【大模型部署】mac m1本地部署 ChatGLM3-6B 超详细教程
本人环境:macOS 15.5 (Sonoma) - Apple M1 / 16 G
目标:在 mac m1 16G 上 完全离线 的本地模型目录上,跑通官方 ChatGLM3-6B
目录
-
背景 & 踩坑记录
-
准备工作
-
新建 Conda 环境并安装依赖
-
关键环境变量
-
运行 composite_demo
-
常见报错与解决方案
-
运行效果截图
-
结语 & 参考链接
1 背景 & 踩坑记录
ChatGLM3-6B 出来后,很多小伙伴(包括我🙋♂️)直接 git clone + pip install -r requirements.txt 结果一路红 ❌:
| 报错 | 根因 |
|---|---|
| ModuleNotFoundError: huggingface_hub.inference._text_generation | hub≥0.30 路径改动 |
| ImportError: Using low_cpu_mem_usage=True ... requires Accelerate | accelerate 版本过低 / 未装 |
| NotImplementedError: aten::isin ... on MPS | PyTorch MPS 后端缺少算子 |
| RuntimeError: torch.classes ... __path__._path | Streamlit 热重载探测 torch.classes |
因此本文一步到位给出一套「官方 issue 实测可行」的版本组合,并解释 为什么 这样配才最稳。
2 准备工作
-
硬件:Apple M1 (16 GB 内存起步,建议 32 GB 更稳)
-
软件:
-
Conda ≥ 23.x(本文用 miniforge)
-
Git & Homebrew
-
-
模型文件:
~/models/chatglm3-6b/
├── config.json
├── pytorch_model-00001-of-00007.bin
├── ...
└── tokenizer.model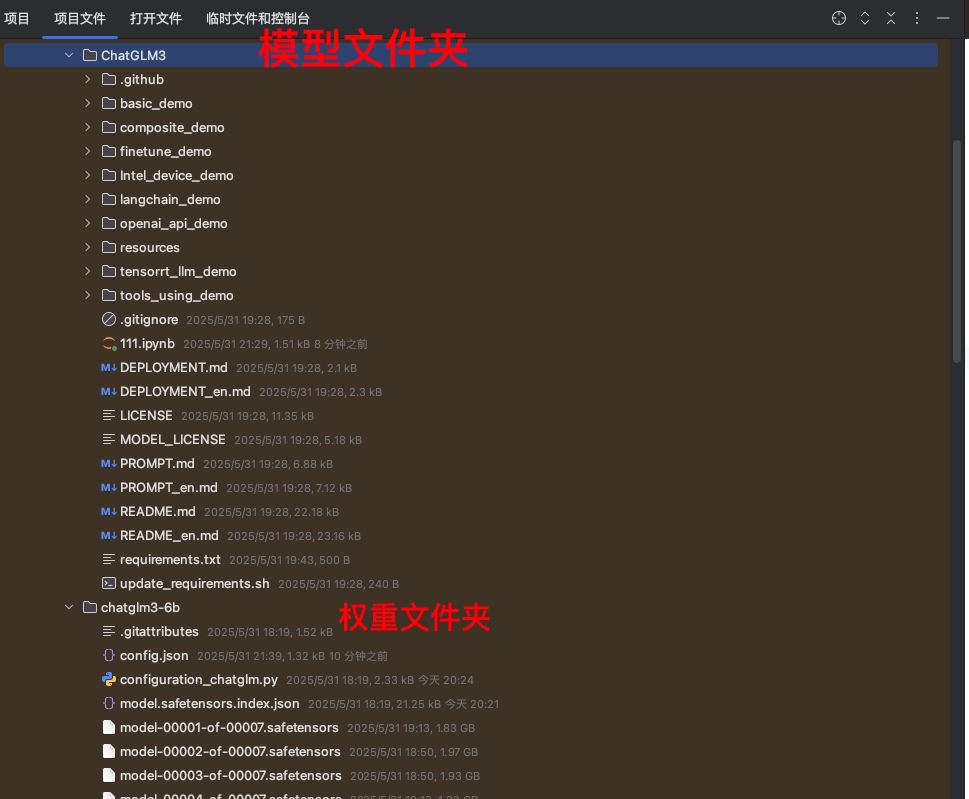
# 下载模型文件和权重文件
cd models/
# 下载模型文件
git clone https://github.com/THUDM/ChatGLM3.git# 下载权重文件
# 1. 先下载小文件
GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/THUDM/chatglm3-6b.git
# 2. 进入目录
cd chatglm3-6b
# 3. 下载大文件(分两步是方便看进度,因为权重50G,一步到位的下载看不到进度)
#git lfs pull 等价于先 git lfs fetch(只抓当前分支对应的对象)再 git lfs checkout(将指针替换为大文件)。
git lfs pull也可以 git lfs clone https://huggingface.co/THUDM/chatglm3-6b,或从同事处拷贝离线权重。我这里是用的是代理方式下载。
3 新建 Conda 环境并安装依赖
为什么固定这些版本?
