回归算法模型之线性回归
哈喽!我是 我不是小upper~
今天来和大家聊聊「线性回归」—— 这是机器学习里最基础、最直观的算法之一,咱们用一个超简单的例子就能搞懂它!
先看一个生活场景
假设你是房产中介,遇到一个灵魂拷问:
客户有一套 110 平米的房子,到底能卖多少钱?
你手头有一批真实数据:
| 房子面积(平米) | 价格(万) |
|---|---|
| 80 | 100 |
| 100 | 120 |
| 120 | 140 |
| 150 | 170 |
这些数据看起来像什么?如果把它们画在纸上(横轴是面积,纵轴是价格),每个数据点会「大致排成一条斜线」,但又不完全重合(毕竟现实中房价还受地段、装修等因素影响)。
线性回归的核心目标:画一条「最聪明的线」
面对这些散落的数据点,线性回归要解决的问题是:
如何画出一条直线,让它尽可能靠近所有数据点?
这条线需要满足一个条件:让每个数据点到直线的垂直距离之和最小(简单来说,就是「整体误差最小」)。
举个直观的例子:
-
如果画一条很陡的线,可能离 80 平米的点很近,但离 150 平米的点很远;
-
如果画一条平缓的线,可能中间的点靠近了,但两端的点又偏离了。
而线性回归会通过数学计算(比如最小二乘法),找到一条「平衡感最佳」的线,让这条线成为所有数据点的「最佳代言人」。
用这条线做预测
当这条「最佳直线」画好后,预测就变得超简单:
-
客户问「110 平米的房子值多少钱?」
-
你只需在直线上找到横轴为 110 的位置,看对应的纵轴数值是多少 —— 假设直线在这一点的高度是 130 万,就可以给出这个预测值。
因此,这就是线性回归。
原理详解
1. 建立模型假设:用直线搭建变量关系
我们先假设变量间存在「线性关系」,就像用一把直尺对齐散落的点。 单变量场景(如面积→房价): 用一条直线描述关系:
:预测值(如房价)
- x:输入特征(如面积)
- w:斜率(每增加 1 平米,房价上涨的金额)
- b:截距(面积为 0 时的 “虚拟基础价格”,实际无意义,但数学上需要)
多变量场景(如面积、卧室数→房价): 用向量表示更简洁:
写成向量点积形式:
:权重向量(每个特征的影响程度)
:特征向量
数学统一技巧: 为了简化推导,把截距 b 合并到权重向量中:
- 令
(新增一个恒为 1 的特征)
- 令
(最后一个元素是截距) 则公式简化为:
2. 目标函数:让预测误差尽可能小
我们有 m 条真实数据:,希望预测值
尽量接近真实值
。
用均方误差(MSE)度量总误差:
- 为什么用平方? ① 放大误差(便于数学处理);② 避免正负误差抵消;③ 光滑函数,便于求导。
- 目标:找到
,使得
最小。
3. 解析解推导:用数学公式直接算出最优解
当数据量不大时,可以通过数学推导直接求出最优的 ,步骤如下:
1. 用矩阵表示数据
- 特征矩阵
:形状为
,每行是一个样本的特征向量(含新增的 1)。
- 标签向量
:形状为
,包含所有真实值。
- 预测向量
(矩阵乘法本质是批量计算每个样本的
)。
2. 损失函数的矩阵形式
是预测误差向量,转置乘自身等于误差平方和。
3. 对 求导并令导数为 0
令导数为 0,解得:
- 前提:
可逆(即特征之间线性无关,无冗余)。
- 优点:一步到位,无需迭代;缺点:矩阵求逆计算量大(尤其当特征数 n 很大时)。
4. 梯度下降:用迭代法逼近最优解
当数据量大或特征多(矩阵求逆困难)时,用梯度下降法逐步优化参数:
核心思想:
- 随机初始化权重
- 计算当前参数下的损失函数梯度(即每个
对损失的影响方向)。
- 沿着梯度反方向更新参数(梯度方向是损失增加最快的方向,反方向即损失减少最快的方向)。
- 重复直到损失不再明显下降(收敛)。
数学步骤:
-
计算梯度(对单变量场景,梯度是导数;对多变量,是偏导数向量):
-
更新参数:
:学习率(步长),控制每次更新的幅度。
- 直观理解:若预测值大于真实值,梯度为正,w 减少;反之,w 增加。
关键点:
- 学习率太小→收敛慢;太大→容易跳过最优解(震荡或发散)。
- 可通过调整学习率、迭代次数或使用优化变种(如 Adam)提升效果。
总结对比
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 解析解 | 小数据、低维特征 | 一步到位,无迭代 | 矩阵求逆计算量大 |
| 梯度下降 | 大数据、高维特征 | 可扩展性强,适合迭代 | 需要调参,可能收敛慢 |
通过这两种方法,我们就能找到那条 “最聪明的线”,实现对未知数据的预测啦!
