【掌握文件操作】(下):文件的顺序读写、文件的随机读写、文件读取结束的判定、文件缓冲区
目录
四、文件的顺序读写
(八)fwrite
(九)fread
五、对比函数:scanf/fscanf/sscanf和printf/fprintf/sprintf
(一)sscanf
(二)sprintf
(三)sscanf和sprintf的代码实现:
(四)表格
六、文件的随机读写
(一)fseek
(二)ftell
(三)rewind
七、文件缓冲区
(一)介绍
(二)fflush
八、更新文件
结尾
🔥个人主页:艾莉丝努力练剑
🍓专栏传送门:《C语言》
🍉学习方向:C/C++方向
⭐️人生格言:为天地立心,为生民立命,为往圣继绝学,为万世开太平

前言:前面几篇文章介绍了c语言的一些知识,包括循环、数组、函数、VS实用调试技巧、函数递归、操作符、指针、字符函数和字符串函数、C语言内存函数、数据在内存中的存储、结构体、联合和枚举、动态内存管理等,在这篇文章中,我将继续开始介绍文件操作的一些重要知识点!对文件操作感兴趣的友友们可以在评论区一起交流学习!
四、文件的顺序读写
(八)fwrite
代码原型:
size_t fread(void* ptr, size_t size, size_t count, FILE* stream);三板斧——
功能:fwrite函数用于将数据块写入stream指向的文件流中,是以二进制的形式写入的;
参数:fwrite函数有四个参数——
ptr:指向要写入的数据块的指针;
size:要写入的每个数据项的大小(以字节为单位);
count:要写入的数据项的数量;
stream:指向FILE类型结构体的指针,指向了要写入数据的文件流;
返回值:返回实际写入的数据项的数量。如果发生错误,则返回值可能小于count。
使用注意事项:
1、需要包含<stdio.h>头文件;
2、在使用fwrite()之前,需要确保文件已经以二进制形式可写方式打开;
3、fwrite()通常用于二进制数据的写入,如果写入文本数据,要谨慎处理换行符和编码问题。
代码演示:
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>struct S
{char name[20];int age;float score;
};int main()
{struct S s = { "zhangsan",20,95.5f };FILE* pf = fopen("data.txt", "wb");if (pf == NULL){perror("fopen");return 1;}//写文件fwrite(&s, sizeof(struct S), 1, pf);fclose(pf);pf = NULL;return 0;
}上面我们演示的是写入一个结构体类型的数据到文件中去,写数据的时候我们什么类型的数据都可以写,这里我们也可以写一个整型数组的数据:
#include<stdio.h>int main()
{int data[] = { 1,2,3,4,5 };//打开文件FILE* fp = fopen("data.txt", "wb");//检查文件是否成功打开if (fp == NULL){perror("fopen");return -1;}//将数据写入文件if (fwrite(data, sizeof(int), 5, fp) != 5)//这里data是数组名,就不用取地址了//sizeof(int)写一个数据是整型,这里写5个//!= 5这里是如果不是5,perror("fopen")会报错{perror("fopen");return -1;}//关闭文件fclose(fp);fp = NULL;return 0;
}(九)fread
函数原型:
size_t fread(void* ptr, size_t size, size_t count, FILE* stream);三板斧——
功能:函数用于从stream指向的文件流中读取数据块,并且将其存储到ptr指向的内存缓冲区中。
参数:
ptr:指向内存区域的指针,用于存储从文件中读取的数据;
size:要读取的每个数据块的大小(以字节为单位);
count:要读取的数据块的数量;
stream:指向FILE类型结构体的指针,指定了要从中读取数据的文件流。
返回值:返回实际读取的数据块的数量。
使用注意事项:
1、需要包含<stdio.h>头文件;
2、在使用fread()之前,需要确保文件已经以二进制可读方式打开;
3、ptr指向的内存区域必须足够大,一遍存储指定数量和大小的数据块;
4、如果fread()成功读取了指定数量的数据块,则返回值等于count;如果读取数量少于count,则可能已经到达文件末尾或者发生了错误;
5、在二进制文件读取时,fread()是常用的函数,但对于文本文件读取,通常使用fgets()或者fscanf()。
代码演示:
#include<stdio.h>struct S
{char name[20];int age;float score;
};int main()
{struct S s = { 0 };//打开文件FILE* pf = fopen("data.txt", "rb");//检查文件是否成功打开if (pf == NULL){perror("fopen");return -1;}//读文件size_t r = fread(&s, sizeof(struct S), 1, pf);if (r != 1){//1.遇到了文件末尾if (feof(pf)){printf("遇到了文件末尾:");}//2.读取发生了错误else if (ferror(pf)){printf("读取过程中发生了错误:");}}else{printf("%s %d %f\n", s.name, s.age, s.score);}//关闭文件fclose(pf);pf = NULL;return 0;
}到这里,我们文件的顺序读写部分就全部介绍完了,
五、对比函数:scanf/fscanf/sscanf和printf/fprintf/sprintf
1、scanf/printf:针对标准输入/标准输出的格式化的输入函数和输出函数;
2、fscanf/fprintf:针对所有输入流/所有输出流的格式化的输入函数和输出函数;
3、那sscanf和sprintf呢?我们接下来就来介绍一下这两个函数——
(一)sscanf
代码原型:
int sscanf(const char* str, const char* format, ...);三板斧——
功能:从字符串中读取格式化数据,它与scanf类似,但输入源是内存中的字符串而非控制台或者文件。常用于解析字符串中的结构化数据(比如提取数字、分割文本等等)。
参数:
str:要解析的源字符串(输入数据来源);
format:格式化字符串,定义如何解析数据(比如%d、%f、%s等等);
...:可变参数列表,提供存储数据的变量地址(需要与格式字符串中的说明符相匹配)。
返回值:
(1)若成功:返回成功解析并且赋值的参数数量(非负值);
(2)若失败或者未匹配任何数据:若输入结束或者解析失败,返回EOF(通常为-1)。
(二)sprintf
我们对比一下printf和sprintf,printf其实是把格式化的数据打印到屏幕(标准输出)上去,sprintf和printf类似,只不过输出目标不再是控制台和文件,而是用户指定的一个内存缓冲区。
先观察一下sprintf的代码原型:
int sprintf(char* str, count char* format, ...);三板斧——