transformers 4.40.0 :ChatGLM3 官方示例锁的版本,兼容 hub<0.30
huggingface_hub 0.19.4 :仍包含旧私有路径 _text_generation
torch 2.2.2 :MPS 稳定版,兼容 peft/cpm_kernels
accelerate 0.26.0 :device_map="auto" 需要的最低版本
streamlit 1.45.1 :避免热重载新 BUG
其余库满足 GLM3 推理 + 内核 + Notebook 需求
新建conda 环境和下载依赖包
# 0)推荐单独新建,避免污染原有 Python
conda create -n glm3-demo python=3.10 -y && conda activate glm3-demo# 1)一次性安装“老三件”+ 其他依赖
pip install "torch==2.2.2" \"transformers==4.40.0" \"huggingface_hub==0.19.4" \"accelerate==0.26.0" \"peft==0.10.0" \"streamlit==1.45.1" \"cpm_kernels>=1.0.11" \"sentencepiece>=0.2.0" \"jupyter_client>=8.6.0"⚠️ 注意
绝对不要 pip install -U transformers 或 pip install huggingface_hub>=0.30,否则又会踩回“私有路径丢失”坑。
如果你想体验最新功能,需手改源码 → 见第 6 节“升级方案”。
4 关键环境变量
| 变量 | 作用 | 必须放在 import torch 之前 |
|---|---|---|
| STREAMLIT_SERVER_ENABLE_FILE_WATCHER=false | 关闭 Streamlit 热重载,绕开 torch.classes 路径报错 | ✅ |
| PYTORCH_ENABLE_MPS_FALLBACK=1 | MPS 不支持算子时自动回退 CPU,避免 isin 报错 | ✅ |
设置方式:(推荐)
export STREAMLIT_SERVER_ENABLE_FILE_WATCHER=false
export PYTORCH_ENABLE_MPS_FALLBACK=1或者在 composite_demo/main.py 顶部写:(我没有这么干)
import os, torch
os.environ["STREAMLIT_SERVER_ENABLE_FILE_WATCHER"] = "false"
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
torch.classes.__path__ = [] # 再保险5 运行 composite_demo
cd /path/to/ChatGLM3 # 仓库根目录
streamlit run composite_demo/main.py --server.fileWatcherType none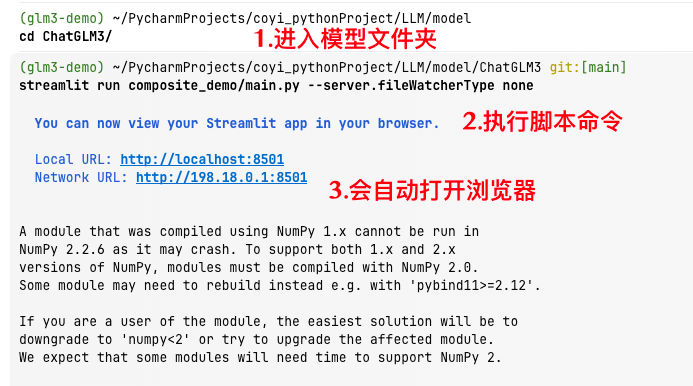
