机器学习-随机森林
一、集成学习
1.1定义
机器学习中有一种大类叫集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
1.2类型
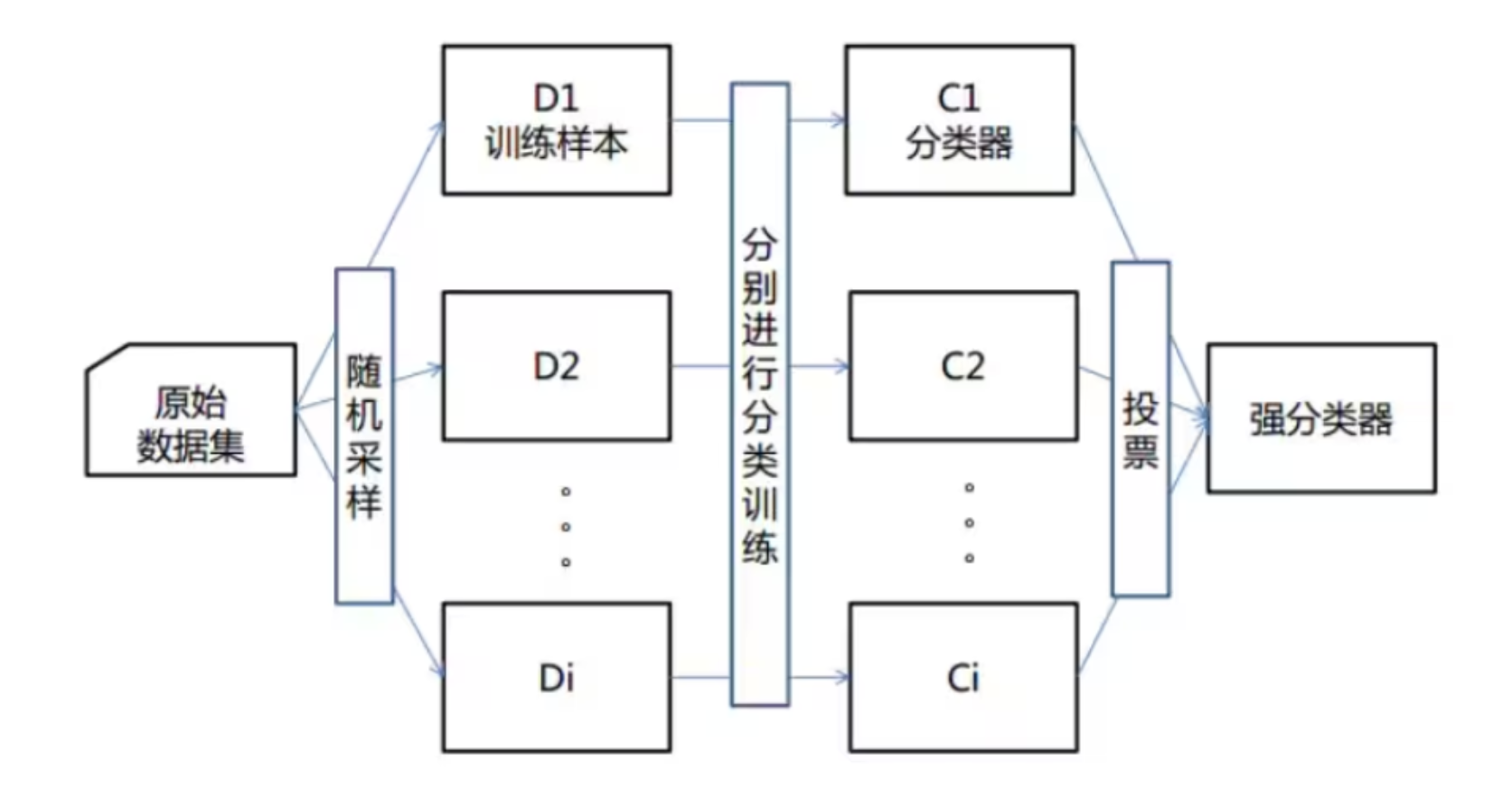
bagging(装袋法):通过自助采样(Bootstrap)从原始数据中抽取多个子集,独立训练多个弱学习器,最终通过投票或平均整合结果。
boosting(提升法):通过迭代训练弱学习器,逐步调整样本权重或分类器权重,使后续模型更关注前序模型误分类的样本,最终将弱学习器加权组合为强学习器。
stacking(堆叠法):通过多层模型组合,第一层由多个弱学习器组成,其输出作为第二层元学习器的输入特征,最终由元学习器输出预测结果。
1.3小结
| 方法 | 核心策略 | 弱学习器关系 | 典型算法 | 优势 |
|---|---|---|---|---|
| Boosting | 迭代优化样本 / 模型权重 | 串行依赖 | AdaBoost、XGBoost | 高精度,适合复杂数据 |
| Bagging | 自助采样与并行训练 | 并行独立 | 随机森林 | 抗过拟合,适合高方差模型 |
| Stacking | 多层模型特征融合 | 分层组合 | 堆叠泛化模型 | 灵活,可挖掘模型间互补信息 |
二、随机森林
2.1定义
随机森林(Random Forest) 是一种基于 集成学习(Ensemble Learning) 的机器学习算法,属于 Bagging(装袋法) 的改进变体。它通过构建多个 决策树(Decision Tree) 作为子模型,并将它们的预测结果进行组合,以提高模型的泛化能力和鲁棒性。
2.2随机森林与集成学习的关系
随机森林(Random Forest)是集成学习(Ensemble Learning)的一种具体实现方式,属于集成学习中的同质集成模型(所有子模型类型相同),是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林,每棵树都在不同的数据子集和特征子集上进行训练,最终通过投票或平均预测结果来产生更准确和稳健的预测。
2.3算法作用
(1)提高了预测精度;
(2)降低了过拟合风险;
(3)能够处理高维度和大规模数据集。
三、算法原理
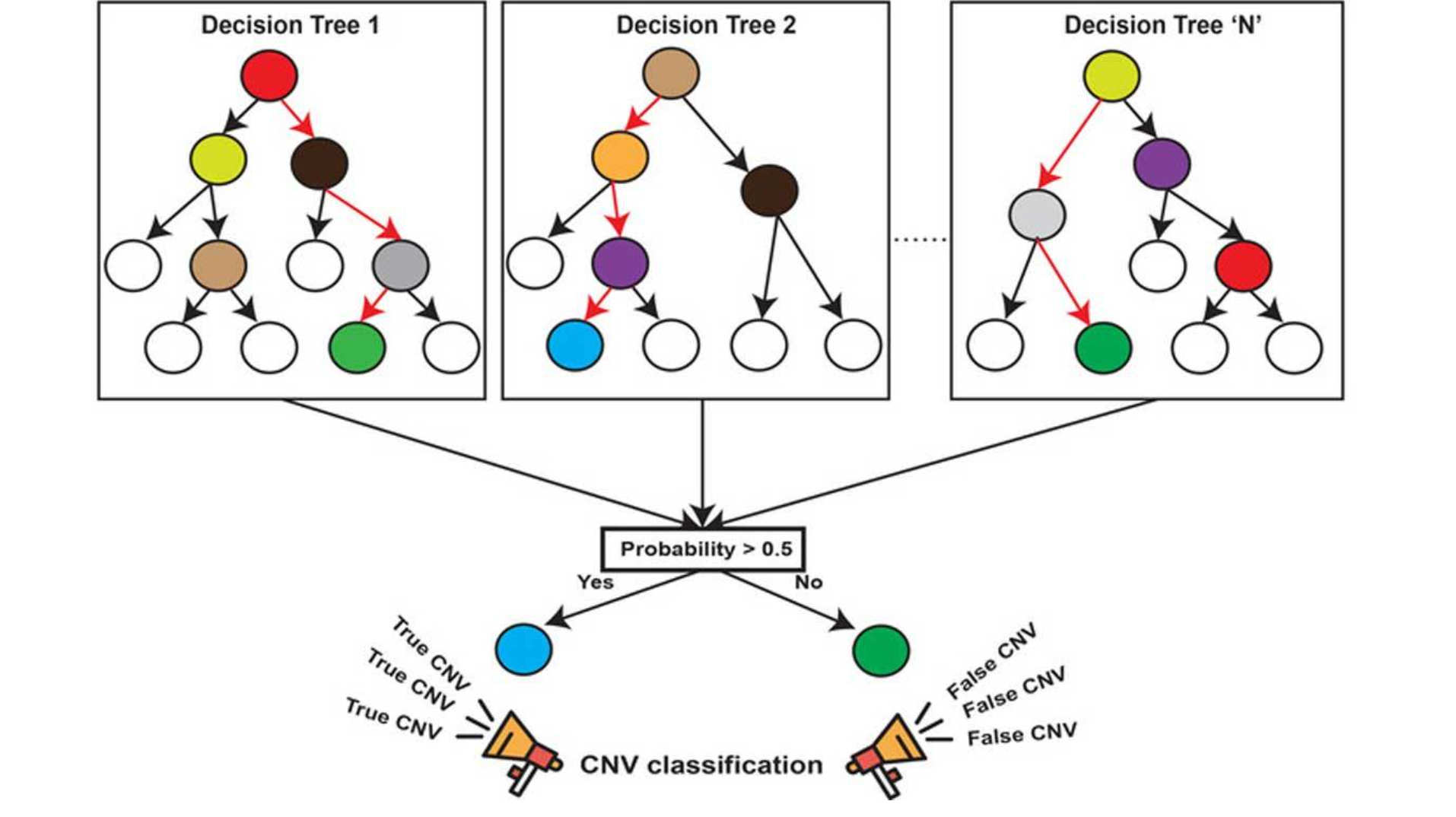
随机:特征随机、训练集随机。
森林:多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树。
特点:
-
处理具有高维特征的输入样本,而且不需要降维
-
使用平均或者投票来提高预测精度和控制过拟合
四、API
from sklearn.ensemble import RandomForestClassifier(n_estimators,criterion,max_depth)
参数解释:
n_estimators :森林中树木的数量。(决策树个数)
criterion : 当criterion取值为“gini”时采用 基尼不纯度(Gini impurity)算法构造决策树,
当criterion取值为 “entropy” 时采用信息增益( information gain)算法构造决策树.
max_depth :树的最大深度。
五、泰坦尼克号乘客生存示例
5.1数据集背景
泰坦尼克号数据集是经典的机器学习入门数据集,主要用于分类任务(预测乘客是否幸存)。数据包含泰坦尼克号上乘客的个人信息和乘船信息,通过分析这些特征来预测生存概率。
5.2数据集介绍
| 特征名 | 含义解释 | 数据类型 |
|---|---|---|
PassengerId | 乘客唯一编号 | 整数(ID) |
Survived | 标签名(目标变量):是否幸存(0 = 遇难,1 = 幸存) | 整数(0/1) |
Pclass | 船舱等级(1 = 一等舱,2 = 二等舱,3 = 三等舱) | 整数(分类) |
Name | 乘客姓名 | 字符串 |
Sex | 性别(male = 男性,female = 女性) | 字符串(分类) |
Age | 年龄(可能存在缺失值) | 浮点数 |