功能:将格式化数据写入字符数组(字符串)。它类似于printf,但输出目标不是控制台或者文件,而是用户指定的一块内存缓冲区。常用于动态生成字符串、拼接数据或数据格式。简单理解就是将格式化的数据直接转换成一个字符串。
参数:
str:指向字符数组的指针,用于存储生成的字符串(需要确保足够大以防止溢出);
format:格式化字符串,定义输出格式(如%d、%f、%s等);
...:可变参数列表,提供与格式字符串对应的数据。
返回值:
(1)成功时,返回写入buffer(buf)的字符数(不包括结尾的空字符\0);
(2)失败时,返回负值。
(三)sscanf和sprintf的代码实现:
#include<stdio.h>struct S
{char name[20];int age;float score;
};int main()
{struct S s = { "zhangsan",20,95.5 };char buf[100] = { 0 };sprintf(buf, "%s %d %f", s.name, s.age, s.score);//zhangsan 95.500000 20printf("%s\n", buf);struct S t = { 0 };sscanf(buf, "%s %f %d", t.name, &(t.score), &(t.age));printf("%s %f %d", t.name, &(t.score), &(t.age));return 0;
}(四)表格
| 函数类型 | 作用 |
| scanf | 针对标准输入(stdin)的格式化的输入函数 |
| printf | 针对标准输出(stdout)的格式化的输出函数 |
| fscanf | 针对所有输入流(可以是文件流,也可以是stdin)的格式化的输入函数 |
| fprintf | 针对所有输出流(可以是文件流,也可以是stdout)的格式化的输出函数 |
| sscanf | 从字符串中提取格式化的数据 |
| sprintf | 简化格式化的数据转换成字符串 |
六、文件的随机读写
(一)fseek
作用:fseek函数是根据文件指针的位置和偏移量来定位文件指针(文件内容的光标)。
函数原型:
int fseek(FILE* stream, long int offset, int origin);注:
offset:偏移量;
origin:起始位置——不是文件的起始位置,而是指你从哪一个位置开始算文件的偏移量;
origin是有固定的值的,总共有三种可能性,见下面的截图。
我们在C库-C++参考这个网站检索一下:


代码演示:
#include<stdio.h>int main()
{FILE* pf = fopen("data.txt", "w");if (pf == NULL){perror("fopen");return 1;}//写文件fseek(pf, -3, SEEK_END);fputc('x', pf);fclose(pf);pf = NULL;return 0;
}我们这样写:
#include<stdio.h>int main()
{FILE* pf = fopen("data.txt", "w");if (pf == NULL){perror("fopen");return 1;}fputs("abcdefghi", pf);//写文件fseek(pf, -3, SEEK_END);fputc('x', pf);fclose(pf);pf = NULL;return 0;
}假如我们要算一下相较于起始位置的偏移量:
//算一下相较于起始位置的偏移量
#include<stdio.h>int main()
