Redis--缓存穿透与缓存雪崩详解及解决方案
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会到达数据库。
如图所示:
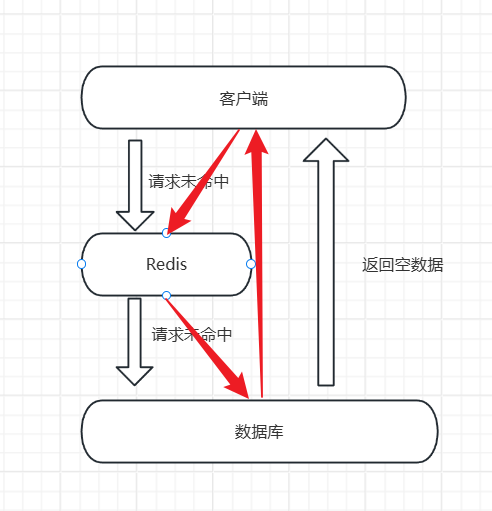
这种情况如果别有用心的人就可以制造大量线程并发请求这个不存在的数据,这样所有的请求都会到达数据库,可能数据库就会崩溃。
这就是缓存穿透带来的危害。
解决方案:
-
缓存空对象
缓存空对象是一种简单暴力的处理方案。思路:
客户端请求redis缓存,redis缓存中没有,就去请求数据库,数据库也没有,为了让该请求停止,数据库将空值缓存到redis中,下次该请求再来访问,在Redis缓存中就可以命中。即使是一个空值。这样就不会请求数据库了。
优点:实现简单,维护方便
缺点:
-
额外的内存消耗:不去做识别就直接存入缓存,如果有大量线程发起空请求,那么内存空间就会爆满,造成额外的内存消耗。(解决方案:在缓存空值时设置较短的超时时间TTL,在该有效时间内内存有效,可以保护数据库,再过时后,这些垃圾数据就会被清理)
-
可能存在短期的不一致性。现在用户请求一个ID,但ID不在,按照缓存空对象方案,就会存入该ID值的空对象,但在之后,在数据库中真的向该ID中插入了一条商铺的数据,而此时客户端来查询缓存命中,是一个空对象,但是数据库实际是有这个数据的,这就造成了一致性问题。只有当TTL过期后,客户端才可以访问到数据。(解决方案:通过控制超时时间在一定程度上可以缓解。)
-
布隆过滤(类似于算法)
原理:在客户端和redis之间加入了一层拦截器,叫做布隆过滤器,在客户端发起请求时,会先访问布隆过滤器,查询该数据存在不存在,如果不存在,就直接拒绝请求,如果存在,放行,让其访问缓存。后续逻辑一致
如图所示:
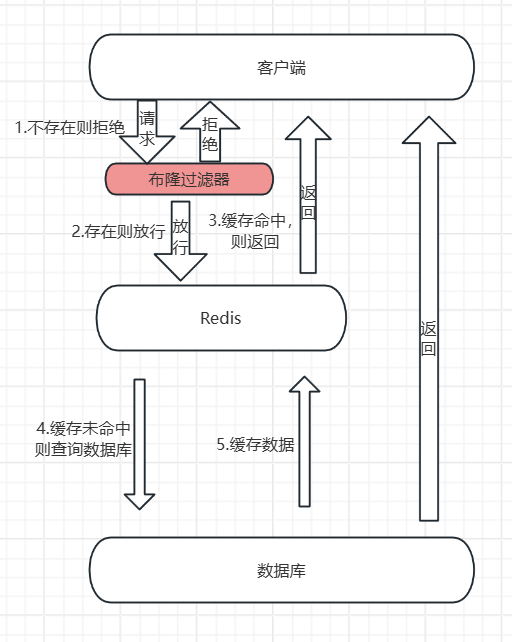
布隆过滤器如何得知数据是否存在?
