图神经网络在信息检索重排序中的应用:原理、架构与Python代码解析
现代信息检索系统和搜索引擎普遍采用两阶段检索架构,在人工智能应用中也被称为检索增强生成(Retrieval-Augmented Generation, RAG)。在初始检索阶段,系统采用高效的检索方法,包括词汇检索算法(如BM25)或密集嵌入检索器(基于近似最近邻算法),为给定查询获取初始候选文档或段落集合。这一阶段优先考虑检索速度而非完整性,因此常常返回包含噪声或不相关的结果,可能导致下游任务产生错误答案或幻觉问题。第二阶段即重排序过程,通过重新计算候选文档的相关性分数并生成更精确的排序列表来优化检索结果。传统重排序方法通常使用强大的语言模型(交叉编码器或大型Transformer模型)独立评估每个查询-文档对,虽然计算成本更高,但显著提升了检索精度。

但是当面对复杂信息需求或需要上下文知识时,传统方法面临重大挑战。基于大型语言模型的重排序器难以直接整合结构化知识(如知识图谱中的关系信息)或多个检索文档间的交互关系。这一局限性催生了基于图的重排序这一新兴研究方向。该方法利用图表示和图神经网络来挖掘检索项目间或查询与内容间的关联性。其核心思想是将检索得到的文档以及相关上下文信息(实体、术语等)建模为图结构中的节点,边则表示有意义的关系,包括内容相似性、语义相关性或知识连接。随后,图神经网络或图算法在此结构上传播信息,计算出考虑结果全局结构的改进相关性分数,而非仅仅孤立地评估每个文档。通过整合结构化上下文,基于图的重排序旨在克服密集检索器和交叉编码器的局限性,例如发现初始检索中遗漏的相关文档,或通过整合有助于阐明查询意图的背景知识来提升检索效果。
本文将深入探讨Zaoad等人于2025年发表的论文《Graph-Based Re-ranking: Emerging Techniques, Limitations, and Opportunities》中提出的基于图的重排序方法,并详细介绍其实现过程。我们将阐述使用图进行重排序的动机、基于图的重排序器的通用架构以及论文中强调的创新方法。此外,我们将讨论这些基于图的方法如何改进传统密集检索,并展示相关性能基准测试结果。最后,我们将分析这个快速发展的信息检索领域的当前局限性和未来发展方向。
基于图的重排序工作流程
从系统架构角度看,基于图的重排序通过在检索和最终排序之间引入图构建和图神经网络推理步骤,扩展了标准的两阶段信息检索流程。该论文概述了典型的基于图的重排序工作流程,包含以下关键步骤:
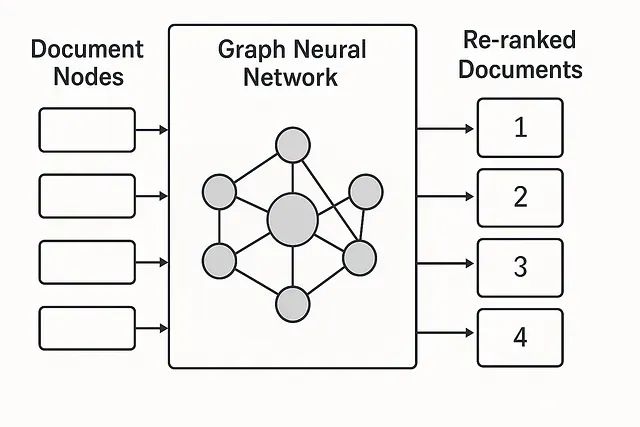
初始检索阶段,输入查询通过检索器(如BM25或密集向量检索器)处理,返回前n个候选文档或段落,产生基于粗略相关性的初始排序列表。编码阶段,查询和检索文档由编码器(通常基于Transformer架构或嵌入模型)处理,获得捕获查询和内容语义特征的向量表示。相关性匹配阶段,相关性匹配器计算查询嵌入与各文档嵌入间的相似性分数,这些分数用于构建连接查询与文档或文档间的图结构边。换言之,我们构建一个以查询和文档为节点的图,边表示某种形式的相关性或交互关系,例如边权重可以是两个文档向量间的余弦相似度,或当相似度高于阈值时的二元连接。
生成的图及其编码的节点和加权边关系被输入到基于图的重排序器模型中。这通常是一个能够在边上传播信息的图神经网络。例如图神经网络可以通过聚合图中邻居节点(可能包括查询节点或其他文档)的特征来迭代更新每个文档的节点表示。在某些情况下,基于图的模型可能包含多个组件,例如图神经网络与神经评分层的结合。最终重评分阶段,图模型为每个候选文档生成相关性分数,此时不仅考虑孤立的查询-文档相似性,还考虑相关文档或知识连接的上下文信息。基于这些分数,系统输出重排序后的文档列表作为最终结果。
该工作流程在论文图1中得到详细说明,其中查询被编码,初始检索结果用于构建查询和文档节点的图(边基于相似性),然后图神经重排序器计算新的相关性分数,从而生成重新排序的列表。其直观理念是,通过将检索候选表示为图结构,重排序器能够利用相似文档簇、不同子主题或跨文档的逻辑推理链等模式,这些是标准逐点重排序器可能忽略的重要信息。
图构建策略:文档级与实体级图表示
在基于图的重排序中,如何从查询和检索文档构建图结构是一个关键的设计决策。该综述论文指出,当前方法已探索了多种图表示方式,大致可分为两个主要类别:
