存储引擎---数据库
数据库的存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式
数据库系统管理的核心组件之一,负责数据的存储、检索和管理。它决定了数据如何存储在磁盘上,如何被索引,如何支持事务和并发操作等。不同的存储引擎有不同的设计目标和优化方向,适应于不同的应用场景,
存储引擎的核心功能:
-
数据存储:
-
定义数据的物理存储格式(如行存储、列存储)。
-
管理数据在磁盘上的分布(如页、块、文件)。
-
-
数据检索:
-
提供高效的索引结构(如B+Tree、LSM-Tree)。
-
支持快速查询和数据过滤。
-
-
事务管理:
-
实现ACID特性(原子性、一致性、隔离性、持久性)。
-
提供事务的提交、回滚和隔离级别控制。
-
-
并发控制:
-
处理多用户并发访问(如锁机制、MVCC多版本并发控制)。
-
避免数据竞争和一致性问题。
-
-
故障恢复:
-
通过日志(如Redo Log、Undo Log)实现崩溃恢复。
-
保证数据的持久性和一致性。
-
二、存储引擎的分类
根据设计目标和适用场景,存储引擎可以分为以下几类:
1. 按存储格式
-
行式存储引擎:
-
特点:将整行数据存储在一起,适合OLTP(在线事务处理)。
-
代表:MySQL InnoDB、PostgreSQL。
-
-
列式存储引擎:
-
特点:将每列数据存储在一起,适合OLAP(在线分析处理)。
-
代表:ClickHouse、Apache Parquet。
-
2. 按索引结构
-
B+Tree引擎:
-
特点:支持高效的范围查询和点查询,适合读多写少场景。
-
代表:MySQL InnoDB。
-
-
LSM-Tree引擎:
-
特点:写优化,适合写多读少场景。
-
代表:RocksDB、Cassandra。
-
3. 按数据位置
-
磁盘存储引擎:
-
特点:数据持久化到磁盘,适合大规模数据存储。
-
代表:MySQL InnoDB、RocksDB。
-
-
内存存储引擎:
-
特点:数据存储在内存中,适合高性能缓存和实时计算。
-
代表:Redis、MemSQL。
-
三、常见存储引擎对比
以下是几种常见存储引擎的对比:
| 存储引擎 | 代表数据库 | 索引结构 | 事务支持 | 适用场景 | 特点 |
|---|---|---|---|---|---|
| InnoDB | MySQL | B+Tree | 支持 | OLTP | 支持ACID,行级锁,MVCC |
| MyISAM | MySQL | B+Tree | 不支持 | 读密集型 | 表级锁,不支持事务 |
| RocksDB | MySQL (MyRocks) | LSM-Tree | 支持 | 写密集型 | 高写入吞吐,压缩率高 |
| LevelDB | LSM-Tree | 不支持 | 嵌入式存储 | 简单高效,适合小规模数据 | |
