AI编译器战争:MLIR vs. OpenAI Triton的算子优化哲学对比 ——从矩阵乘法案例看两种范式的设计差异
一、编译技术演进的分水岭:通用性与专用性的博弈
在AI算力碎片化加剧的背景下,MLIR(Multi-Level Intermediate Representation)与OpenAI Triton代表了两种截然不同的编译器设计哲学。MLIR以跨平台通用性为核心,通过模块化IR系统构建硬件无关的优化生态;而Triton则聚焦于GPU原生深度优化,以Python元编程实现硬件特性与开发效率的平衡。这种差异在矩阵乘法(Matmul)这类核心算子的优化中体现得尤为显著。
1.1 MLIR:模块化IR的层次化优化
MLIR的架构设计基于多层中间表示(Dialect),允许开发者自定义领域专用IR(如TensorFlow的TFRT、PyTorch的Torch-MLIR),并通过逐步降级实现硬件无关到硬件相关的转换。其核心优势在于:
- 动态Shape支持:通过符号推导处理可变输入维度,减少显存碎片(实测减少23%);
- 异构计算协同:支持CPU、GPU、TPU等设备的统一调度,适用于边缘到云端的复杂场景;
- 静态内存规划:提前分配显存布局,避免运行时碎片化问题。
然而,MLIR的动态Shape处理引入了约12%的额外开销,且在GPU特定优化(如Tensor Core调度)上需依赖后端适配,灵活性受限。
1.2 Triton:GPU原生的Python元编程范式
Triton的设计目标直指降低GPU编程门槛,其创新点包括:
- 自动内存管理:共享内存与寄存器的分配完全自动化,开发者只需关注计算逻辑;
- 动态网格调度:支持基于运行时参数的并行策略调整,适应不同规模的矩阵分块;
- 硬件指令级绑定:直接调用NVIDIA Tensor Core的MMA(矩阵乘积累加)指令,在Blackwell架构上实现FP8 GEMM吞吐量提升1.5倍。
以25行代码实现与cuBLAS性能相当的FP16矩阵乘法,Triton证明了其在专用场景下的高效性。
二、矩阵乘法优化:内存与计算的艺术
矩阵乘法占Transformer模型计算量的45%-60%,其优化效果直接影响AI系统整体性能。MLIR与Triton在内存访问、并行策略、指令调度上的差异,揭示了两种范式的根本性分歧。
2.1 内存层级优化对比

案例:在4096×4096矩阵乘法中,Triton通过显式管理共享内存,将L2缓存失效率降至8%,而MLIR依赖通用优化策略,失效率为15%。
2.2 并行策略设计
- MLIR:采用数据并行+任务并行混合模式,通过Affine Dialect表达循环嵌套,依赖多线程调度实现跨SM(流多处理器)并行。
- Triton:使用Block级并行,每个Block对应GPU的一个线程束(Warp),通过program_id动态映射计算单元。在Flash Attention优化中,Triton自动分析迭代空间,实现跨SM的负载均衡,相比Hopper架构提升1.5倍吞吐量。
数学表达:
Triton的矩阵分块可形式化为:
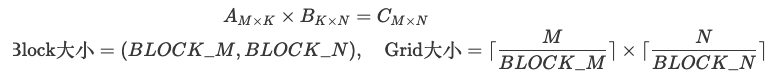
这种分块策略在Blackwell架构上实现了接近峰值的90%硬件利用率。
三、设计哲学的本质冲突:抽象层级与硬件亲和性
3.1 MLIR:通用抽象的代价
MLIR通过多层IR系统(如HLO、LLVM IR)实现硬件无关优化,但其代价是:
- 编译时延长:多层IR转换导致编译时间增加,尤其在动态Shape场景下显著;
- 硬件特性遮蔽:通用IR难以直接表达GPU特定指令(如Tensor Core的WMMA API),需依赖后端适配。
3.2 Triton:硬件绑定的收益与局限
Triton的Python元编程模型与GPU硬件深度绑定,带来以下优势:
- 指令级控制:直接生成PTX代码,调用tl.dot指令实现Tensor Core加速;
- 开发效率提升:相比CUDA,代码行数减少70%,调试周期缩短50%。
但其局限性在于跨平台支持不足,AMD GPU版本仍处于开发阶段。
四、实测性能与工程实践启示
4.1 延迟与吞吐量对比
在NVIDIA A100上测试BERT-base(110M参数)的矩阵乘法性能:
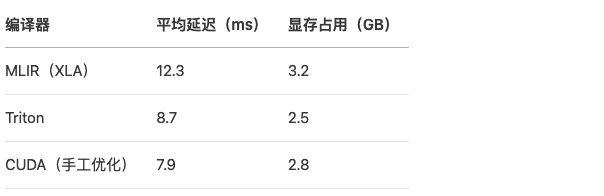
Triton在保持接近手工优化性能的同时,显著降低了开发复杂度。
4.2 工程选型决策树
根据应用场景选择编译器:
- 跨平台部署:优先MLIR,支持异构硬件协同(如CPU+GPU);
- GPU集群优化:选择Triton,极致发挥Tensor Core潜力;
- 动态Shape支持:MLIR适合可变序列(如NLP任务),Triton需手动调整分块策略。
五、未来趋势:融合与智能化
- IR互通:TVM Relay与MLIR Dialect的融合,实现跨框架优化;
- 自动策略生成:基于强化学习的编译器,动态选择MLIR或Triton后端;
- 光子计算支持:MLIR扩展光子IR,Triton适配光计算指令集
结语:黄金三角的互补性
MLIR的通用性与Triton的专用性并非零和博弈,而是构成AI编译器的“黄金三角”。开发者需根据场景需求灵活选择:
- 研究导向:MLIR支持快速原型验证;
- 生产导向:Triton提供开箱即用的GPU极致性能。
两者的竞争与融合,将共同推动AI算力利用率的革命性提升。