SibSp | 船上兄弟姐妹 / 配偶的数量(Sibling-Spouse) | 整数 |
Parch | 船上父母 / 子女的数量(Parent-Child) | 整数 |
Ticket | 船票编号 | 字符串 |
Fare | 船票价格 | 浮点数 |
Cabin | 船舱号(可能存在大量缺失值) | 字符串 |
Embarked | 登船港口(C = 瑟堡,Q = 皇后镇,S = 南安普顿) | 字符串(分类) |
标签名(目标变量)
-
标签名:
Survived-
含义:预测目标,即乘客是否在泰坦尼克号事故中幸存。
-
取值:
0(遇难)或1(幸存)。
-
5.3代码实现
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 加载泰坦尼克号数据集
titanic = pd.read_csv('./机器学习sklearn/srcc/titanic/titanic.csv')
print(titanic.head())# 查看基本信息
print(titanic.shape)# 提取训练特征,处理缺失值
titanic = titanic[['pclass','age','sex','survived']]
#将需要训练的特征提取出来(船票等级、年龄、性别、是否生产)
titanic['age'] = titanic['age'].fillna(titanic['age'].mean())
#把年龄的缺失值设置为平均年龄y = titanic['survived'].to_numpy()
#取出生还列,再转换为numpy数组
x = titanic[['pclass','age','sex',]]
#取出其他特征列转换为dataframe
x = x.to_dict(orient='records')
#把dataframe转换为字典,每一个字典的键值对就是一个人的提取特征信息#字典向量转化器
dict_vet = DictVectorizer(sparse=False)
#把字典转换为特征向量
x = dict_vet.fit_transform(x)
print(x)
print(dict_vet.get_feature_names_out())# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)# 标准化数据集
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)# 创建模型
model = RandomForestClassifier()# 创建网格搜索器
param_grid ={'n_estimators':[100,120,200,300,400,600,1000],'max_depth':[5,8,15,25,30]}
grid = GridSearchCV(model,param_grid=param_grid,cv=3)
# 加入网格搜索与交叉验证, cv=3表示3次交叉验证# 训练模型 - 使用网格搜索器进行训练
grid.fit(x_train, y_train) # 修改:使用grid而非model进行训练# 模型评估 - 使用网格搜索器进行评分
score = grid.score(x_test, y_test) # 修改:使用grid而非model进行评分
print('模型评分为:', score)# 查看网格搜索参数
print('最佳参数:', grid.best_params_)
print('最佳结果:', grid.best_score_)
print('最佳估计器:', grid.best_estimator_)
print('验证结果:', grid.cv_results_)# 预测
x_new = [{'age':20,'pclass':3,'sex':'female'}]
x_new_test = dict_vet.transform(x_new) #字典列表特征提取
print('预测结果为:', grid.predict(x_new_test)) # 修改:使用grid而非model进行预测结果:
