从0到1:某智慧园区数字孪生项目的技术选型复盘
从0到1:某智慧园区数字孪生项目的技术选型复盘
【内容摘要】
你有没有想过,一个“数字孪生”项目到底是怎么一步步从一张白纸变成一个能跑数据、能看趋势、能辅助决策的系统平台?很多人一提到数字孪生,想到的是炫酷的3D可视化效果,是“科技感爆棚”的大屏展示。但真正做项目的人都知道:技术选型才是决定成败的第一步。
在我们参与的一个智慧园区数字孪生项目中,团队一开始信心满满,结果却在技术栈的选择上走了不少弯路——有的工具性能跟不上需求,有的平台文档缺失导致开发效率低下,甚至一度影响了整个项目的进度。
这篇文章将带你一起回顾这个项目的真实技术选型过程,包括:
- 为什么选择了A而不是B?
- 哪些看似“高大上”的方案最终被放弃?
- 如何在有限预算和时间下做出平衡?
如果你正在筹备或参与类似的数字孪生项目,这篇文章或许能帮你少踩几个坑,把力气用在刀刃上。
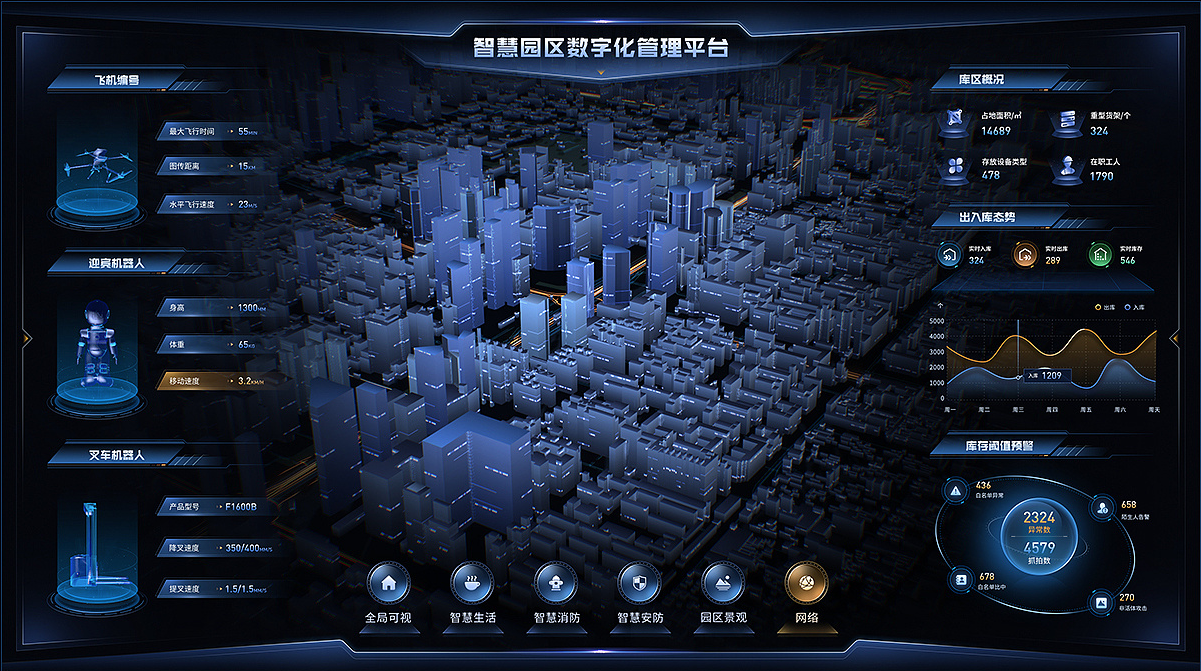
一、什么是数字孪生?它在智慧园区中扮演什么角色?
先来搞清楚一个基本问题:数字孪生到底是什么?
简单来说,数字孪生就是通过数字化手段,在虚拟空间中构建一个与现实世界一一对应的“镜像模型”。它可以实时反映物理对象的状态,并支持模拟、预测和优化等操作。
在智慧园区中的典型应用场景:
| 场景 | 描述 |
| 园区管理 | 实时查看建筑状态、人流热力分布、能耗情况 |
| 设备运维 | 监控电梯、空调、照明等设备运行状态,提前预警故障 |
| 安防监控 | 集成摄像头、门禁、报警系统,实现统一调度 |
| 应急指挥 | 出现突发事件时,快速调取三维场景进行分析和响应 |
可以说,数字孪生是智慧园区的大脑和眼睛,它让管理者能够“看见”原本看不见的数据,从而做出更科学的决策。
二、为什么说技术选型是数字孪生项目的“地基”?
很多团队刚开始做数字孪生项目时,往往关注点都在“怎么做3D建模”、“怎么接入数据”,却忽略了最关键的一环:底层技术架构是否合理?能否支撑起长期运营的需求?
技术选型的重要性体现在以下几个方面:
| 维度 | 影响 |
| 性能表现 | 决定系统能否承载大量并发访问和复杂计算 |
| 开发效率 | 工具链是否成熟、文档是否完善、社区是否活跃 |
| 扩展能力 | 是否方便后续接入新设备、新增功能模块 |
| 成本控制 | 是否能在有限预算内完成部署和维护 |
| 安全性 | 数据传输、用户权限、系统稳定性是否有保障 |
换句话说,选错技术栈,轻则返工重做,重则项目流产。这正是我们在实际项目中踩过的坑。

