【深度学习】10. 深度推理(含链式法则详解)RNN, LSTM, GRU,VQA
深度推理(含链式法则详解)RNN, LSTM, GRU,VQA
RNN 输入表示方式
在循环神经网络(Recurrent Neural Network, RNN)中,我们处理的是一段文字或语音等序列数据。对于文本任务,输入通常是单词序列。为了将这些离散的语言符号送入神经网络中处理,我们需要将每个单词转换成向量。常见的表示方法有三种:
- One-hot 编码(One-hot Encoding)
- 单词哈希(Word Hashing)
- 词向量嵌入(Word Embedding)
这些表示方式的目标都是将单词映射为数值向量,供神经网络进行计算。
One-hot 编码机制详解
One-hot 编码是一种最简单的词表示方式:
- 向量长度等于词典大小 V V V
- 每个维度对应词典中的一个词
- 当前单词对应的位置为 1 1 1,其余为 0 0 0
假设我们有如下词典:
lexicon = { apple , bag , cat , dog , pig } \text{lexicon} = \{ \text{apple}, \text{bag}, \text{cat}, \text{dog}, \text{pig} \} lexicon={apple,bag,cat,dog,pig}
则每个单词的 One-hot 表示为:
| Word | D₁ | D₂ | D₃ | D₄ | D₅ |
|---|---|---|---|---|---|
| apple | 1 | 0 | 0 | 0 | 0 |
| bag | 0 | 1 | 0 | 0 | 0 |
| cat | 0 | 0 | 1 | 0 | 0 |
| dog | 0 | 0 | 0 | 1 | 0 |
| pig | 0 | 0 | 0 | 0 | 1 |
优点是简单直观,但缺点是向量稀疏,无法表达语义相似性。例如 “cat” 和 “dog” 语义相近,但在 one-hot 表示中完全不相似。
Word Hashing(单词哈希)
为了节省空间和避免词典过大带来的维度问题,我们可以使用哈希编码。
以单词 "apple" 为例:
-
拆分为若干个字符组(例如 3-gram):
a-p-p,p-p-l,p-l-e,这三个都属于apple类别注意需要连续的单词,比如apl就不行
-
将每个字符组映射到一个哈希空间中的维度
-
例如对于英文字母, 26 × 26 × 26 = 17576 26 \times 26 \times 26 = 17576 26×26×26=17576 种可能组合
输出表示与分类任务
RNN 的最终输出通常是一个概率分布,表示当前输入序列属于某个类别的概率。在情感分类任务中:
- 给定输入:“Complicated? Yes, and a little slow, too.”
- 输出可能是:
- 正面概率: y + = 0.1 y^+ = 0.1 y+=0.1
- 负面概率: y − = 0.9 y^- = 0.9 y−=0.9
再比如:
- 输入:“But the animation is as colorful as the story.”
- 输出:
- 正面概率: y + = 0.7 y^+ = 0.7 y+=0.7
- 负面概率: y − = 0.3 y^- = 0.3 y−=0.3
这说明网络通过学习上下文,能对整句话的语义做出判断。
序列信息与记忆需求
RNN 处理的不是单个输入,而是整个序列,因此模型需要具备“记忆”能力,以理解前后文的联系。
举例:
- 输入句子:“Complicated? Yes, and a little slow, too. But the animation is as colorful as the story.”
- 判断情感时,不能仅依赖“slow”或“colorful”单个词,而需理解整个语境。
这就意味着我们希望神经网络能够记住前面的信息来辅助后续判断。
隐状态与记忆机制
RNN 的关键机制在于引入了“隐状态”变量 h t h_t ht,它在每个时间步更新,并携带前文信息:
- 每个时间步输入 x t x_t xt
- 网络通过函数 f ( h t − 1 , x t ) f(h_{t-1}, x_t) f(ht−1,xt) 计算当前隐藏状态 h t h_t ht
- 隐状态 h t h_t ht 被看作一种“记忆”,传递到下一个时间步
因此记忆的传递方式是:
h t = f ( h t − 1 , x t ) h_t = f(h_{t-1}, x_t) ht=f(ht−1,xt)
这种循环结构使得 RNN 能够学习和保留先前输入的信息。
简化线性 RNN 示例
为了便于理解,假设我们构造一个极简版本的 RNN,所有权重均为 1,激活函数为线性函数,即:
- 不含偏置项
- 不使用非线性激活(如 tanh 或 ReLU)
我们令输入为一个二维向量序列:
Input: [ [ 1 1 ] , [ 2 2 ] , [ 3 3 ] ] \text{Input: } \left[ \begin{bmatrix} 1 \\ 1 \end{bmatrix}, \begin{bmatrix} 2 \\ 2 \end{bmatrix}, \begin{bmatrix} 3 \\ 3 \end{bmatrix} \right] Input: [[11],[22],[33]]
初始化 h 0 = [ 0 0 ] h_0 = \begin{bmatrix} 0 \\ 0 \end{bmatrix} h0=[00],我们每步令:
h t = h t − 1 + x t h_t = h_{t-1} + x_t ht=ht−1+xt
输出即为隐藏状态:
| 时间步 t t t | 输入 x t x_t xt | 隐状态 h t h_t ht |
|---|---|---|
| 1 | [ 1 , 1 ] [1, 1] [1,1] | [ 1 , 1 ] [1, 1] [1,1] |
| 2 | [ 2 , 2 ] [2, 2] [2,2] | [ 3 , 3 ] [3, 3] [3,3] |
| 3 | [ 3 , 3 ] [3, 3] [3,3] | [ 6 , 6 ] [6, 6] [6,6] |
这个过程表明:RNN 的输出依赖于当前输入与先前记忆之和。
状态与输出非一致情形
进一步构造一个例子,使得输出不直接等于隐藏状态,而是对其进行变换。例如令:
y t = 2 ⋅ h t y_t = 2 \cdot h_t yt=2⋅ht
继续上面的输入序列,输出为:
| 时间步 t t t | 隐状态 h t h_t ht | 输出 y t y_t yt = 2 h t 2h_t 2ht |