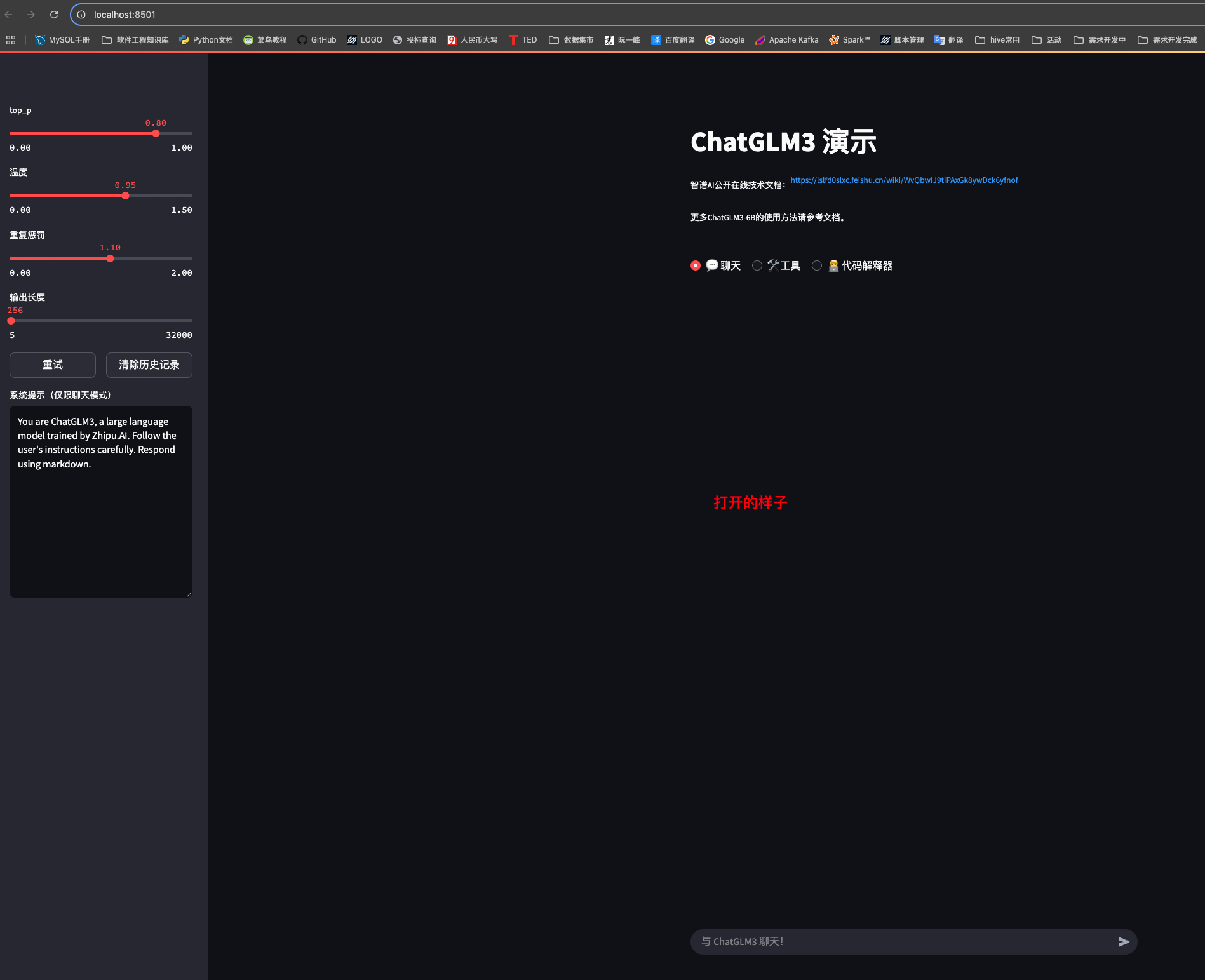
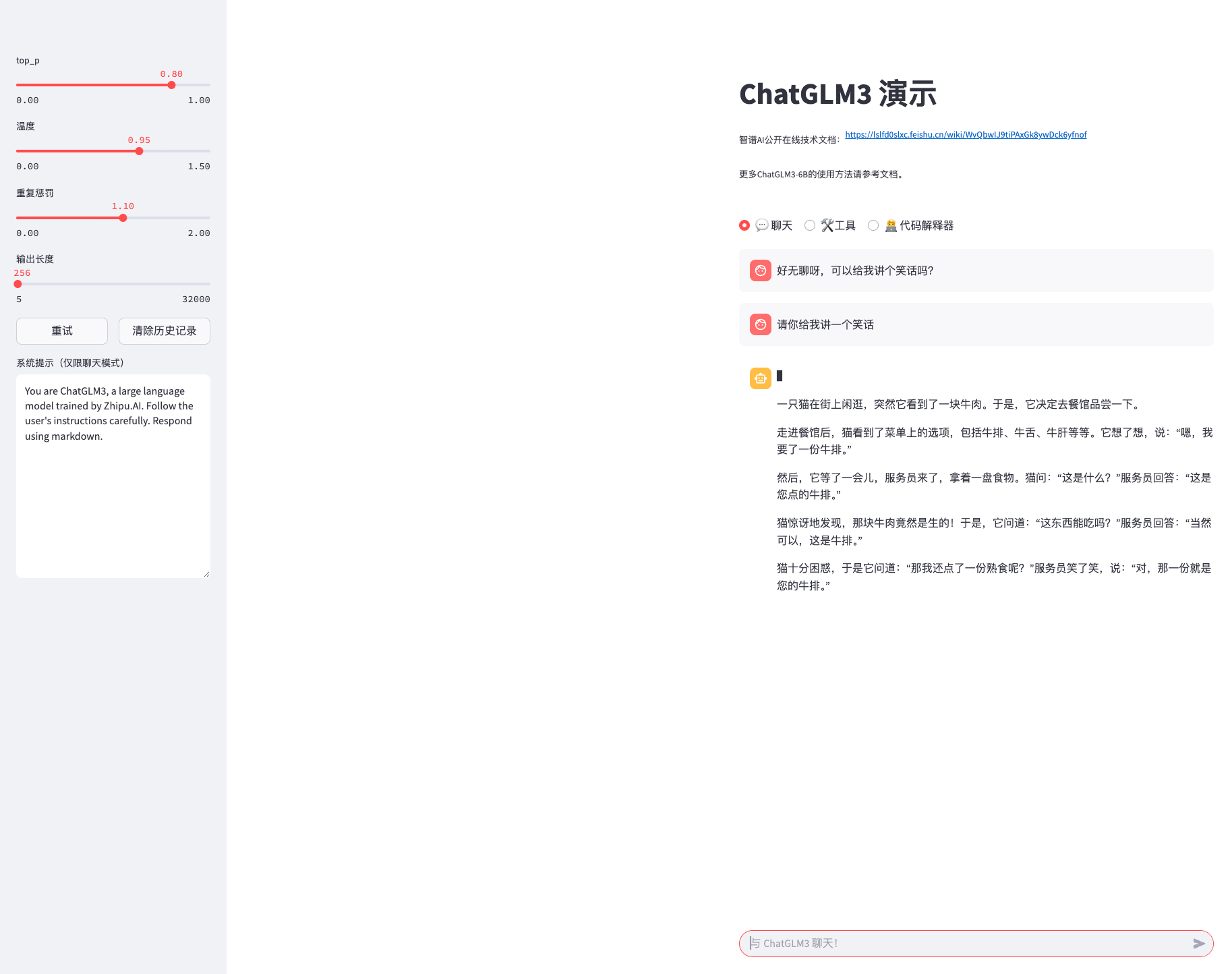
浏览器自动打开 http://localhost:8501,就能看到下图界面👇
6 常见报错与解决方案
| 报错关键词 | 可能原因 | 解决办法 |
|---|---|---|
| _text_generation Not found | hub ≥ 0.30 改路径 | 固定 hub==0.19.4 或改 client.py 引入 |
| low_cpu_mem_usage=True requires Accelerate | accelerate 未装 / 版本<0.26 | pip install -U accelerate>=0.26.0 |
| aten::isin ... MPS | MPS 缺算子 | export PYTORCH_ENABLE_MPS_FALLBACK=1 或安装 PyTorch Nightly |
| torch.classes __path__._path | Streamlit 热重载 | export STREAMLIT_SERVER_ENABLE_FILE_WATCHER=false |
| OOM / swap 爆掉 | 模型全精度占内存 13 GB+ | 加 4-bit int 模型或 CPU+FP32 |
升级到最新版 transformers?
