docker网络相关内容详解
一、docker与k8s
一、Docker 核心解析
1. Docker 定义与架构
本质:
- 容器化平台(构建容器化应用)、进程管理软件(守护进程管理容器生命周期)。
- 客户端(
docker cli)与服务端(docker server)通过 Unix 套接字通信,本机客户端可直接管理容器。核心功能:
- 应用打包:镜像(Image)包含应用 + 依赖,解决 环境一致性(“一次构建,处处运行”)。
- 进程隔离:通过 Namespace(网络、PID 等)和 Cgroups(资源限制)实现容器级隔离,确保进程(容器)间互不干扰。
- Swarm 集群:
- 多节点部署(
swarm init/join)、服务伸缩(docker service scale)、负载均衡(Ingress 网络)。- 配置与密钥管理(
configs/secrets),支持集群化部署与安全管控。技术边界:
- 单进程原则:容器内 仅运行一个主进程(如 Web 服务),复杂场景需 Sidecar 容器(如日志代理)辅助。
- 非 GUI 环境:不支持容器内运行带 GUI 的开发环境(如 IDE),专注于运行时(Runtime)管理。
2. Docker Swarm 与 K8s 的对比(为何需要 K8s)
特性 Docker Swarm K8s(Kubernetes) 生态兼容性 仅支持 Docker 容器(原生生态) 兼容所有 CRI 运行时(如 containerd、CRI-O) 复杂度与规模 轻量,适合小规模集群 复杂,支持大规模高可用场景(多租户、跨云) 资源类型 少(无 CSI 存储扩展) 丰富(CRD 扩展,支持 GPU、存储类等) 配置管理 手动维护部署指令(无自动同步) 声明式配置(YAML + etcd 自动同步状态) 多租户支持 弱(无命名空间隔离) 强(命名空间 + 资源配额精细管控) 扩展性 扩展能力有限(依赖 Docker 生态) 高度可扩展(CRD、Operator 模式,自定义资源) 总结:
- Swarm 适合 Docker 生态内的简单集群(如小规模微服务),但缺乏标准化扩展(如 CSI 存储)。
- K8s 通过 CRI/CSI 标准化 和 CRD 扩展性,成为 云原生时代的主流编排平台(支持复杂多集群、混合云场景)。
二、K8s(Kubernetes)核心解析(基于图片内容)
1. 定义与架构
本质:
分布式容器编排与服务管理平台,不负责容器化(依赖 Docker 等 CRI 运行时),专注 容器生命周期管理(部署、伸缩、故障恢复)。核心组件:
- Master 节点:
- 调度器(Scheduler):分配 Pod 到 Worker 节点。
- API Server:集群控制入口(接收 REST 请求,管理资源状态)。
- etcd:分布式键值存储,持久化集群状态(如 Pod 期望副本数)。
- Worker 节点:
- Kubelet:管理节点上的容器(与 API Server 交互,确保 Pod 状态)。
- Kube-proxy:网络代理(实现 Service 负载均衡,维护 Pod 网络连接)。
核心功能:
- 弹性部署:
- 无状态服务(Deployment,滚动更新)、有状态服务(StatefulSet,有序部署)。
- HPA(水平自动伸缩):根据 CPU / 内存使用率动态调整 Pod 副本数。
- 服务治理:
- Service:将 Pod 暴露为网络服务(ClusterIP 内部访问,NodePort 外部访问)。
- Ingress:七层负载均衡(HTTP 流量路由,支持 TLS 终止、路径匹配)。
- 故障与资源管理:
- 自愈能力:Pod 崩溃自动重启,节点故障时 Pod 迁移到其他节点。
- 资源配额(ResourceQuota):限制命名空间内的 CPU / 内存使用,避免资源争抢。
- Sidecar 模式:
Pod 内多容器协同(如主应用 + 日志采集器),实现 非侵入式扩展(无需修改主应用代码)。技术边界:
- 无镜像构建:仅管理已构建的镜像,需 CI/CD 工具(如 Jenkins)配合生成镜像。
- 非应用级隔离:不支持应用程序级别的内部服务隔离(如 MySQL 与 Kafka 中间件的资源隔离需通过 Namespace 或标签)。
2. K8s 重要概念
Pod:
最小调度单元,包含 共享网络(同一 Pod 内容器可通过 localhost 通信)和存储 的容器组。每个 Pod 含一个 Pause 容器(维持网络命名空间)和业务容器(如 Web 服务 + Sidecar 代理)。控制器(Controller):
- Deployment:管理无状态服务(滚动更新、回滚),确保 Pod 副本数符合期望(
replicas: 3)。- StatefulSet:管理有状态服务(如数据库),保证 Pod 唯一标识(
pod-name-0, pod-name-1)和有序部署。- DaemonSet:每个节点运行一个 Pod(如监控 Agent、日志收集器)。
Label 与 Selector:
- Label:键值对(如
app=web, env=prod),用于分组资源(Pod、Node)。- Selector:通过 Label 筛选资源(如