文档级图表示中,节点代表完整的文档或段落,边表示文档间的关系。这些关系通常基于内容相似性或其他信号,如引文链接或聚类关系。相似性图是一个简单的文档图示例,其中每个检索文档作为一个节点,边连接具有高文本相似性的文档(通常通过嵌入余弦相似度衡量)。另一个例子是连接共享特定关键词或主题的文档。通过使用文档级图,图神经网络重排序器可以强化相关文档簇获得更高的相关性,基于这样的假设:如果多个文档彼此相似且其中一个相关,那么其他文档也可能相关。文档图也可以从外部结构构建,例如为集合中的所有文档预先计算语料库范围的相似性图,将每个文档连接到其最近邻居,然后针对特定查询的顶部结果对此图进行修剪或子集化。
实体级图表示中,节点代表更细粒度的单元,如从文档和查询中提取的特定实体、概念甚至术语,边表示这些实体间的语义或基于知识的关系。知识图谱的使用是一个突出例子:节点是查询或文档中提到的实体(人物、地点、概念),边是来自外部知识库的关系(例如医学概念间的"symptom_of"关系)。通过共享实体和已知关系连接检索文本,重排序器可以注入背景知识并在该上下文中评估相关性。另一种术语级方法是在文档与其包含的关键术语或实体间创建二分图,从而建模哪些文档共享重要术语。
一些重排序方法甚至结合这两个层面,创建多层图或使用一个层面为另一个层面提供信息。该综述强调,构建正确的图表示至关重要,因为选择包含哪些节点和边会极大影响模型性能,它决定了图神经网络可以获得哪些关系信息。由于这是一个新兴领域,研究人员一直在针对每个任务发明自己的图构建技术,例如选择连接多少个邻居,如何通过相似性分数为边加权,是否将查询作为节点包含在内等等。这种缺乏标准化的现状使得直接比较方法变得困难,该论文建议社区应朝着通用基准和图构建最佳实践方向发展。
构建图后,我们需要初始化节点特征。通常,每个文档节点可能以来自文本编码器的特征开始,如文档嵌入或查询与文档嵌入的组合。一些方法用权重(如相似性分数)初始化边,或将这些权重作为特征合并。有了图和初始特征后,我们便应用图神经网络或相关算法进行处理。
图神经网络重排序器:架构设计与方法分析
图神经网络是许多基于图的重排序模型的核心组件。图神经网络通过消息传递机制,聚合来自邻居节点的信息来迭代更新每个节点的表示,从而将关系上下文注入到表示中。经过多层图神经网络处理后,每个文档节点的嵌入不仅编码文档内容,还编码其与图中其他文档或实体的关系信息。随后,这种丰富的嵌入可用于计算最终的相关性分数,例如通过评分函数,甚至是将节点嵌入映射到相关性标量的简单线性层。
不同的重排序模型在架构设计方面存在差异。该综述论文根据传统信息检索排序策略(逐点、逐对或逐列表重排序)以及图中建模的信息类型对方法进行分类。下面我们将讨论每个类别中基于图的重排序器的关键示例,重点介绍其独特的架构和创新特点。
逐点基于图的重排序方法
逐点重排序意味着每个文档的相关性独立评估,尽管可能融入来自图的上下文信息。图结构用于增强每个文档的特征或分数,但最终的相关性分数仍是单个文档与查询的函数。许多图重排序器遵循此策略,最终为每个文档生成独立的分数。
PassageRank是2020年提出的一种早期针对段落的图重排序方法。PassageRank构建有向图,其中每个段落作为节点,边连接段落,权重等于其内容相似性。该方法在此图上应用PageRank算法的变体来计算每个段落的重要性分数,其假设是连接到许多其他相关段落的段落本身也可能相关。这些基于图的分数与基于BERT的排序器结合使用以产生最终排序。本质上,PassageRank引入了使用图中心性作为重排序特征的思想。
**图自适应重排序(GAR)**于2022年提出,解决了两阶段检索的重要局限性。重排序器只能对第一阶段检索到的文档进行重新评分,如果明显相关的文档在初始检索中被遗漏,它就永远没有机会被发现。GAR通过使用预先计算的文档相似性图迭代扩展候选集来解决这个召回率限制。GAR假设存在语料库图,其中每个文档是节点,边连接相似的文档(例如基于嵌入余弦相似度)。该方法从初始的前k个结果开始,然后在多个轮次中重新排序当前池(使用神经重排序器),在语料库图中找到顶部结果的邻居新文档,并将这些邻居添加到池中。通过这样做直到达到预算(要考虑的固定数量的文档),GAR可以引入第一次检索可能遗漏的相关文档,从而提高召回率。这个想法植根于信息检索中的聚类假设:相关文档往往彼此相似,因此如果检索到一个相关项,其在相似性图中的近邻也可能相关。GAR的创新之处在于将此作为重排序中的反馈循环。
文档内聚图由Sarwar和O’Riordan于2021年提出,是另一种逐点方法,侧重于对文档内段落间的内聚性进行建模。该方法指出,如果文档的内部段落都围绕同一主题(高内聚性),则该文档可能与集中的查询更相关,而如果文档的段落跨越多个主题,则其相关性可能较低。他们构建图,其中节点是文档的段落,边捕获段落间的语义相似性。平均边权重定义文档的内聚性分数,该分数可用于重排序。这种方法实质上将图建模引入单个文档内部以评估主题一致性,通过偏好内聚性文档来改进排序。