|---|---|---|
| 1 | [ 1 , 1 ] [1, 1] [1,1] | [ 2 , 2 ] [2, 2] [2,2] |
| 2 | [ 3 , 3 ] [3, 3] [3,3] | [ 6 , 6 ] [6, 6] [6,6] |
| 3 | [ 6 , 6 ] [6, 6] [6,6] | [ 12 , 12 ] [12, 12] [12,12] |
这说明 RNN 模型的输出可以灵活地由隐藏状态决定,而隐藏状态本身是累积的“记忆”表示。
标准 RNN 的数学定义
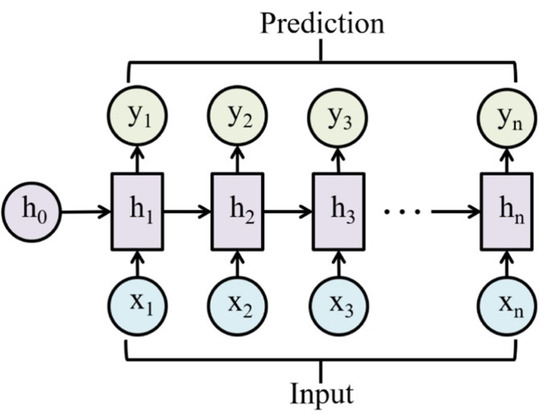
一个标准的 RNN 由以下几个核心组成:
- 输入序列: x t x_t xt
- 隐藏状态: h t h_t ht
- 输出序列: o t o_t ot
其计算公式如下:
h t = tanh ( W h h h t − 1 + W x h x t + b h ) h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h) ht=tanh(Whhht−1+Wxhxt+bh)
o t = W h o h t + b o o_t = W_{ho} h_t + b_o ot=Whoht+bo
其中:
- W h h W_{hh} Whh:前一隐藏状态到当前隐藏状态的权重
- W x h W_{xh} Wxh:输入到隐藏状态的权重
- W h o W_{ho} Who:隐藏状态到输出的权重
- b h b_h bh, b o b_o bo:偏置项
tanh 函数作为激活函数能压缩输出范围在 [ − 1 , 1 ] [-1, 1] [−1,1] 内。
这种结构让网络具备记忆和非线性建模能力。
在标准 RNN 中,所有时间步共享同一组参数,包括:
| 参数 | 含义 | 是否共享 |
|---|---|---|
| WxhW_{xh}Wxh | 输入到隐藏状态的权重(input → hidden) | ✅ 是 |
| WhhW_{hh}Whh | 上一隐藏状态到当前隐藏状态的权重(memory) | ✅ 是 |
| bhb_hbh | 隐藏层偏置项 | ✅ 是 |
| WhyW_{hy}Why | 隐藏状态到输出的权重 | ✅ 是 |
| byb_yby | 输出层偏置项 | ✅ 是 |
梯度消失与梯度爆炸问题
在训练 RNN 时,我们通常使用反向传播算法(Backpropagation Through Time, BPTT)来更新参数。但由于序列的深度较长(每一步都构成一个深度层),会出现如下两个严重问题:
- 梯度消失(Vanishing Gradient)
- 梯度爆炸(Exploding Gradient)
这两个问题会导致模型难以学习长距离依赖。
数学推导
考虑 RNN 中隐藏状态的更新公式:
h t = tanh ( W h h h t − 1 + W x h x t + b h ) h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h) ht=tanh(Whhht−1+Wxhxt+bh)
令损失函数对 h t h_t ht 的梯度为:
∂ L ∂ h t \frac{\partial L}{\partial h_t} ∂ht∂L
则通过链式法则, t t t 时刻的损失对 h t − n h_{t-n} ht−n 的影响为:
∂ L ∂ h t − n = ( ∏ k = 1 n ∂ h t − k + 1 ∂ h t − k ) ⋅ ∂ L ∂ h t \frac{\partial L}{\partial h_{t-n}} = \left( \prod_{k=1}^{n} \frac{\partial h_{t-k+1}}{\partial h_{t-k}} \right) \cdot \frac{\partial L}{\partial h_t} ∂ht−n∂L=(k=1∏n∂ht−k∂ht−k+1)⋅∂ht∂L
若激活函数为 tanh \tanh tanh,其导数最大为 1,当:
∥ ∂ h t − k + 1 ∂ h t − k ∥ < 1 \left\| \frac{\partial h_{t-k+1}}{\partial h_{t-k}} \right\| < 1 ∂ht−k∂ht−k+1 <1
则多次相乘后,梯度将指数级衰减,趋于 0,即为梯度消失。
相反,若导数大于 1,多次相乘后会指数增长,即梯度爆炸。
1. 前向传播公式回顾
在标准 RNN 中,隐藏状态和输出的更新为:
-
隐藏状态更新:
h t = tanh ( W h h h t − 1 + W h x x t + b h ) h_t = \tanh(W_{hh} h_{t-1} + W_{hx} x_t + b_h) ht=tanh(Whhht−1+Whxxt+bh) -
输出计算:
y t = W y h h t y_t = W_{yh} h_t yt=Wyhht
其中:
- x t x_t xt 是输入向量
- h t h_t ht 是当前隐藏状态
- W h x W_{hx} Whx 是输入到隐藏层的权重
- W h h W_{hh} Whh 是前一隐藏状态到当前的权重(递归权重)
- W y h W_{yh} Wyh 是隐藏状态到输出的权重
- b h b_h bh 是隐藏层偏置
2. 我们的目标
假设分析的是时间步 t = 3 t=3 t=3 的损失 E 3 E_3 E3 对权重 W h h W_{hh} Whh 的梯度:
∂ E 3 ∂ W h h \frac{\partial E_3}{\partial W_{hh}} ∂Whh∂E3
按照链式法则,
如果一个变量 y 是通过另一个变量 u 再通过 x 计算出来的
可以分解为:
∂ E 3 ∂ W h h = ∂ E 3 ∂ y 3 ⏟ 从损失反向 ⋅ ∂ y 3 ∂ h 3 ⏟ 线性输出 ⋅ ∂ h 3 ∂ W h h ⏟ 关键部分 \frac{\partial E_3}{\partial W_{hh}} = \underbrace{\frac{\partial E_3}{\partial y_3}}_{\text{从损失反向}} \cdot \underbrace{\frac{\partial y_3}{\partial h_3}}_{\text{线性输出}} \cdot \underbrace{\frac{\partial h_3}{\partial W_{hh}}}_{\text{关键部分}} ∂Whh∂E3=从损失反向 ∂y3∂E3⋅线性输出 ∂h3∂y3⋅关键部分 ∂Whh∂h3
