【机器学习基础】机器学习入门核心算法:XGBoost 和 LightGBM
机器学习入门核心算法:XGBoost 和 LightGBM
- 一、算法逻辑
- XGBoost (eXtreme Gradient Boosting)
- LightGBM (Light Gradient Boosting Machine)
- 二、算法原理与数学推导
- 目标函数(二者通用)
- 二阶泰勒展开:
- XGBoost 分裂点增益计算:
- LightGBM 直方图加速:
- 三、模型评估
- 常用评估指标:
- 过拟合控制:
- 四、应用案例
- XGBoost 典型场景:
- LightGBM 典型场景:
- 五、面试题及答案
- 常见问题:
- 六、相关论文
- 七、优缺点对比
- 总结
一、算法逻辑
XGBoost (eXtreme Gradient Boosting)
- 核心思想:
基于梯度提升框架(Gradient Boosting),通过迭代添加弱学习器(CART树)优化损失函数,支持正则化防止过拟合。 - 关键优化:
- 预排序(Pre-sorted):对特征值预先排序并存储为块结构,加速分裂点查找。
- 加权分位数草图(Weighted Quantile Sketch):近似算法高效生成候选分裂点。
LightGBM (Light Gradient Boosting Machine)
- 核心思想:
针对XGBoost计算效率瓶颈改进,核心是 直方图算法(Histogram-based) 和 生长策略优化。 - 关键创新:
- Gradient-based One-Side Sampling (GOSS):保留大梯度样本,随机采样小梯度样本。
- Exclusive Feature Bundling (EFB):互斥特征捆绑,减少特征维度。
- Leaf-wise 生长策略:选择增益最大叶子分裂,提升精度但可能加深树深。
二、算法原理与数学推导
目标函数(二者通用)
第 t t t 次迭代的目标函数:
O b j ( t ) = ∑ i = 1 n L ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) Obj^{(t)} = \sum_{i=1}^{n} L(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t) Obj(t)=i=1∑nL(yi,y^i(t−1)+ft(xi))+Ω(ft)
其中正则项 Ω ( f t ) = γ T + 1 2 λ ∥ w ∥ 2 \Omega(f_t) = \gamma T + \frac{1}{2}\lambda \|w\|^2 Ω(ft)=γT+21λ∥w∥2( T T T为叶子数, w w w为叶子权重)。
二阶泰勒展开:
O b j ( t ) ≈ ∑ i = 1 n [ L ( y i , y ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) Obj^{(t)} \approx \sum_{i=1}^{n} \left[ L(y_i, \hat{y}^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i) \right] + \Omega(f_t) Obj(t)≈i=1∑n[L(yi,y^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)
其中 g i = ∂ y ^ ( t − 1 ) L ( y i , y ^ ( t − 1 ) ) g_i = \partial_{\hat{y}^{(t-1)}} L(y_i, \hat{y}^{(t-1)}) gi=∂y^(t−1)L(yi,y^(t−1)), h i = ∂ y ^ ( t − 1 ) 2 L ( y i , y ^ ( t − 1 ) ) h_i = \partial_{\hat{y}^{(t-1)}}^2 L(y_i, \hat{y}^{(t-1)}) hi=∂y^(t−1)2L(yi,y^(t−1))。
XGBoost 分裂点增益计算:
G a i n = 1 2 [ ( ∑ i ∈ I L g i ) 2 ∑ i ∈ I L h i + λ + ( ∑ i ∈ I R g i ) 2 ∑ i ∈ I R h i + λ − ( ∑ i ∈ I g i ) 2 ∑ i ∈ I h i + λ ] − γ Gain = \frac{1}{2} \left[ \frac{(\sum_{i \in I_L} g_i)^2}{\sum_{i \in I_L} h_i + \lambda} + \frac{(\sum_{i \in I_R} g_i)^2}{\sum_{i \in I_R} h_i + \lambda} - \frac{(\sum_{i \in I} g_i)^2}{\sum_{i \in I} h_i + \lambda} \right] - \gamma Gain=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ
I L , I R I_L, I_R IL,IR 为分裂后左右子节点样本集。
LightGBM 直方图加速:
- 将连续特征离散化为 k k k 个桶(默认256),生成直方图。
- 分裂时遍历直方图桶,计算增益:
G a i n = max j ∈ [ 1 , k ] ( ( ∑ i ∈ B l e f t j g i ) 2 ∑ i ∈ B l e f t j h i + λ + ( ∑ i ∈ B r i g h t j g i ) 2 ∑ i ∈ B r i g h t j h i + λ ) Gain = \max_{j \in [1,k]} \left( \frac{(\sum_{i \in B_{left}^j} g_i)^2}{\sum_{i \in B_{left}^j} h_i + \lambda} + \frac{(\sum_{i \in B_{right}^j} g_i)^2}{\sum_{i \in B_{right}^j} h_i + \lambda} \right) Gain=j∈[1,k]max(∑i∈Bleftjhi+λ(∑i∈Bleftjgi)2+∑i∈Brightjhi+λ(∑i∈Brightjgi)2)
其中 B l e f t j B_{left}^j Bleftj 和 B r i g h t j B_{right}^j Brightj 为按桶 j j j 分裂的样本子集。
三、模型评估
常用评估指标:
| 任务类型 | 指标 |
|---|---|
| 分类 | AUC, F1-Score, 准确率 |
| 回归 | RMSE, MAE, R-squared |
| 排序 | NDCG, MAP |
过拟合控制:
- XGBoost:
gamma(分裂阈值)、lambda(L2正则)、subsample(样本采样)。 - LightGBM:
min_data_in_leaf、feature_fraction(特征采样)、lambda_l1/l2。
四、应用案例
XGBoost 典型场景:
- Kaggle竞赛:2015-2016年多数表格数据竞赛冠军方案。
- 金融风控:预测贷款违约概率(如Lending Club数据集)。
LightGBM 典型场景:
- 大规模数据:腾讯广告点击率预测(十亿级样本)。
- 高维特征:推荐系统特征工程(EFB减少特征维度)。
五、面试题及答案
常见问题:
-
Q: XGBoost 为什么用二阶导数?