**图神经重排序(GNRR)**是Di Francesco等人于2024年提出的最新方法,是在初始检索派生的文档级图上使用图神经网络的有力示例。在GNRR中,标准检索器(使用BM25和TCT-ColBERT编码器)为查询获取前1000个文档。然后,通过获取这些顶部候选文档并根据语料库级相似性图(每个文档连接到1000个文档中的最近邻居)将它们连接起来,从而构建查询诱导子图。每个文档节点的初始特征通过文档嵌入和查询嵌入的逐元素乘积设置,以便特征反映查询词在文档中的重要性。随后GNRR在此子图上应用图神经网络:随着图神经网络传播消息,文档与其相似邻居共享信息,有效地在评分中对文档间关系进行建模。同时,GNRR使用前馈网络独立计算每个查询-文档对的相关性分数(类似不考虑邻居的逐点分数)。最后,图神经网络和独立多层感知器的输出被组合(连接和评分)以产生每个文档的最终相关性分数。这种组合确保模型同时考虑文档的独立相关性及其在其他候选文档中的上下文。GNRR表明,以这种方式整合语料库图可以提高排序质量,尤其是在考虑相似文档有助于解决的查询(如多方面查询)上。该方法实质上训练图神经网络,如果文档的邻居看起来也与查询相关,则向上调整该文档的分数,这是一个强大的重排序信号。
其他逐点图神经网络模型引入了独特的图构建或图神经网络架构。例如,G-RAG集成了抽象意义表示图:它将文本解析为语义图,并通过抽象意义表示图中的实体连接查询和文档,然后沿着查询和文档节点间的最短路径聚合特征以优化文档的表示。因此,该模型在最终评分之前使用语义知识图来丰富文档嵌入。另一种方法MiM-LiM构建混合文档图,其中包括文档间链接和文档内(段落级)链接,然后使用图注意力网络传播信息并改进段落排序。IDR(迭代文档重排序)构建以实体为中心的图,如果文档共享实体(人、地点等),则将它们连接起来。该方法在此图上应用图注意力网络来更新实体节点表示,然后通过Transformer将信息融合回文档表示中,有效地在对文档评分之前执行多文档推理。这些变体展示了基于图的重排序的多功能性:通过选择不同的图节点(文档、段落、实体)和边(相似性、共现、语义关系),研究人员可以捕获相关性的不同方面。共同的主题是,所有这些逐点方法最终都为每个文档输出相关性分数,但该分数是由丰富的关系网络提供的。
代码实现:基于图的重排序实践
为了更好地理解基于图的重排序的内部工作原理,我们使用Python和PyTorch Geometric演练一个简化示例。该示例使用BM25和Sentence-BERT进行初始检索和嵌入,模拟基本的检索场景,根据检索文档间的余弦相似性构建图,并应用基于图卷积网络的重排序器。
此示例专为教学目的而设计,突出了核心阶段:初始检索、图构建、图神经网络评分和重排序。在实际系统中,数据集和模型会更复杂,但结构保持相似。
importnumpyasnp
fromrank_bm25importBM25Okapi
fromsentence_transformersimportSentenceTransformer
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
fromtorch_geometric.nnimportGCNConv
fromtorch_geometric.dataimportData
fromsklearn.metrics.pairwiseimportcosine_similarity
importwarnings
warnings.filterwarnings("ignore") # 抑制警告以获得更清晰的输出# 步骤 1:合成语料库和查询
corpus= [ "The theory of relativity was developed by Albert Einstein in 1915.", "Einstein's work on general relativity revolutionized physics.", "Quantum mechanics emerged in the early 20th century with contributions from Planck and Heisenberg.", "Special relativity describes the behavior of objects moving at high speeds.", "The history of physics includes major discoveries by Newton and Einstein."