3. 推导 ∂ h 3 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} ∂Whh∂h3
我们从隐藏状态 h 3 h_3 h3 的表达式入手:
h 3 = tanh ( W h h h 2 + W h x x 3 + b h ) h_3 = \tanh(W_{hh} h_2 + W_{hx} x_3 + b_h) h3=tanh(Whhh2+Whxx3+bh)
对 W h h W_{hh} Whh 求导,用链式法则:
∂ h 3 ∂ W h h = tanh ′ ( z 3 ) ⋅ ∂ z 3 ∂ W h h = tanh ′ ( z 3 ) ⋅ h 2 + tanh ′ ( z 3 ) ⋅ W h h ⋅ ∂ h 2 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} = \tanh'(z_3) \cdot \frac{\partial z_3}{\partial W_{hh}} = \tanh'(z_3) \cdot h_2 + \tanh'(z_3) \cdot W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} ∂Whh∂h3=tanh′(z3)⋅∂Whh∂z3=tanh′(z3)⋅h2+tanh′(z3)⋅Whh⋅∂Whh∂h2
其中:
- z 3 = W h h h 2 + W h x x 3 + b h z_3 = W_{hh} h_2 + W_{hx} x_3 + b_h z3=Whhh2+Whxx3+bh
- tanh ′ ( z 3 ) \tanh'(z_3) tanh′(z3) 是对激活函数的导数,按元素计算
RNN 中 ∂ h 3 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} ∂Whh∂h3 的推导详解
我们从以下公式出发:
h 3 = tanh ( W h h h 2 + W h x x 3 + b h ) h_3 = \tanh(W_{hh} h_2 + W_{hx} x_3 + b_h) h3=tanh(Whhh2+Whxx3+bh)
记:
z 3 = W h h h 2 + W h x x 3 + b h z_3 = W_{hh} h_2 + W_{hx} x_3 + b_h z3=Whhh2+Whxx3+bh
所以:
h 3 = tanh ( z 3 ) h_3 = \tanh(z_3) h3=tanh(z3)
我们要求的目标是:
∂ h 3 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} ∂Whh∂h3
第一步:链式法则
根据链式法则,有:
∂ h 3 ∂ W h h = ∂ h 3 ∂ z 3 ⋅ ∂ z 3 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} = \frac{\partial h_3}{\partial z_3} \cdot \frac{\partial z_3}{\partial W_{hh}} ∂Whh∂h3=∂z3∂h3⋅∂Whh∂z3
由于 tanh \tanh tanh 是逐元素作用的激活函数,所以导数为:
∂ h 3 ∂ z 3 = tanh ′ ( z 3 ) \frac{\partial h_3}{\partial z_3} = \tanh'(z_3) ∂z3∂h3=tanh′(z3)
第二步: ∂ z 3 ∂ W h h \frac{\partial z_3}{\partial W_{hh}} ∂Whh∂z3 包含两部分
因为:
z 3 = W h h h 2 + W h x x 3 + b h z_3 = W_{hh} h_2 + W_{hx} x_3 + b_h z3=Whhh2+Whxx3+bh
所以:
∂ z 3 ∂ W h h = h 2 ⊤ + W h h ⋅ ∂ h 2 ∂ W h h \frac{\partial z_3}{\partial W_{hh}} = h_2^\top + W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} ∂Whh∂z3=h2⊤+Whh⋅∂Whh∂h2
第一项是 z 3 z_3 z3 中 W h h W_{hh} Whh 的直接导数,第二项是由于 h 2 h_2 h2 本身也依赖于 W h h W_{hh} Whh,要再乘一轮链式法则。
为什么 ∂ z 3 ∂ W h h \frac{\partial z_3}{\partial W_{hh}} ∂Whh∂z3 有一项是 W h h ⋅ ∂ h 2 ∂ W h h W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} Whh⋅∂Whh∂h2
一、核心问题再重复一遍:
已知:
h 3 = tanh ( W h h h 2 + W h x x 3 + b h ) h_3 = \tanh(W_{hh} h_2 + W_{hx} x_3 + b_h) h3=tanh(Whhh2+Whxx3+bh)
记 z 3 = W h h h 2 + … z_3 = W_{hh} h_2 + \dots z3=Whhh2+…,我们要计算:
∂ h 3 ∂ W h h = tanh ′ ( z 3 ) ⋅ ∂ z 3 ∂ W h h \frac{\partial h_3}{\partial W_{hh}} = \tanh'(z_3) \cdot \frac{\partial z_3}{\partial W_{hh}} ∂Whh∂h3=tanh′(z3)⋅∂Whh∂z3
关键就在于:
∂ z 3 ∂ W h h = ? \frac{\partial z_3}{\partial W_{hh}} = \ ? ∂Whh∂z3= ?
二、 z 3 z_3 z3 中的变量有哪些?
从 z 3 = W h h h 2 z_3 = W_{hh} h_2 z3=Whhh2 来看,注意有两种依赖:
显式依赖: W h h W_{hh} Whh 自己在乘 h 2 h_2 h2(这是直接依赖)
隐式依赖: h 2 h_2 h2 是前一步隐藏状态,计算公式是:
h 2 = tanh ( W h h h 1 + W h x x 2 + b h ) h_2 = \tanh(W_{hh} h_1 + W_{hx} x_2 + b_h) h2=tanh(Whhh1+Whxx2+bh)所以 h 2 h_2 h2 本身也依赖于 W h h W_{hh} Whh!