线性回归完整算法流程(从数据到模型的 6 大核心步骤)
步骤一:数据准备 —— 给模型喂 “学习材料”
-
收集数据: 每个样本包含两部分:
- 特征(X):影响结果的因素(如房子的面积、房间数)。
- 目标值(y):需要预测的结果(如房价)。 例如:
(面积=100㎡, 房间数=3) → 房价=120万。
-
数据预处理(标准化 / 归一化):
- 原因:特征尺度差异大(如 “房产税” 可能是 400,“犯罪率” 可能是 0.1),模型会误判数值大的特征更重要。
- 方法:用
StandardScaler将特征转换为 均值为 0,标准差为 1(公式:),让模型公平对待所有特征。
步骤二:构建模型 —— 用数学公式描述 “关系”
假设特征与目标值呈线性关系,模型公式为:
- 单特征:
(
是特征权重,b 是截距)。
- 多特征:
,可写成矩阵形式:
其中
步骤三:定义损失函数 —— 告诉模型 “哪里错了”
用 均方误差(MSE) 衡量预测值 与真实值
的差距:
- 为什么用平方? ① 放大误差,便于数学优化;② 避免正负误差抵消;③ 函数光滑,方便求导。
步骤四:选择优化方法 —— 找到 “最优解” 的两条路
-
解析解(最小二乘法,适合小数据): 通过数学公式直接求解最优权重,公式:
- 前提:特征矩阵
- 优点:一步到位,无需迭代;缺点:数据量大时矩阵求逆计算慢。
- 前提:特征矩阵
-
梯度下降(适合大数据): 迭代优化权重,每次沿损失函数梯度的反方向更新(梯度是损失增长最快的方向,反方向即下降最快的方向):
- 重复迭代直到损失不再明显下降(收敛)。
步骤五:训练模型 —— 让模型 “学起来”
- 输入数据:将预处理后的特征和目标值分为训练集(80%)和测试集(20%)。
- 前向计算:用当前权重计算预测值
。
- 计算误差:用损失函数(如 MSE)衡量预测值与真实值的差距。
- 反向优化:根据优化方法(解析解 / 梯度下降)更新权重,重复直到误差最小。
步骤六:模型预测 —— 用 “学会的知识” 做判断
给定新样本的特征,代入训练好的模型:
得到预测值(如根据 110㎡、3 个房间,预测房价为 130 万)。
完整案例:用线性回归预测房价(代码逐行解析)
Step 1:模拟真实房价数据(带业务含义的特征)
假设我们拥有一组历史房屋交易数据,想根据房子的特征(比如面积、卧室数、地段评分等)预测它的售价。
咱们目标是使用线性回归模型预测房价,并进行可视化与模型优化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler# Step 1: 构造模拟数据(仿真实际房价数据)
np.random.seed(42)
n_samples = 5006# 模拟特征
X = pd.DataFrame({'CRIM': np.random.exponential(scale=5, size=n_samples), # 犯罪率'ZN': np.random.uniform(0, 100, size=n_samples), # 住宅用地比例'INDUS': np.random.normal(10, 2, size=n_samples), # 工业用地比例'RM': np.random.normal(6, 0.5, size=n_samples), # 房间数'AGE': np.random.uniform(20, 100, size=n_samples), # 建造年代'TAX': np.random.normal(400, 50, size=n_samples), # 房产税'LSTAT': np.random.normal(12, 5, size=n_samples), # 低收入人口比例
})# 模拟房价 y(带有一定线性关系 + 噪声)
y = 24 + 0.3*X['RM'] - 0.2*X['LSTAT'] - 0.01*X['CRIM'] + \0.05*X['ZN'] - 0.04*X['AGE'] + 0.01*X['TAX'] + 0.1*X['INDUS'] + \np.random.normal(0, 2, size=n_samples)X['PRICE'] = y# Step 2: 特征选择与划分训练集