三、我们的技术选型实战经验分享(含优劣势对比)
接下来我们将以我们参与的实际项目为例,详细介绍从建模、渲染、数据接入到后端服务的整体技术选型过程,并给出每一步的思考与权衡。
✅ 1. 建模工具选择:Blender vs BIM vs Revit
| 工具 | 优点 | 缺点 |
| Blender | 免费开源,建模能力强,适合创意类设计 | 学习成本高,缺乏工程级精度 |
| BIM(广联达) | 建筑信息模型完整,适合大型基建项目 | 商业软件,价格贵,对硬件要求高 |
| Revit | Autodesk出品,广泛用于建筑设计行业 | 功能强大但导出格式不友好,需二次处理 |
📌 最终选择:Revit + FBX 导出 + Unity 加载
理由:虽然 Revit 使用门槛高,但它提供了最完整的建筑结构数据,且可通过插件导出为通用格式,便于后续渲染使用。
✅ 2. 渲染引擎对比:Unity vs Unreal Engine vs Three.js
| 引擎 | 优势 | 劣势 |
| Unity | 上手快,生态丰富,跨平台能力强 | 对复杂光照和材质表现略逊色 |
| Unreal Engine | 图形渲染极致逼真,适合影视级展示 | 学习曲线陡峭,资源占用高 |
| Three.js | Web端原生支持,适合轻量级项目 | 功能较弱,不适合大规模场景 |
📌 最终选择:Unity + WebGL 导出
理由:项目需要兼顾本地部署和Web访问,Unity 的 WebGL 支持较为成熟,且可以借助 Asset Store 快速集成常用组件。

✅ 3. 数据接入方式:MQTT vs HTTP vs WebSocket
| 协议 | 特点 | 适用场景 |
| MQTT | 轻量级、低延迟、适用于物联网设备通信 | 需要中间代理服务器,配置稍复杂 |
| HTTP | 简单易用,兼容性强 | 实时性差,频繁请求压力大 |
| WebSocket | 双向通信、实时性强 | 连接保持消耗资源,需注意连接池管理 |
📌 最终选择:MQTT + 后端中转 + WebSocket 推送前端
理由:园区有大量传感器设备,采用 MQTT 接入后端服务,再由后端统一推送到前端页面,既保证了实时性,又降低了前端压力。
✅ 4. 后端服务框架:Node.js vs Spring Boot vs Django
| 框架 | 优势 | 劣势 |
| Node.js | 异步非阻塞,适合高并发场景 | 不适合复杂业务逻辑 |
| Spring Boot | Java生态成熟,适合企业级应用 | 启动慢,依赖多 |
| Django | Python语言,开发效率高,内置功能强 | 并发能力一般 |
📌 最终选择:Spring Boot + MyBatis + Redis
理由:考虑到未来可能对接政务系统、ERP系统,Java生态更有扩展性和安全性保障。

四、技术选型背后的“隐形成本”与教训总结
除了看得见的功能和技术之外,还有一些隐藏的成本和挑战,也是我们在项目过程中深刻体会到的。
常见隐形成本:
| 成本类型 | 描述 |
| 学习成本 | 团队成员对新技术的熟悉程度直接影响开发进度 |
| 调试成本 | 有些平台接口不规范,调试起来异常痛苦 |
| 部署成本 | 云服务费用、GPU资源、带宽限制都可能成为瓶颈 |
| 维护成本 | 代码结构混乱、文档缺失会导致后期难以维护 |
我们的几点教训:
- 不要盲目追求“最新最潮”的技术,稳定性和可维护性更重要;
- 技术选型必须结合团队技能,否则容易陷入“会写的人太少”的困境;
- 尽早搭建原型验证可行性,避免后期推倒重来;
- 预留一定的技术弹性空间,以应对未来可能出现的新需求。

总结
从0到1打造一个数字孪生项目并不容易,而技术选型则是整个项目中最基础、也最容易忽视的一环。它不仅决定了系统的上限,也影响着团队的效率和项目的可持续性。
总结一下:
- 数字孪生不是简单的3D建模,而是融合建模、渲染、数据、交互等多个维度的系统工程
- 技术选型应围绕性能、成本、可维护性三大核心目标展开
- 不同阶段、不同团队、不同预算下的技术栈选择策略各有侧重
- 前期做好原型验证和团队培训,是降低风险的关键
总结:本文通过一个真实项目的视角,带你了解了数字孪生项目中技术选型的核心思路与实践经验。希望这些经验能为你提供参考,让你在未来的项目中少走弯路,顺利打造出真正有价值、有人用、能落地的数字孪生系统。