【Doris基础】Apache Doris 基本架构深度解析:从存储到查询的完整技术演进
目录
1 引言
2 Doris 架构全景图
2 核心组件技术解析
2.1 Frontend 层(FE)
2.2 Backend 层(BE)
3 数据存储与复制机制
3.1 存储架构演进
3.2 副本复制策略
4 查询处理全流程解析
4.1 查询生命周期
5 高可用设计
5.1 FE高可用架构
5.2 BE故障恢复
6 总结
1 引言
Apache Doris作为一款基于MPP架构的高性能实时分析数据库,凭借其极速的OLAP查询能力和简单易用的特性,在大数据领域获得了广泛应用。
2 Doris 架构全景图
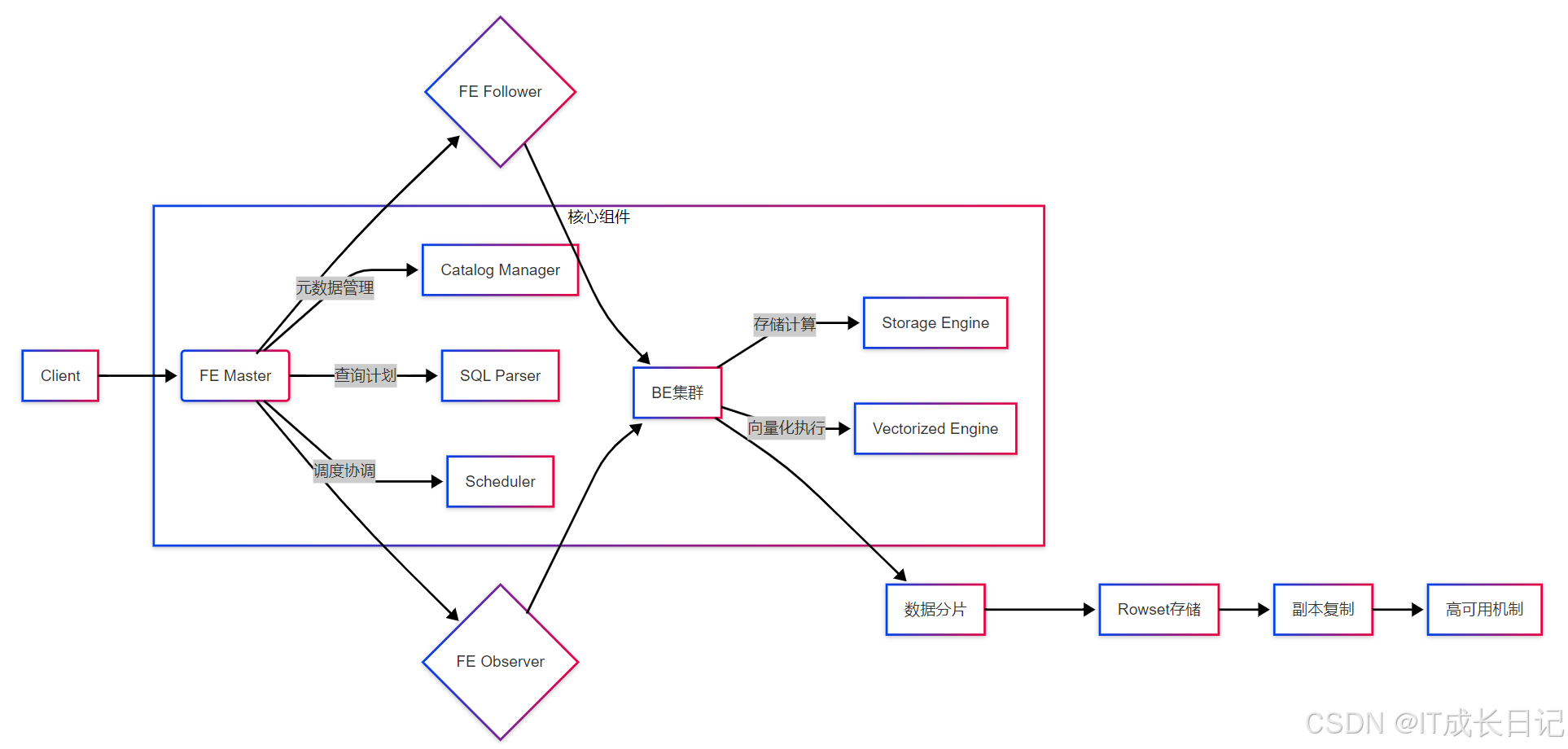
- 三层服务架构:由Frontend(FE) 集群和Backend(BE) 集群构成计算存储分离架构,通过Broker实现外部数据源访问
- 元数据双环路:FE Master主导元数据变更,Follower通过Paxos协议保证强一致性,Observer提供只读扩展
- 数据分片机制:采用动态分片(Tablet)设计,每个分片包含多个Rowset实现增量更新
- 存储引擎:采用列式存储格式,支持多种索引结构(Zone Map、Bloom Filter)
- 计算引擎:基于LLVM的向量化执行引擎,支持Pipeline执行模式
2 核心组件技术解析
2.1 Frontend 层(FE)
角色定位:作为系统的"大脑",承担元数据管理、查询计划生成、用户访问控制等核心职责,采用 Shared-Nothing 架构实现水平扩展关键模块:
- Catalog Manager:存储表结构、分区信息、分片位置等元数据,通过多版本控制(MVCC)保证事务一致性,采用两阶段提交协议管理Schema变更
- Query Planner:将SQL解析为逻辑计划,通过CBO(基于成本的优化器)生成物理执行计划,优化策略包括:
- 谓词下推(Predicate Pushdown)
- 分区剪枝(Partition Pruning)
- 动态分区裁剪(Dynamic Partition Pruning)
- Coordinator:负责将物理计划拆分为多个Fragment,通过Pipeline调度机制分配给BE执行,支持自适应执行,可根据集群负载动态调整并行度
2.2 Backend 层(BE)
角色定位:作为数据存储和计算的核心载体,采用混合架构设计:
- 存储层:基于LSM-Tree思想实现的高效列存引擎
- 计算层:支持Pipeline执行模式的向量化引擎