features = ['CRIM', 'ZN', 'INDUS', 'RM', 'AGE', 'TAX', 'LSTAT']
X_data = X[features]
y_data = X['PRICE']X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=0)# Step 3: 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# Step 4: 建立模型
model = LinearRegression()
model.fit(X_train_scaled, y_train)# Step 5: 模型预测
y_pred = model.predict(X_test_scaled)# Step 6: 模型评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print("MSE:", mse)
print("R^2 Score:", r2)# Step 7: 可视化:真实值 vs 预测值
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, c='crimson', edgecolors='black', alpha=0.7)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='limegreen', linewidth=2)
plt.title("Real vs Predicted Prices", fontsize=16)
plt.xlabel("Actual Prices", fontsize=14)
plt.ylabel("Predicted Prices", fontsize=14)
plt.grid(True)
plt.tight_layout()
plt.show()# Step 8: 查看回归系数(特征影响)
coefficients = pd.Series(model.coef_, index=features)plt.figure(figsize=(10, 6))
coefficients.sort_values().plot(kind='barh', color='royalblue', edgecolor='black')
plt.title("Feature Influence on Price", fontsize=16)
plt.xlabel("Coefficient Value", fontsize=14)
plt.grid(True)
plt.tight_layout()
plt.show()# Step 9: 模型优化 - 使用岭回归与Lasso
ridge = Ridge(alpha=1.0)
ridge.fit(X_train_scaled, y_train)
ridge_pred = ridge.predict(X_test_scaled)lasso = Lasso(alpha=0.1)
lasso.fit(X_train_scaled, y_train)
lasso_pred = lasso.predict(X_test_scaled)print("Ridge R^2:", r2_score(y_test, ridge_pred))
print("Lasso R^2:", r2_score(y_test, lasso_pred))Step 1:模拟真实房价数据(带业务含义的特征)
# 模拟7个特征(犯罪率、房间数等)和房价,加入随机噪声模拟真实场景
np.random.seed(42) # 固定随机种子,确保结果可复现
n_samples = 5006
X = pd.DataFrame({'CRIM': np.random.exponential(scale=5, size=n_samples), # 犯罪率(数值越高,房价可能越低)'RM': np.random.normal(6, 0.5, size=n_samples), # 房间数(数值越高,房价可能越高)# 其他特征类似...