kubectl get pods -l app=web筛选 Web 服务 Pod),实现灵活的服务发现与调度。3. K8s 扩展场景
网络扩展(CNI):
如 Calico(基于 BGP 的网络策略,支持 Pod 间访问控制)、Flannel(Overlay 网络,跨节点通信),通过 CNI 插件 实现自定义网络拓扑。存储扩展(CSI):
如 NFS(共享存储)、Ceph(分布式存储),通过 CSI 插件 提供持久化存储,支持 StorageClass 动态分配卷(如volumeClaimTemplates定义 PVC)。API 扩展(CRD/API Server):
- CRD(自定义资源定义):扩展 K8s API(如定义
CustomApp资源),适合内部工具(字段少、无需外部存储)。- API Server 扩展:资源需存储在外部(非 etcd)或需独立 API 服务时,通过自定义 API Server 实现(如集成第三方服务管理)。
三、Docker 与 K8s 的协同关系(总结)
Docker 角色:
负责 容器化(镜像构建、运行时隔离),是 K8s 的 运行时基础(通过 CRI 接口与 K8s 集成,提供容器运行能力)。K8s 角色:
负责 集群级编排(部署、伸缩、治理),构建 云原生应用的运行时平台,通过声明式配置(YAML)和自动化控制器(如 Deployment),实现 弹性、高可用、可扩展 的应用部署。典型流水线:
开发(Dockerfile 构建镜像) → 测试(Docker Compose 本地编排) → 部署(K8s 集群,通过 Helm 管理应用) → 运维(K8s 控制器自动修复故障,HPA 伸缩服务)。四、技术边界与实践建议
Docker 实践:
- 本地开发用 Docker Compose 定义多容器依赖(如 Web + 数据库),简化环境搭建。
- 生产环境通过 Docker Swarm 或 K8s 实现集群化,根据规模选择(小规模用 Swarm,大规模用 K8s)。
K8s 实践:
- 基础部署:掌握 Pod、Service、Deployment 定义,通过
kubectl管理资源。- 进阶扩展:学习 CRD、Operator 模式,实现自定义资源管理(如数据库备份自动化)。
- 生态集成:结合 Prometheus(监控)、Jaeger(链路追踪)、ArgoCD(持续部署),构建完整云原生栈。
二、docker网络
1. 素材准备
1. dockerfile 定义
From alpine:3.18run apk add ethtoolrun apk add ipvsadmrun apk add iptables2. 镜像构建
docker build -t myalpine .2. 网络解决什么问题
1. 容器与外界通信
2. 容器间通讯,跨主机容器间通讯
3. 网络隔离(容器网络命名空间、子网隔离)
4. 提供网络自定义能力
5. 提供容器间发现功能
6. 提供负载均衡能力
3. docker网络命令
一、Docker 网络核心命令
命令格式 描述说明 docker network connect将容器连接到指定网络 docker network create创建新的 Docker 网络 docker network disconnect将容器从网络中断开 docker network inspect查看网络的详细配置信息 docker network ls列出所有已创建的网络 docker network prune移除所有未被使用的闲置网络 docker network rm移除指定的一个或多个网络 二、端口发布与映射操作
1. 端口发布语法
# 基础格式:-p [主机地址:][主机端口]:容器端口[协议]# 案例1:将容器TCP端口80映射到主机8080端口 -p 8080:80# 案例2:将容器TCP端口80映射到指定IP的8080端口 -p 192.168.239.154:8080:80# 案例3:将容器UDP端口80映射到主机8080端口 -p 8080:80/udp# 案例4:同时映射TCP和UDP端口 -p 8080:80/tcp -p 8080:80/udp2. 实战案例:发布 Nginx 服务端口
# 运行Nginx容器并映射8080端口 docker run -d --rm --name mynginx -p 8080:80 nginx:1.23.4# 验证访问(本地或远程主机) curl http://localhost:8080 # 输出:Nginx默认欢迎页面内容三、容器 Hostname 修改配置
1. --hostname 选项修改容器主机名
# 运行容器时指定hostname(影响容器内/etc/hosts) docker run -d --rm --name mynginx1 -p 8081:80 --hostname mynginx1.0voice.com nginx:1.23.4# 验证访问 curl http://localhost:8081# 查看容器内hostname docker exec mynginx1 hostname # 输出:mynginx1.0voice.com2. 查看容器 hosts 文件配置
# 查看容器内/etc/hosts映射 docker exec mynginx1 cat /etc/hosts # 输出示例: # 127.0.0.1 localhost # ... # 172.17.0.2 mynginx1.0voice.com mynginx13. 容器内交互验证 hostname
# 进入容器交互环境 docker exec -it mynginx1 bash# 在容器内验证hostname hostname # 输出:mynginx1.0voice.com# 退出容器 exit
4. 网络驱动
一、网桥(Bridge)基础概念
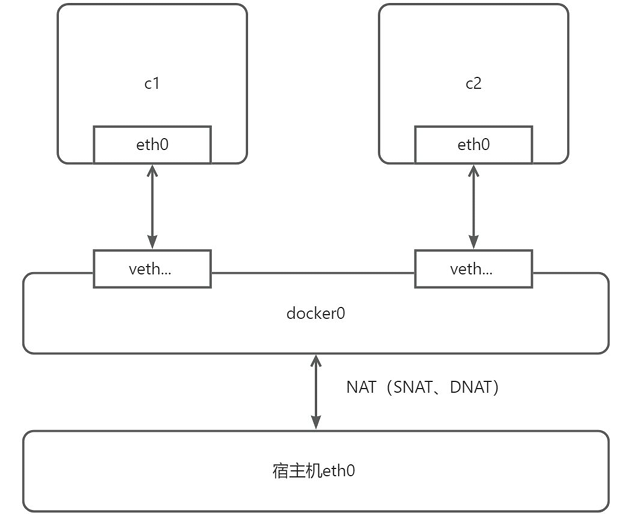
网桥(Bridge)是 Docker 默认的网络驱动程序。当未显式指定网络驱动时,所有新创建的网络均为网桥类型。其核心作用是在同一台主机的容器之间建立通信链路,同时隔离不同网桥网络的容器。
1. 网桥的本质
- 链路层设备:网桥工作在 OSI 模型的链路层(二层),基于 MAC 地址转发流量,实现网段间的通信。
- 软件网桥:Docker 中的网桥是运行在宿主机内核的软件设备(如默认的
docker0网桥),负责管理容器间的网络连接与隔离。2. Docker 网桥的核心特性
- 容器通信:同一网桥下的容器可直接通信(无需显式端口映射);不同网桥的容器无法直接通信。
- 默认网桥:安装 Docker 后,会自动创建名为
docker0的默认网桥,新启动的容器默认连接至此网络(除非显式指定其他网络)。3. 虚拟网卡对(veth pair)
每个容器启动时,Docker 会为其创建一对虚拟网卡(veth pair):
- 一端(如
veth-xxxx)连接到虚拟网桥docker0;- 另一端(如
eth0)作为容器的 “内网网卡”,分配容器的 IP 地址(默认子网为172.17.0.0/16,可通过docker network inspect bridge查看)。4. 容器 IP 与子网
默认网桥
bridge(对应虚拟网桥docker0)会为容器分配一个私有 IP(如172.17.0.2、172.17.0.3等),所有容器共享同一子网(如172.17.0.0/16),形成一个局域网。
二、用户自定义网桥 vs 默认网桥
Docker 支持两种网桥类型:默认网桥(
docker0)和用户自定义网桥(通过docker network create创建)。二者的核心区别如下:
特性 默认网桥(docker0) 用户自定义网桥 DNS 解析 仅支持 IP 地址访问,不支持容器名 / 别名 自动支持容器名 / 别名的 DNS 解析(通过 Docker 内置 DNS) 网络隔离 所有未指定网络的容器默认连接至此,隔离性差 需显式指定容器加入,隔离性更可控 配置灵活性 配置(如子网、IP 范围)需手动修改 Docker 配置文件,且需重启 Docker 可通过 docker network create命令灵活配置(子网、网关、IP 范围等)容器间连接(ICC) 默认启用(容器间可直接通信) 可通过选项 com.docker.network.bridge.enable_icc控制是否启用IP 伪装(NAT) 默认启用(容器可访问外网) 可通过选项 com.docker.network.bridge.enable_ip_masquerade控制是否启用
三、网桥驱动的配置选项
使用
docker network create --driver bridge创建网桥时,可通过--opt参数传递以下特定选项,精细控制网桥行为:
选项名称 默认值 描述 com.docker.network.bridge.namedocker0(默认网桥)自定义网桥的 Linux 接口名称(如 alpine-net1)。com.docker.network.bridge.enable_ip_masqueradetrue是否启用 IP 伪装(NAT):若启用,容器可通过宿主机 IP 访问外网;禁用则容器无法访问外网。 com.docker.network.bridge.enable_icctrue是否启用容器间连接(ICC):启用时同一网桥的容器可直接通信;禁用则容器间无法通信(但仍可通过端口映射访问)。 com.docker.network.bridge.host_binding_ipv40.0.0.0容器端口映射时的默认绑定 IP(如 192.168.1.10)。com.docker.network.driver.mtu0(无限制)容器网络的最大传输单元(MTU),默认与宿主机网络 MTU 一致。 com.docker.network.container_iface_prefixeth容器内网络接口的名称前缀(如设置为 ethnick,则容器接口为ethnick0)。
四、默认网桥网络详情
1. 默认网络列表
安装 Docker 后,默认创建三个网络(可通过
docker network ls查看):、、docker network ls输出示例
NETWORK ID NAME DRIVER SCOPE a1b2c3d4 bridge bridge local # 默认网桥(docker0) e5f6g7h8 host host local # 主机网络(直接使用宿主机网络) i9j0k1l2 none null local # 无网络(容器隔离)2. 默认网桥(docker0)的关键参数
- 子网:默认子网为
172.17.0.0/16(可通过docker network inspect bridge查看)。- 网桥名称:Linux 接口名为
docker0(通过ip addr或brctl show查看)。3. 宿主机网络关联
内核路由表:宿主机路由表中会添加一条规则,将
172.17.0.0/16网段的流量转发到docker0网桥:route -n输出示例(关键行):
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0iptables 规则:Docker 会自动配置 iptables 规则管理网络流量,关键链如下:
FORWARD链:默认策略为DROP(丢弃所有转发流量),仅允许 Docker 网桥相关的流量通过。DOCKER链:处理容器的 NAT 规则(如端口映射)。DOCKER-USER链:用户自定义规则(可在此添加流量过滤策略)。DOCKER-ISOLATION-STAGE链:实现容器网络隔离(如不同网桥间的流量隔离)。4. 查看 iptables NAT 规则
通过以下命令查看 NAT 表的详细规则
iptables -t nat -vnL关键规则解读:
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)pkts bytes target prot opt in out source destination 0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0含义:对于源 IP 属于
172.17.0.0/16网段、且不通过docker0接口输出的流量,执行MASQUERADE(动态 NAT),将源 IP 替换为宿主机公网 IP,实现容器访问外网。
五、网桥网络使用案例
案例 1:使用默认网桥网络
目标:验证默认网桥的容器通信与限制(仅支持 IP 访问,无 DNS 解析)。
步骤 1:启动容器
# 启动两个容器(默认连接到 docker0 网桥) docker run -dit --rm --name alpine1 myalpine ash docker run -dit --rm --name alpine2 myalpine ash步骤 2:查看网桥网络详情
docker network inspect bridge输出关键信息(子网、容器 IP 等)
{"Name": "bridge","Subnets": [{"IPRange": "172.17.0.0/16","Gateway": "172.17.0.1"}],"Containers": {"alpine1": { "IPv4Address": "172.17.0.2/16" },"alpine2": { "IPv4Address": "172.17.0.3/16" }} }步骤 3:验证容器通信
通过 IP 访问(成功):
# 进入 alpine1 容器,ping alpine2 的 IP(172.17.0.3) docker exec alpine1 ping -c 3 172.17.0.3通过容器名访问(失败):
# 进入 alpine1 容器,ping alpine2(无 DNS 解析) docker exec alpine1 ping -c 3 alpine2 # 输出:ping: bad address 'alpine2'案例 2:自定义网桥网络
目标:创建自定义网桥,验证容器间 DNS 解析与灵活隔离。
步骤 1:创建自定义网桥
docker network create --driver bridge alpine-net步骤 2:启动容器并指定网络
# 启动两个容器,连接到 alpine-net 网桥 docker run -dit --rm --name alpine3 --network alpine-net myalpine ash docker run -dit --rm --name alpine4 --network alpine-net myalpine ash步骤 3:验证 DNS 解析
# 进入 alpine3 容器,ping alpine4(通过容器名访问) docker exec alpine3 ping -c 3 alpine4 # 输出:64 bytes from alpine4 (172.18.0.3): icmp_seq=1 ttl=64 time=0.078 ms步骤 4:将已有容器加入自定义网络
# 将 alpine1、alpine2 加入 alpine-net 网桥 docker network connect alpine-net alpine1 docker network disconnect alpine-net alpine2 # 可选:断开容器与网络的连接步骤 5:移除自定义网络(需先断开所有容器)
# 断开所有容器与 alpine-net 的连接 docker network disconnect alpine-net alpine1 docker network disconnect alpine-net alpine3 docker network disconnect alpine-net alpine4# 移除网络 docker network rm alpine-net案例 3:自定义网桥网络(高级配置)
目标:通过参数定制网桥的子网、网关、接口名称,并禁用 IP 伪装和容器间连接(ICC)。
步骤 1:创建高级自定义网桥
docker network create \--driver=bridge \--subnet=172.28.0.0/16 \ # 自定义子网--ip-range=172.28.5.0/24 \ # 容器 IP 分配范围(仅 172.28.5.0-172.28.5.255)--gateway=172.28.5.254 \ # 网桥网关 IP--opt com.docker.network.bridge.name=alpine-net1 \ # 网桥接口名--opt com.docker.network.bridge.enable_ip_masquerade=false \ # 禁用 IP 伪装(容器无法访问外网)--opt com.docker.network.bridge.enable_icc=false \ # 禁用容器间连接(ICC)--opt com.docker.network.container_iface_prefix=ethnick \ # 容器接口前缀alpine-net1步骤 2:启动容器并验证配置
# 启动两个容器,连接到 alpine-net1 网桥 docker run -dit --rm --name alpine6 --network alpine-net1 myalpine ash docker run -dit --rm --name alpine7 --network alpine-net1 myalpine ash步骤 3:验证容器间通信(ICC 禁用)
# 进入 alpine6 容器,ping alpine7(容器间无法通信) docker exec alpine6 ping -c 3 alpine7 # 输出:From 172.28.5.254 icmp_seq=1 Destination Host Unreachable步骤 4:验证外网访问(IP 伪装禁用)
# 进入 alpine6 容器,ping 外网(如 www.0voice.com) docker exec alpine6 ping -c 3 www.0voice.com # 输出:From 172.28.5.254 icmp_seq=1 Destination Host Unreachable步骤 5:查看容器接口名称(前缀为 ethnick)
# 进入 alpine6 容器,查看网络接口 docker exec alpine6 ip addr # 输出示例:ethnick0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
5. overlay
Docker 的 Overlay 网络是一种跨主机的网络驱动,主要用于解决不同宿主机上容器的通信问题。它通过将底层物理网络 “抽象” 成一个逻辑上的虚拟网络,让分布在多台宿主机上的容器能够像在同一局域网中一样通信,无需手动配置复杂的路由规则。
一、Overlay 网络的核心作用
Overlay 网络的核心是跨主机容器通信,主要解决以下问题:
- 分布式应用(如微服务)需要跨多台宿主机部署容器(例如:A 主机的
web容器需要调用 B 主机的db容器);- 容器需要透明访问其他主机的服务,无需关心底层物理网络拓扑;
- 容器需要支持动态扩缩容(如 Docker Swarm 或 Kubernetes 的服务发现)。
二、Overlay 网络的工作原理
Overlay 网络基于 VXLAN(Virtual Extensible LAN) 技术实现,通过 “封装 - 解封装” 网络流量,将容器间的通信流量 “包裹” 在宿主机的物理网络中传输。其核心组件和流程如下:
1. VXLAN 封装
VXLAN 是一种隧道协议,将容器的原始网络包(如 TCP/UDP)封装到一个新的 UDP 报文中,外层 UDP 报文的源 / 目的地址是宿主机的物理 IP。这样,容器间的跨主机流量可以通过宿主机的物理网络传输。
2. 控制平面(Control Plane)
Overlay 网络需要一个控制平面来管理网络元数据(如容器 IP、宿主机对应关系、VXLAN 隧道信息)。Docker 默认使用 Gossip 协议(适用于 Swarm 集群)或集成 Consul/Etcd(需手动配置)来同步这些信息。控制平面的作用是:
- 记录每台宿主机的物理 IP 和对应的 VXLAN 隧道端点(VTEP);
- 同步容器的 IP 地址和所属宿主机信息;
- 确保所有节点对网络状态达成一致(如新增容器、容器销毁)。