row.names pclass survived name age ... home.dest room ticket boat sex
0 1 1st 1 Allen, Miss Elisabeth Walton 29.0000 ... St Louis, MO B-5 24160 L221 2 female
1 2 1st 0 Allison, Miss Helen Loraine 2.0000 ... Montreal, PQ / Chesterville, ON C26 NaN NaN female
2 3 1st 0 Allison, Mr Hudson Joshua Creighton 30.0000 ... Montreal, PQ / Chesterville, ON C26 NaN (135) male
3 4 1st 0 Allison, Mrs Hudson J.C. (Bessie Waldo Daniels) 25.0000 ... Montreal, PQ / Chesterville, ON C26 NaN NaN female
4 5 1st 1 Allison, Master Hudson Trevor 0.9167 ... Montreal, PQ / Chesterville, ON C22 NaN 11 male
[5 rows x 11 columns]
(1313, 11)
[[29. 1. 0. 0. 1. 0. ]
[ 2. 1. 0. 0. 1. 0. ]
[30. 1. 0. 0. 0. 1. ]
...
[31.19418104 0. 0. 1. 0. 1. ]
[31.19418104 0. 0. 1. 1. 0. ]
[31.19418104 0. 0. 1. 0. 1. ]]
['age' 'pclass=1st' 'pclass=2nd' 'pclass=3rd' 'sex=female' 'sex=male']
模型评分为: 0.8326996197718631
最佳参数: {'max_depth': 5, 'n_estimators': 300}
最佳结果: 0.8219047619047619
最佳估计器: RandomForestClassifier(max_depth=5, n_estimators=300)
验证结果: {'mean_fit_time': array([0.10117801, 0.1216282 , 0.19375849, 0.28457403, 0.38878767,
0.66723251, 1.20607026, 0.13137197, 0.14699125, 0.25415667,
0.37686475, 0.49679947, 0.76004561, 1.2675058 , 0.12876074,
0.15029407, 0.26181118, 0.37688279, 0.54013014, 0.76058555,
1.24102648, 0.11771758, 0.1247925 , 0.19877696, 0.302701 ,
0.40527646, 0.65357049, 1.00810424, 0.10199483, 0.12308002,
0.20153499, 0.29675182, 0.40002569, 0.63420518, 0.98959104]), 'std_fit_time': array([0.00795861, 0.01019274, 0.00116691, 0.00183674, 0.00999216,
0.06752551, 0.00518442, 0.00179136, 0.00306008, 0.0064371 ,
0.00641618, 0.01031046, 0.01265372, 0.01953059, 0.00326854,
0.00189769, 0.01428949, 0.00690053, 0.03051407, 0.00849426,
0.10710842, 0.01426651, 0.00512832, 0.00146376, 0.00291139,
0.0080446 , 0.02717183, 0.01457377, 0.00145367, 0.00278646,