]
query="What is the theory of relativity?" # 合成相关性标签 (1 = 相关, 0 = 不太相关)
relevance_labels= {0: 1, 3: 1, 1: 1, 4: 0, 2: 0} # 文档 0, 3, 1 相关;文档 4, 2 不太相关# 步骤 2:使用 BM25 进行初始检索
tokenized_corpus= [doc.lower().split() fordocincorpus]
tokenized_query=query.lower().split()
bm25=BM25Okapi(tokenized_corpus)
bm25_scores=bm25.get_scores(tokenized_query)
k=4
top_k_indices=np.argsort(bm25_scores)[::-1][:k]
initial_ranking= [(idx, corpus[idx], bm25_scores[idx]) foridxintop_k_indices]
print("Initial BM25 Ranking:")
foridx, doc, scoreininitial_ranking: print(f"Doc {idx}: {doc} (Score: {score:.4f})") # 步骤 3:编码文档和查询
model=SentenceTransformer('all-MiniLM-L6-v2')
document_embeddings=model.encode(corpus, convert_to_tensor=True, show_progress_bar=False)
query_embedding=model.encode([query], convert_to_tensor=True, show_progress_bar=False)[0]
initial_scores=cosine_similarity(query_embedding.unsqueeze(0).cpu().numpy(), document_embeddings.cpu().numpy())[0]
print("\nInitial Cosine Similarity Scores:")
foridx, scoreinenumerate(initial_scores): print(f"Doc {idx}: {score:.4f}") # 步骤 4:图构建
document_embeddings_np=document_embeddings.cpu().numpy()
selected_embeddings_np=document_embeddings_np[top_k_indices].copy()
print("\nSelected embeddings strides:", selected_embeddings_np.strides)
similarity_matrix=cosine_similarity(selected_embeddings_np)
print("\nSimilarity Matrix:")
foriinrange(k): print([f"{similarity_matrix[i, j]:.4f}"forjinrange(k)]) # 使用 k-NN (2 个邻居) 构建边
edge_index= []
edge_weight= []
added_pairs=set()
foriinrange(k): sim_scores=similarity_matrix[i].copy() sim_scores[i] =-1 # 排除自身top_neighbors=np.argsort(sim_scores)[::-1][:2] # 前 2 个邻居forneighborintop_neighbors: pair=tuple(sorted([i, neighbor])) ifpairnotinadded_pairs: edge_index.append([i, neighbor]) edge_index.append([neighbor, i]) edge_weight.append(similarity_matrix[i, neighbor]) edge_weight.append(similarity_matrix[i, neighbor]) added_pairs.add(pair) ifnotedge_index: print("Warning: No edges formed. Using dummy edge.") # 警告:未形成边。使用虚拟边。edge_index=torch.tensor([[0, 0]], dtype=torch.long).t().contiguous() edge_weight=torch.tensor([1.0], dtype=torch.float)
else: edge_index=torch.tensor(edge_index, dtype=torch.long).t().contiguous() edge_weight=torch.tensor(edge_weight, dtype=torch.float)
print("\nEdges formed:", edge_index.t().tolist()) # 节点特征:将文档嵌入与查询相关性结合起来
node_features= []
foridxintop_k_indices: doc_query_feature=document_embeddings[idx] *query_embedding node_features.append(doc_query_feature.cpu().numpy())