3. 数据平面(Data Plane)
数据平面负责实际的流量传输。当容器 A(宿主机 H1)需要访问容器 B(宿主机 H2)时:
- 容器 A 发送原始数据包(源 IP: 容器 A 的 IP,目的 IP: 容器 B 的 IP);
- 宿主机 H1 的 Docker 守护进程通过控制平面获取容器 B 所在的宿主机 H2 的物理 IP;
- H1 将原始数据包封装为 VXLAN 报文(外层 UDP 源 IP: H1 物理 IP,目的 IP: H2 物理 IP);
- 物理网络将 VXLAN 报文传输到 H2;
- H2 解封装 VXLAN 报文,将原始数据包转发给容器 B。
三、Overlay 网络的典型场景
Overlay 网络最常见于 Docker Swarm 集群或 Kubernetes 集群(通过 CNI 插件如 Flannel 实现类似功能),适用于以下场景:
- 跨主机的微服务通信(如
web服务调用redis服务);- 容器化应用的高可用部署(多副本分布在不同宿主机);
- 服务发现与负载均衡(Swarm 或 Kubernetes 自动管理容器的网络入口)。
四、Overlay 网络的使用案例(以 Docker Swarm 为例)
以下通过一个具体案例演示 Overlay 网络的创建和使用,需准备 2 台或更多 Linux 宿主机(假设 IP 分别为
192.168.1.10和192.168.1.11)。前提条件
- 所有宿主机安装 Docker(版本 ≥ 19.03);
- 所有宿主机时间同步(避免 Gossip 协议同步异常);
- 防火墙开放以下端口:
2377/tcp:Swarm 集群管理;7946/tcp/udp:节点间通信(Gossip 协议);4789/udp:VXLAN 流量(Overlay 网络核心端口)。步骤 1:初始化 Swarm 集群
在主节点(如
192.168.1.10)执行以下命令,初始化 Swarm 集群:# 主节点初始化 Swarm(生成加入令牌) docker swarm init --advertise-addr 192.168.1.10输出会包含从节点加入集群的命令(类似
docker swarm join --token ... 192.168.1.10:2377)。步骤 2:从节点加入集群
在从节点(如
192.168.1.11)执行主节点生成的加入命令,将节点加入 Swarm 集群# 从节点加入集群(替换为实际令牌和主节点 IP) docker swarm join --token SWMTKN-1-... 192.168.1.10:2377步骤 3:创建 Overlay 网络
在主节点创建一个 Overlay 网络(名称为
my-overlay)docker network create -d overlay my-overlay步骤 4:部署跨主机服务
在 Swarm 集群中部署两个服务(
web和db),分别运行在不同宿主机,并连接到my-overlay网络。部署
db服务(MySQL):docker service create \--name db \--network my-overlay \--replicas 1 \-e MYSQL_ROOT_PASSWORD=123456 \mysql:5.7部署
web服务(Nginx,模拟调用db):docker service create \--name web \--network my-overlay \--replicas 2 \ # 部署 2 个副本,分布在不同节点 -p 8080:80 \ # 映射宿主机 8080 端口到容器 80 端口 nginx:alpine步骤 5:验证跨主机通信
查看服务分布:
docker service ps web # 输出会显示两个副本分别在主节点和从节点运行进入其中一个
web容器(假设在从节点192.168.1.11),尝试访问db服务:# 找到 web 容器的 ID(假设为 abc123) docker exec -it abc123 sh# 在容器内 ping db 服务(Swarm 自动解析服务名为 IP) ping db # 应成功响应(说明跨主机通信正常)宿主机访问
web服务:
无论访问主节点还是从节点的192.168.1.10:8080或192.168.1.11:8080,都会路由到可用的web容器(Swarm 自动负载均衡)。
6. host网络模式
一、Host 网络模式(主机网络)
1. 核心概念
Host 模式是 Docker 网络中最特殊的一种:容器直接使用宿主机的网络栈,不进行任何网络隔离。容器与宿主机共享 IP 地址、端口空间和网络设备,相当于容器进程直接运行在宿主机网络中。
2. 关键特性
- 无网络隔离:容器无独立 IP,直接使用宿主机 IP,端口映射(
-p)失效(因端口已属于宿主机)。- 性能优势:无需 NAT 转换和 Userland Proxy,网络延迟最低,适用于对性能敏感的场景(如高并发服务)。
- 平台限制:仅支持 Linux 主机,Mac/Windows 不支持。
- 集群限制:同一宿主机上,相同端口的容器只能运行一个(端口冲突)。
3. 实战案例
案例 1:运行 Nginx 容器(Host 模式)
# 无需端口映射,直接使用宿主机 80 端口 docker run -d --rm --name mynginx --network host nginx:latest# 验证访问(宿主机 IP:80 直接访问) curl http://localhost案例 2:Swarm 服务部署(Host 模式)
# 创建 3 个副本的 Nginx 服务(每个节点仅能运行 1 个) docker service create --replicas 3 --name nginx-svc2 --network host nginx:latest# 问题:若节点 1 已运行 80 端口容器,节点 2 部署时会因端口冲突失败4. 适用场景
- 高性能网络服务:如 Redis、MySQL 等对网络延迟敏感的应用。
- 需要直接访问宿主机网络设备:如监控工具、网络测试工具。
- 简化网络配置:避免端口映射维护,直接复用宿主机端口。
7. IPvlan网络驱动
1. 核心概念
IPvlan 是一种高性能网络驱动,允许容器直接连接到宿主机的物理网络接口,每个容器分配独立 IP,共享宿主机 MAC 地址(L2 模式)或独立 MAC(L3 模式)。其设计目标是实现容器与物理网络的直接通信,降低网络开销。
2. 关键配置选项
选项 描述 ipvlan_mode模式选择:
l2(默认):容器与宿主机共享 MAC,同一子网可直接通信
l3:容器有独立 MAC,需路由转发
l3s:L3 模式的扩展,支持多子网ipvlan_flag附加标志: bridge(默认)、private(隔离容器间通信)、vepa(强制流量经父接口转发)parent指定物理网卡(如 ens33)作为父接口3. 内核要求
- Linux 内核版本需 ≥ 4.2(通过
uname -r查看)。4. 实战案例
案例 1:单机 IPvlan(L2 模式)
# 创建 IPvlan 网络(L2 模式,共享父接口 MAC) docker network create -d ipvlan \--aux-address vmware=192.168.239.1 \--subnet=192.168.239.0/24 --gateway=192.168.239.2 \-o parent=ens33 -o ipvlan_mode=l2 \pub_ens33# 启动容器(自动分配子网内 IP) docker run -dit --rm --name alpine8 --network pub_ens33 alpine ash docker run -dit --rm --name alpine9 --network pub_ens33 alpine ash# 查看网络详情(容器 IP 与宿主机同子网) docker network inspect pub_ens33案例 2:宿主机与容器通信(L2 模式配置)
# 1. 创建宿主机 IPvlan 子接口 sudo ip link add ipvlan-net link ens33 type ipvlan mode l2 sudo ip addr add 192.168.239.254/24 dev ipvlan-net sudo ip link set ipvlan-net up# 2. 启用混杂模式(允许接收所有 MAC 帧) sudo ip link set ens33 promisc on sudo ip link set ipvlan-net promisc on# 3. 配置路由表(新建 docker 路由表) sudo vim /etc/iproute2/rt_tables # 添加一行:100 docker sudo ip route flush table docker sudo ip route add default via 192.168.239.254 table docker sudo ip route add 192.168.239.0/24 dev ipvlan-net src 192.168.239.254 metric 10 sudo ip rule add from all to 192.168.239.0/24 table docker# 4. 验证宿主机访问容器 ping 192.168.239.3 # 容器 IP# 5. 还原配置(生产环境慎用) sudo ip rule del from all to 192.168.239.0/24 table docker # ...