三、用链式法则表示总导数
设 z 3 = W h h h 2 ( W h h ) z_3 = W_{hh} h_2(W_{hh}) z3=Whhh2(Whh),这是一个复合函数。
那么对 W h h W_{hh} Whh 求导:
∂ z 3 ∂ W h h = ∂ ( W h h h 2 ) ∂ W h h ⏟ 显式项 + ∂ ( W h h h 2 ) ∂ h 2 ⋅ ∂ h 2 ∂ W h h ⏟ 隐式项 \frac{\partial z_3}{\partial W_{hh}} = \underbrace{\frac{\partial (W_{hh} h_2)}{\partial W_{hh}}}_{\text{显式项}} + \underbrace{\frac{\partial (W_{hh} h_2)}{\partial h_2} \cdot \frac{\partial h_2}{\partial W_{hh}}}_{\text{隐式项}} ∂Whh∂z3=显式项 ∂Whh∂(Whhh2)+隐式项 ∂h2∂(Whhh2)⋅∂Whh∂h2
拆开来:
- 显式项: h 2 ⊤ h_2^\top h2⊤( W h h W_{hh} Whh 对自己那一项求导)
- 隐式项: W h h ⋅ ∂ h 2 ∂ W h h W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} Whh⋅∂Whh∂h2
所以:
∂ z 3 ∂ W h h = h 2 ⊤ + W h h ⋅ ∂ h 2 ∂ W h h \frac{\partial z_3}{\partial W_{hh}} = h_2^\top + W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} ∂Whh∂z3=h2⊤+Whh⋅∂Whh∂h2
四、直观解释
你可以这样理解:
- W h h W_{hh} Whh 一边乘着 h 2 h_2 h2
- 但 h 2 h_2 h2 又是前面一步计算出来的,里面又含有 W h h W_{hh} Whh
所以在计算梯度时,你不能只看当下这一步,还要把它对前面那一层的“影响”也算进去
这就是链式法则的本质:如果一个变量通过多个路径影响了输出,就要加上所有路径上的偏导
第三步:代入回总导数
∂ h 3 ∂ W h h = tanh ′ ( z 3 ) ⋅ ( h 2 ⊤ + W h h ⋅ ∂ h 2 ∂ W h h ) \frac{\partial h_3}{\partial W_{hh}} = \tanh'(z_3) \cdot \left( h_2^\top + W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} \right) ∂Whh∂h3=tanh′(z3)⋅(h2⊤+Whh⋅∂Whh∂h2)
这就是标准、完整、矩阵化版本的推导。
图中的写法说明
图中给出的简化写法为:
∂ h 3 ∂ W h h = ( tanh ) ′ ( h 2 + W h h ⋅ ∂ h 2 ∂ W h h ) \frac{\partial h_3}{\partial W_{hh}} = (\tanh)' \left( h_2 + W_{hh} \cdot \frac{\partial h_2}{\partial W_{hh}} \right) ∂Whh∂h3=(tanh)′(h2+Whh⋅∂Whh∂h2)
注意这个公式是对上面完整推导的简写,它省略了矩阵符号如转置 h 2 ⊤ h_2^\top h2⊤,是为强调结构上的“递归依赖”,而不是表示矩阵形式精确的微分。
递归形式继续展开
继续展开 ∂ h 2 ∂ W h h \frac{\partial h_2}{\partial W_{hh}} ∂Whh∂h2:
∂ h 2 ∂ W h h = tanh ′ ( z 2 ) ⋅ ( h 1 ⊤ + W h h ⋅ ∂ h 1 ∂ W h h ) \frac{\partial h_2}{\partial W_{hh}} = \tanh'(z_2) \cdot \left( h_1^\top + W_{hh} \cdot \frac{\partial h_1}{\partial W_{hh}} \right) ∂Whh∂h2=tanh′(z2)⋅(h1⊤+Whh⋅∂Whh∂h1)
最终就会形成一连串链条:
( tanh ) ′ ⋅ W h h ⋅ ( tanh ) ′ ⋅ W h h ⋅ ( tanh ) ′ ⋅ … (\tanh)' \cdot W_{hh} \cdot (\tanh)' \cdot W_{hh} \cdot (\tanh)' \cdot \dots (tanh)′⋅Whh⋅(tanh)′⋅Whh⋅(tanh)′⋅…
这就是导致梯度消失的源头:这些值都小于 1,乘多次后趋近于 0。
总结
- 图中的公式是对链式法则展开的一个简化表示
- 真正推导中应使用 ∂ h t ∂ W h h = tanh ′ ( z t ) ⋅ ( h t − 1 ⊤ + W h h ⋅ ∂ h t − 1 ∂ W h h ) \frac{\partial h_t}{\partial W_{hh}} = \tanh'(z_t) \cdot \left( h_{t-1}^\top + W_{hh} \cdot \frac{\partial h_{t-1}}{\partial W_{hh}} \right) ∂Whh∂ht=tanh′(zt)⋅(ht−1⊤+Whh⋅∂Whh∂ht−1)
- 图中的写法强调结构递归性,而不是精确微分操作
进一步地:
∂ h 2 ∂ W h h = tanh ′ ( z 2 ) ⋅ h 1 + tanh ′ ( z 2 ) ⋅ W h h ⋅ ∂ h 1 ∂ W h h \frac{\partial h_2}{\partial W_{hh}} = \tanh'(z_2) \cdot h_1 + \tanh'(z_2) \cdot W_{hh} \cdot \frac{\partial h_1}{\partial W_{hh}} ∂Whh∂h2=tanh′(z2)⋅h1+tanh′(z2)⋅Whh⋅∂Whh∂h1
同理再向前传播:
∂ h 1 ∂ W h h = tanh ′ ( z 1 ) ⋅ h 0 + tanh ′ ( z 1 ) ⋅ W h h ⋅ ∂ h 0 ∂ W h h \frac{\partial h_1}{\partial W_{hh}} = \tanh'(z_1) \cdot h_0 + \tanh'(z_1) \cdot W_{hh} \cdot \frac{\partial h_0}{\partial W_{hh}} ∂Whh∂h1=tanh′(z1)⋅h0+tanh′(z1)⋅Whh⋅∂Whh∂h0
如果 h 0 h_0 h0 是常数初始状态,则其导数为 0,终止链条。
4. 梯度消失现象
我们看到:
∂ E 3 ∂ W h h ∝ tanh ′ ( z 3 ) ⋅ W h h ⋅ tanh ′ ( z 2 ) ⋅ W h h ⋅ tanh ′ ( z 1 ) ⋅ h 0 \frac{\partial E_3}{\partial W_{hh}} \propto \tanh'(z_3) \cdot W_{hh} \cdot \tanh'(z_2) \cdot W_{hh} \cdot \tanh'(z_1) \cdot h_0 ∂Whh∂E3∝tanh′(z3)⋅Whh⋅tanh′(z2)⋅Whh⋅tanh′(z1)⋅h0
