MMdetection推理保存图片和预测标签脚本
引言
MMdetection作为一款集中了多种目标检测方法的框架,是研究2D视觉科研人员必备的框架,然而,自带的mmdet.visualization打印图片会使图片变质,这里提供一个自动推理保存图片的脚本,同时支持多种格式标签的保存。
代码实现
import os
from mmdet.apis import init_detector, inference_detector
import torch
import cv2# -------------------在使用前请指定以下参数-------------------------
# 1.输出文件夹,新建并将结果输出到该文件夹下
output_dir = 'result' # 修改变量名避免冲突
# 2.待检测图片文件夹
image_dir = 'Dataset_depth_COCO/val'
# 3.模型配置文件路径,py格式
config_file = '/home/hary/ctc/mmdetection/work_dirs/freeanchor_r50_fpn_1x_coco/freeanchor_r50_fpn_1x_coco.py'
# 4.模型权重文件路径,pth格式
checkpoint_file = 'work_dirs/freeanchor_r50_fpn_1x_coco/epoch_50.pth'
# 5.置信度阈值,0-1之间的数值,MMdetection是给出100个预测,包含大量无效预测,需要过滤
confidence_threshold = 0.3
# 6.save_mod标签保存格式,可选参数:None, xywh, xyxy, YOLO, COCO
save_mod = 'YOLO'
# 7.指定标签名称
class_names = ['shallow_box_rgb', 'shallow_half_box_rgb'] # 数据集类别,注意和colors长度一致
# 8.标签颜色数组
colors = {0: (0, 0, 255), # 红色(BGR格式)1: (255, 0, 0) # 蓝色(BGR格式)
}
# -----------------------指定参数完毕-----------------------------# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)# 创建子目录存放标注后的标签
if save_mod:label_dir = os.path.join(output_dir, 'predicted_label')os.makedirs(label_dir, exist_ok=True)# 初始化模型
model = init_detector(config_file, checkpoint_file, device='cuda' if torch.cuda.is_available() else 'cpu')# 支持的图像扩展名
valid_extensions = ['.jpg', '.jpeg', '.png', '.bmp']# 遍历图片文件夹
image_files = [f for f in os.listdir(image_dir) if os.path.splitext(f)[1].lower() in valid_extensions]for i, filename in enumerate(image_files):img_path = os.path.join(image_dir, filename)# 获取模型推理的结果result = inference_detector(model, img_path)print(f"({i + 1}/{len(image_files)}) {filename} has detected!")# 过滤置信度大于阈值的结果if hasattr(result, 'pred_instances'):valid_idx = result.pred_instances.scores > confidence_threshold filtered_bboxes = result.pred_instances.bboxes[valid_idx] # 模型推理的检测框:[x_min, y_min, x_max, y_max]filtered_scores = result.pred_instances.scores[valid_idx] # 置信度filtered_labels = result.pred_instances.labels[valid_idx] # 模型推理类别else:# 