关键特性:
- 数据分片(Tablet):物理存储的最小单元,每个Tablet包含多个Rowset(不可变数据块),支持自动数据均衡和副本迁移
- 智能索引:
- Zone Map:记录每个数据块的最大/最小值,实现快速范围查询过滤
- Bloom Filter:加速点查性能,减少不必要的IO
- 倒排索引:对高基数列建立索引,支持快速存在性判断
- 向量化执行:通过SIMD指令集优化,将单条记录处理升级为批量处理,典型场景性能提升3-5倍
3 数据存储与复制机制
3.1 存储架构演进

存储流程:
- 写入数据首先进入内存MemTable
- 达到阈值后转为Immutable Rowset
- 通过BaseCompaction生成不可变的Base Rowset
- 增量数据写入Delta Rowset
- 定期执行Cumulative Compaction合并增量数据
3.2 副本复制策略
- 多副本存储:默认3副本,支持自定义副本数
- Paxos协议:FE层通过Multi-Paxos保证元数据一致性
- Quorum机制:数据写入需要多数派副本确认,确保强一致性
- 副本修复:通过异步复制和 Checksum 校验自动修复损坏副本
4 查询处理全流程解析
4.1 查询生命周期
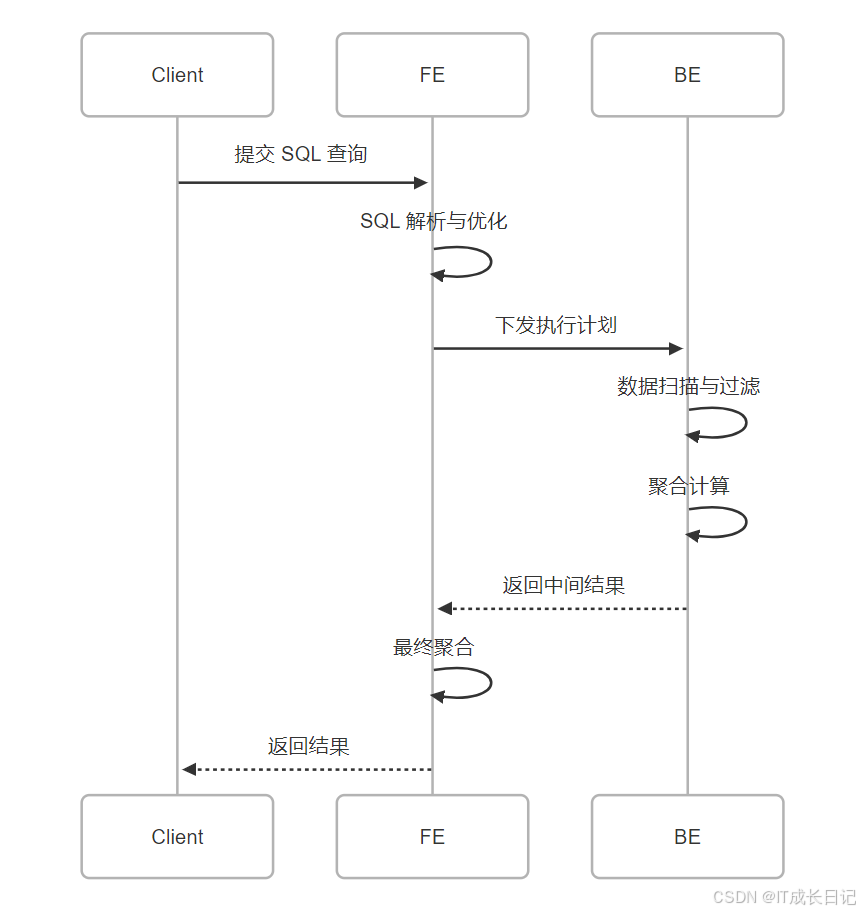
查询解析阶段:
- 语法解析生成AST
- 语义检查验证表/列存在性
- 生成逻辑执行计划
优化阶段:
- 统计信息收集(行数、Distinct值等)
- 代价模型选择最优执行路径
- 生成物理执行计划(包含Scan、Shuffle、Aggregate等Operator)
执行阶段:
- BE执行Pipeline计算
- 通过网络交换中间结果(Shuffle)
- FE进行最终结果聚合
5 高可用设计
5.1 FE高可用架构
- 三节点部署:1个Master + 2个Follower
- 脑裂防护:通过租约机制防止双Master
- 元数据备份:支持定期快照到远程存储
5.2 BE故障恢复
- 副本迁移:自动检测故障节点,触发副本复制
- 负载均衡:通过均衡器自动迁移热点分片
- 隔离机制:支持按照机房、机架维度部署副本
6 总结
Apache Doris通过创新的MPP架构设计,在存储层实现了高效的列式存储与智能索引,在计算层构建了高性能的向量化执行引擎,配合完善的副本机制和高可用设计,形成了完整的现代数据仓库解决方案。其架构设计充分体现了"极致性能"与"简单易用"的平衡哲学,为大数据分析场景提供了强有力的技术支撑。