每一项 tanh ′ ( z t ) \tanh'(z_t) tanh′(zt) 的值都在 ( 0 , 1 ) (0, 1) (0,1) 之间(最大值为 1,通常远小于 1)
每乘一次,就相当于把梯度“缩小”了一次。最终:
- 如果时间步很多(长序列)
- 激活函数导数又小(如 tanh \tanh tanh 饱和区)
就会出现:
∥ ∂ E ∂ W h h ∥ → 0 \left\|\frac{\partial E}{\partial W_{hh}}\right\| \to 0 ∂Whh∂E →0
这就是 vanishing gradient problem(梯度消失问题)
数值示例
- 若每一步梯度衰减因子为 0.9 0.9 0.9,则 0.9 100 ≈ 0 0.9^{100} \approx 0 0.9100≈0
- 若每一步因子为 1.01 1.01 1.01,则 1.01 100 ≈ 2100 1.01^{100} \approx 2100 1.01100≈2100
这意味着在长序列上训练 RNN,若不加改进,模型可能完全无法捕捉前面信息的影响。
LSTM 的核心结构
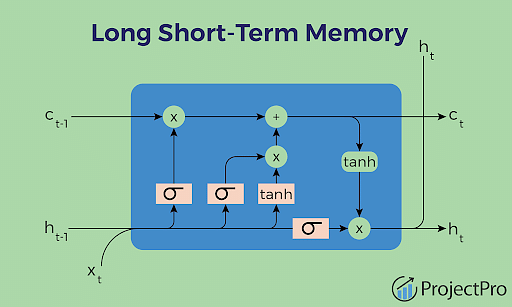
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络单元,它通过引入门控机制,有效缓解了梯度消失与爆炸的问题,使得网络可以在较长的时间范围内保留关键信息。
LSTM 单元引入了以下关键组成部分:
- 记忆单元(Memory Cell):用于长期存储信息
- 输入门(Input Gate):控制当前输入是否写入记忆
- 遗忘门(Forget Gate):控制旧信息是否从记忆中移除
- 输出门(Output Gate):控制记忆内容是否输出
这些门都是通过 Sigmoid 激活函数控制,取值范围在 [ 0 , 1 ] [0, 1] [0,1],起到“开关”作用。
LSTM 的计算流程
设:
- 当前时间步输入为 x t x_t xt
- 上一时刻隐藏状态为 h t − 1 h_{t-1} ht−1
- 上一时刻记忆状态为 c t − 1 c_{t-1} ct−1
我们依次计算如下:
遗忘门(Forget Gate)
决定是否保留上一时刻的记忆状态:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
输入门(Input Gate)
决定当前输入是否写入记忆:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
候选记忆更新:
c ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde{c}_t = \tanh(W_c \cdot [h_{t-1}, x_t] + b_c) c~t=tanh(Wc⋅[ht−1,xt]+bc)
记忆状态更新
新的记忆状态为旧状态的部分保留加上当前输入的更新:
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t ct=ft⊙ct−1+it⊙c~t
其中 ⊙ \odot ⊙ 表示按元素乘法(element-wise product)。
输出门与隐藏状态
输出门控制记忆状态是否暴露为隐藏状态:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
最终输出隐藏状态为:
h t = o t ⊙ tanh ( c t ) h_t = o_t \odot \tanh(c_t) ht=ot⊙tanh(ct)
LSTM 的门控结构总结
| 门控名称 | 公式 | 功能说明 |
|---|---|---|
| 遗忘门 f t f_t ft | σ ( W f [ h t − 1 , x t ] + b f ) \sigma(W_f [h_{t-1}, x_t] + b_f) σ(Wf[ht−1,xt]+bf) | 保留旧记忆的比例 |
| 输入门 i t i_t it | σ ( W i [ h t − 1 , x t ] + b i ) \sigma(W_i [h_{t-1}, x_t] + b_i) σ(Wi[ht−1,xt]+bi) | 决定写入新信息 |
| 候选记忆 c ~ t \tilde{c}_t c~t | tanh ( W c [ h t − 1 , x t ] + b c ) \tanh(W_c [h_{t-1}, x_t] + b_c) tanh(Wc[ht−1,xt]+bc) | 当前输入生成的新信息候选 |
| 记忆状态 c t c_t ct | f t ⋅ c t − 1 + i t ⋅ c ~ t f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t ft⋅ct−1+it⋅c~t | 最终更新记忆 |
| 输出门 o t o_t ot | σ ( W o [ h t − 1 , x t ] + b o ) \sigma(W_o [h_{t-1}, x_t] + b_o) σ(Wo[ht−1,xt]+bo) | 控制记忆是否输出为 h t h_t ht |
| 隐藏状态 h t h_t ht | o t ⋅ tanh ( c t ) o_t \cdot \tanh(c_t) ot⋅tanh(ct) | 当前时间步输出 |
LSTM 结构中每一个门控都由一个独立的权重矩阵控制,因此相比于 vanilla RNN,参数量大约是其 4 倍。
直观解释与举例说明
门控结构的设计可以类比成水库调节:
- 遗忘门决定“旧水”是否放掉
- 输入门决定是否注入“新水”
- 输出门决定是否将“水”输送出去
这种结构使得网络可以长时间“记住”关键的信息,同时“忘记”无关信息,从而解决传统 RNN 难以处理长依赖的问题。
LSTM 数值演示:门控机制的作用
以下为一个具体的输入序列示例,观察不同门控值下 LSTM 的记忆状态 c t c_t ct 和输出状态 h t h_t ht 是如何变化的。
我们使用以下三个门控信号:
- x t \mathbf{x_t} xt:输入值
- f t f_t ft:遗忘门输出(取值范围 [ − 1 , 1 ] [-1, 1] [−1,1],这里简化为 − 1 -1 −1, 0 0 0, 1 1 1)
- i t i_t it:输入门输出(是否接受当前输入)
- o t o_t ot:输出门输出(是否将记忆暴露为输出)
初始记忆状态 c 0 = 0 c_0 = 0 c0=0,隐藏状态 h 0 = 0 h_0 = 0 h0=0。
输入序列如下:
| x t x_t xt | f t f_t ft | i t i_t it | o t o_t ot |
|---|---|---|---|
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 3 | -1 | 0 | 0 |
| 6 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1 |
我们逐步计算记忆状态 c t c_t ct 和隐藏状态 h t h_t ht:
时间步 1~3:只保留旧记忆,不写入新信息
- i t = 0 i_t = 0 it=0,说明不写入新输入
- f t = 1 f_t = 1 ft=1,旧记忆保持
- 由于初始 c 0 = 0 c_0 = 0 c0=0,所以前 3 步都不会更新记忆, h t = 0 h_t = 0 ht=0
时间步 4:开始写入有效输入
- i t = 1 i_t = 1 it=1,当前输入 x 4 = 1 x_4 = 1 x4=1 被写入