0.00242329, 0.00281502, 0.00239577, 0.03743997, 0.00206593]), 'mean_score_time': array([0.00647593, 0.00760492, 0.01124986, 0.01613665, 0.0229044 ,
0.04001641, 0.06650567, 0.00769718, 0.0095818 , 0.01536091,
0.02160835, 0.0298202 , 0.04309154, 0.07398431, 0.007991 ,
0.01021489, 0.01571019, 0.02223317, 0.02997271, 0.04610165,
0.06551488, 0.00695809, 0.00752306, 0.01211747, 0.01774486,
0.02806314, 0.03710016, 0.05922437, 0.00660419, 0.00704694,
0.01254725, 0.01825301, 0.02411771, 0.03536415, 0.05800343]), 'std_score_time': array([7.27396994e-04, 4.26056306e-04, 5.10785282e-04, 2.19059842e-05,
2.22425200e-03, 1.56794377e-03, 3.03052992e-04, 6.26890008e-04,
3.95159789e-04, 6.80836452e-04, 3.61832590e-04, 1.41842826e-03,
2.19682424e-03, 3.45750952e-03, 8.18168139e-04, 3.17982958e-04,
4.96046583e-04, 2.15761545e-03, 6.34356299e-04, 9.98338095e-04,
9.82661687e-03, 5.75186007e-04, 1.23625647e-05, 3.74280080e-04,
3.68608454e-04, 4.97729233e-03, 4.69460262e-04, 4.47211400e-04,
7.48363170e-04, 3.96615738e-04, 1.78299269e-05, 6.53344064e-04,
3.02498969e-04, 4.67068061e-04, 1.51759497e-04]), 'param_max_depth': masked_array(data=[5, 5, 5, 5, 5, 5, 5, 8, 8, 8, 8, 8, 8, 8, 15, 15, 15,
15, 15, 15, 15, 25, 25, 25, 25, 25, 25, 25, 30, 30, 30,
30, 30, 30, 30],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False],
fill_value=999999), 'param_n_estimators': masked_array(data=[100, 120, 200, 300, 400, 600, 1000, 100, 120, 200, 300,
400, 600, 1000, 100, 120, 200, 300, 400, 600, 1000,
100, 120, 200, 300, 400, 600, 1000, 100, 120, 200, 300,
400, 600, 1000],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False],