布隆过滤器可以简单理解成一个bit数组,里面存的是二进制位,当我们要去判断数据库中数据是否存在时,布隆过滤器将数据库中的数据基于某一种哈希算法计算出哈希值,然后再将这些哈希值转换成二进制位,保存在布隆过滤器中,而后去判断数据是否存在时就是判断对应的位置是零还是一,以此来判断数据是否存在,这种存在与否是概率上的统计,并不是百分百的准确。还是有一定的穿透风险的。
优点:
-
内存占用少,没有多余key(使用二进制位的形式保存数据,因此空间占用十分小)
缺点:
-
实现复杂
-
存在误判可能
在Redis中提供了bitMap这种数据类型,自带一种布隆过滤的实现可以帮助我们简化开发
因此我们在实际开发中一般使用缓存空对象这种方案。
案例展示:解决商铺查询的缓存穿透问题
原实现逻辑:
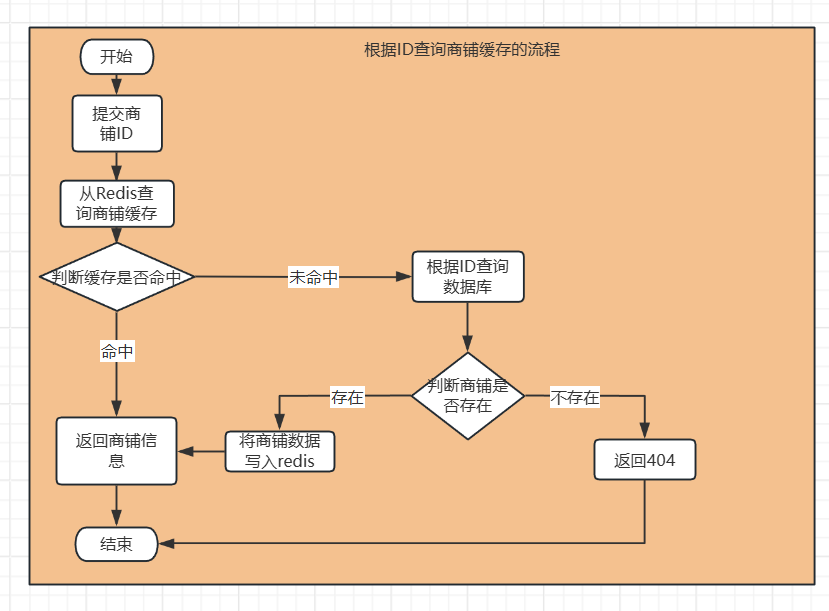
发现问题:在查询数据库判断商铺是否存在时,不存在直接返回404状态码,如果大量线程并发访问不存在的商铺,则就会造成缓存穿透的问题。
修改逻辑:
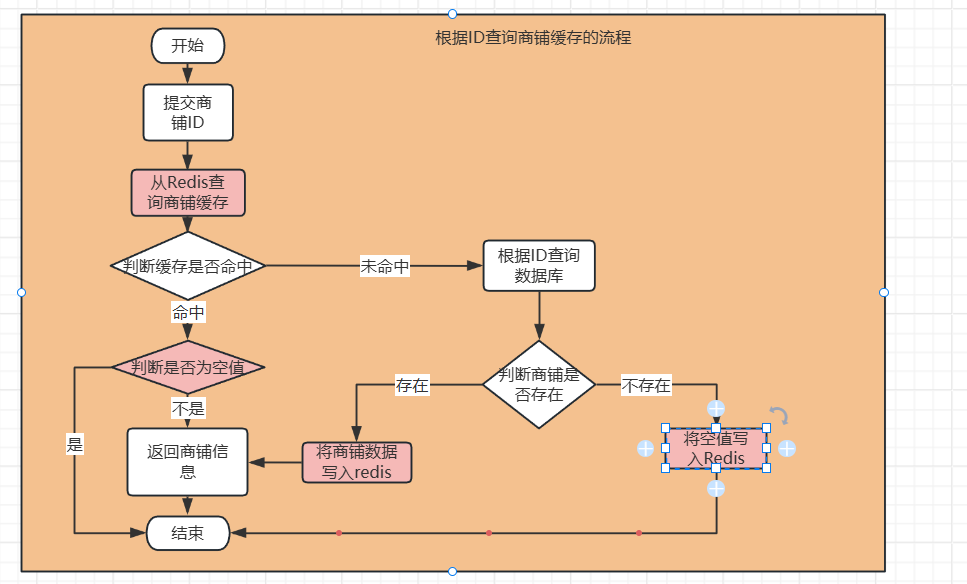
在判断商铺不存在时将空值写入Redis缓存,但此时就会出现新的问题,当我们redis命中时就不清楚是返回的商铺信息,还是空值,因此还需要在判断缓存命中后在判断一次,判断是否为空值,如果为空,直接结束。
如图所示:
代码实现:
@Overridepublic Result queryById(Long id) {//1.从redis中查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY+id);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)){// 3.存在,直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}// 4.判断命中的是否是空值if (shopJson != null){// 返回错误信息return Result.fail("店铺不存在");}// 4.不存在,根据id查询数据库Shop shop = getById(id);if (shop == null) {//将空值返回redisstringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 5.不存在,返回错误return Result.fail("店铺不存在");}// 6.存在,写入redisstringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7.返回return Result.ok(shop);}测试结果:

查看redis数据库:

小结:
缓存穿透的根本原因:客户端查询数据在缓存与数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力。
解决方案: 缓存空对象,布隆过滤。
这两种方案属于被动方案,属于缓存穿透已经发生,想办法来弥补。