- f t = 0 f_t = 0 ft=0,清空旧记忆
- c 4 = 0 ⋅ c 3 + 1 ⋅ x 4 = 1 c_4 = 0 \cdot c_3 + 1 \cdot x_4 = 1 c4=0⋅c3+1⋅x4=1
- o t = 1 o_t = 1 ot=1,输出 h 4 = tanh ( 1 ) ≈ 0.76 h_4 = \tanh(1) \approx 0.76 h4=tanh(1)≈0.76
时间步 5:遗忘门为负数(重置记忆)
- f t = − 1 f_t = -1 ft=−1,强制清除当前记忆
- i t = 0 i_t = 0 it=0,不接收当前输入
- c 5 = − 1 ⋅ c 4 + 0 ⋅ x 5 = − 1 c_5 = -1 \cdot c_4 + 0 \cdot x_5 = -1 c5=−1⋅c4+0⋅x5=−1
- o t = 0 o_t = 0 ot=0,输出被阻断, h 5 = 0 h_5 = 0 h5=0
时间步 6:继续保持当前记忆
- f t = 1 f_t = 1 ft=1,保留 c 5 = − 1 c_5 = -1 c5=−1
- i t = 0 i_t = 0 it=0,不写入新值
- c 6 = − 1 c_6 = -1 c6=−1
- o t = 0 o_t = 0 ot=0, h 6 = 0 h_6 = 0 h6=0
时间步 7:重新写入并输出新信息
- f t = 0 f_t = 0 ft=0,清空 c 6 c_6 c6
- i t = 1 i_t = 1 it=1,写入 x 7 = 1 x_7 = 1 x7=1
- c 7 = 1 c_7 = 1 c7=1
- o t = 1 o_t = 1 ot=1, h 7 = tanh ( 1 ) ≈ 0.76 h_7 = \tanh(1) \approx 0.76 h7=tanh(1)≈0.76
总结表
| 时间 t t t | x t x_t xt | f t f_t ft | i t i_t it | o t o_t ot | c t c_t ct | h t h_t ht |
|---|---|---|---|---|---|---|
| 1 | 3 | 1 | 0 | 0 | 0 | 0 |
| 2 | 4 | 1 | 0 | 0 | 0 | 0 |
| 3 | 2 | 1 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 1 | 1 | 1 | 0.76 |
| 5 | 3 | -1 | 0 | 0 | -1 | 0 |
| 6 | 6 | 1 | 0 | 0 | -1 | 0 |
| 7 | 1 | 0 | 1 | 1 | 1 | 0.76 |
这个例子充分说明了:
- 遗忘门可以清空或保留旧信息
- 输入门决定当前输入是否被接受
- 输出门控制隐藏状态是否输出给外部
这些机制构成了 LSTM 的核心,让它具备“选择性记忆”的能力。
堆叠 LSTM(Stacked LSTM)
在基础 LSTM 的结构上,我们可以进一步构造“深层 RNN”或“堆叠 LSTM”模型。
基本思想是:
- 将多个 LSTM 层堆叠在一起
- 每一层的输出作为下一层的输入
设输入序列为 x t \mathbf{x}_t xt,第一层的输出为 h t ( 1 ) \mathbf{h}^{(1)}_t ht(1),则第二层的输入为:
x t ( 2 ) = h t ( 1 ) \mathbf{x}^{(2)}_t = \mathbf{h}^{(1)}_t xt(2)=ht(1)
以此类推,可以构造 L L L 层堆叠的结构:
h t ( l ) = LSTM ( l ) ( h t ( l − 1 ) ) \mathbf{h}^{(l)}_t = \text{LSTM}^{(l)}(\mathbf{h}^{(l-1)}_t) ht(l)=LSTM(l)(ht(l−1))
这种结构能够提升模型的表达能力和非线性建模能力,尤其适用于复杂语义建模任务,如:
- 文本生成
- 情感分析
- 语言翻译
不过堆叠越多,训练越慢,容易过拟合,因此一般使用 2~4 层即可。
双向 RNN(Bidirectional RNN)
传统 RNN 只能从左到右处理序列,依赖于历史信息,不能利用未来信息。**双向 RNN(BiRNN)**通过在同一时间点引入两个方向的信息流来解决这一问题:
- 一个正向 RNN 处理 x 1 → x T \mathbf{x}_1 \to \mathbf{x}_T x1→xT
- 一个反向 RNN 处理 x T → x 1 \mathbf{x}_T \to \mathbf{x}_1 xT→x1
- 两者的隐藏状态拼接作为输出
设:
- 正向输出为 h → t \overrightarrow{h}_t ht
- 反向输出为 h ← t \overleftarrow{h}_t ht
则总输出为:
h t = [ h → t ; h ← t ] h_t = [\overrightarrow{h}_t ; \overleftarrow{h}_t] ht=[ht;ht]
这种结构适用于:
- 命名实体识别(需要前后文)
- 文本分类
- 语音识别等任务
注意:BiRNN 无法用于实时场景,因为需要整个序列才能计算反向。
LSTM vs RNN 对比
| 特性 | Vanilla RNN | LSTM |
|---|---|---|
| 是否有门控机制 | 否 | 是(输入门、遗忘门、输出门) |
| 是否保留长距离信息 | 否,易受梯度消失影响 | 是,通过记忆单元和门控稳定梯度 |
| 计算复杂度 | 低 | 高(参数量约为 RNN 的 4 倍) |
| 是否能处理长依赖 | 不擅长 | 擅长 |
| 应用范围 | 简单序列建模 | 复杂任务(机器翻译、对话系统等) |
防止梯度消失的方式
我们再回顾梯度问题:
-
RNN 中:
h t = tanh ( W h h h t − 1 + W x h x t + b ) h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b) ht=tanh(Whhht−1+Wxhxt+b) -
LSTM 中核心更新为:
c t = f t ⋅ c t − 1 + i t ⋅ c ~ t c_t = f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t ct=ft⋅ct−1+it⋅c~t
该加法结构保留了来自 c t − 1 c_{t-1} ct−1 的“线性路径”,不会像 RNN 那样在链式相乘中消失。
因此,LSTM 的核心创新在于:
- 在反向传播中构造“加法路径”代替“乘法路径”
- 通过频繁更新的门控变量控制信息的保留与丢弃
- 实现了梯度的长期稳定传播
这也是它能有效处理长距离依赖的关键原因。
GRU(Gated Recurrent Unit)结构详解
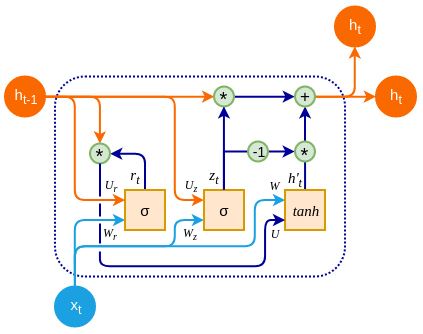
GRU(门控循环单元)是对 LSTM 的进一步简化版本,由 Cho 等人于 2014 年提出。它保留了门控思想,但结构更加紧凑,计算效率更高。
GRU 与 LSTM 的关键区别:
- GRU 将遗忘门与输入门合并为“更新门”
- 没有显式的记忆单元 c t c_t ct,只有隐藏状态 h t h_t ht
- 参数更少,收敛速度更快
GRU 的核心结构如下:
- 重置门 r t r_t rt:决定前一隐藏状态有多少用于当前候选状态的计算
- 更新门 z t z_t zt:控制当前隐藏状态保留多少旧状态、加多少新状态