fill_value=999999), 'params': [{'max_depth': 5, 'n_estimators': 100}, {'max_depth': 5, 'n_estimators': 120}, {'max_depth': 5, 'n_estimators': 200}, {'max_depth': 5, 'n_estimators': 300}, {'max_depth': 5, 'n_estimators': 400}, {'max_depth': 5, 'n_estimators': 600}, {'max_depth': 5, 'n_estimators': 1000}, {'max_depth': 8, 'n_estimators': 100}, {'max_depth': 8, 'n_estimators': 120}, {'max_depth': 8, 'n_estimators': 200}, {'max_depth': 8, 'n_estimators': 300}, {'max_depth': 8, 'n_estimators': 400}, {'max_depth': 8, 'n_estimators': 600}, {'max_depth': 8, 'n_estimators': 1000}, {'max_depth': 15, 'n_estimators': 100}, {'max_depth': 15, 'n_estimators': 120}, {'max_depth': 15, 'n_estimators': 200}, {'max_depth': 15, 'n_estimators': 300}, {'max_depth': 15, 'n_estimators': 400}, {'max_depth': 15, 'n_estimators': 600}, {'max_depth': 15, 'n_estimators': 1000}, {'max_depth': 25, 'n_estimators': 100}, {'max_depth': 25, 'n_estimators': 120}, {'max_depth': 25, 'n_estimators': 200}, {'max_depth': 25, 'n_estimators': 300}, {'max_depth': 25, 'n_estimators': 400}, {'max_depth': 25, 'n_estimators': 600}, {'max_depth': 25, 'n_estimators': 1000}, {'max_depth': 30, 'n_estimators': 100}, {'max_depth': 30, 'n_estimators': 120}, {'max_depth': 30, 'n_estimators': 200}, {'max_depth': 30, 'n_estimators': 300}, {'max_depth': 30, 'n_estimators': 400}, {'max_depth': 30, 'n_estimators': 600}, {'max_depth': 30, 'n_estimators': 1000}], 'split0_test_score': array([0.82285714, 0.82285714, 0.82285714, 0.82285714, 0.82285714,
0.82285714, 0.82285714, 0.82571429, 0.82571429, 0.82571429,
0.82571429, 0.82571429, 0.82571429, 0.82571429, 0.82571429,
0.82285714, 0.82285714, 0.82857143, 0.82571429, 0.82571429,
0.82571429, 0.82285714, 0.82571429, 0.82857143, 0.82857143,
0.82 , 0.82571429, 0.82571429, 0.82857143, 0.82285714,
0.82857143, 0.82 , 0.82285714, 0.82571429, 0.82571429]), 'split1_test_score': array([0.82285714, 0.82285714, 0.82285714, 0.82285714, 0.82285714,
0.82285714, 0.82285714, 0.82 , 0.81428571, 0.81428571,