兼容旧版本mmdet的输出格式filtered_bboxes = []filtered_scores = []filtered_labels = []for class_id, class_result in enumerate(result):if len(class_result) > 0:for bbox in class_result:if bbox[4] > confidence_threshold:filtered_bboxes.append(bbox[:4])filtered_scores.append(bbox[4])filtered_labels.append(class_id)filtered_bboxes = torch.tensor(filtered_bboxes)filtered_scores = torch.tensor(filtered_scores)filtered_labels = torch.tensor(filtered_labels)img = cv2.imread(img_path)if img is None:print(f"Warning: Could not read image {img_path}, skipping")continue# 绘制每个检测框for bbox, score, label in zip(filtered_bboxes, filtered_scores, filtered_labels):# 转换为整数坐标x1, y1, x2, y2 = map(int, bbox[:4])class_id = int(label)# 获取颜色和标签color = colors.get(class_id, (0, 255, 0)) # 默认绿色label_name = class_names[class_id] if class_id < len(class_names) else f"class_{class_id}"# 绘制矩形框cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)# 构建显示文本 (类别 + 置信度)text = f"{label_name}: {score:.2f}"# 计算文本位置 (避免超出图像顶部)y_text = y1 - 10 if y1 - 10 > 10 else y1 + 20cv2.putText(img, text, (x1, y_text),cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2)# 保存结果output_path = os.path.join(output_dir, filename)cv2.imwrite(output_path, img)print(f"Saved result to: {output_path}")# 处理标签if not save_mod:continueelse:# 准备输出标签路径img_name = os.path.splitext(filename)[0] # 得到 "1112_14-rgb"txt_name = f"{img_name}.txt" # 得到 "1112_14-rgb.txt"label_path = os.path.join(label_dir, txt_name)# 升维,方便后续张量拼接filtered_labels = filtered_labels.unsqueeze(1)filtered_scores = filtered_scores.unsqueeze(1)# 获取图片高宽img_h, img_w = img.shape[:2]if save_mod == 'xyxy': # [x_min, y_min, x_max, y_max]predict_label = torch.cat([filtered_labels, filtered_bboxes, filtered_scores], dim=1)with open(label_path, 'w') as f:for row in predict_label:# 第一列转整数,后续列保留4位小数formatted_row = [f"{int(row[0])}"] + [f"{x:.6f}" for x in row[1:]]f.write(" ".join(formatted_row) + "\n")elif save_mod == 'COCO': # [x_min, y_min, width, height]filtered_bboxes[:, 2] = filtered_bboxes[:, 