- 候选隐藏状态 h ~ t \tilde{h}_t h~t:当前时间步的新信息
GRU 的数学公式
设当前时间步输入为 x t x_t xt,前一隐藏状态为 h t − 1 h_{t-1} ht−1,则 GRU 计算过程如下:
1. 重置门(Reset Gate)
控制前一状态参与计算的程度:
r t = σ ( W r x t + U r h t − 1 + b r ) r_t = \sigma(W_r x_t + U_r h_{t-1} + b_r) rt=σ(Wrxt+Urht−1+br)
2. 更新门(Update Gate)
决定当前隐藏状态是否更新:
z t = σ ( W z x t + U z h t − 1 + b z ) z_t = \sigma(W_z x_t + U_z h_{t-1} + b_z) zt=σ(Wzxt+Uzht−1+bz)
3. 候选隐藏状态(Candidate State)
由当前输入和前一状态(乘以 r t r_t rt)生成:
h ~ t = tanh ( W h x t + U h ( r t ⊙ h t − 1 ) + b h ) \tilde{h}_t = \tanh(W_h x_t + U_h (r_t \odot h_{t-1}) + b_h) h~t=tanh(Whxt+Uh(rt⊙ht−1)+bh)
4. 最终隐藏状态更新
将旧状态和新状态进行“加权融合”:
h t = z t ⊙ h t − 1 + ( 1 − z t ) ⊙ h ~ t h_t = z_t \odot h_{t-1} + (1 - z_t) \odot \tilde{h}_t ht=zt⊙ht−1+(1−zt)⊙h~t
其中:
- ⊙ \odot ⊙ 表示按元素乘法
- σ \sigma σ 是 sigmoid 函数(输出范围 [ 0 , 1 ] [0, 1] [0,1])
- tanh \tanh tanh 是非线性激活函数
GRU 与 LSTM 的比较
| 特性 | GRU | LSTM |
|---|---|---|
| 门控数量 | 2(更新门 + 重置门) | 3(输入门 + 遗忘门 + 输出门) |
| 是否有显式记忆单元 | 否,只有 h t h_t ht | 是,包含记忆单元 c t c_t ct 和隐藏状态 h t h_t ht |
| 参数数量 | 较少 | 较多 |
| 训练速度 | 较快 | 略慢 |
| 表达能力 | 稍弱但足够 | 更强,适合处理复杂长期依赖 |
| 实际表现 | 与 LSTM 相近,有时更优 | 稳定性更强,适用于复杂结构 |
GRU 是 LSTM 的轻量级替代方案,常用于资源受限或对速度要求高的场景,例如移动设备推理、短序列建模等。
视觉问答(Visual Question Answering, VQA)
VQA 是一种典型的多模态任务,模型需要同时理解图像和自然语言问题,并输出合理答案。它结合了图像处理(CNN)与文本建模(RNN / LSTM),是深度学习多模态融合的重要代表。
任务示例:
- 图像内容:红绿灯亮着一个颜色
- 问题:What color is illuminated on the traffic light?
- 模型需要输出:“green” 或 “red”
VQA 模型结构概览
VQA 模型通常包含以下几个组件:
-
问题编码模块(Question Encoder)
- 使用 LSTM 编码自然语言问题
- 输入:词向量序列
- 输出:问题向量 q q q
-
图像编码模块(Image Encoder)
- 使用 CNN 或目标检测模型提取图像区域特征
- 输出:多个图像对象或区域的向量 { v 1 , v 2 , . . . , v k } \{v_1, v_2, ..., v_k\} {v1,v2,...,vk}
-
注意力机制(Attention)
- 计算问题向量与图像区域之间的相关性
- 输出加权图像表示 v ^ \hat{v} v^
-
图文融合与分类
- 将问题向量 q q q 与加权图像表示 v ^ \hat{v} v^ 融合(如拼接、加权乘)
- 通过全连接层 + softmax 输出答案
问题编码:LSTM 处理序列
问题如 “What’s the mustache made of?” 会被转换为单词序列:
[What, ’s, the, mustache, made, of] \text{[What, ’s, the, mustache, made, of]} [What, ’s, the, mustache, made, of]
每个词经嵌入后送入 LSTM,最终输出最后一步隐藏状态作为问题向量 q q q:
q = LSTM ( x 1 , x 2 , . . . , x T ) q = \text{LSTM}(x_1, x_2, ..., x_T) q=LSTM(x1,x2,...,xT)
图像区域表示与对象检测
使用 Faster R-CNN 等预训练模型,对图像进行目标检测,获得多个区域特征向量:
V = { v 1 , v 2 , . . . , v k } , v i ∈ R d V = \{v_1, v_2, ..., v_k\}, \quad v_i \in \mathbb{R}^d V={v1,v2,...,vk},vi∈Rd
这些向量可看作“图像中的对象单元”。
图像注意力机制
我们使用注意力机制,让模型自动聚焦于与问题最相关的图像区域。
步骤如下:
-
对每个图像区域 v i v_i vi 与问题向量 q q q 做乘法融合:
s i = score ( v i , q ) s_i = \text{score}(v_i, q) si=score(vi,q) -
用 softmax 得到注意力权重:
α i = exp ( s i ) ∑ j exp ( s j ) \alpha_i = \frac{\exp(s_i)}{\sum_j \exp(s_j)} αi=∑jexp(sj)exp(si) -
加权求和得到图像注意力表示:
v ^ = ∑ i α i v i \hat{v} = \sum_i \alpha_i v_i v^=i∑αivi
图文融合与分类输出
将问题向量 q q q 与图像注意力向量 v ^ \hat{v} v^ 融合,方法包括:
- 拼接 [ q ; v ^ ] [q; \hat{v}] [q;v^]
- 加权乘 q ⊙ v ^ q \odot \hat{v} q⊙v^
- 使用全连接层进行进一步变换
最终通过 softmax 得到答案概率分布:
y ^ = softmax ( W [ q ; v ^ ] + b ) \hat{y} = \text{softmax}(W [q; \hat{v}] + b) y^=softmax(W[q;v^]+b)
该结构支持回答开放式问题,例如:
- “What is the man holding?” → 答:“tennis racket”
- “What’s the mustache made of?” → 答:“banana”
这体现了 LSTM 在语言建模与注意力对齐中的关键作用。
阅读理解(Reading Comprehension)
阅读理解任务要求模型根据提供的上下文信息(事实)回答自然语言问题。与 VQA 类似,它也需要处理文本序列,但输入和答案都在文本中。
示例:
- 上下文:
- A. Brian is a frog.
- B. Lily is gray.
- C. Brian is yellow.
- D. Julius is green.
- E. Greg is a frog.
- 问题:What color is Greg?
