大模型深度学习之双塔模型
前言
双塔模型(Two-Tower Model)是一种在推荐系统、信息检索和自然语言处理等领域广泛应用的深度学习架构。其核心思想是通过两个独立的神经网络(用户塔和物品塔)分别处理用户和物品的特征,并在共享的语义空间中通过相似度计算实现匹配或召回任务。本文从该模型的各个维度开始,对模型做通俗易懂的说明。让您轻松理解这一在推荐系统、信息检索和自然语言处理等领域广泛应用的深度在这里插入图片描述
学习架构。
一、双塔模型初印象:就像搭积木
想象一下,您正在玩搭积木的游戏。您有两堆不同颜色的积木,一堆代表用户,另一堆代表物品(比如商品、新闻、音乐等)。您的目标是根据用户的喜好,从物品堆中找出最合适的积木搭配。
双塔模型就像是一个智能的积木搭配助手。它有两个独立的“塔”,一个专门处理用户积木,另一个专门处理物品积木。每个塔都会把自己的积木“翻译”成一种神秘的语言(向量),然后看看这两种语言能不能对上话(相似度计算),从而找出最匹配的积木组合。
二、双塔模型的基本原理:
分而治之,再求同
特征分治:各扫门前雪
在双塔模型中,用户和物品的特征是分开处理的。这就像您和朋友分别整理自己的玩具,您整理您的积木,朋友整理朋友的积木,互不干扰。
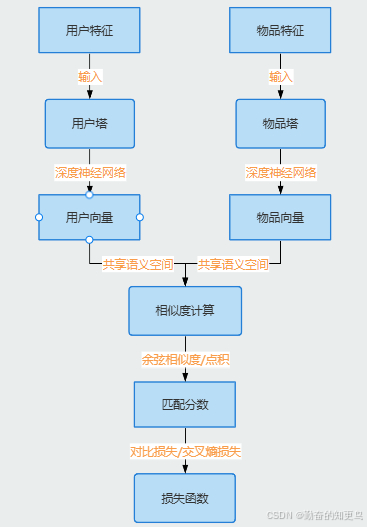
用户塔:
负责处理用户相关的特征。比如,在电商推荐系统中,用户塔可能会考虑您的购买历史、浏览记录、年龄、性别等信息。这些信息就像您的“用户画像”,帮助模型了解您的喜好。
物品塔:
负责处理物品相关的特征。继续用电商的例子,物品塔可能会考虑商品的价格、品牌、类别、描述等信息。这些信息就像商品的“身份证”,帮助模型了解商品的特点。
向量化映射:万物皆可向量
用户塔和物品塔处理完特征后,会把这些信息转换成一种特殊的格式——向量。向量就像是一串神秘的密码,能够代表用户或物品的特征。
用户向量:
用户塔输出的向量,代表了用户的兴趣和需求。比如,如果您经常购买科技产品,您的用户向量可能包含很多与科技相关的“密码”。
物品向量:
物品塔输出的向量,代表了物品的特点和属性。比如,一部新发布的科技产品的物品向量,可能包含与最新技术、创新设计相关的“密码”。
相似度计算:对上暗号就匹配
有了用户向量和物品向量,双塔模型就可以进行相似度计算了。这就像您和朋友用暗号交流,如果暗号对得上,就说明你们心有灵犀。
余弦相似度:
一种常用的相似度计算方法,就像计算两个向量的夹角。夹角越小,说明两个向量越相似,用户和物品的匹配度就越高。
点积或内积:
另一种常用的相似度计算方法,就像计算两个向量的“点积”。点积越大,说明两个向量越相似,用户和物品的匹配度就越高。
损失函数:让模型越学越聪明
为了让双塔模型更好地工作,我们需要一个“老师”来指导它学习。这个“老师”就是损失函数。
对比损失:一种常用的损失函数,它的目标是让正样本(用户喜欢的物品)的匹配分数高,负样本(用户不喜欢的物品)的匹配分数低。就像您考试时,老师希望您做对的题目得分高,做错的题目得分低。
