AI炼丹日志-26 - crawl4ai 专为 AI 打造的爬虫爬取库 上手指南
点一下关注吧!!!非常感谢!!持续更新!!!
Java篇:
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
大数据篇 300+:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)

官方地址
https://docs.crawl4ai.com/
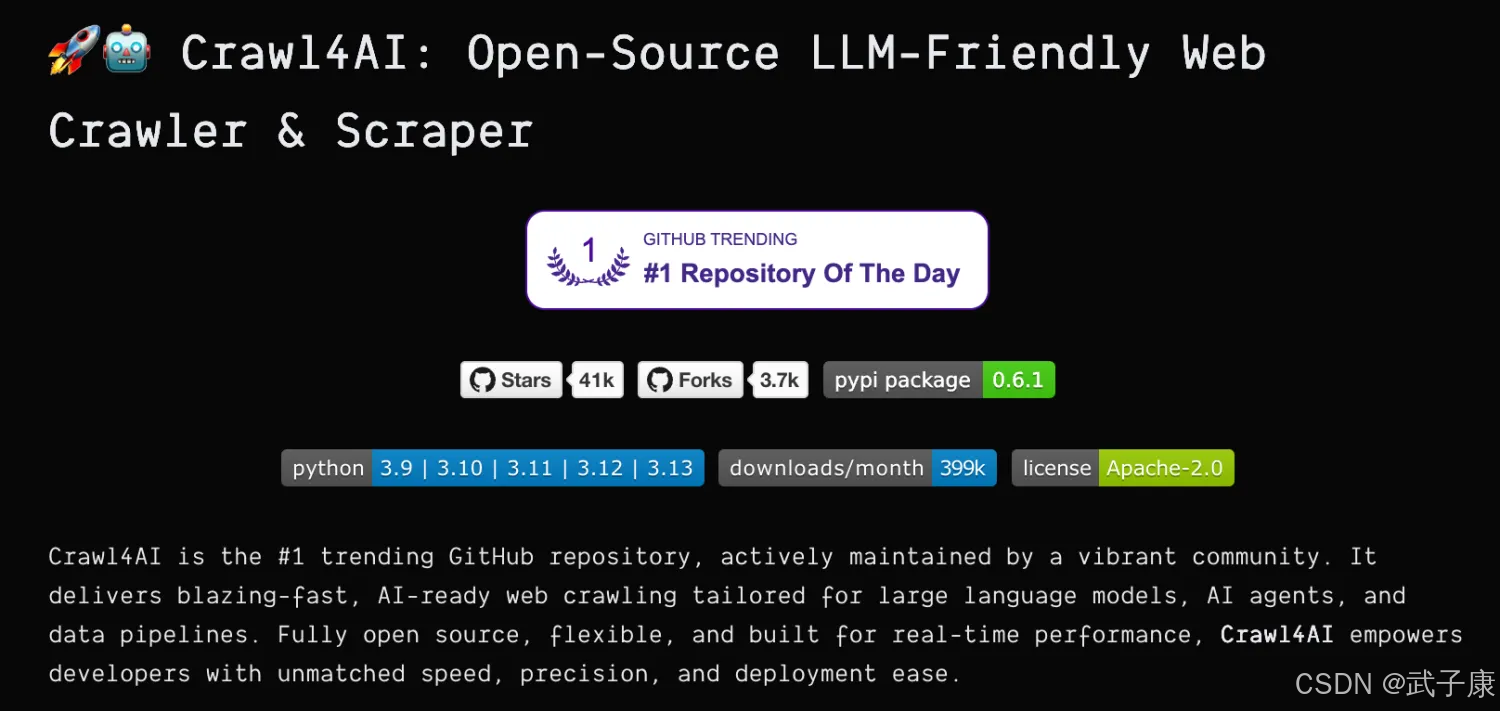
Crawl4ai是第一个趋势GitHub存储库,由充满活力的社区积极维护。它提供了针对大型语言模型,AI代理和数据管道量身定制的燃烧,AI-Ready Web爬行。完全开源,灵活并为实时性能而构建,crawl4ai以无与伦比的速度,精度和部署易于使用。
作者故事