- 正确答案:yellow(因为 Brian 和 Greg 都是 frog,根据 A 和 C 可推理出)
基本结构
模型通常包含以下组成:
- 问题编码器:将问题向量化
- 上下文编码器:将每一句事实转为向量
- 注意力机制:让模型从所有句子中聚焦于与问题相关的句子
- 答案选择器:根据注意力分布选择或生成答案
输入表示
- 问题 q q q:通过 LSTM 编码为向量表示
- 每条事实 s i s_i si:也通过 LSTM 编码为向量 m i m_i mi,作为记忆槽(memory slot)
假设有 n n n 条句子:
M = { m 1 , m 2 , . . . , m n } M = \{ m_1, m_2, ..., m_n \} M={m1,m2,...,mn}
选择相关事实:注意力机制
模型通过注意力机制判断哪些事实与问题最相关。
计算每个事实 m i m_i mi 与问题 q q q 的匹配度(注意力分数):
α i = softmax ( q ⊤ m i ) \alpha_i = \text{softmax}(q^\top m_i) αi=softmax(q⊤mi)
注意力加权和作为上下文总结表示:
o = ∑ i = 1 n α i m i o = \sum_{i=1}^n \alpha_i m_i o=i=1∑nαimi
然后将问题 q q q 与上下文表示 o o o 结合,用于生成或选择答案。
端到端记忆网络(End-to-End Memory Networks)
一种经典方法是 Memory Network(MemN2N),其结构如下:
- 输入表示模块:将问题和句子转为向量
- 记忆更新模块:多轮注意力选择事实
- 输出模块:根据最终记忆状态生成答案
多轮结构(多 hop)允许模型反复选择不同事实,从而实现复杂推理。
例如:
- 第一次选择:A(Brian 是青蛙)
- 第二次选择:C(Brian 是黄色)
- 得出结论:Greg 是青蛙 → Greg 是黄色
该结构模拟了“多轮阅读 - 关联推理”的过程。
阅读理解任务强调模型的逻辑推理能力,对 LSTM 的长程建模和注意力机制依赖极强。
Sequence-to-Sequence(Seq2Seq)模型架构
Seq2Seq(序列到序列)模型用于将一个输入序列映射到一个输出序列,是机器翻译、问答系统、语音识别等任务的核心技术之一。该架构由一个编码器(Encoder)和一个解码器(Decoder)构成,典型实现基于 LSTM 或 GRU。
应用示例
-
输入(中文):我是一个学生
-
输出(英文):I am a student
-
输入(对话):Where do you come from?
-
输出:I am from Sydney, and you?
编码器部分(Encoder)
编码器接收源语言序列 { x 1 , x 2 , . . . , x T } \{x_1, x_2, ..., x_T\} {x1,x2,...,xT},逐步处理输入,并将其转化为隐藏状态序列 { h 1 , h 2 , . . . , h T } \{h_1, h_2, ..., h_T\} {h1,h2,...,hT}。
如果使用 LSTM:
h t = LSTM ( x t , h t − 1 ) h_t = \text{LSTM}(x_t, h_{t-1}) ht=LSTM(xt,ht−1)
通常我们取最后一个隐藏状态作为上下文向量(context vector) c c c:
c = h T c = h_T c=hT
该上下文向量 c c c 被传递给解码器作为其初始状态。
解码器部分(Decoder)
解码器根据上下文向量 c c c 和之前已生成的词,逐步输出目标序列 { y 1 , y 2 , . . . , y T } \{y_1, y_2, ..., y_T\} {y1,y2,...,yT}。
其每一步的输入是前一个输出词 y t − 1 y_{t-1} yt−1 和上一隐藏状态 s t − 1 s_{t-1} st−1:
s t = LSTM ( y t − 1 , s t − 1 ) , y t = softmax ( W s t + b ) s_t = \text{LSTM}(y_{t-1}, s_{t-1}), \quad y_t = \text{softmax}(W s_t + b) st=LSTM(yt−1,st−1),yt=softmax(Wst+b)
该方法称为自回归生成,即当前预测依赖前面已生成的输出。
注意力机制(Attention)
传统 Seq2Seq 架构存在一个瓶颈:所有输入信息被压缩为一个固定向量 c c c,当输入序列过长时,效果显著下降。
注意力机制通过动态计算每个输入隐藏状态对当前输出的贡献,解决了这个问题。
计算过程如下:
- 对每一个编码器隐藏状态 h i h_i hi 与当前解码器状态 s t − 1 s_{t-1} st−1 计算注意力得分:
e t i = s t − 1 ⊤ W a h i e_{ti} = s_{t-1}^\top W_a h_i eti=st−1⊤Wahi
- 对所有得分进行归一化,得到注意力权重 α t i \alpha_{ti} αti:
α t i = exp ( e t i ) ∑ j exp ( e t j ) \alpha_{ti} = \frac{\exp(e_{ti})}{\sum_j \exp(e_{tj})} αti=∑jexp(etj)exp(eti)
- 使用注意力权重加权求和编码器隐藏状态,得到上下文向量 a t a_t at:
a t = ∑ i α t i h i a_t = \sum_i \alpha_{ti} h_i at=i∑αtihi
- 解码器将该上下文向量作为额外输入:
s t = LSTM ( y t − 1 , s t − 1 , a t ) s_t = \text{LSTM}(y_{t-1}, s_{t-1}, a_t) st=LSTM(yt−1,st−1,at)
带注意力的门控计算(多项加权)
在引入注意力后,LSTM 的每个门控都可以接收额外的上下文信息 a t a_t at,如下所示:
-
遗忘门:
f t = σ ( W f s t − 1 + U f y t − 1 + V f a t + b f ) f_t = \sigma(W_f s_{t-1} + U_f y_{t-1} + V_f a_t + b_f) ft=σ(Wfst−1+Ufyt−1+Vfat+bf) -
输入门:
i t = σ ( W i s t − 1 + U i y t − 1 + V i a t + b i ) i_t = \sigma(W_i s_{t-1} + U_i y_{t-1} + V_i a_t + b_i) it=σ(Wist−1+Uiyt−1+Viat+bi) -
输出门:
o t = σ ( W o s t − 1 + U o y t − 1 + V o a t + b o ) o_t = \sigma(W_o s_{t-1} + U_o y_{t-1} + V_o a_t + b_o) ot=σ(Wost−1+Uoyt−1+Voat+bo) -
候选状态:
c ~ t = tanh ( W c s t − 1 + U c y t − 1 + V c a t + b c ) \tilde{c}_t = \tanh(W_c s_{t-1} + U_c y_{t-1} + V_c a_t + b_c) c~t=tanh(Wcst−1+Ucyt−1+Vcat+bc)
最终隐藏状态为:
s t = o t ⊙ tanh ( f t ⋅ c t − 1 + i t ⋅ c ~ t ) s_t = o_t \odot \tanh(f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t) st=ot⊙tanh(ft⋅ct−1+it⋅c~t)
直观解释
注意力机制允许模型在每个时间步“对准”最相关的输入词,使得翻译、摘要等任务的对齐关系更加自然。例如:
- 输入:“我是一个学生”
- 解码第一个词 “I” 时,主要关注 “我”
- 解码 “student” 时,主要关注 “学生”
总结
Seq2Seq + Attention 架构通过:
- 编码整个源序列
- 动态对齐目标词与源词
- 强化了长距离依赖建模能力
成为现代神经机器翻译(Neural Machine Translation, NMT)的基础架构。