我们也可以采取一些主动的措施来解决缓存穿透:
-
增强ID的复杂度,避免被猜测ID规律
-
做好数据的基础格式校验
-
加强用户权限校验
-
做好热点参数的限流(对用户进行限流等等)
缓存雪崩
缓存雪崩是指同一时间段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,给数据库带来巨大压力,可能导致数据崩溃。
正常请求时大部分到达redis缓存后直接返回,少数请求到达数据库。
第一种情况:如果一瞬间大量的key失效比如过期,同一时间大量请求就会直接到达数据库,这时就可能导致数据库压力过大导致出现服务宕机。
第二种情况:Redis服务直接宕机,相当于所有的key全部失效,搜无法访问了,客户端所有的请求都会直接到达数据库,相当于原始状态。可能导致服务宕机
解决方案:
-
给不同的key的TTL添加随机值(针对大量key同时失效):平时在做缓存时,又是为了做缓存的预热,可能提前将数据库的数据导入缓存,即批量导入,因为是同一时刻导入的,数据的有效期可能一致,就可能出现以后时间一到,一批数据直接失效的情况,就会出现缓存雪崩。因此在做缓存预热批量导入数据时,可以设置TTL时设置一个随机数范围,这样过期的时间就分散在一个时间段内了,就不会一起失效。导致缓存雪崩。
-
利用Redis集群提高服务的可用性(针对redis服务宕机):为了尽可能的避免Redis的宕机,就要提高整个Redis的高可用性,想要提高Redis的高可用性,就必须借助于redis的集群,(redis的哨兵机制,可以实现对服务的监控),先搭建Redis集群形成主从,如果其中有一个机器宕机比如主机器宕机,哨兵会自动地从从机中选出一个替代原来的主,这样就可以保证redis一直能够正常对外提供服务,主从还可以实现数据同步,也不会导致数据的丢失,这样就可以在很大程度上保证Redis的高可用性。
-
给缓存业务添加降级限流策略(针对一些罕见的事故,比如服务器挂了,整个机房被烧没了)这时redis集群全部失效,如何保证可用性,此时就可以给服务添加一些降级限流策略:提前做好一些容错处理,当发现Redis出现故障时,应该及时地去做服务降级,比如快速失败拒绝服务,而不是让请求继续访问数据库。这样做的结果就是牺牲部分服务,但保证了整个数据库的健康
-
给业务添加多级缓存:用于保证数据库安全,多级缓存是指缓存使用的场景是多种多样的,它不仅仅说可以在应用层添加,浏览器也可以添加缓存,浏览器缓存一般是缓存静态资源,对于一些从数据库查询的动态数据是无法做缓存的,我们可以在反向代理服务器Nginx层面去做缓存,Nginx缓存未命中再去找redis缓存,redis缓存未命中还可以到达jvm(内存模型),还可以在JVM内部建立本地缓存,最后是数据库。即在多个层面建立缓存,这样就算是Redis这一环没了,还有很多别处的缓存去弥补。
拓展知识:redis集群中主从如何保证数据的一致性?
分析:主从之间的数据如何保持同步的?他们的同步流程是怎样的?
同步的流程主和从都会发起,当主写了数据之后会异步的同步给从。这个逻辑比较简单。
但从是怎样定时同步主的数据呢?