2] - filtered_bboxes[:, 0]filtered_bboxes[:, 3] = filtered_bboxes[:, 3] - filtered_bboxes[:, 1]predict_label = torch.cat([filtered_labels, filtered_bboxes, filtered_scores], dim=1)with open(label_path, 'w') as f:for row in predict_label:# 第一列转整数,后续列保留4位小数formatted_row = [f"{int(row[0])}"] + [f"{x:.6f}" for x in row[1:]]f.write(" ".join(formatted_row) + "\n")elif save_mod == 'xywh': # [x_center, y_center, width, height]filtered_bboxes[:, 2] = filtered_bboxes[:, 2] - filtered_bboxes[:, 0]filtered_bboxes[:, 3] = filtered_bboxes[:, 3] - filtered_bboxes[:, 1]filtered_bboxes[:, 0] = filtered_bboxes[:, 0] + filtered_bboxes[:, 2] / 2filtered_bboxes[:, 1] = filtered_bboxes[:, 1] + filtered_bboxes[:, 3] / 2predict_label = torch.cat([filtered_labels, filtered_bboxes, filtered_scores], dim=1)with open(label_path, 'w') as f:for row in predict_label:# 第一列转整数,后续列保留4位小数formatted_row = [f"{int(row[0])}"] + [f"{x:.6f}" for x in row[1:]]f.write(" ".join(formatted_row) + "\n")elif save_mod == 'YOLO': # [x_center, y_center, width, height],并归一化filtered_bboxes[:, 2] = filtered_bboxes[:, 2] - filtered_bboxes[:, 0]filtered_bboxes[:, 3] = filtered_bboxes[:, 3] - filtered_bboxes[:, 1]# 再转换为[x_yolo, y_yolo, w, h]filtered_bboxes[:, 0] = filtered_bboxes[:, 0] + filtered_bboxes[:, 2] / 2filtered_bboxes[:, 1] = filtered_bboxes[:, 1] + filtered_bboxes[:, 3] / 2filtered_bboxes[:, 0] = filtered_bboxes[:, 0] / img_wfiltered_bboxes[:, 2] = filtered_bboxes[:, 2] / img_wfiltered_bboxes[:, 1] = filtered_bboxes[:, 1] / img_hfiltered_bboxes[:, 3] = filtered_bboxes[:, 3] / img_hpredict_label = torch.cat([filtered_labels, filtered_bboxes, filtered_scores], dim=1)with open(label_path, 'w') as f:for row in predict_label:# 第一列转整数,后续列保留4位小数formatted_row = [f"{int(row[0])}"] + [f"{x:.6f}" for x in row[1:]]f.write(" ".join(formatted_row) + "\n")else:print("The save_mod parameter is illegal!")break结果展示
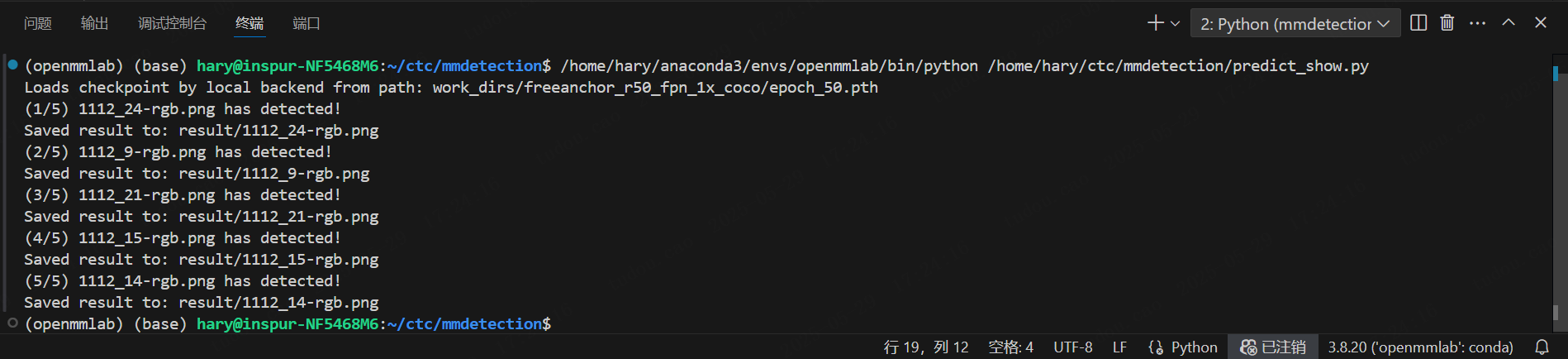
运行界面:
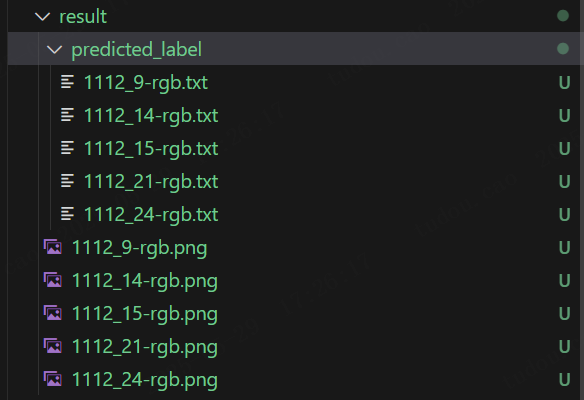
保存结果:
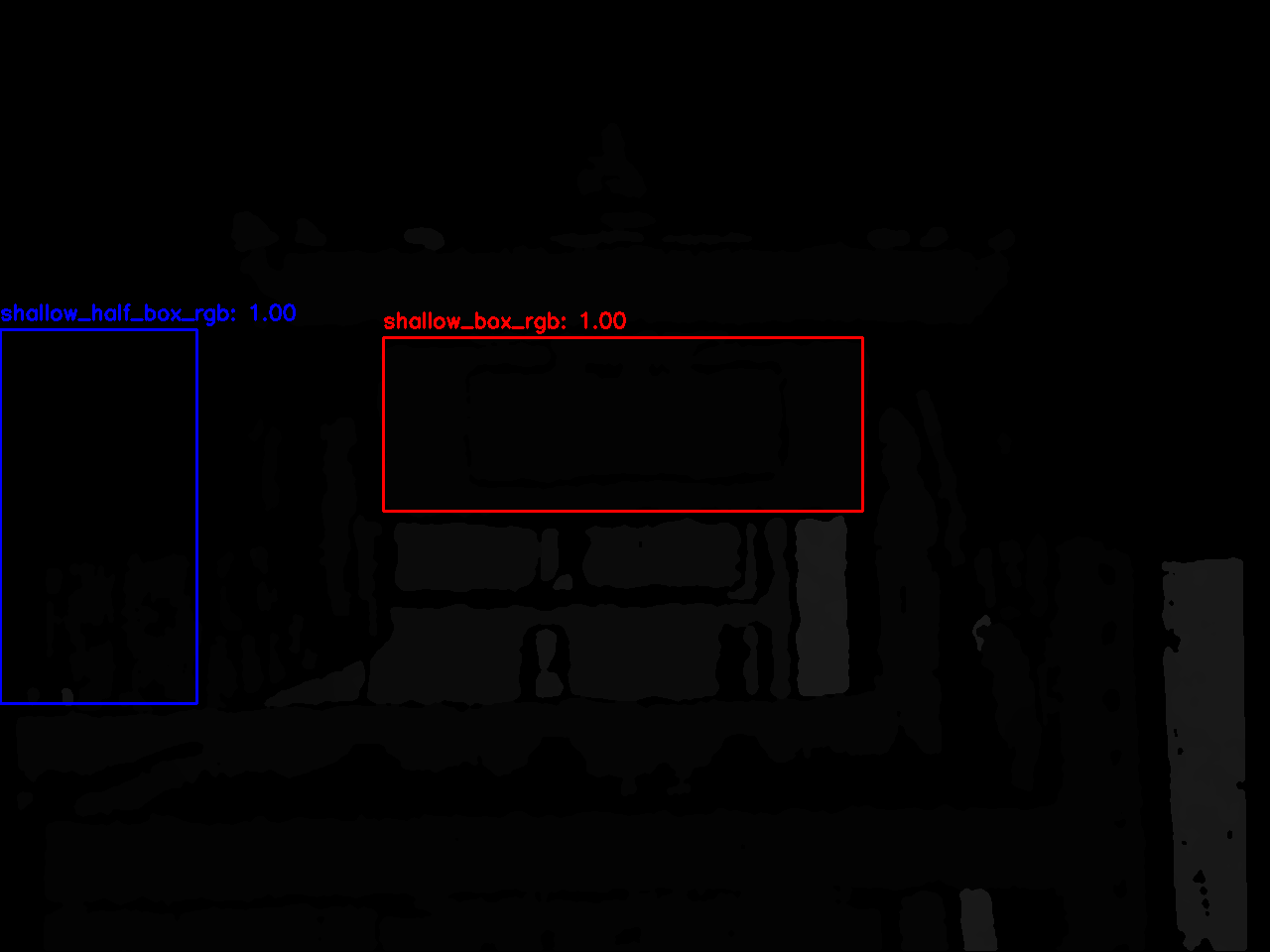
图片展示: