动手学深度学习pytorch学习笔记 —— 第四章(2)
1 暂退法
1.1 偏差-反差权衡
泛化性和灵活性之间的基本权衡被描述为偏差-方差权衡。 线性模型有很高的偏差:它们只能表示一小类函数。 然而,这些模型的方差很低:它们在不同的随机数据样本上可以得出相似的结果。但是,线性模型泛化的可靠性是有代价的,即线性模型没有考虑到特征之间的交互作用。 对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。
- 当面对更多的特征而样本不足时,线性模型往往会过拟合。
- 当给出更多样本而不是特征,通常线性模型不会过拟合。
深度神经网络位于偏差-方差谱的另一端。 与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互(即参数之间的交互)。
1.2 扰动的稳健性暂退法
在探究泛化性之前,我们期待好的预测模型能在未知的数据上有很好的表现。经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。 简单性以较小维度的形式展现。简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。也就是模型在一些有随机噪声(也就是微小的干扰因素)的输入影响是不大的。因此,在训练过程中,在计算后续层之前向网络的每一层注入噪声,以此在输入-输出映射上增强平滑性。
1.3 暂退法
暂退法:在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。 之所以称为暂退法,是因为从表面上看是在训练过程中丢弃一些神经元(结果)。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
关键的挑战是如何注入这种噪声。 书中提出的想法是以一种无偏向的方式注入噪声。 这样在固定其他层时,每一层的期望值等于没有噪音时的值。将高斯噪声添加到线性模型的输入中, 在每次训练迭代中,将从均值为零的分布ϵ∼N(0,σ2) 采样噪声添加到输入x, 从而产生扰动点x′=x+ϵ, 预期是E[x′]=x。
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。 换言之,每个中间活性值h以暂退概率p由随机变量h′替换,如下所示:

这样的概率设计可以保证期望值保持不变为E[h′]=h。
- 通常,我们在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。
- 然而也有一些例外:一些研究人员在测试时使用暂退法, 用于估计神经网络预测的“不确定性”。
- “不确定性”:如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
1.4 实现暂退法
运用深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(即下一层的输入)
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);# 对模型进行训练和测试
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)2 前向传播、反向传播
2.1 前向传播
前向传播指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
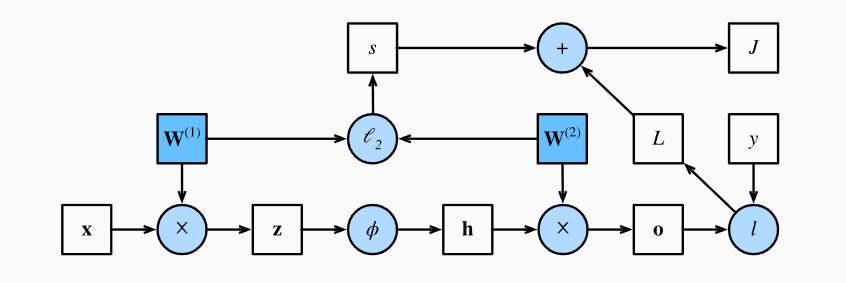
假设我们的输入为X,不考虑偏置项。中间变量Z也就是X与参数向量W1进行计算。然后经过激活函数得到h,最终得到输出结果O = W1 * h。假设我们的交叉熵损失为l,再加上我们之前所学习的L2范数。最后的正则化损失J为l + L2. 详细前向传播图如下:
2.2 反向传播
反向传播:计算神经网络参数梯度的方法。 简言之,该方法根据微积分中的链式规则。
梯度的自动计算(自动微分)大大简化了深度学习算法的实现。 在自动微分之前,即使是对复杂模型的微小调整也需要手工重新计算复杂的导数,现在可以直接使用框架提供的自动微分的函数。
在训练神经网络时,前向传播和反向传播相互依赖。 对于前向传播,我们沿着依赖的方向遍历计算图并计算其路径上的所有变量。 然后将这些用于反向传播,其中计算顺序与计算图的相反。
因此,在训练神经网络时,在初始化模型参数后, 我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。 反向传播重复利用前向传播中存储的中间值,以避免重复计算。带来的影响之一是我们需要保留中间值,直到反向传播完成。 这也是训练比单纯的预测需要更多的内存的原因之一。
3 数值稳定性和模型初始化
目前为止,我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。初始化方案的选择在神经网络学习中非常重要, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择结合在一起。函数的选择以及初始化参数可以决定优化算法收敛的速度。糟糕的选择可能会导致我们在训练时梯度爆炸或梯度消失。
3.1 打破对称性
神经网络设计中的另一个问题是其参数化所固有的对称性。假设我们有一个简单的多层感知机,它有一个隐藏层和两个隐藏单元。 在这种情况下,我们可以对第一层的权重W1进行重排列, 并且同样对输出层的权重进行重排列,可以获得相同的函数。第一个隐藏单元与第二个隐藏单元没有什么特别的区别。 换句话说,我们在每一层的隐藏单元之间具有排列对称性。
如果将隐藏层的所有参数初始化为W(1)=c, c为常量。在这种情况下,前向传播期间,两个隐藏单元采用相同的输入和参数, 产生相同的激活,该激活被送到输出单元。 在反向传播期间,根据参数W1对输出单元进行微分, 得到一个梯度,其元素都取相同的值。 因此,在基于梯度的迭代(之后,W1的所有元素仍然采用相同的值。 这样的迭代永远不会打破对称性,我们可能永远也无法实现网络的表达能力。 隐藏层的行为就好像只有一个单元。虽然小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
3.2 参数初始化
3.2.1 默认初始化
在前面的部分中,使用正态分布来初始化权重值。如果我们不指定初始化方法, 框架将使用默认的随机初始化方法,对于中等难度的问题,这种方法通常很有效。
3.2.2 Xavier初始化
权重w(ij)都是从同一分布中独立抽取的。 此外,让我们假设该分布具有零均值和方差σ2。 请注意,这并不意味着分布必须是高斯的,只是均值和方差需要存在。 现在,假设层xj的输入也具有零均值和方差γ2, 并且它们独立于wij并且彼此独立。
通常,Xavier初始化从均值为零,方差如下的高斯分布中采样权重。