{FILE* pf = fopen("data.txt", "w");if (pf == NULL){perror("fopen");return 1;}fputs("abcdefghi", pf);//写文件fseek(pf, -3, SEEK_END);fputc('x', pf);int ret = ftell(pf);printf("%d\n", ret);fclose(pf);pf = NULL;return 0;
}
(二)ftell
作用:ftell函数是返回文件指针相对于起始位置的偏移量。
函数原型:
long int ftell(FILE* stream);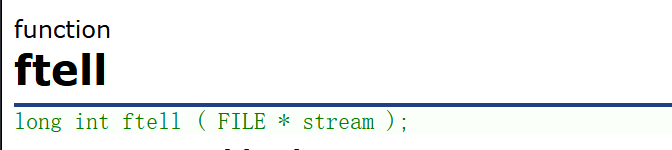
代码演示:
假如我们要算文件中一共有几个字符,可以这样写:
//算文件里面一共有几个字符
//巧妙利用特点,算出文件的长度
#include<stdio.h>int main()
{FILE* pf = fopen("data.txt", "w");if (pf == NULL){perror("fopen");return 1;}fputs("abcdefghi", pf);//写文件fseek(pf, -3, SEEK_END);fputc('x', pf);int ret = ftell(pf);printf("%d\n", ret);fclose(pf);pf = NULL;return 0;
}
(三)rewind
作用:rewind函数是让文件指针的位置回到文件的起始位置。
函数原型:
void rewind(FILE* stream);
代码演示:
#include<stdio.h>int main()
{FILE* pf = fopen("data.txt", "w");if (pf == NULL){perror("fopen");return 1;}fputs("abcdefghi", pf);//写文件fseek(pf, -3, SEEK_END);fputc('x', pf);fseek(pf, 0, SEEK_END);int ret = ftell(pf);printf("文件的字节数:%d\n", ret);rewind(pf);//文件指针就回到文件的初始位置了//等价于fseek(pf,0,SEEK_SET);fclose(pf);pf = NULL;return 0;
}七、文件缓冲区
(一)介绍
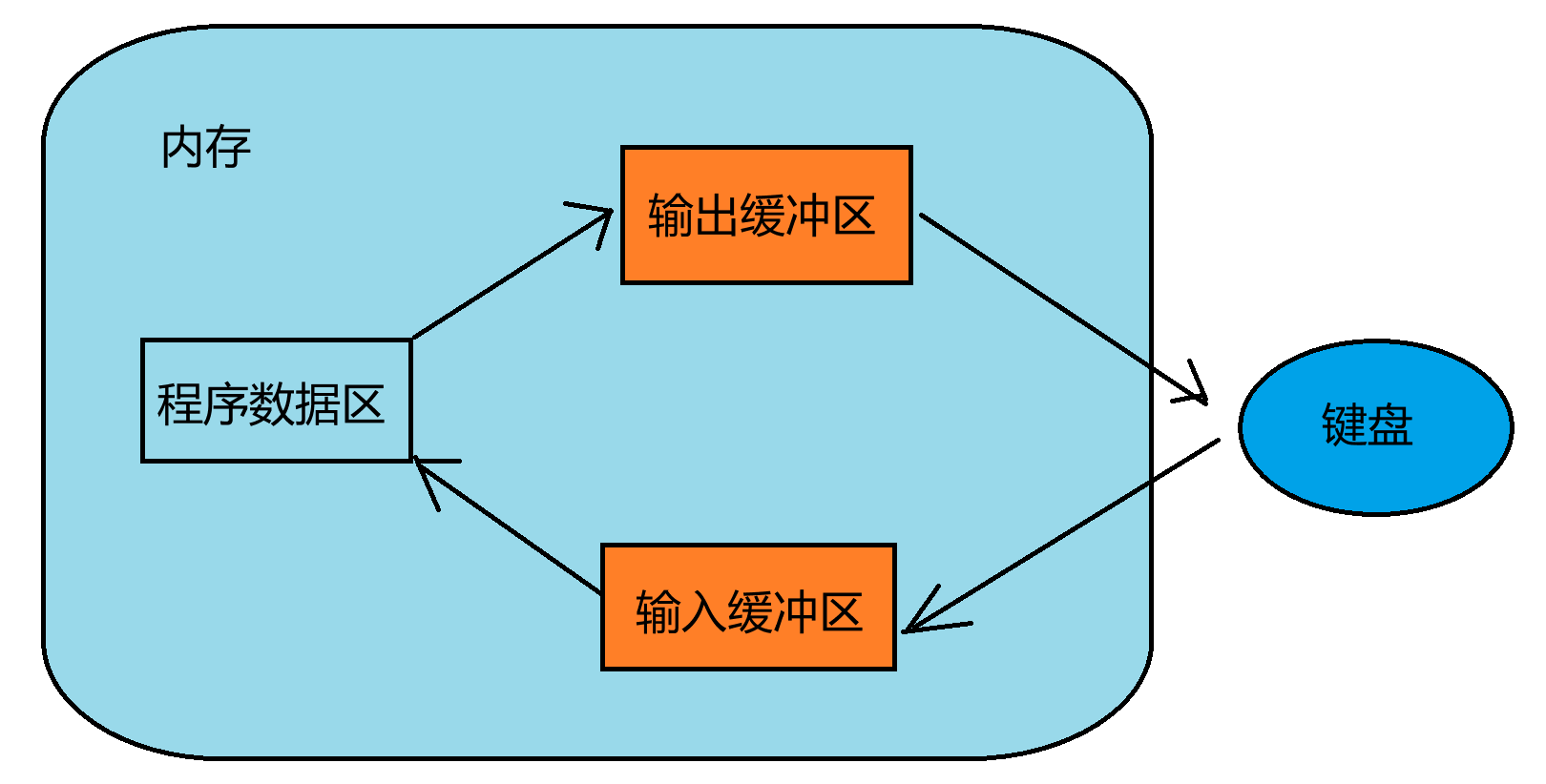
ANSI C标准采用“缓冲文件系统”处理数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区之后才会一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个将数据送到程序数据区(程序变量等)。缓冲区大小根据C编译系统决定。
(二)fflush
函数原型:
int fflush(FILE* stream);功能:强制刷新参数stream指定流的缓冲区,确保数据写入底层设备;
(1)对输出流:将缓冲区中未写入的数据立即写入文件;
(2)对输入流: 行为由具体实现决定,非C语言标准行为(可能清空输入缓冲区)
(3)参数为NULL时:刷新所有打开的输出流。
参数:
stream:指向文件流的指针(如stdout、文件指针等等)。
返回值:成功返回0,失败返回EOF。
注意事项:
1、仅对输出流或者更新流(最后一次操作为输出)有明确刷新行为;
2、输入的刷新行为不可移植(比如清空输入缓冲区是非标准特性的);
3、程序正常终止(exit)或调用fclose时会自动刷新,但程序崩溃时缓冲区数据可能丢失。
代码演示:
//文件缓冲区
#include<stdio.h>
