NumPy 聚合:最小、最大值及此间一切
文章目录
- 聚合:最小、最大值及此间一切
- 一、数组值求和
- 二、最小值和最大值
- 1. 多维聚合
- 2. 其他聚合函数
- 三、示例:美国总统的平均身高是多少?
聚合:最小、最大值及此间一切
也许,翻译成“聚合操作:最小值、最大值及期间所有统计量”会更合适吧……
探索任何数据集的第一步通常是计算各种汇总统计量。也许最常见的汇总统计量是均值和标准差,它们能让你总结数据集中的"典型"值,但其他聚合函数同样有用(如求和、乘积、中位数、最小值和最大值、分位数等)。
在处理数组方面,NumPy具有高效快速的内置聚合函数;我们将在这里讨论并尝试其中的一些函数。
一、数组值求和
作为一个简单的例子,考虑计算数组中所有值的总和。
Python本身可以使用内置的sum函数来完成此操作:
import numpy as np
rng = np.random.default_rng()
L = rng.random(100)
sum(L)
np.float64(45.968416990980614)
语法与NumPy的sum函数非常相似,在最简单的情况下结果也是相同的:
注:实测结果精度有一点点差异,但整体来看计算结果一致。
np.sum(L)
np.float64(45.96841699098061)
然而,由于在编译好的代码中执行操作,NumPy版本计算速度要快得多:
big_array = rng.random(1000000)
%timeit sum(big_array)
%timeit np.sum(big_array)
23.4 ms ± 203 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
217 μs ± 11.2 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
不过要小心:sum函数和np.sum函数并不完全相同,这有时会导致混淆!
特别是它们的可选参数含义不同——(sum(x, 1)将求和初始化为1,而np.sum(x, 1)沿着轴1求和),并且np.sum能够处理多维数组,我们将在下一节看到这一点。
二、最小值和最大值
同样,Python有内置的min和max函数,用于找到任何给定数组的最小值和最大值:
min(big_array), max(big_array)
(np.float64(1.1312209065028611e-06), np.float64(0.9999991669578098))
NumPy对应的函数具有相似的语法,同样运行速度要快得多:
np.min(big_array), np.max(big_array)
(np.float64(1.1312209065028611e-06), np.float64(0.9999991669578098))
%timeit min(big_array)
%timeit np.min(big_array)
16.4 ms ± 245 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
130 μs ± 4.82 μs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
对于min、max、sum以及其他几个NumPy聚合函数,更简洁的语法是使用数组对象本身的方法:
print(big_array.min(), big_array.max(), big_array.sum())
1.1312209065028611e-06 0.9999991669578098 499947.2329253865
只要有可能,在操作NumPy数组时请确保使用这些聚合函数的NumPy版本!
1. 多维聚合
一种常见的聚合操作类型是沿行或列进行聚合。
假设你有一些存储在二维数组中的数据:
M = rng.integers(0, 10, (3, 4))
print(M)
[[1 9 7 4][3 3 3 5][7 1 6 6]]
NumPy聚合函数将对多维数组的所有元素执行全量计算:
M.sum()
np.int64(55)
聚合函数会接受一个额外的参数,用于指定计算聚合的轴(axis)。例如,我们可以通过指定 axis=0 来找出每一列中的最小值:
M.min(axis=0)
array([1, 1, 3, 4])
该函数返回四个值,分别对应数字的四列。
类似地,我们可以找出每一行中的最大值:
M.max(axis=1)
array([9, 5, 7])
对于来自其他语言的用户来说,这里指定轴的方式可能会令人困惑。
axis 关键字指定的是数组将被折叠(Collapsed)的维度,而不是将要返回的维度。
因此,指定 axis=0 意味着轴 0 将被折叠:对于二维数组,每列中的值将被聚合。
2. 其他聚合函数
NumPy 提供了许多其他具有类似 API 的聚合函数,此外,大多数函数都有一个 NaN 安全的对应版本,该版本在计算结果时会忽略缺失值,这些缺失值由特殊的 IEEE 浮点值 NaN 标记。
下表列出了 NumPy 中常用的聚合函数及其说明:
| 函数名 | “NaN-安全”(NaN-Safe)版本 | 描述 |
|---|---|---|
np.sum | np.nansum | 计算所有元素的和 |
np.prod | np.nanprod | 计算所有元素的乘积 |
np.mean | np.nanmean | 计算所有元素的均值 |
np.std | np.nanstd | 计算所有元素的标准差 |
np.var | np.nanvar | 计算所有元素的方差 |
np.min | np.nanmin | 查找最小值 |
np.max | np.nanmax | 查找最大值 |
np.argmin | np.nanargmin | 查找最小值的索引 |
np.argmax | np.nanargmax | 查找最大值的索引 |
np.median | np.nanmedian | 计算所有元素的中位数 |
np.percentile | np.nanpercentile | 计算元素的分位数等排序统计量 |
np.any | N/A | 判断是否有元素为 True |
np.all | N/A | 判断是否所有元素都为 True |
你将在本书的后续内容中经常看到这些聚合函数。
三、示例:美国总统的平均身高是多少?