交叉熵损失:另一种常用的损失函数,常用于分类任务。在双塔模型中,它可以用来优化用户和物品的匹配概率,让模型更准确地预测用户是否喜欢某个物品。
三、双塔模型的应用场景:无处不在的智能助手
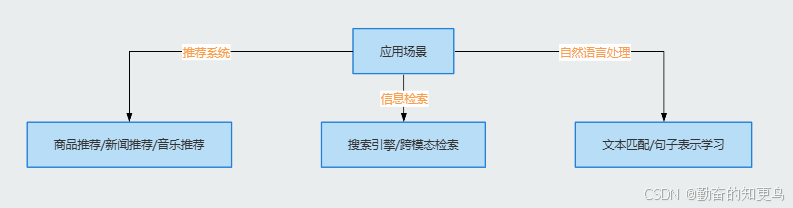
双塔模型就像是一个万能的智能助手,广泛应用于推荐系统、信息检索和自然语言处理等领域。
推荐系统:
猜您喜欢
商品推荐:
在电商平台上,双塔模型可以根据您的购买历史和浏览记录,推荐您可能感兴趣的商品。就像您走进一家超市,超市的导购员根据您的购物篮里的商品,推荐您可能还需要的其他商品。
新闻推荐:
在新闻客户端上,双塔模型可以根据您的阅读历史和兴趣偏好,推荐您可能感兴趣的新闻。就像您订阅了一份报纸,报纸的编辑根据您的阅读习惯,为您精选每日头条。
音乐推荐:
在音乐平台上,双塔模型可以根据您的听歌历史和音乐偏好,推荐您可能喜欢的歌曲。就像您走进一家咖啡馆,咖啡馆的驻唱歌手根据您的音乐品味,为您演唱专属曲目。
广告推荐:
在网页或应用上,双塔模型可以根据您的浏览行为和兴趣偏好,展示您可能感兴趣的广告。就像您走在街上,街边的广告牌根据您的目光停留,展示您可能需要的商品或服务。
信息检索:
找您所需
搜索引擎:
在搜索引擎中,双塔模型可以将您的查询和网页内容映射到同一语义空间,计算它们的语义相关性,返回最相关的检索结果。就像您问图书馆管理员一本书的位置,管理员根据您的描述,快速找到您需要的书籍。
跨模态检索:
双塔模型还可以实现跨模态检索,比如图像和文本之间的检索。就像您有一张图片,想找到与这张图片相关的文章或视频,双塔模型可以帮您实现这一需求。
自然语言处理:
理解语言之美
文本匹配:
在自然语言处理中,双塔模型可以用来判断两个文本的语义相似度。比如,在问答系统中,双塔模型可以计算用户的问题和答案库中的答案的相似度,返回最匹配的答案。
句子表示学习:
双塔模型还可以用来生成具有语义意义的句子向量。这些句子向量可以用于文本分类、聚类等任务,帮助计算机更好地理解和处理自然语言。
四、双塔模型的优缺点:权衡的艺术
双塔模型虽然强大,但也有其优缺点。就像一把双刃剑,既能披荆斩棘,也可能伤及自身。
优点:
高效、灵活、易部署
高效性:
双塔模型的一个显著优点是高效性。物品向量可以离线预计算并存储,线上仅需实时计算用户向量,大大减少了计算量,适合大规模推荐场景。就像超市的导购员提前准备好商品推荐列表,您一进门就能快速得到推荐。
灵活性:
双塔模型的用户塔和物品塔可以独立更新和优化,支持新用户和新物品的冷启动。就像超市的导购员可以根据新的销售数据,随时调整推荐策略。
易部署:
双塔模型的相似度计算简单(如点积),线上服务延迟低,易于部署和扩展。就像超市的导购员可以轻松应对大量顾客的咨询,不会因为顾客太多而手忙脚乱。
缺点:
特征交叉不足、负采样偏差、时效性问题
特征交叉不足:
双塔模型的一个主要缺点是特征交叉不足。用户和物品特征仅在顶层进行相似度计算,细粒度特征可能丢失,影响模型表达能力。就像超市的导购员只根据您的购物篮里的商品推荐商品,可能忽略了您的其他需求和偏好。