| TokuDB | MySQL | Fractal Tree | 支持 | 大数据量 | 高压缩比,适合归档数据 |
| Aria | MariaDB | B+Tree | 支持 | 轻量级OLTP | 支持崩溃恢复,适合小型应用 |
四、存储引擎的工作原理
1. 数据存储
-
页结构:
-
数据按页(Page)存储,通常大小为16KB。
-
页中包含页头、行数据、页尾等信息。
-
-
文件组织:
-
数据文件(如InnoDB的.ibd文件)由多个页组成。
-
索引文件和数据文件可能分离或合并。
-
2. 索引结构
-
B+Tree:
-
非叶子节点存储键值,叶子节点存储数据。
-
支持高效的范围查询和点查询。
-
-
LSM-Tree:
-
数据先写入内存(MemTable),再刷入磁盘(SSTable)。
-
通过Compaction合并磁盘文件。
-
3. 事务与并发
-
Redo Log:
-
记录事务的物理修改,用于崩溃恢复。
-
-
Undo Log:
-
记录事务的逻辑修改,用于回滚和MVCC。
-
-
MVCC:
-
多版本并发控制,通过版本链实现非阻塞读。
-
五、存储引擎的选择
-
OLTP场景:
-
需要高并发、强一致性。
-
推荐:InnoDB、PostgreSQL。
-
-
OLAP场景:
-
需要高性能分析查询。
-
推荐:ClickHouse、Apache Parquet。
-
-
写密集型场景:
-
需要高写入吞吐。
-
推荐:RocksDB、Cassandra。
-
-
缓存场景:
-
需要低延迟访问。
-
推荐:Redis、Memcached。
-
如何使用数据库的存储引擎
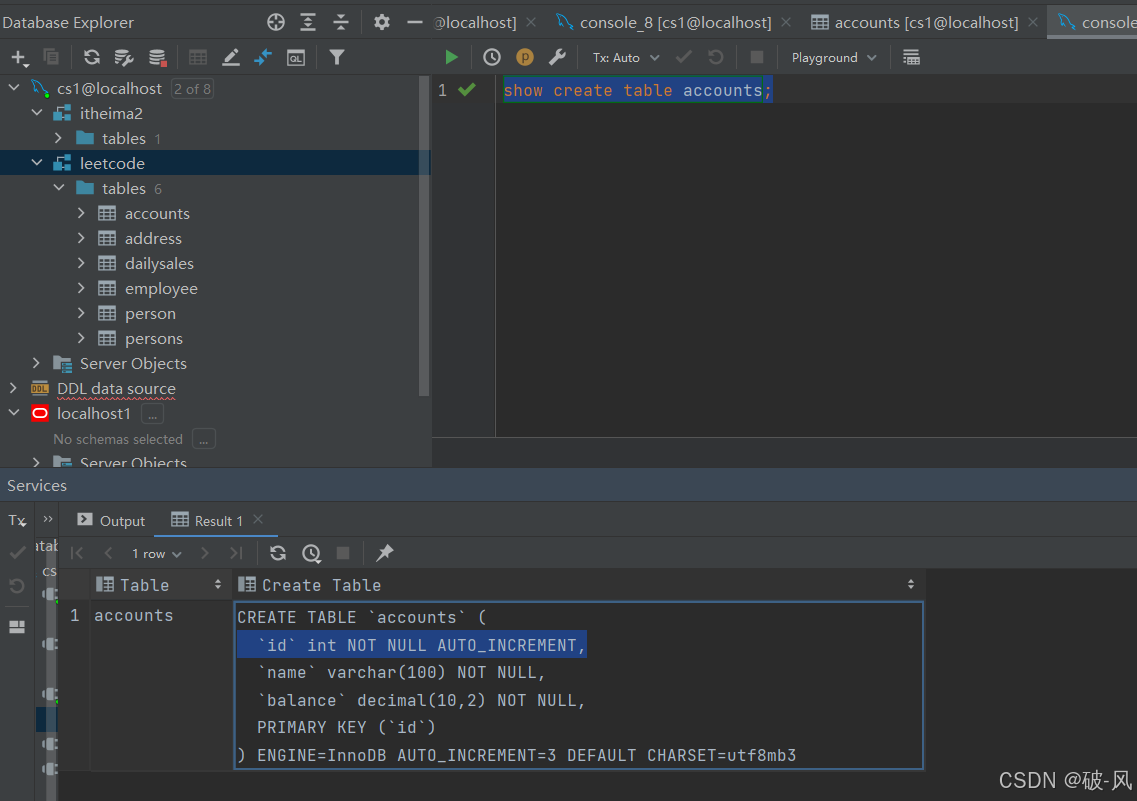
如何查看数据库的存储引擎
show engines建表时指定存储引擎
create table 表名{
字段1 字段1类型 [comment 字段1注释]
...
字段2 字段2类型 [comment 字段2注释]
}engine = innodb[comment 表注释]数据库(以mysql为例),我查询建表语句(会默认存储引擎)一般默认为InnoDB
存储引擎的选择
InnoDB: 是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要
求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操
作,那么InnoDB存储引擎是比较合适的选择。
MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完
整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是
对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。