0.81714286, 0.82 , 0.81714286, 0.81714286, 0.80857143,
0.80857143, 0.80857143, 0.81142857, 0.80571429, 0.80571429,
0.80857143, 0.80571429, 0.80285714, 0.80571429, 0.80285714,
0.81142857, 0.81142857, 0.80571429, 0.80285714, 0.80857143,
0.80285714, 0.80857143, 0.80571429, 0.81142857, 0.81142857]), 'split2_test_score': array([0.81714286, 0.81428571, 0.81714286, 0.82 , 0.81714286,
0.81428571, 0.81714286, 0.8 , 0.80285714, 0.80285714,
0.80285714, 0.80285714, 0.8 , 0.80285714, 0.79714286,
0.79428571, 0.79714286, 0.79714286, 0.79428571, 0.79714286,
0.79428571, 0.79714286, 0.79714286, 0.79142857, 0.79428571,
0.79714286, 0.79428571, 0.79714286, 0.79142857, 0.79428571,
0.79714286, 0.79714286, 0.79714286, 0.79428571, 0.79714286]), 'mean_test_score': array([0.82095238, 0.82 , 0.82095238, 0.82190476, 0.82095238,
0.82 , 0.82095238, 0.8152381 , 0.81428571, 0.81428571,
0.8152381 , 0.81619048, 0.81428571, 0.8152381 , 0.81047619,
0.80857143, 0.80952381, 0.81238095, 0.80857143, 0.80952381,
0.80952381, 0.80857143, 0.80857143, 0.80857143, 0.80857143,
0.80952381, 0.81047619, 0.80952381, 0.80761905, 0.80857143,
0.80952381, 0.80857143, 0.80857143, 0.81047619, 0.81142857]), 'std_test_score': array([0.00269374, 0.00404061, 0.00269374, 0.00134687, 0.00269374,
0.00404061, 0.00269374, 0.01102461, 0.00933139, 0.00933139,
0.00942809, 0.00971242, 0.01069045, 0.00942809, 0.01174174,
0.01166424, 0.01051939, 0.01284832, 0.01298874, 0.01197124,
0.01284832, 0.01069045, 0.01234427, 0.0152975 , 0.01456863,
0.00942809, 0.01284832, 0.01197124, 0.01553286, 0.01166424,
0.01366924, 0.00933139, 0.01069045, 0.01284832, 0.01166424]), 'rank_test_score': array([ 2, 6, 2, 1, 2, 6, 2, 9, 12, 12, 9, 8, 12, 9, 17, 26, 20,
15, 26, 20, 20, 26, 26, 26, 26, 25, 17, 20, 35, 26, 20, 26, 26, 17,
16], dtype=int32)}
预测结果为: [0]