负采样偏差:
负样本的选择直接影响模型效果,随机或Batch内采样可能导致热门物品被过度打压。就像超市的导购员在推荐商品时,如果只推荐冷门商品,可能忽略了热门商品的需求。
时效性问题:
离线计算的物品向量可能存在时效性问题,对新用户或新物品不友好。就像超市的导购员如果长时间不更新推荐列表,可能无法及时反映最新的商品信息和顾客需求。
五、双塔模型的优化方向:让模型更聪明、更强大
为了克服双塔模型的缺点,研究人员提出了许多优化方向,让模型更聪明、更强大。
- 减少特征信息损失:让特征更充分地交互
引入交叉网络:
在双塔模型中引入交叉网络(如FM、DCN),可以增强特征之间的交互,减少特征信息损失。就像超市的导购员不仅根据您的购物篮里的商品推荐商品,还考虑您的年龄、性别等信息,提供更个性化的推荐。
使用注意力机制:
在双塔模型中使用注意力机制(如SENet),可以让模型更关注重要的特征,提高特征利用率。就像超市的导购员在推荐商品时,更关注您经常购买的商品类别,提供更精准的推荐。
多任务学习:
使用多任务学习,同时优化多个相关任务,可以提高特征利用率,增强模型的泛化能力。就像超市的导购员不仅推荐商品,还提供商品比较、优惠信息等服务,满足您的多样化需求。
- 蒸馏学习:让模型向大师学习
以精排模型为教师:蒸馏学习是一种有效的模型优化方法,它以精排模型为教师,指导双塔模型学习。通过知识蒸馏的方式,双塔模型可以弥补特征和结构上的不足,提高推荐效果。就像超市的导购员向经验丰富的老员工学习,提高自己的推荐技巧。
- 引入交叉信息或特征:让模型更懂用户
对偶增强双塔:通过互蒸馏学习用户和物品的交叉信息,对偶增强双塔模型可以提高推荐效果。就像超市的导购员不仅了解您的购物习惯,还了解商品的库存和销售情况,提供更全面的推荐。
阿里COLD模型:阿里COLD模型结合特征筛选和线上性能优化,提升细粒度交互效果。就像超市的导购员根据商品的销量和顾客的评价,筛选出最受欢迎的商品进行推荐。
- 负采样策略优化:让负样本更合理
结合Hard负例挖掘和流行度加权:优化负采样策略,结合Hard负例挖掘和流行度加权,可以提高负样本的质量和多样性,提升模型效果。就像超市的导购员在推荐商品时,不仅推荐热门商品,还推荐一些冷门但优质的商品,满足您的多样化需求。
使用动态负采样策略:根据模型训练情况调整负样本的选择,可以使模型更适应不同的训练阶段,提高推荐效果。就像超市的导购员根据销售数据和顾客反馈,随时调整推荐策略,提高顾客满意度。
六、总结与展望:双塔模型的未来之路
双塔模型以其高效性和灵活性,在推荐系统和信息检索等领域发挥了重要作用。尽管存在特征交叉不足等局限,但通过结构改进和训练策略优化,其性能仍可显著提升。
未来,双塔模型可能会与交互式模型结合,在效果与效率间寻求更优平衡。同时,随着深度学习技术的不断发展,双塔模型的应用场景也将更加广泛,为我们的生活带来更多便利和惊喜。
希望这篇讲解能够帮助您更好地理解双塔模型的工作原理和应用。如果您有任何问题或建议,欢迎随时与我交流。