node_features=torch.tensor(node_features, dtype=torch.float) graph_data=Data(x=node_features, edge_index=edge_index, edge_attr=edge_weight) # 步骤 5:用于重排序的图神经网络
classGNNReRanker(nn.Module): def__init__(self, input_dim, hidden_dim): super(GNNReRanker, self).__init__() self.conv1=GCNConv(input_dim, hidden_dim) self.conv2=GCNConv(hidden_dim, hidden_dim) self.scorer=nn.Linear(hidden_dim+input_dim, 1) self.dropout=nn.Dropout(0.5) # 增加 dropoutdefforward(self, data): x, edge_index, edge_weight=data.x, data.edge_index, data.edge_attr x=self.conv1(x, edge_index, edge_weight) x=F.relu(x) x=self.dropout(x) x=self.conv2(x, edge_index, edge_weight) x=F.relu(x) x=self.dropout(x) x=torch.cat([x, data.x], dim=-1) scores=self.scorer(x).squeeze(-1) returnscores # 初始化 GNN 和优化器
input_dim=node_features.shape[1]
hidden_dim=128
gnn_model=GNNReRanker(input_dim, hidden_dim)
optimizer=torch.optim.Adam(gnn_model.parameters(), lr=0.01, weight_decay=1e-4) # L2 正则化# 步骤 6:使用早停法训练 GNN
gnn_model.train()
best_loss=float('inf')
patience=10
patience_counter=0
forepochinrange(200): optimizer.zero_grad() scores=gnn_model(graph_data) loss=0 num_pairs=0foriinrange(k): forjinrange(i+1, k): idx_i, idx_j=top_k_indices[i], top_k_indices[j] # 如果文档 i 比文档 j 更相关,则 score_i 应该 > score_jifrelevance_labels.get(idx_i, 0) >relevance_labels.get(idx_j, 0): loss+=torch.relu(1- (scores[i] -scores[j])) num_pairs+=1elifrelevance_labels.get(idx_i, 0) <relevance_labels.get(idx_j, 0): loss+=torch.relu(1- (scores[j] -scores[i])) num_pairs+=1ifnum_pairs>0: loss=loss/num_pairs else: # 处理没有有效对或所有相关性相同的情况# 后备方案:尝试将分数直接与相关性匹配(不理想,但避免 NaN)target_scores=torch.tensor([relevance_labels.get(top_k_indices[i], 0.0) foriinrange(k)], dtype=torch.float)loss=F.mse_loss(scores, target_scores)loss.backward() optimizer.step() ifepoch%20==0: print(f"Epoch {epoch}, Loss: {loss.item():.4f}") ifloss.item() <best_loss: best_loss=loss.item() patience_counter=0 else: patience_counter+=1 ifpatience_counter>=patience: print(f"Early stopping at epoch {epoch}") break # 步骤 7:使用训练好的 GNN 进行推理
gnn_model.eval()
withtorch.no_grad(): gnn_scores=gnn_model(graph_data) # 步骤 8:将 GNN 分数与初始分数结合
bm25_top_k=torch.tensor([bm25_scores[idx] foridxintop_k_indices], dtype=torch.float)
bm25_top_k=torch.sigmoid(bm25_top_k) # 更平滑的归一化
gnn_scores=torch.sigmoid(gnn_scores) # 更平滑的归一化
final_scores=0.5*bm25_top_k+0.5*gnn_scores # 平衡加权# 步骤 9:最终重排序
