Dify案例实战之智能体应用构建(二)
一、部署dify
Windows安装Docker部署dify,接入阿里云api-key进行rag测试-CSDN博客
可以参考我的前面文章,创建一个本地dify或者直接dify官网使用一样的(dify官网需要科学上网)
二、Dify案例实战之智能体
2.1 飞书智能客服需求和演示
需求:将用户的对某个商品的评价由大模型判断是正面评价还是负面评价(负面评价又细分物流慢、质量差、其他)然后通过飞书机器人发送到飞书运营群,给运营处理。
演示效果:输入商品ID :1 输入信息:商品很棒
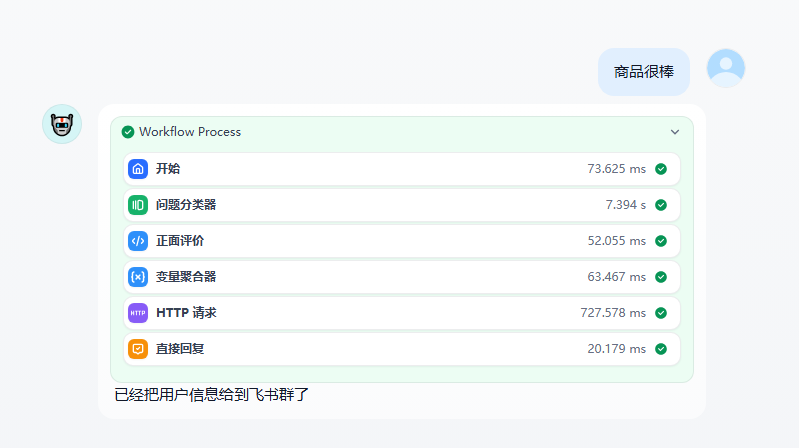
飞书群收到的信息

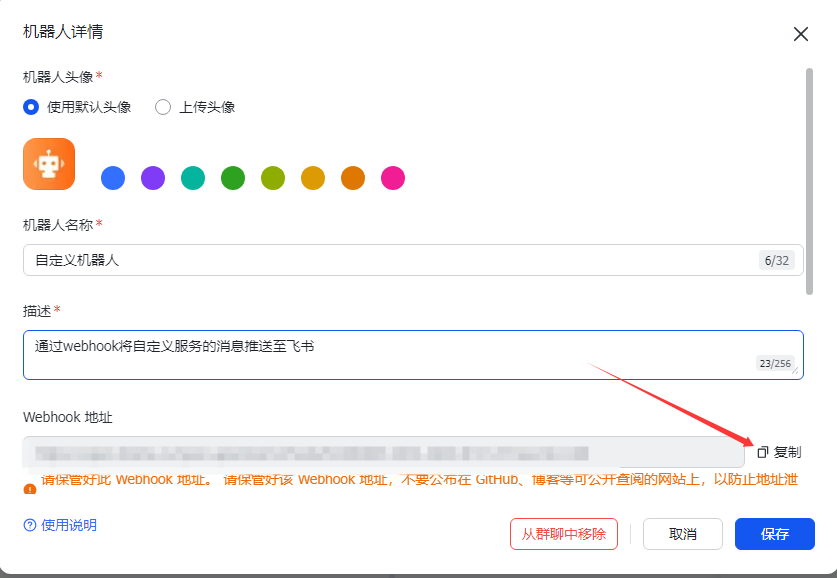
2.2 获取飞书机器人的url
在飞书群中拉一个飞书机器人,复制webhook地址作为post请求的url
飞书机器人信息发送代码.py
import requests
import json
# 飞书的Webhook地址
WEBHOOK_URL = 'your_webhook_url'
# 要发送的消息内容
data = {
"msg_type": "text",
"content": {
"text": "你好,这是一个测试消息。"
}
}
headers = {
'Content-Type': 'application/json',
'Charset': 'UTF-8'
}