(逐步删除路由、关闭混杂模式、删除接口)案例 3:跨主机容器通信(L2 模式)
# 每台主机创建相同配置的 IPvlan 网络 docker network create -d ipvlan \--aux-address vmware=192.168.239.1 \--subnet=192.168.239.0/24 --gateway=192.168.239.2 \-o parent=ens33 -o ipvlan_mode=l2 \pub_ens33# 主机1启动容器 docker run -dit --rm --name alpine10 --ip=192.168.239.10 --network pub_ens33 alpine ash # 主机2启动容器 docker run -dit --rm --name alpine12 --ip=192.168.239.12 --network pub_ens33 alpine ash# 跨主机通信(需物理网络支持二层互通) ping 192.168.239.12 # 主机1容器访问主机2容器案例 4:单机跨网络通信(L3 模式)
# 创建多子网 IPvlan 网络(L3 模式,支持跨子网路由) docker network create -d ipvlan \--subnet=192.168.214.0/24 \--subnet=10.1.214.0/24 \-o parent=ens33 -o ipvlan_mode=l3 \pub_ens33-1# 启动跨子网容器 docker run -dit --rm --name alpine14 --network pub_ens33-1 --ip=192.168.214.10 alpine ash docker run -dit --rm --name alpine15 --network pub_ens33-1 --ip=10.1.214.10 alpine ash# 跨子网通信(需容器内配置路由) # alpine14 中:ip route add 10.1.214.0/24 via 192.168.214.15. 注意事项
- 安全隔离:L2 模式下容器共享 MAC,需通过防火墙限制容器间访问;L3 模式需配置路由规则。
- 外部访问:IPvlan 网络默认不被外部路由知晓,需在物理路由器添加静态路由。
- 性能优势:跳过 Docker 网桥转发,适合高吞吐量场景(如网络代理、负载均衡器)。
8. Macvlan 网络驱动
1. 核心概念
Macvlan 允许为容器的虚拟网卡分配独立 MAC 地址,使容器看起来像 “物理设备” 直接连接到物理网络。与 IPvlan 相比,Macvlan 更贴近传统网络模型,每个容器有独立 MAC 和 IP,适用于需要直接接入物理网络的遗留应用。
2. 关键配置选项
选项 描述 macvlan_mode模式选择:
bridge(默认):容器间直接通信
vepa:流量强制经父接口转发
passthru:直接使用物理接口(仅一个容器可连接)
private:容器间隔离parent指定物理网卡(如 ens33)作为父接口3. 注意事项
- MAC 地址管理:大量容器可能导致 MAC 地址泛滥,需网络设备支持(如交换机开启混杂模式)。
- 性能影响:若网络设备未优化 MAC 学习,可能导致广播风暴。
- 替代方案:优先使用 Bridge 或 Overlay 网络,仅在遗留应用必须直连物理网络时使用 Macvlan。
4. 实战案例
# 案例:创建 Macvlan 网络并启动容器 docker network create -d macvlan \--subnet=172.16.86.0/24 \--gateway=172.16.86.1 \-o parent=ens33 \pub_mac_ens33# 启动容器(自动分配独立 IP 和 MAC) docker run -dit --rm --name alpine16 --network pub_mac_ens33 alpine ash docker run -dit --rm --name alpine17 --network pub_mac_ens33 alpine ash# 查看容器网络详情(包含独立 MAC 地址) docker network inspect pub_mac_ens33
9. None 网络模式
1. 核心概念
None 模式是 Docker 中最严格的网络隔离模式:容器创建时仅生成环回接口(
lo),完全没有网络连接。适用于不需要网络的场景(如批处理任务、离线计算)。2. 实战案例
# 启动无网络容器 docker run -dit --rm --name alpine-none --network none alpine ash# 进入容器查看网络接口(仅有 lo) docker exec alpine-none ip addr # 输出:1: lo: <LOOPBACK,UP,LOWER_UP> ...3. 适用场景
- 安全敏感场景:禁止容器访问任何网络,防止数据泄露。
- 离线任务:如日志处理、文件转换等无需网络的批量作业。
五、网络模式对比与选择建议
网络模式 隔离性 IP 分配 性能 适用场景 Bridge 中等(同网桥可通信) 容器独立 IP(NAT) 中等 常规应用、微服务 Host 无 共享宿主机 IP 最高 高性能服务、直接使用宿主机端口 IPvlan/Macvlan 高(可配置隔离) 独立 IP(直连物理网络) 高 网络代理、遗留应用、跨主机二层通信 None 最高 仅有环回接口 N/A 离线任务、安全隔离 选择原则:优先使用 Bridge 模式;追求性能用 Host;需直连物理网络用 IPvlan/Macvlan;完全隔离用 None。
0voice · GitHub