我的计算机之旅始于童年,当时我父亲是一名计算机科学家,他向我介绍了 Amstrad 计算机。那些早期的经历激发了我对技术的浓厚兴趣,促使我后来攻读了计算机科学专业,并在研究生阶段专注于自然语言处理(NLP)。也是在那段时间,我第一次接触到网页爬取,开发了帮助研究人员整理论文和从出版物中提取信息的工具。这是一段既充满挑战又极具收获的经历,极大地锤炼了我在数据提取方面的技能。
时间快进到2023年,当时我正在为一个项目开发工具,需要一个爬虫将网页内容转成 Markdown 格式。在寻找解决方案的过程中,我发现了一个自称开源的项目,但它要求创建账户并生成 API Token。更糟糕的是,它实际上是一个 SaaS 模型,需要支付 16 美元,而且质量还达不到我的预期。感到非常沮丧之余,我意识到这背后存在着更深层次的问题。这种沮丧很快变成了爆发式的愤怒,我决定自己动手解决。在短短几天内,我开发出了 Crawl4AI。出乎意料的是,它迅速走红,在 GitHub 上收获了数千颗星星,并受到了全球社区的热烈响应。
我之所以将 Crawl4AI 开源,主要有两个原因。首先,这是我回馈开源社区的一种方式,多年来,正是开源精神一直在支持着我的成长。其次,我坚信数据应该对所有人开放,而不是被高墙锁住或被少数人垄断。数据的自由访问是实现 AI 民主化的基础——一个人人都能训练自己的模型、掌握自己数据的未来愿景。而这个库,就是迈向打造全球最佳开源数据提取与生成工具之路的第一步,这一切将由一个充满激情的社区共同完成。
为什么选择
● 为大语言模型(LLMs)而生:生成智能、简洁的 Markdown 格式内容,专为 RAG(检索增强生成)和微调应用优化。
● 极速性能:以实时、低成本的方式交付结果,速度提升至 6 倍。
● 灵活的浏览器控制:支持会话管理、代理设置和自定义钩子,助力无缝访问数据。
● 启发式智能:采用先进算法进行高效提取,减少对高成本模型的依赖。
● 开源可部署:完全开源,无需 API Key,可直接使用 Docker 部署,支持云端集成。
● 蓬勃发展的社区:由充满活力的社区积极维护,且成为 GitHub 上趋势榜第一的热门项目。
配置环境
python -m venv env
source env/bin/activate
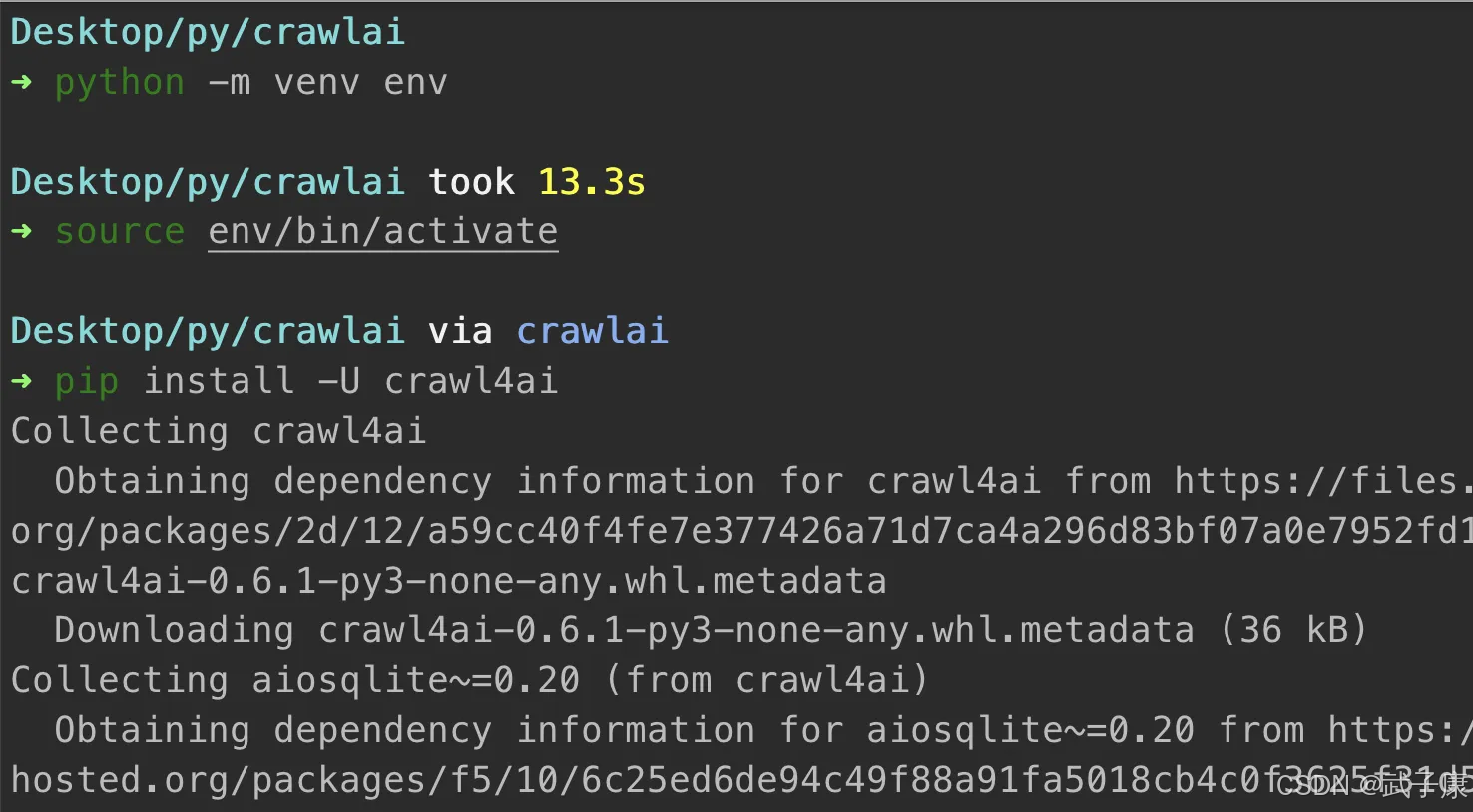
安装项目
pip install -U crawl4ai
执行结果如下所示:
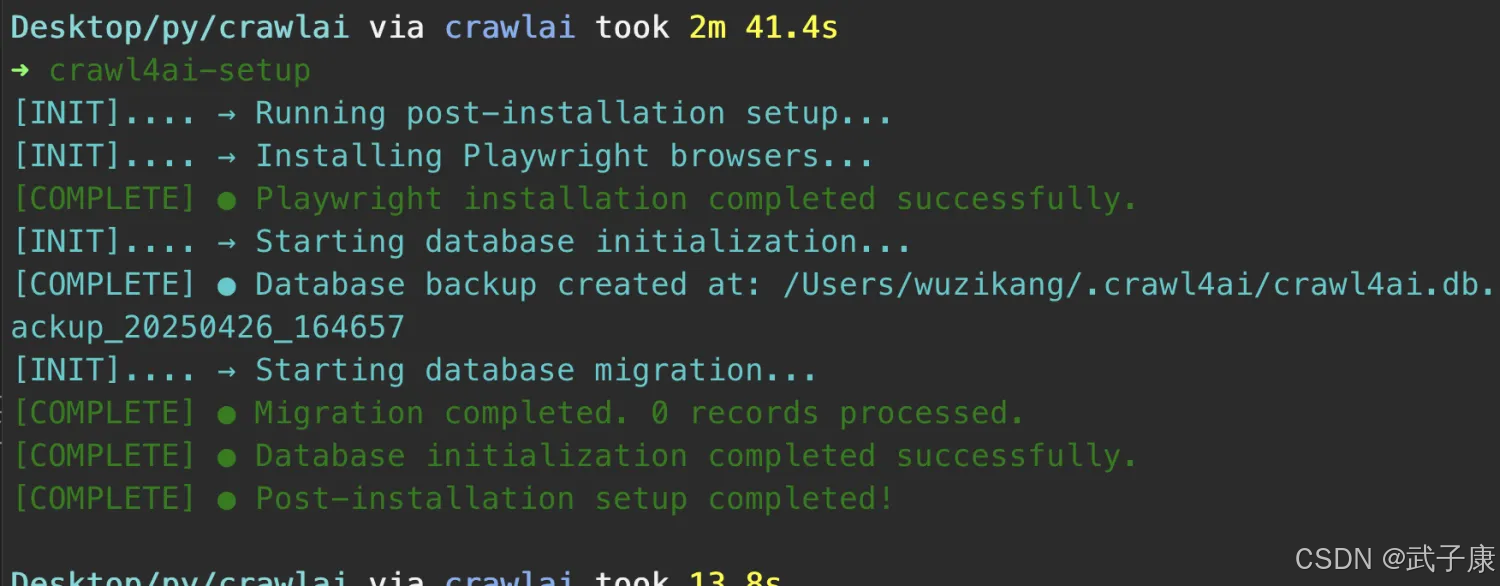
配置环境
crawl4ai-setup
执行结果如下
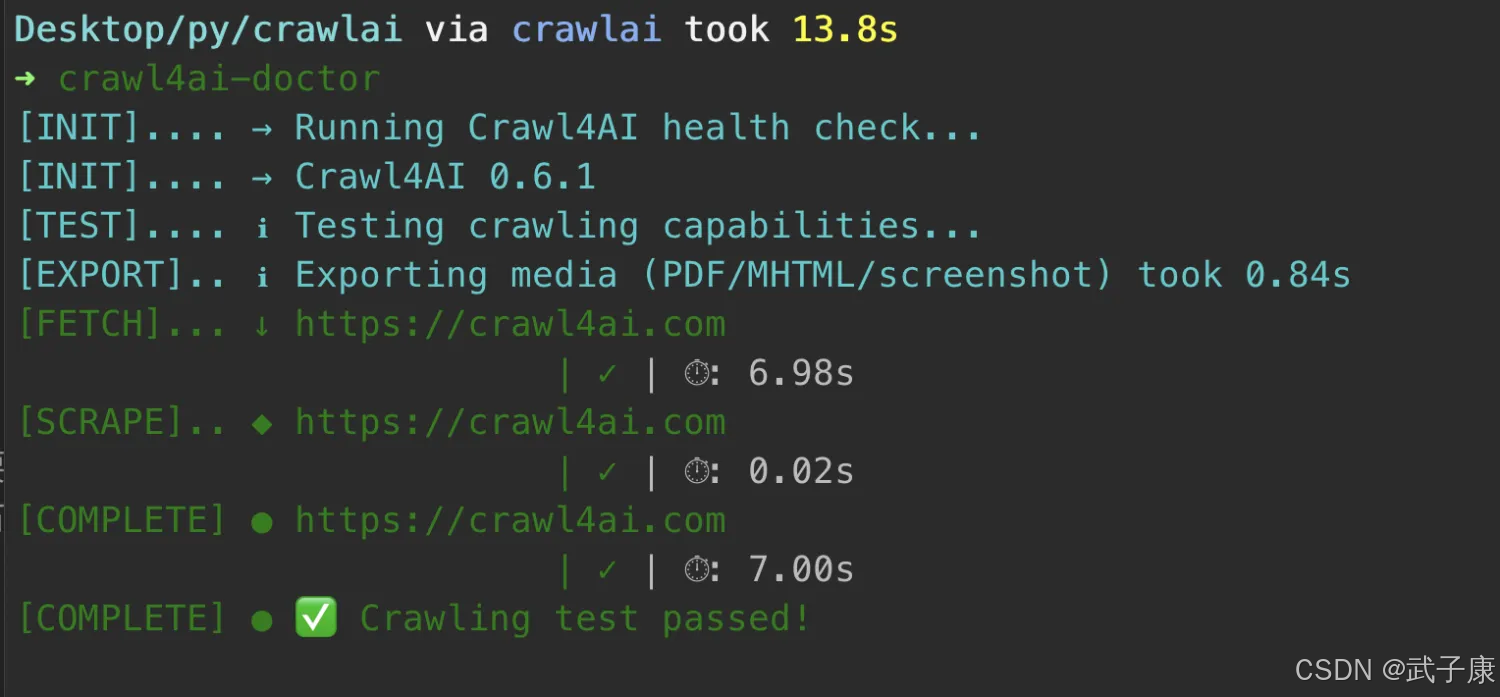
检查环境
crawl4ai-doctor
如果一切正确,则出现的样子如下:
Docker方式
可以通过Docker来部署
拉取镜像
docker pull unclecode/crawl4ai
执行结果:
运行项目
docker run -d -p 11235:11235 --name crawl4ai --shm-size=1g unclecode/crawl4ai
访问项目
http://localhost:11235/playground
访问页面如下所示:
