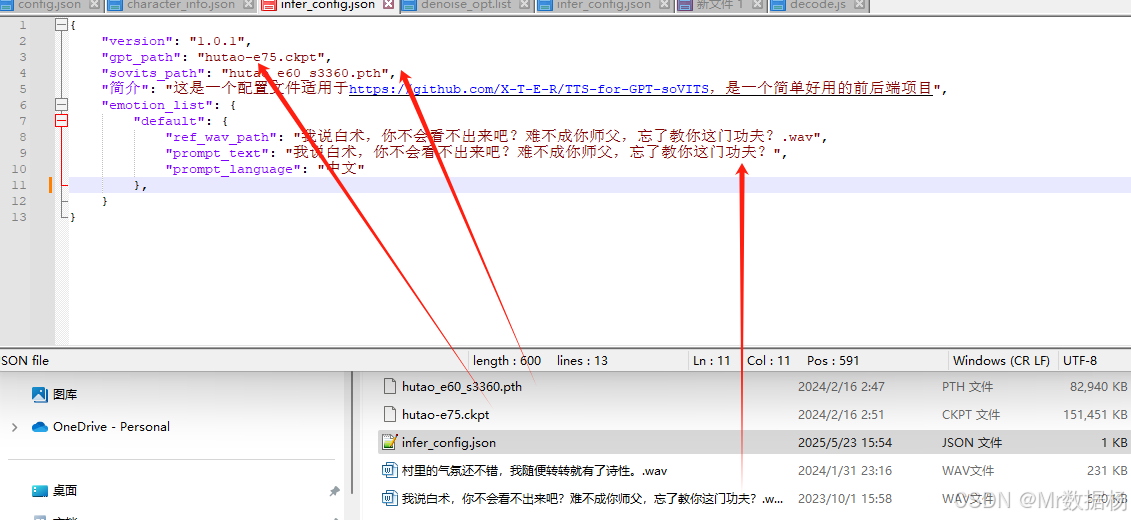
您还可以通过WebUI界面进行操作,只需确保模型和信息保持一致即可。
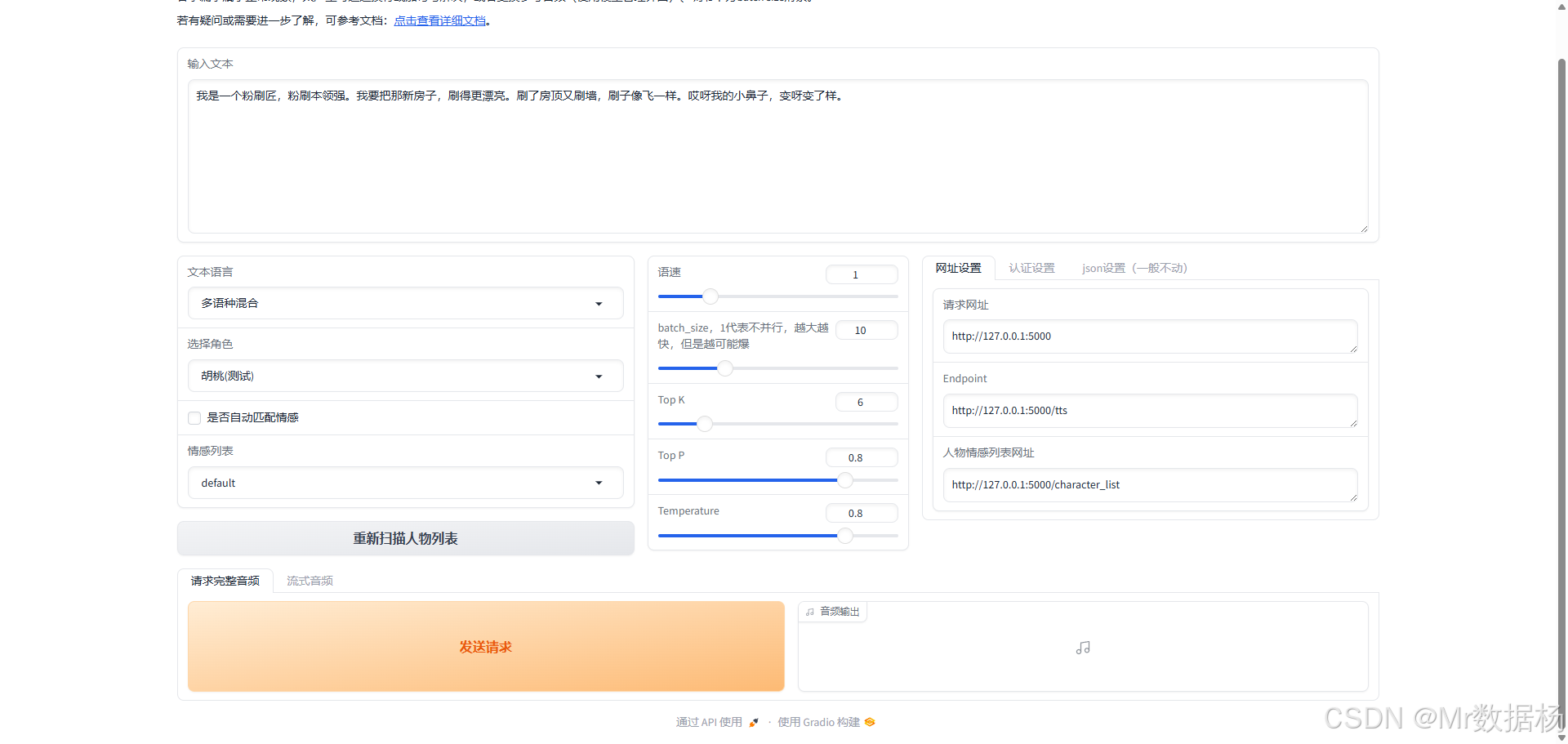
启动后端服务
成功启动后,系统将显示接口地址提示信息。请保持当前启动窗口处于开启状态。
ver instead.* Running on all addresses (0.0.0.0)* Running on http://127.0.0.1:5000* Running on http://172.19.0.1:5000
INFO:werkzeug:Press CTRL+C to quit
启动前端合成程序
系统启动后,用户可立即进行音频合成操作,该功能同时支持流式处理和文件合成两种模式。
开发与应用
软件使用以及综合参考资料内容可以查阅
| 文章链接 | 内容描述 |
|---|---|
| AIGC工具平台Tauri+Django环境开发,支持局域网使用 | 图形桌面工具使用教程,详细介绍 Tauri+Django 环境的开发方法,支持局域网部署与使用。 |
| AIGC工具平台Tauri+Django常见错误与解决办法 | 常见错误与解决办法,针对 Tauri+Django 环境下可能遇到的问题提供实用的解决方案。 |
| AIGC工具平台Tauri+Django内容生产介绍和使用 | 包含当前主流新媒体领域常用的音频、视频剪辑,以及内容一键生产功能。 |
| AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用 | 工作流相关内容讲解,涵盖文件管理、文件汇总、软件使用教程及开发指导,附带模型下载资源。 |
| AIGC工具平台Tauri+Django开源git项目介绍和使用 | 开源git项目内容讲解,涵盖项目整合包、算法模型、测试指导、项目应用,附带项目整合包下载。 |