response = requests.post(WEBHOOK_URL, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print('消息发送成功。')
else:
print('消息发送失败。')
2.3 制作工作流
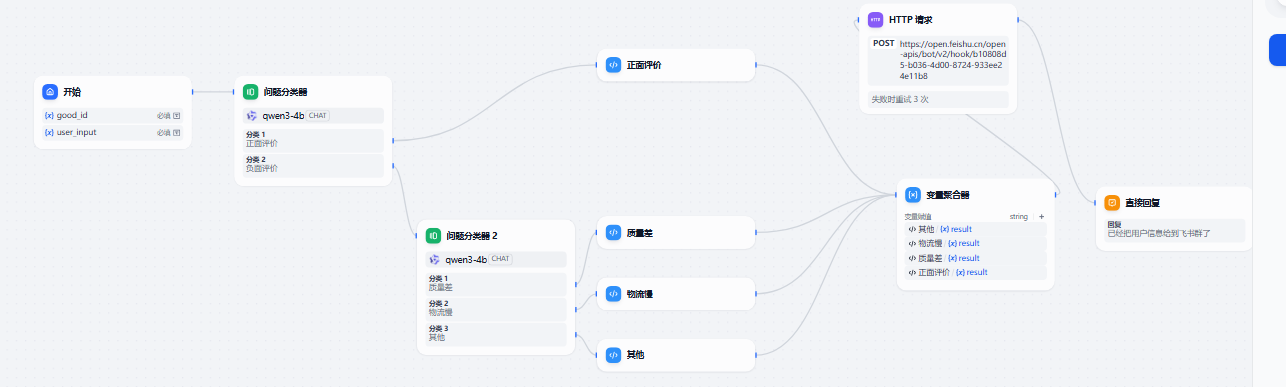 开始节点【good_id,user_input】
开始节点【good_id,user_input】
正负向分类节点【开始/user_input】--->class_name
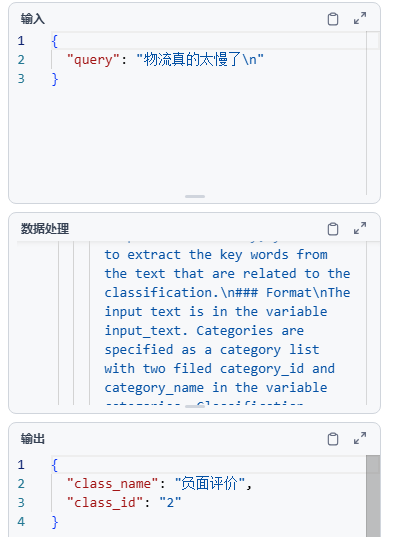
若是正向评价,进入代码执行器【开始/user_input,开始/good_id】目的是生成飞书机器人信息发送代码.py 中的请求体部分信息,后续给到post请求处理。
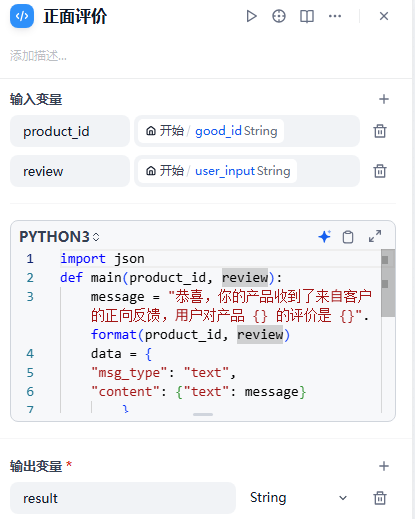
import json
def main(product_id, review):
message = "恭喜,你的产品收到了来⾃客户的正向反馈,⽤户对产品 {} 的评价是 {}".format(product_id, review)
data = {
"msg_type": "text",
"content": {"text": message}
}
return {
"result": json.dumps(data, ensure_ascii=False)
}
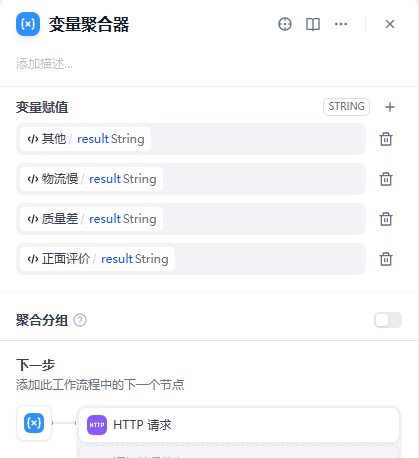
负面评价的话,再走一次情感分类节点,分成三大类后和正面评价评价流程一样,都是得到请求体的部分。