reranked_indices=torch.argsort(final_scores, descending=True)
print("\nFinal Re-ranked List:")
forrank, rerank_idxinenumerate(reranked_indices): orig_idx=top_k_indices[rerank_idx] print(f"Rank {rank+1}: Doc {orig_idx}: {corpus[orig_idx]} (Final Score: {final_scores[rerank_idx]:.4f})")

实验结果分析
实验结果表明,BM25检索到了相关和不太相关的文档混合体,纯粹基于词汇重叠进行排名。语义相似性分数显示文档1是相关的,但它在BM25的前4个结果中被遗漏了,这显示了第一阶段检索的局限性。
基于图神经网络的重排序器通过以下方式改进了排名:正确地提升了文档3的排名,这是一个被BM25低估的相关文档;利用构建图中的文档间相似性来传播相关性信号;最终的重排序列表将相关的文档0和3置于顶部,显示了基于图的推理相对于孤立评分的有效性。然而,文档1完全被遗漏了,因为它不在初始BM25的前k个结果中,这强调了需要像GAR中那样的召回感知扩展的重要性。
图神经网络重排序器有效地利用图上下文调整了排名,验证了文档关系有助于改进检索,其效果超出了单独的词汇或嵌入分数所能达到的水平这一观点。本次演练说明了简单的图神经网络如何通过图结构整合文档间的相似性来改进文档排名。虽然我们的语料库很小且是合成的,但其核心原理反映了像GNRR和KGPR这样的基于图的重排序器如何大规模工作。
逐对和逐列表的基于图的重排序
虽然逐点方法独立地对每个文档进行评分(使用图增强特征),但逐对重排序方法在计算排名时明确考虑文档对。通常,逐对重排序器试图预测对于任意两个文档A和B,哪一个应该排名更高,然后将这些逐对偏好聚合成整体排名。图在这种情况下也很自然地出现:我们可以创建锦标赛图或偏好图,其中节点是文档,从A到B的有向边表示"A应该排在B之上"(可能带有一定的权重或置信度)。
DuoRank与PageRank由Gienapp等人于2022年提出,通过对一部分文档对进行抽样比较,解决了逐对重排序的高计算成本问题。该方法首先运行逐点排序器(例如monoT5)将列表修剪为顶部子集,然后对这些子集中的部分对运行逐对模型(duoT5)来估计逐对偏好。为了从这些逐对判断中获得最终排名,他们构建文档的有向图,其中从文档i到文档j的边的权重是i优于j的概率。然后他们在这个图上应用类似PageRank的算法,将其解释为投票图,来计算每个文档的全局分数。本质上,如果文档赢得许多逐对比较(尤其是对强劲的对手),它将有许多出边和很少的入边,从而在图中获得较高的排名分数。这种基于图的逐对结果聚合被发现比简单地计算获胜次数更稳健,尤其是在并非所有对都进行显式比较的情况下。PageRank的使用确保了从部分逐对数据中产生传递的、自洽的排名。
基于大型语言模型的PRP-Graph于2024年提出,是通过提示进行逐对排序的零样本方法的扩展。通过提示进行逐对排序是一种最近的零样本方法,其中提示大型语言模型比较两个文档并决定哪个更相关。Luo等人通过构建PRP-Graph来处理不确定性和传递性,从而扩展了这种方法。在他们的方法中,大型语言模型用于生成初始的偏好有向图,然后图算法迭代地对其进行优化,再次类似于加权PageRank,更新文档分数直到收敛。通过这样做,他们减少了可能来自大型语言模型输出的不一致性,并实现了更稳定的重排序。
SlideGAR列表式图重排序是2025年提出的最新进展,代表了使用图进行列表式重排序的方法。列表式重排序意味着模型同时评估一组文档以产生新的排序,而不是一次一个文档或一对一地进行。SlideGAR建立在早期的GAR方法之上,但将其与列表式排序模型集成。其过程是:首先检索初始文档列表(例如通过BM25),然后使用滑动窗口来获取一批文档(例如一次取前10个)并使用基于大型语言模型的列表式排序器(例如RankT5或RankZephyr)对每个批次进行重排序。在对一个窗口进行重排序后,它将窗口向下移动列表(因此称为"滑动"),并且在每个步骤中还从相似性图中引入相邻文档(就像GAR那样)以考虑新加入者。通过这种方式,SlideGAR确保模型可以考虑文档组之间的联合交互(而不仅仅是成对的),并且还可以从GAR的自适应图扩展中受益。其结果是更具上下文感知能力的重排序,它考虑了文档在列表中的相互关系,从而可能发现多样性或冗余问题。SlideGAR是最早将大型语言模型重排序器和基于图的扩展结合在列表式设置中的尝试之一,显示了该领域的持续创新。
外部知识图谱的整合应用
基于图的重排序最具前景的发展方向之一是将外部知识(例如语义网络或知识图谱)整合到检索过程中。许多信息需求,特别是在生物医学、金融或技术问答等专业领域,如果系统能够感知所涉及的现实世界实体和关系,则可以得到更好的满足。基于图的重排序提供了一种自然的方式来包含这些结构化知识:使用知识图谱中的节点和边作为重排序输入的组成部分。
知识感知交叉编码器由Vollmers等人于2023年提出,是一种通过图结构增强标准交叉编码器的重排序方法。在该方法中,对于每个查询-文档对,研究者从查询和文档中提取实体(使用FLAIR和实体链接器等自然语言处理工具)。随后,他们从大型知识图谱(如Wikidata或领域特定的知识图谱)中检索包含这些实体及其关系的小型子图(例如,连接查询和文档实体的所有三元组,直到某个半径范围内)。这样便产生了一个查询-文档知识子图,其中节点是实体,边是知识图谱关系。该子图被输入到图注意力网络编码器中,该编码器有效地充当文本的"协同编码器":图注意力网络处理链接的实体及其连接,生成捕获查询实体和文档实体如何通过知识图谱在语义上相关联的嵌入。然后,交叉编码器合并这个基于图的嵌入(例如,通过将其与文本特征连接)以输出最终的相关性分数。其结果是一个能够感知背景知识的重排序器,例如能够理解文档X提到了"阿尔伯特·爱因斯坦",他与查询"谁发展了相对论"相关,即使文本没有明确提及这种联系。这种方法在背景知识消除查询歧义或将查询词与文档内容联系起来的场景中显著有助于提升效果。