A: 二阶导提供损失函数的曲率信息,比一阶导更精准定位最优解,加速收敛。 -
Q: LightGBM 的 Leaf-wise 为什么更快但可能过拟合?
A: Leaf-wise 减少不必要的分裂(对比 Level-wise),但树深度可能更大,需通过max_depth和min_data_in_leaf约束。 -
Q: 直方图算法的缺点?
A: 离散化引入误差,桶数量少时精度下降(精度与效率权衡)。
六、相关论文
-
XGBoost:
Chen & Guestrin, 2016. “XGBoost: A Scalable Tree Boosting System”
Key: 分布式加权分位数草图、稀疏感知算法。 -
LightGBM:
Ke et al., 2017. “LightGBM: A Highly Efficient Gradient Boosting Decision Tree”
Key: GOSS 样本采样、EFB 特征捆绑、直方图优化。
七、优缺点对比
| 算法 | 优点 | 缺点 |
|---|---|---|
| XGBoost | 1. 精度高,正则化强; 2. 支持自定义损失函数; 3. 树结构可解释性好。 | 1. 内存消耗大(预排序); 2. 训练速度较慢。 |
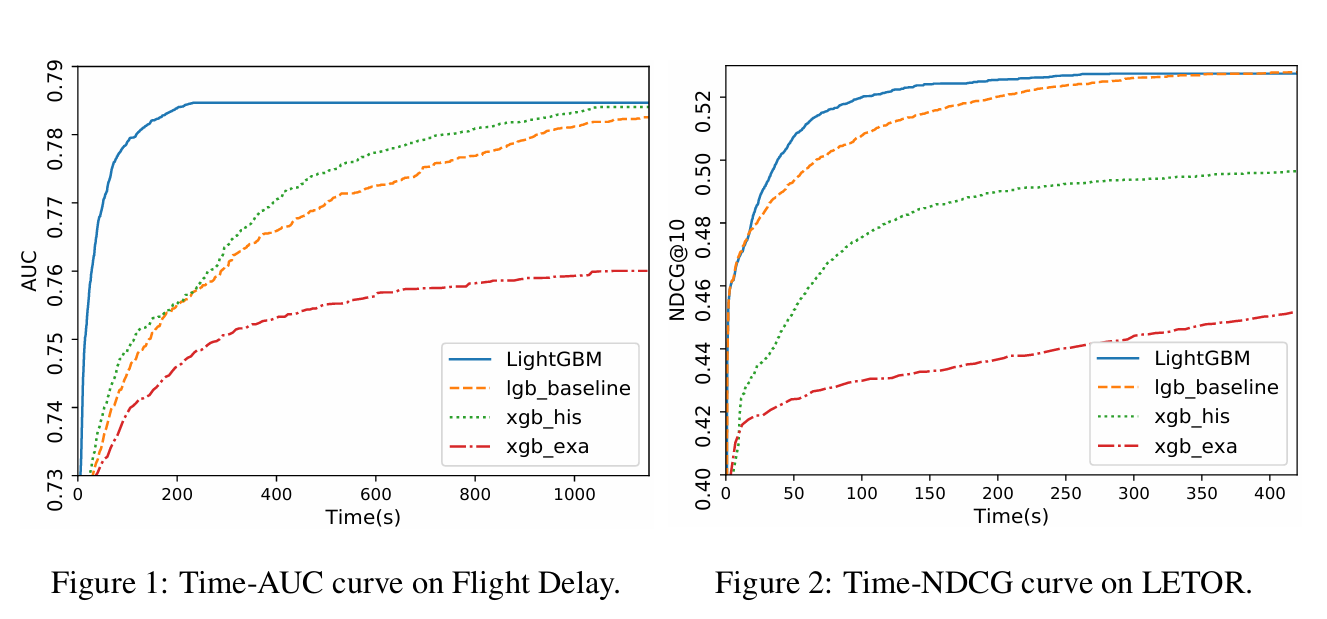
| LightGBM | 1. 训练速度快3~5倍; 2. 内存占用低; 3. 支持大规模数据并行。 | 1. 小数据集易过拟合; 2. 离散化可能损失精度。 |
总结
- XGBoost:精度优先,适合中小规模数据、需强正则化的场景。
- LightGBM:效率优先,适合大规模数据、高维特征、实时性要求高的场景。
两者均属于GBDT优化框架,选择需权衡数据规模、特征维度与精度要求。