小狼毫输入法雾凇拼音输入方案辅码由默认的部件拆字/拼音输入方案修改为五笔画方案
搜狗拼音输入法不单单是弹出广告的问题,还有收集输入习惯等隐私的嫌疑。所以最近彻底删除了这个输入法,改安装了小狼毫输入法。关于小狼毫输入法的安装和使用网上已经有了无数文章,我这里就不重复了。在试用多个拼音方案后,最终我决定使用雾凇拼音输入方案,该方案的最新版本不需要对配置文件作大的修改就能很方便的使用。唯一比较不满意的是,在输入拼音后,再键入`触发辅码输入并继续输入辅码以减少候选字的数量时,它的默认辅码拆字方案是部件拆字/拼音输入方案字典文件radical_pinyin.dict.yaml中的字表,很多汉字部件的辅码需要记忆,例如“龥”字(这个字是Unicode码表的最后一个中文字符)的左半边,它的辅码是“yue”,太不直观了,不如将它改成与搜狗拼音类似的以笔画名称第一个字母做辅码的方式,以免除记忆辅码的负担。
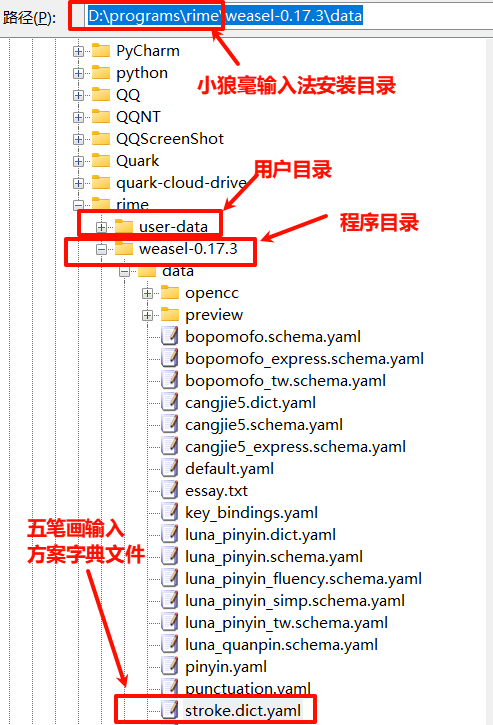
如果手工修改radical_pinyin.dict.yaml中的字表,6万4千多个汉字简直要命。好在小狼毫输入法自带有五笔画输入方案,可以将该方案字典文件stroke.dict.yaml(在程序文件夹“weasel-版本号”下的data目录里)中的字表复制,然后替换radical_pinyin.dict.yaml中的汉字字表即可,无须修改任何配置文件。
此外,因为`在雾凇拼音输入方案中承担了一些特殊任务,默认情况下中文输入时`没有转换为·(这对于在md文件中输入代码反而成了福音,无须进行中英文切换),这个符号可以通过输入拼音“jiangehao”输入,或者在custom_phrase.txt中添加一行:
· jg
重新部署后输入jg,·就成了第一个候选字。如果使用双拼,则需要将custom_phrase.txt复制后粘贴到同一目录下,并将文件名修改为custom_phrase_double.txt。
经过这样的改造,小狼毫输入法比搜狗输入法还好用,因为输入颜文字和特殊符号更方便。再输入龥字时,如果输入拼音“yu”后候选字中找不到龥字,可以继续输入`,然后输入辅码pnhs,它就已经成了第一个候选字了。碰上不认识的生僻字,可以键入uU进入拆字模式,直接按顺序键入笔画将这个字输入,无须切换到五笔画输入法。五笔画拆字方案的笔画名称包括hspnz,对应横竖撇捺折,比搜狗输入法少了一个d(点),点则被当作短捺,输入n即可。当前版本有个小bug,三点水输入辅码时本来应该是nnn,但键入两个nn后候选字会消失,要键入第三个n后候选字才会出现,例如湘字,微软双拼键入:
xd`nn
这时没有候选字了,继续键入一个n
xd`nnn
湘字就成了唯一候选字。这告诉我们如果在输入某个笔画后看不到候选字了,可以继续输入后续笔画试试,让子弹飞一会儿。
另外要说明的是,stroke.dict.yaml包含九万多个汉字,远远超过radical_pinyin.dict.yaml中的汉字数量,勤快点的话,可以写个python程序过滤掉stroke.dict.yaml多余的汉字以减小文件大小,不过本益比似乎并不划算。下面即为能够实现这一目的的python代码,运行后代码所在目录中的c.txt改名为radical_pinyin.dict.yaml并拷贝到小狼毫输入法用户目录即可重新部署:
import redef replace_lines_in_a(a_filepath, b_filepath, output_filepath):"""遍历a.txt中的每一行,如该行以汉字开头,则在b.txt中查找以同一个汉字开头的行,并用b.txt中对应行的内容替代a.txt中的该行内容。Args:a_filepath (str): a.txt的路径。b_filepath (str): b.txt的路径。output_filepath (str): 存储结果的新文件的路径。"""b_lines_map = {}# 预处理b.txt,将以汉字开头的行存储到字典中,方便快速查找try:with open(b_filepath, 'r', encoding='utf-8') as f_b:for line_b in f_b:line_b = line_b.strip()if line_b: # 确保行不为空first_char = line_b[0]# 只要汉字开头的行。r'[\u4e00-\u9fa5]'只能匹配21902个汉字,远少于文件中的汉字,# 所以根据文件内容特点用r'[^a-z\._#\s]'排除不以汉字开头的行if re.match(r'[^a-z\._#\s]', first_char):b_lines_map[first_char] = line_bexcept FileNotFoundError:print(f"错误:文件 {b_filepath} 未找到。")returnexcept Exception as e:print(f"读取文件 {b_filepath} 时发生错误:{e}")returnprint(f'{len(b_lines_map)=}')output_lines = []try:with open(a_filepath, 'r', encoding='utf-8') as f_a:for line_a in f_a:line_a = line_a.strip()if line_a:first_char_a = line_a[0]if re.match(r'[^a-z\._#\s]', first_char_a):# 如果a.txt中的行以汉字开头,并且b_lines_map中有对应的汉字开头的行if first_char_a in b_lines_map:output_lines.append(b_lines_map[first_char_a])# else:# output_lines.append(line_a) # 如果b.txt中没有对应行,则保留原行else:output_lines.append(line_a) # 如果不是以汉字开头,则保留原行else:output_lines.append(line_a) # 保留空行except FileNotFoundError:print(f"错误:文件 {a_filepath} 未找到。")returnexcept Exception as e:print(f"读取文件 {a_filepath} 时发生错误:{e}")returnprint(f'{len(output_lines)=}')try:with open(output_filepath, 'w', encoding='utf-8') as f_out:for line in output_lines:f_out.write(line + '\n')print(f"处理完成,结果已保存到 {output_filepath}")except Exception as e:print(f"写入文件 {output_filepath} 时发生错误:{e}")if __name__ == "__main__": a_file = r"D:\programs\rime\user-data\radical_pinyin.dict - 原版备份.yaml"b_file = r"D:\programs\rime\weasel-0.17.3\data\stroke.dict.yaml"output_file = "c.txt" # 生成的新文件replace_lines_in_a(a_file, b_file, output_file)有关文件所在目录如下图所示:

从此小狼毫输入法就成了我在Windows平台的唯一输入法。😀
最近GitHub总是上不去,完成后的方案文件(增加了五笔输入86版,对原始配置文件做了一些小修改,例如句号不上屏,左右shift键都能在中英文输入之间切换)参见https://download.csdn.net/download/yivifu/90942276。