**知识图谱增强段落排序(KGPR)**是2023年提出的另一个证明了将知识图谱注入重排序效益的模型。该模型的核心是使用基于LUKE的交叉编码器(LUKE是一种预训练为实体感知的Transformer)对查询-段落对进行评分。KGPR的创新之处在于并不孤立地处理段落,而是在查询和段落中查找实体,将它们链接到知识图谱(Freebase),并提取连接这些实体的子图。通常,研究者获取段落中的所有实体,并检索查询实体1跳范围内的任何知识图谱节点和关系。这个子图代表了可能将查询与段落联系起来的上下文知识。该方法不仅对文本进行编码,还引入了知识图谱关系和实体的嵌入,并将它们混合到交叉编码器的输入或嵌入空间中。从本质上讲,KGPR将知识图谱的相关部分"馈送"给重排序器,以便例如,如果查询是关于某种医疗状况而段落使用了相关术语,知识图谱可以弥合这个差距(例如知道"心肌梗塞"与"心脏病发作"指代同一概念)。令人印象深刻的是,KGPR在段落排序基准测试中显示出显著的改进:它在MS MARCO(一个标准数据集)上比强大的monoT5交叉编码器高出3.3%,在TREC深度学习的困难查询上高出10.8%。这些收益突显了添加知识图谱可以显著提高对查询相关性的理解,特别是对于需要背景信息或查询和文档之间措辞不同的困难情况。
知识增强重排序方法示例(KGPR)中,查询和段落首先链接到实体(例如"盆腔痛"、“子宫内膜异位症”),并从知识图谱(Freebase)中提取相关的子图。然后,基于LUKE的交叉编码器将文本信息与图上下文(实体嵌入和关系三元组)集成起来,以产生最终的相关性分数。通过注入结构化知识,即使术语不同,重排序器也能更好地识别段落与查询的相关性。
其他方法采用不同的方式处理知识图谱信息。**知识增强重排序模型(KERM)**于2022年提出,旨在处理原始知识图谱可能嘈杂或过于笼统的问题。KERM执行一种知识蒸馏和过滤过程:它使用知识图谱嵌入模型(TransE)来修剪并仅保留每个实体最相关的邻居,有效地将全局知识图谱修剪为针对查询的更集中的"知识元图"。然后,该方法构建连接文本证据(如文档中的句子)和知识图谱实体的二分图,并通过图元网络(一种专门的图神经网络)传递该图,以共同优化文本和知识图谱节点的表示。输出是融合了隐式(文本)和显式(知识图谱)知识的混合表示,然后由重排序器使用。KERM的贡献在于学习忽略大型知识图谱的不相关部分,仅关注对排序重要的内容,从而提高了在完整知识图谱会增加过多噪音的任务上的有效性。
GraphMonoT5于2024年提出,代表了将基于图的推理与强大的序列到序列排序器(如T5)相结合的努力。GraphMonoT5应用于生物医学文档排序,其中领域知识至关重要。在GraphMonoT5中,每个查询-文档对都通过将其中的生物医学实体链接到领域知识图谱来增强,然后将这些实体2跳邻域内的所有实体收集到一个子图中。图神经网络对该子图进行编码,而T5编码器对文本进行编码,随后交互模块将图嵌入与文本嵌入融合(在文本序列中引入特殊的"交互标记"来表示图节点)。这个融合的表示被传递到T5解码器,该解码器产生相关性分数。从本质上讲,GraphMonoT5在Transformer中学习文本和知识图谱的联合表示。其结果是一个知识感知的序列模型,在生物医学排序任务中显著优于普通的T5排序器,例如,它能理解"EGFR"和"表皮生长因子受体"指的是同一个实体,或者一种药物和一种疾病通过已知的治疗关系相关联。
性能优势和基准测试分析
在各种应用场景中,基于图的重排序方法已经报告了相对于传统密集检索器和重排序器的显著改进。通过整合文档间链接或外部知识,这些模型解决了传统方法的一些关键盲点。例如前述的KGPR知识增强重排序在大规模基准测试(MS MARCO)上产生了超过3%的提升,在具有挑战性的查询集上产生了超过10%的提升,而基线模型没有使用图上下文。在信息检索领域,这样的改进是相当显著的,因为性能收益往往来之不易。类似地,基于图神经网络的重排序器在诸如网络问答和文档排序等任务上表现出强大的性能。例如,GNRR模型证明了使用语料库图可以将NDCG(归一化折扣累积增益)等指标比仅使用初始BM25排序的基线提高一个有意义的幅度。在这种情况下,图有助于发现BM25遗漏但被其他相关文档包围的文档。
一些方法在特定领域上下文中尤其出色。GraphMonoT5对生物医学知识的融合使其在医学文档排序挑战中取得了最先进的结果,优于缺乏该领域意识的普通Transformer。Graph-RAG方法在检索增强生成中使用图重排序,通过确保检索到的上下文更相关且相互关联,从而减少了生成答案中的幻觉并提高了事实性。
值得注意的是,由于基于图的重排序相对较新,目前还没有一个单一的排行榜可以直接比较所有这些方法。研究人员通常在标准信息检索数据集(如MS MARCO、TREC深度学习、自然问题等)上进行评估,但每个基于图的模型可能使用略有不同的评估设置或用于构建图的额外数据。该综述指出,目前"尚未开发出用于评估基于图的段落和文档排序任务的标准基准来衡量性能"。这部分是因为每种方法都带来了自己的图构建技术,有时还会使用额外的资源(如知识图谱或预计算的语料库图),这使得同类比较变得复杂。尽管如此,趋势表明当论文中引入一种图方法时,它通常优于等效的非图基线,证明了附加关系信息的价值。例如,如果一个密集检索器后跟交叉编码器重排序器产生的MRR(平均倒数排名)为X,那么添加基于图的重排序器(或用图增强交叉编码器)通常会将MRR推高到X加上某个百分比。我们在KGPR与monoT5的比较中看到了这一点,其他文献中报道的模型也有类似情况。