想要 4.52.x + hub 0.32.x,需要:
# client.py 旧写法
from huggingface_hub.inference._text_generation import TextGenerationStreamResult
# 改成
from huggingface_hub.inference._generated.types.text_generation import (TextGenerationStreamResult,
)再升级库即可。
7 运行效果截图
下侧参数栏 = top_p / temperature / repetition_penalty / max_new_tokens
到此,Mac M1 完全离线跑 ChatGLM3-6B 的流程就梳理完毕。核心思想只有三点:
-
锁定 “老三件”(transformers 4.40 + hub 0.19 + accelerate 0.26)
-
关闭 Streamlit 热重载,同时 开启 MPS Fallback
-
缺什么补什么,不轻易乱升级
-
下面讲一讲这个页面的参数设置
参数设置解释:
下面用更口语化、简单易懂的话来解释这四个参数,让你一看就明白它们对生成效果的影响。
1. top_p(核采样概率)
-
干什么的?
控制“候选词”的范围。模型每一步会给出很多可能的词,并给出它们的“可能性”高低。top_p 就是说:我只要把概率累加到某个百分比,就把这些最有希望出现的词留下来,其他概率特别低的词就不考虑,最后在留住的那批词中随机选一个出来。
-
怎么影响结果?
-
如果 top_p=1.0,就意味着“全盘考虑”,所有词都有机会被选。(这跟不做 top_p 过滤等价)
-
如果 top_p=0.8,就只在概率最前面累加到 80% 的那部分词里挑,剩下20%低概率的词被直接扔掉。这样能保证输出不会太“离谱”,也还保留了一点随机。
-
-
简单说:
-
把这个数字调小(比如 0.5),候选范围就更小,句子更“保守”、更容易生成常见表达。
-
调到接近 1.0(比如 0.95),候选更多,生成会更“活跃”、“多样”,但也有可能出现一些冷门、奇怪的词。
-
2. 温度(temperature)
-
干什么的?
控制“随机性”的强弱。模型给每个词一个得分,接着做 Softmax 变成概率。这个概率之前会先除以温度 T:
-
把分数 ÷ T,然后再做归一化
-
-
当 T < 1 时,分数差距会被“放大”,高分词更容易被选,随机性降低,句子更“确定”。
-
当 T > 1 时,分数差距会被“压平”,低分词的机会增大,随机性变高,句子更“花样”,可能有点“天马行空”。
-
-
怎么影响结果?
-
T = 0.5(低温度):输出很稳定,几乎总是挑几率最大的词,适合希望答案很靠谱、不爱跑偏的场景。
-
T = 1.0:默认的“正常随机度”。
-
T = 1.3(高温度):输出比较活跃,可能会冒出一些有创意、没那么常见的词,但也容易跑题。
-
-
简单说:
温度越低(0.2~0.5),句子越“板正”、越不会出意外;温度越高(1.0~1.5),句子越“活泼”、“有新意”,但风险是可能会出现不太靠谱的表达。
3. 重复惩罚(repetition_penalty)
-
干什么的?
防止模型不停地重复同一句话或同一个词。每次模型想输出一个已经在对话里出现过的词,就给它打点折扣,让它这次不要总选同一个。
-
怎么影响结果?