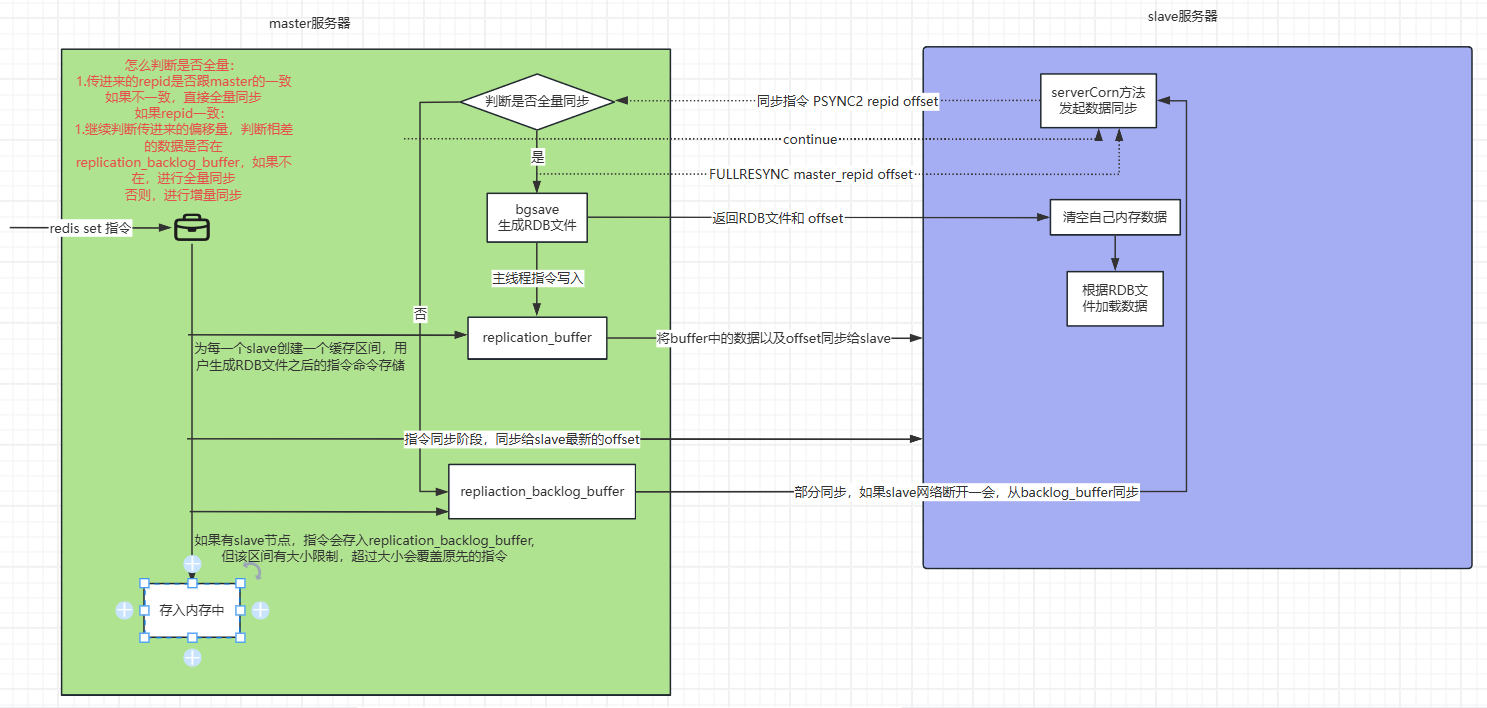
首先有两个服务器:主从节点master和slave服务器。
首先slave服务器会通过servercron()方法发起同步请求,这个方法是一个定时任务 默认10毫秒执行一次,执行时会传出repid和offset。
repid:Redis每一个实例都会有这样的一个服务ID,offset是偏移量:同步的进度。
master服务器接受到请求后,会先去做一个判断,判断是否要全量同步(把当前服务器所有数据同步给slave),
如何判断是否全量:
首先回去根据他传进来的服务ID跟masterID是否一致?
因为我的slave传过来的repid是我原来同步的masterID。如果不一致,说明是首次到master服务器同步数据,肯定要全量同步(这时master服务器会通过后台(bgsave指令)生成一个RDB文件,并将RDB文件以及offset(偏移量)返回给slave服务器,slave拿到RDB文件后,会将自己的数据清空,根据RDB文件加载,并且拿到当前的一个偏移量),
如果repid一致,则继续判断传过来的offset,判断相差的数据是否能在积压缓存中找到,如果找不到,则需要全量同步(流程同上),如果能找到,则进行增量同步
偏移量在master服务器中如何查询自己想要的数据?
偏移量不是从master服务器中的内存去寻找数据的,这样性能太差,而Redis数据库的每一个指令都会去记录一个积压缓存replication_backlog_buffer,这个缓存就是我每写一个数据,都会放在这个积压缓存中,当从来同步数据时,根据offset来到replication_backlog_buffer中寻找。
bgsave不会阻塞指令执行,在bgsave指令生成RB文件以后,master还会继续写新的数据,这些新的数据并没有同步给slave,这时该怎么处理?
master会为每一个slave创建一个缓存区间,用来保存RDB文件生成文件以后的一些新的指令,叫做replication_buffer,再将其中的数据以及offset同步给slave。当slave加载完BG save以后,会拿到这些新的指令。
所以,当master生成RDB文件以后,新的指令也会同步给从。
如下图所示:
以上就是缓存穿透与缓存雪崩的详情以及解决方案。希望对大家有所帮助。