NumPy 中可用的聚合函数可以作为一组数值的汇总统计量。
以当前所有美国总统的身高作为一个下例子——
这些数据存储在文件 president_heights.csv 中,这是一个以逗号分隔,包含标签和值的列表:
!head -4 data/president_heights.csv
'head' �����ڲ����ⲿ���Ҳ���ǿ����еij���
���������ļ���
上述命令等效于以下代码,考虑到编码乱码问题,加上encoding='utf-8'。
with open('data/president_heights.csv', encoding='utf-8') as f:for _ in range(4):print(f.readline().strip())
order,name,height(cm)
1,George Washington,189
2,John Adams,170
3,Thomas Jefferson,189
我们将使用 Pandas 包来读取文件并提取这些信息(注意,身高的单位是厘米):
import pandas as pd
data = pd.read_csv('data/president_heights.csv')
heights = np.array(data['height(cm)'])
print(heights)
[189 170 189 163 183 171 185 168 173 183 173 173 175 178 183 193 178 173174 183 183 168 170 178 182 180 183 178 182 188 175 179 183 193 182 183177 185 188 188 182 185 191 182]
现在我们读入了这些数据,并以数组形式做好了准备,可以计算各种汇总统计量:
print("Mean height: ", heights.mean())
print("Standard deviation:", heights.std())
print("Minimum height: ", heights.min())
print("Maximum height: ", heights.max())
Mean height: 180.04545454545453
Standard deviation: 6.983599441335736
Minimum height: 163
Maximum height: 193
值得注意的是在每种情况下,聚合操作都将整个数组简化为一个汇总值,这为我们提供了有关数值分布的信息。
有时候,我们还希望计算出分位数:
print("25th percentile: ", np.percentile(heights, 25))
print("Median: ", np.median(heights))
print("75th percentile: ", np.percentile(heights, 75))
25th percentile: 174.75
Median: 182.0
75th percentile: 183.5
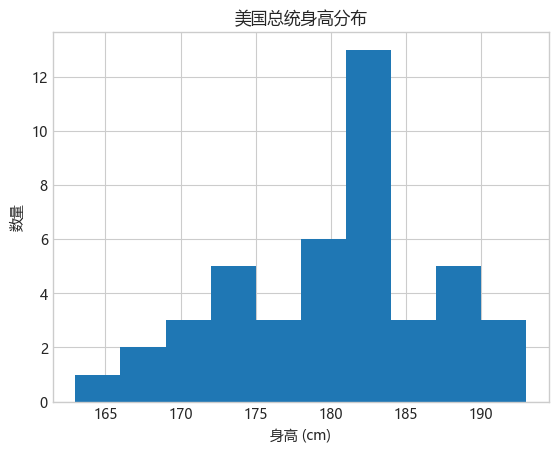
我们可以看到,美国总统的身高中位数为182厘米,略低于六英尺。
当然,有时候通过可视化的方式来展示这些数据会更生动形象,更有作用。那么,我们可以使用 Matplotlib 工具来实现。例如,下面的代码会生成如下图表:
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid') # 设置绘图样式,本机运行环境是Python 3.12.9,matplotlib是3.10.3
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #用来正常显示中文标签
plt.hist(heights)
# plt.title('Height Distribution of US Presidents')
plt.title('美国总统身高分布')
# plt.xlabel('height (cm)')
plt.xlabel('身高 (cm)')
# plt.ylabel('number');
plt.ylabel('数量');