-
repetition_penalty = 1.0:不做惩罚(相当于关闭),模型可能出现“我我我……”“哈哈哈……”“再见再见……”这种重复。
-
repetition_penalty = 1.1:轻度惩罚,出现过一次的词,下次出现的可能性会被除以 1.1,能稍微抑制重复。
-
repetition_penalty = 1.3 甚至更高:惩罚力度更大,模型几乎不会重复之前那一串字。但如果惩罚过强,也可能把一些该出现的关联词也给压下去,造成句子稍微奇怪。
-
-
简单说:
想让输出更“丰富”、不要老是同样几句话循环,就把这个数字调高一点(1.1~1.2);
想让输出更“流畅”,没什么重复烦恼,就留在 1.0~1.1。
4. 输出长度(max_new_tokens 或 max_output_length)
-
干什么的?
控制“最多能多说多少字”。默认是让模型在看到你的提问后,最多生成这么多个 token(token 通常相当于一个汉字或一个单词的一部分)的回答。到了上限就不再往下说了。
-
怎么影响结果?
-
输出长度 = 20~50:短小精悍的回答,就像一句话或两句话,适合问个小问题拿个结论。
-
输出长度 = 256~512:回答会很长,像一段段故事、长文档、代码示例之类,适合写文章、写长段解释。
-
如果你设置得太短,模型可能回答得过于简略;设置太长,容易让模型“唠叨”或跑题。
-
-
简单说:
这就像给模型“说话时间”的最大限制——给多少就说多少。
5. 重试 & 清除历史
-
重试:点一次“重试”就再用当前这套参数(top_p、temperature、重复惩罚、输出长度)重新生成一个答案,通常会和上一次稍有不同,因为其中有随机采样的成分。
-
清除历史:清掉当前对话框里已经生成过的所有问答内容,下次提问就好像从零开始,没有上下文,比较适合换话题。
简单的调参思路
-
想要稳定靠谱:
-
温度(temperature)调低到 0.7~0.9;
-
top_p 调到 0.8 左右;
-
重复惩罚(repetition_penalty)设 1.0~1.1;
-
输出长度控制在 128~256 之间。
这样,生成的大部分句子都比较常规、不离谱,也不会乱跑题。
-
-
想要更“有趣”或“发散”:
-
温度提高到 1.1~1.3;
-
top_p 增加到 0.9~0.95;
-
重复惩罚设 1.1~1.2;
-
输出长度可以 256 起跳、甚至 512。
此时会出现一些比较新奇的表达或意想不到的句子,但也要小心有时会跑偏、语义不太连贯。
-
-
只想要一句话回答:
-
输出长度设得小一些(如 20~50);
-
温度 0.5~0.7;
-
top_p 0.8;
-
重复惩罚 1.0~1.1。
这样回答简短干脆,不会多说。
-
-
出现老是重复同一句话的情况:
-
把重复惩罚从 1.0 调到 1.2~1.3 看看;
-
也可以稍微调低温度或调低 top_p,减少随机性有时也有帮助。
-
总结
-
top_p(核采样):控制候选词的“范围”——去掉那部分“太低概率”的词。
-
温度(temperature):控制随机性——温度低.outputs 更确定;温度高.outputs 更随机。
-
重复惩罚(repetition_penalty):防止循环重复——值越大越抑制重复。
-
输出长度(max_new_tokens):规定最多能多“说”多少字,就到上限停下。
只要搞清楚它们各自的作用,就可以根据自己的需求(“要稳”还是“要酷”或“要短”)去调参,让模型输出符合预期。
8 结语 & 参考链接
-
ChatGLM3 官方 Repo
-
PyTorch GitHub Issue #77764
-
HuggingFace Hub 路径迁移 PR #2199
建议本地部署使用量化版本,因为 m1 电脑版本还是太低了,没有cuda,mps 目前还不支持,只靠cpu ,推理特别的慢,本次只是能用,建议换个好点的GPU啥的也行。
如果本文对你有帮助,不妨 点赞 / 收藏 / 关注,后续我会持续更新 深度学习,和大模型相关的知识 在 Apple Silicon 上的部署踩坑记录。
Happy Hacking! 🎉