})
# 房价公式:真实关系 + 随机噪声(模拟现实中的不确定性)
y = 24 + 0.3*X['RM'] - 0.2*X['LSTAT'] + ... + np.random.normal(0, 2, size=n_samples)
Step 2:划分训练集与测试集(8:2 比例)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=0
)
目的:用测试集评估模型在 “没见过的数据” 上的表现,避免过度拟合训练数据。
Step 3:数据标准化(让特征 “公平竞争”)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 用训练集的均值/标准差转换数据
X_test_scaled = scaler.transform(X_test) # 测试集用训练集的统计量转换(避免数据泄漏)
为什么必须先 fit 训练集? 测试集不能接触训练集的信息,否则评估结果不真实。
Step 4:训练线性回归模型(核心代码 2 行)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train_scaled, y_train) # 自动求解最优权重w和截距b
fit() 内部做了什么? 对多特征数据,默认使用高效的矩阵运算求解解析解(或梯度下降,取决于数据规模)。
Step 5-6:预测与评估(量化模型好坏)
y_pred = model.predict(X_test_scaled) # 用测试集特征预测房价
MSE(均方误差):\(\text{MSE} = \frac{1}{m} \sum_{i=1}^m (y_i - \hat{y}_i)^2\) 数值越小,预测越准。
R²(判定系数)::完美预测;
:仅能预测平均值。
Step 7:可视化 —— 直观判断预测效果
plt.scatter(y_test, y_pred) # 真实值vs预测值散点图
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='limegreen')
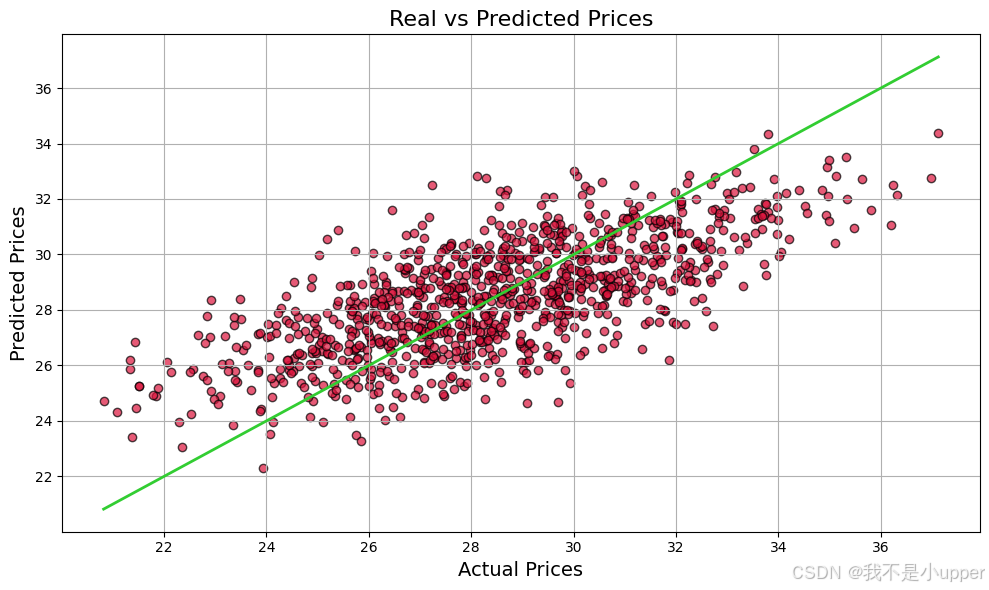
理想情况:点分布在绿色对角线上,说明预测值与真实值一致。
Step 8:特征影响分析(系数可视化)
coefficients = pd.Series(model.coef_, index=features)
coefficients.sort_values().plot(kind='barh')
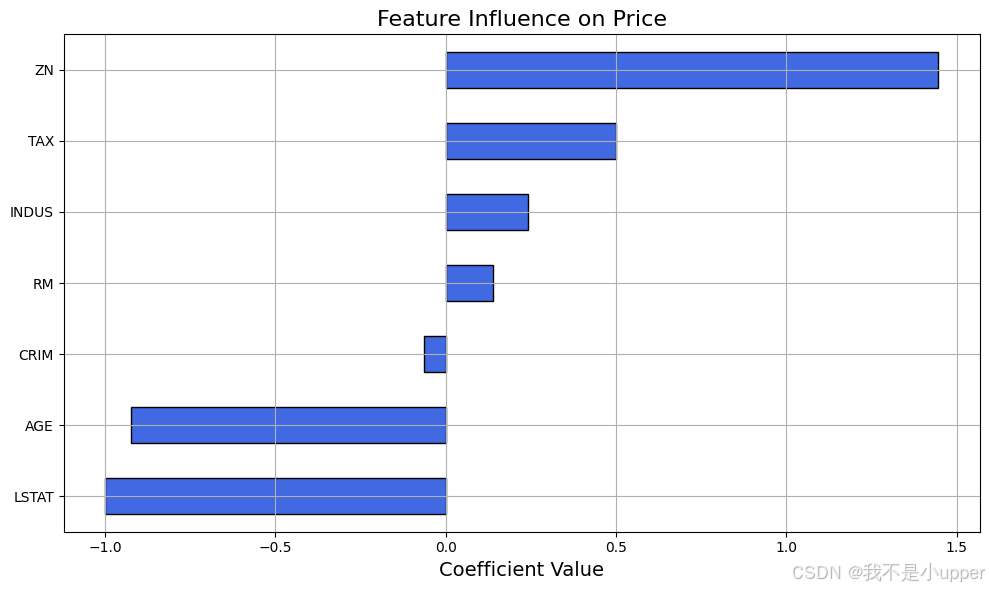
正系数(如 RM 房间数):特征值越大,房价越高;
负系数(如 LSTAT 低收入比例):特征值越大,房价越低;
系数绝对值越大,特征对房价的影响越强。
Step 9:模型优化(应对过拟合,提升泛化能力)
from sklearn.linear_model import Ridge, Lasso
ridge = Ridge(alpha=1.0) # 岭回归,惩罚系数绝对值过大
lasso = Lasso(alpha=0.1) # Lasso回归,强制不重要特征的系数为0(特征选择)
过拟合场景:训练集表现好,测试集表现差(模型记住了噪声)。
- 正则化作用:
- Ridge:防止系数过大,增强模型稳定性;
- Lasso:自动剔除无关特征(系数为 0 的特征可忽略)。
总结:线性回归的 “全链路思维”
- 数据是基础:特征质量直接影响模型效果(如 “房间数” 比 “小区名称” 更易量化)。
- 模型是桥梁:用线性公式假设特征与目标的关系,数学上可推导、可解释。
- 优化是关键:根据数据规模选择解析解或梯度下降,用正则化防止过拟合。
- 评估是验证:通过测试集和可视化,确保模型不仅 “学过”,还能 “举一反三”。
通过这套流程,线性回归能快速落地到房价预测、销量预估等实际场景,是理解机器学习的最佳入门案例~