总而言之,基于图的重排序带来的性能提升包括改进的召回率(找到更多最初被遗漏的相关文档)、更高的顶部排名精度(通过利用上下文过滤掉误报)以及在复杂查询上更好的鲁棒性。这些好处在关系重要的任务中尤其明显,例如多跳问题(答案分布在多个来源中),或使用同义词并需要背景知识才能与文档匹配的查询。基于图的方法有效地在密集检索之上增加了一层上下文推理:它们不是将每个文档视为一个孤岛,而是将整个检索集视为信息空间的相互关联的组成部分,从而做出更明智的排序决策。
技术局限性与发展前景
尽管基于图的重排序展现出良好前景,但该综述论文强调了该领域的几个技术局限性和开放性挑战。缺乏标准数据集和基准是当前面临的主要问题。目前还没有专门为基于图的重排序设计的基准测试。研究人员一直在重新利用现有的信息检索数据集(如MS MARCO、TREC等),然后为这些数据集创建自己的图输入。这导致了不一致性:一篇论文可能使用某种方式构建图并在MS MARCO上进行评估,而另一篇论文在相同数据上使用不同的图,这使得很难判断哪个图或模型真正效果更好。该论文建议社区应开发专门针对基于图的检索的标准化数据集或评估任务,其中图结构是基准的一部分,例如提供知识图谱和一组查询的数据集,系统必须使用该图进行处理。这将允许公平比较并更有系统地推动进展。
图构建开销是另一个重要的技术挑战。构建和使用图的计算成本可能很高。一些方法需要为每个查询构建大型子图(例如,在排名前1000的文档中找到所有成对相似性,或者为每个实体查询庞大的知识库)。这在实践中可能成为瓶颈。预计算语料库图(如GAR和GNRR中所做的那样)等技术有助于分摊成本,但对于非常大的集合,这些图的存储可能会占用大量内存。未来的研究可能会探索更有效的图构建方法,也许是动态学习图的边,或者压缩图表示。
图神经网络的可扩展性也是一个考虑因素。在几十或几百个节点(对于给定查询的结果)上运行图神经网络通常可以接受,但如果试图合并太多节点(例如数千个段落),图神经网络的消息传递可能会变慢。一些逐对方法通过对偶进行采样来缓解这个问题,但总的来说,图重排序器必须仔细限制图的大小(通常仅考虑检索到的前N个项目或限制包含的邻居数量)。在包含更多上下文和保持计算可行性之间存在权衡。未来的创新可能涉及分层图或使用可以通过采样或聚类技术处理更大图的图神经网络。
建模和训练复杂性是基于图的模型面临的另一个挑战。这些模型引入了许多新的设计选择,包括如何编码节点和边,如何将图输出与现有排序器结合,使用什么损失函数(逐点与逐对损失等),以及如何平衡相关性与其他因素(如多样性或公平性)。这种复杂性意味着该领域仍在探索最佳实践。该综述的作者指出,不同的工作已经"派生出自己的方法"来构建邻接矩阵、扩充训练数据等等。一个未来的发展方向是确定哪些图构建和训练策略效果最好,并可能开发统一的框架。例如,可以想象一个库,给定一组检索到的文档,它会自动构建有用的图(使用某种学习或统计方法)并应用标准化的图神经网络重排序器。
与语言模型的集成是另一个重要的发展机遇。更无缝地将基于图的方法与大型语言模型的强大功能相结合具有巨大潜力。一些初步的尝试(如SlideGAR或知识感知的交叉编码器)正在通过将图输出馈送到Transformer来实现这一点。但是,更有可能出现神经符号混合模型,这些模型使用大型语言模型来指导图构建,或使用图来帮助解释大型语言模型输出。随着大型语言模型的不断改进,弄清楚图如何补充它们(提供事实基础,通过图约束强制执行逻辑一致性等)将非常重要。
可解释性评估是一个值得深入探索的领域。图还可以提供可解释性优势,例如强调"文档A的排名更高,因为它与我们知道相关的文档B共享内容"。然而,当前的评估纯粹关注排名指标。探索基于图的重排序器如何使检索过程更具可解释性以及如何衡量这一点还有很大空间。
总结
基于图的重排序是信息检索和图机器学习交叉领域一个令人兴奋的发展。通过明确表示检索到的文档以及外部知识之间的关系,这些方法解决了传统检索器孤立地考虑每个文档的局限性。从利用聚类效应和文档相似性网络到将丰富的知识图谱注入重排序过程,基于图的模型已经证明了改进的检索性能以及发现否则可能被遗漏的相关信息的能力。
论文《Graph-Based Re-ranking: Emerging Techniques, Limitations, and Opportunities》全面概述了这些创新,展示了图神经网络架构和巧妙的图构建如何应用于排序问题。我们看到了使用图来增强单个文档分数的逐点重排序器示例,将排序本身转变为图问题的逐对和逐列表方法,以及将文本神经网络与知识图谱相结合以获得强大结果的混合模型。根据经验证据,这些技术已在多个基准测试中取得了最先进的结果,验证了核心思想——“不要忘记连接!”——即通过图连接信息片段可以带来更好的检索效果。
随着该领域的进展,我们预计在如何评估基于图的重排序器方面将有更多的统一,并进一步与高级语言模型集成。基于图的重排序代表了一个有前途的研究方向,它通过利用结构化关系来增强传统信息检索系统的能力,为构建更智能、更上下文感知的搜索和问答系统开辟了新的可能性。
论文:
https://avoid.overfit.cn/post/ee7dcac0cc934a1eb12518391a2eb482
作者:BavalpreetSinghh