#include <windows.h>//VS2022 WIN11环境测试int main(){FILE* pf = fopen("test.txt", "w");fputs("abcdef", pf);//先将代码放在输出缓冲区printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n");Sleep(10000);printf("刷新缓冲区\n");fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)//注:fflush 在高版本的VS上不能使用了printf("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了\n");Sleep(10000);fclose(pf);//注:fclose在关闭文件的时候,也会刷新缓冲区pf = NULL;return 0;
}
我们由此可以得出一个结论:
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。如果不做的话,可能会导致读写文件的问题。
八、更新文件
在前面那篇的【文件打开方式】的表格中,有三种文件打开方式值得注意:“r+”、“w+”、“a+”。
前文的链接放在这儿(当然结尾处也放了):【掌握文件操作】(上):二进制文件和文本文件、文件的打开和关闭、文件的顺序读写
我们接下来就通过表格的形式了解一下这三种打开方式:
| 行为 | "r+" | "w+" | "a+" |
| 解释 | 可读/可写 | 可读/可写 | 可读/可写 |
| 文件不存在 | 打开失效 | 自动创建新文件 | 自动创建新文件 |
| 文件存在时 | 保留内容 | 清空内容 | 保留内容 |
| 初始文件指针位置 | 文件开头 | 文件开头 | 文件末尾 |
| 写入是否覆盖原有数据 | 是(可定位覆盖) | 是(内容已清空,从头写入) | 否(默认是在文件末尾写数据) |
| 典型用途 | 修改文件部分内容 | 创建新文件或者完全重写旧文件 | 在文件末尾追加数据,比如记录日志 |
关键要点:
1、在写完文件后,要继续读文件的时候,在读取之前一定是要使用fflush()刷新文件缓冲区,或者使用fseek()、rewind()重新定义文件指示器的位置;
2、读完文件后,需要继续写文件之前——在写文件之前——使用fseek()、rewind()重新定位文件指示器的位置。
代码演示:
//文件更新
#include<stdio.h>int main()
{FILE* pf = fopen("test.txt", "w+");if (pf == NULL){perror("fopen");return 0;}//写文件fputs("abcdefghi", pf);fflush(pf);//刷新缓冲区//读文件fseek(pf, 0, SEEK_SET);int ch = fgetc(pf);printf("%c\n", ch);//abcdefghifseek(pf, 2, SEEK_CUR);fputs("xxx", pf);//abcxxxghifclose(pf);pf = NULL;return 0;
}结尾
往期回顾:
【掌握文件操作】(上):二进制文件和文本文件、文件的打开和关闭、文件的顺序读写
【动态内存管理】深入详解:malloc和free、calloc和realloc、常见的动态内存的错误、柔性数组、总结C/C++中程序内存区域划分
【详解自定义类型:联合和枚举】:联合体类型的声明、特点、大小的计算,枚举类型的声明、优点和使用
【自定义类型:结构体】:类型声明、结构体变量的创建与初始化、内存对齐、传参、位段
结语:本篇文章就到此结束了,本文为友友们分享了文件操作相关的一些重要知识点,如果友友们有补充的话欢迎在评论区留言,下一篇博客,我们将介绍编译和链接的内容,敬请期待,感谢友友们的关注与支持!