西瓜书第九章——集成学习
集成学习
顾名思义,集成学习(ensemble learning)指的是将多个学习器进行有效地结合,组建一个“学习器委员会”,其中每个学习器担任委员会成员并行使投票表决权,使得委员会最后的决定更能够四方造福普度众生…,即其泛化性能要能优于其中任何一个学习器。
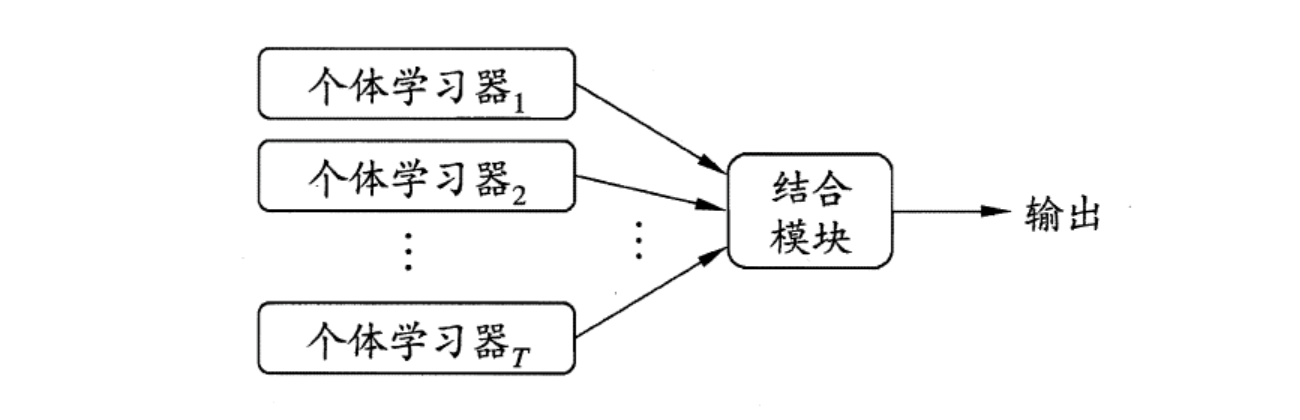
集成学习的关键是训练准确率高且具有多样性的基学习器。
以下是三种主流的集成学习方法Boosting、Bagging以及随机森林(Random Forest)
Boosting
Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合
Boosting的有效性
Boosting的有效性可从以下角度解释:
- 偏差-方差分解:
降低偏差:Boosting通过迭代优化,使模型更关注难样本,减少模型欠拟合。
控制方差:通过加权投票(如AdaBoost)或梯度优化(如GBDT),避免过拟合。 - 自适应学习:
每一轮迭代根据前一轮的误差调整样本权重或模型参数,逐步逼近真实数据分布。 - 理论保证:
AdaBoost的损失函数(指数损失)与分类误差直接相关,最小化损失等价于最小化误差。
AdaBoost原理
Boosting的核心原理
以最经典的AdaBoost(Adaptive Boosting)为例,每次训练迭代中加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,而对于预测错误的样本也增加其权重,使得后续分类是更加关注这些样本
(1) 算法流程
-
初始化权重:
对 N 个样本赋予相同权重 w i = 1 N w_i = \frac{1}{N} wi=N1 。
-
迭代训练弱学习器:
每一轮用当前样本分布训练一个弱学习器 G t ( x ) G_t(x) Gt(x)。
计算该学习器的加权错误率 ϵ t = ∑ i = 1 N w i ⋅ I ( y i ≠ G t ( x i ) ) \epsilon_t = \sum_{i=1}^N w_i \cdot I(y_i \neq G_t(x_i)) ϵt=∑i=1Nwi⋅I(yi=Gt(xi))。
计算学习器权重 α t = 1 2 ln ( 1 − ϵ t ϵ t ) \alpha_t = \frac{1}{2} \ln \left( \frac{1-\epsilon_t}{\epsilon_t} \right) αt=21ln(ϵt1−ϵt)(错误率越低,权重越高)。
-
更新样本权重:
增加误分类样本的权重: w i ← w i ⋅ e α t w_i \leftarrow w_i \cdot e^{\alpha_t} wi←wi⋅eαt 。
减少正确分类样本的权重: w i ← w i ⋅ e − α t w_i \leftarrow w_i \cdot e^{-\alpha_t} wi←wi⋅e−αt 。
归一化权重,使其和为1。
-
组合弱学习器:
最终模型为加权投票: G ( x ) = sign ( ∑ t = 1 T α t G t ( x ) ) G(x) = \text{sign} \left( \sum_{t=1}^T \alpha_t G_t(x) \right) G(x)=sign(∑t=1TαtGt(x))。
(2) 关键公式
- 指数损失函数:
L ( y , f ( x ) ) = e − y f ( x ) , 其中 f ( x ) 为模型输出 L(y, f(x)) = e^{-y f(x)}, \quad \text{其中 } f(x) \text{ 为模型输出} L(y,f(x))=e−yf(x),其中 f(x) 为模型输出
- 样本权重更新:
w i ( t + 1 ) = w i ( t ) ⋅ e − α t y i G t ( x i ) Z t w_i^{(t+1)} = \frac{w_i^{(t)} \cdot e^{-\alpha_t y_i G_t(x_i)}}{Z_t} wi(t+1)=Ztwi(t)⋅e−αtyiGt(xi)
Z t Z_t Zt 为归一化因子。
Bagging——自助法抽象
核心思想:
通过有放回抽样(Bootstrap Sampling)构建多个差异化的训练子集,并行训练基学习器后投票集成,重点降低模型方差。
关键特点:
样本扰动:每个基学习器使用不同的训练子集(约63.2%的样本被选中,剩余36.8%作为袋外数据可用于验证)。
基学习器要求:需选择 高方差、低偏差 的模型(如深度决策树、神经网络),通过集成平滑预测波动。
输出聚合:分类任务采用投票,回归任务采用平均。
算法流程:
从原始数据集中有放回抽取 m 个样本,重复 T 次,生成 T 个训练子集。
随机森林——Bagging升级版
-
核心思想:
在Bagging的基础上,增加特征随机选择,进一步增强基学习器的多样性,同时降低方差与部分偏差。 -
关键改进——双重随机
样本随机:Bootstrap采样(同Bagging)。
特征随机:每个节点分裂时,仅从随机选取的 K 个特征(推荐 K = log 2 ( d ) K=\log_2(d) K=log2(d),d 为总特征数)中选择最优分裂点。 -
基学习器:固定为决策树,但通过特征扰动减少单棵树的相关性。
-
算法流程:
从原始数据中有放回采样生成训练子集(同Bagging)。
对每棵决策树的分裂过程:
随机选择 K 个候选特征。
从这 K 个特征中找最优分裂点(而非所有特征)。
聚合所有树的预测结果。 -
优势:
比Bagging更强的抗过拟合能力(特征扰动减少树间相关性)。
天然支持特征重要性评估。
训练效率高(特征子集减少计算量)。
具体的集成方法
1.平均(回归问题)
多个基学习器加权平均
2.投票(分类问题)
3. 学习法(Stacking)
核心思想:
用基学习器的输出作为新特征,训练一个小模型进行最终预测。