聚合变量节点,因为全部变量都是一样的,聚合在
http请求节点,直接把聚合体的输出作为请求体,所以选择raw,原始格式输入
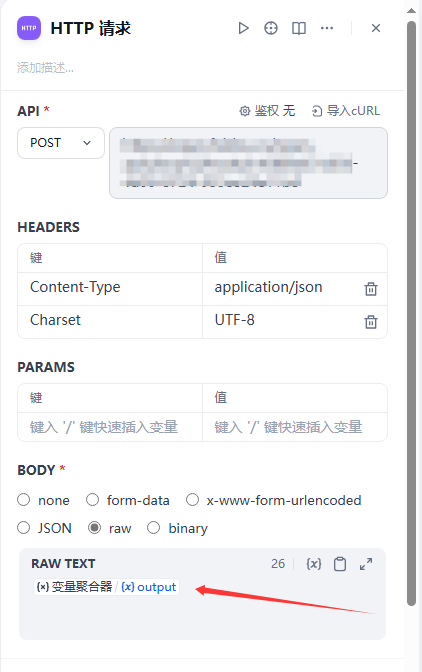
最后因为选择的是chatflow所以必须要chat节点,让大模型总是回复,已经把用户信息给到飞书群了。就可以了。
dify应用怎么部署可以看完上一篇文章:Dify案例实战之智能体应用构建(一)-CSDN博客
三、构建企业RAG应用
3.1 RAG是什么
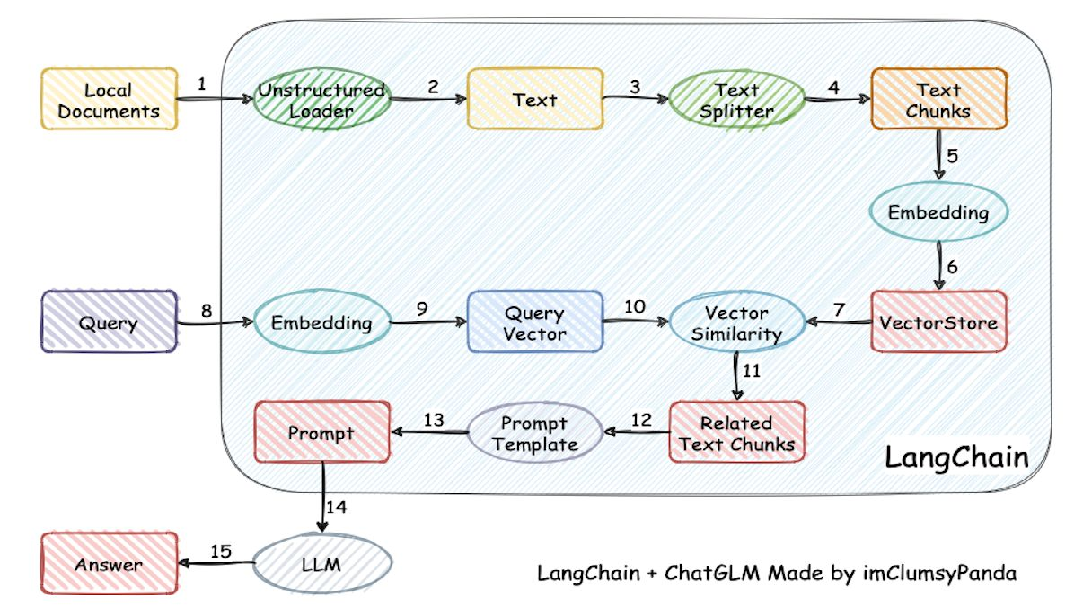
如下图所示,传统的RAG技术是在大模型回答用户问题前,前通过向量检索技术把用户的问题向量化再拿到向量数据库中向量匹配,得到最相关的知识片段一并给到LLM,让LLM开卷回答用户问题,减少LLM的幻觉问题(一本正经的胡说八道)。
3.2 Dify知识库实现
知识库是⼀些⽂档的集合,可以被整体集成⾄⼀个应⽤中作为检索上下⽂使⽤。 Dify 的知识库功能可实现 RAG 流⽔线上各环节的可视化,并且 Dify 提供了⼀套简单易⽤的⽤户界⾯来⽅便应⽤构建者来管理个⼈或者团队的知识库,并能够将知识库快速的集成到 AI 应⽤中。
⽬前 Dify ⽀持多种源数据格式,包括:
⻓⽂本内容:TXT、Markdown、DOCX、HTML、JSON、 PDF
结构化数据:CSV、Excel
注:私有知识库要达到良好的效果,必须与embedding模型和reranker模型相结合,请在xinterface中启⽤相关模型并引⼊Dify